Acta Aeronautica et Astronautica Sinica ›› 2025, Vol. 46 ›› Issue (15): 331354.doi: 10.7527/S1000-6893.2024.31354
• Electronics and Electrical Engineering and Control • Previous Articles
Yu WANG( ), Zhipeng XIE, Yongjian TIAN, Guanglei MENG
), Zhipeng XIE, Yongjian TIAN, Guanglei MENG
Received:2024-10-08
Revised:2025-01-13
Accepted:2025-02-21
Online:2025-03-11
Published:2025-03-06
Contact:
Yu WANG
E-mail:wangyu@sau.edu.cn
Supported by:CLC Number:
Yu WANG, Zhipeng XIE, Yongjian TIAN, Guanglei MENG. Distributed UAV formation control with virtual structure guided reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(15): 331354.
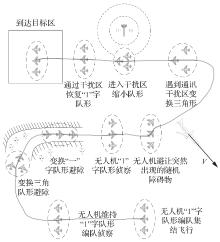
Fig.1
UAV mission scenario
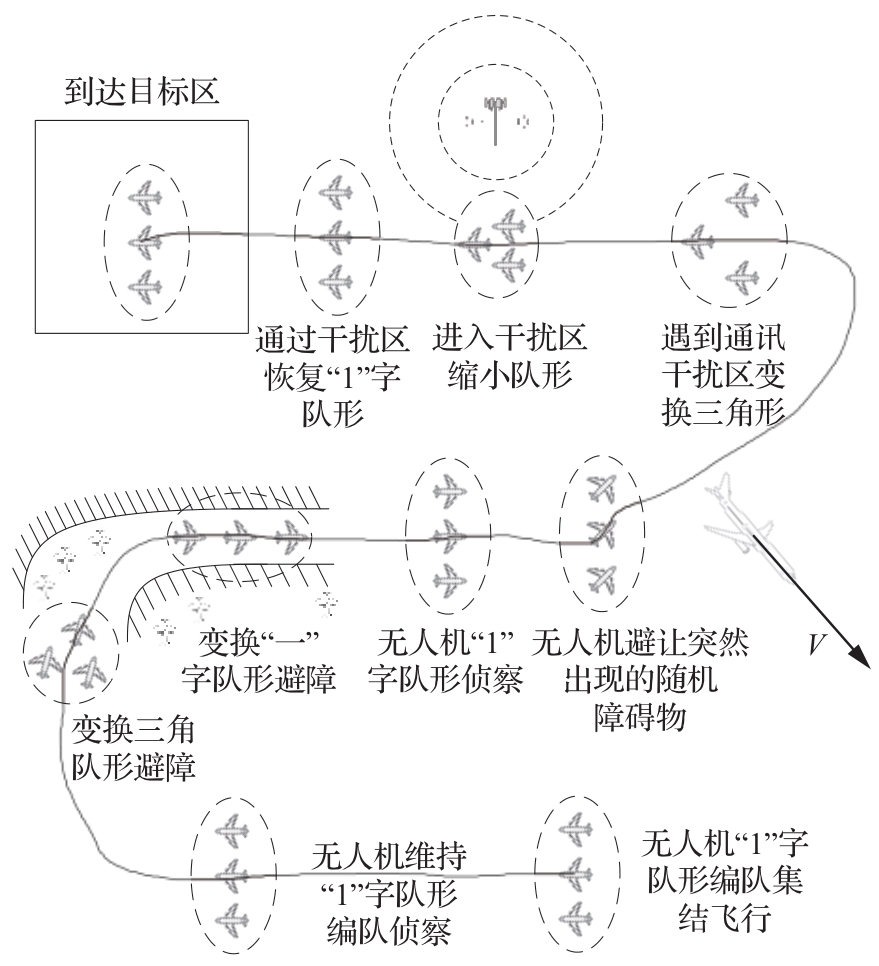

Fig.2
Subtarget region
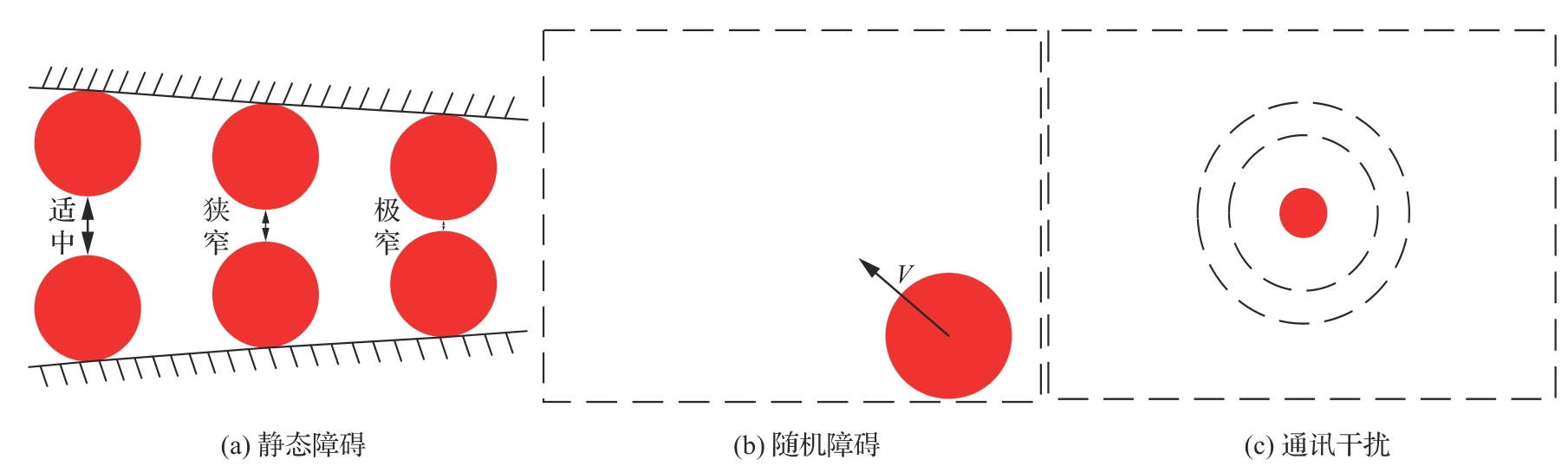
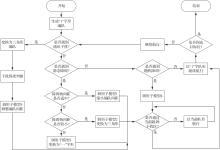
Fig.3
Flow chart of UAV formation control
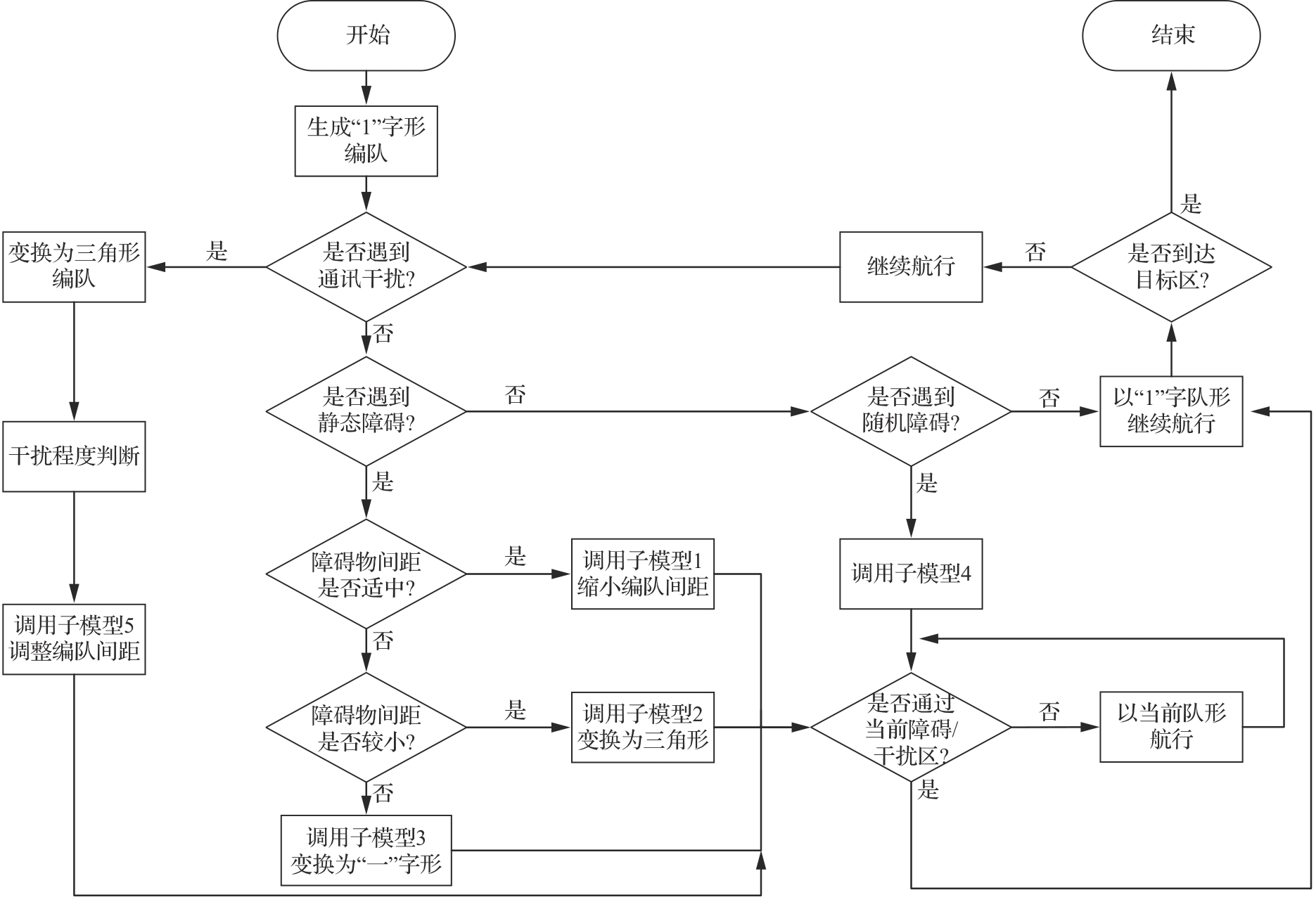

Fig.4
Distributed UAV formation control system
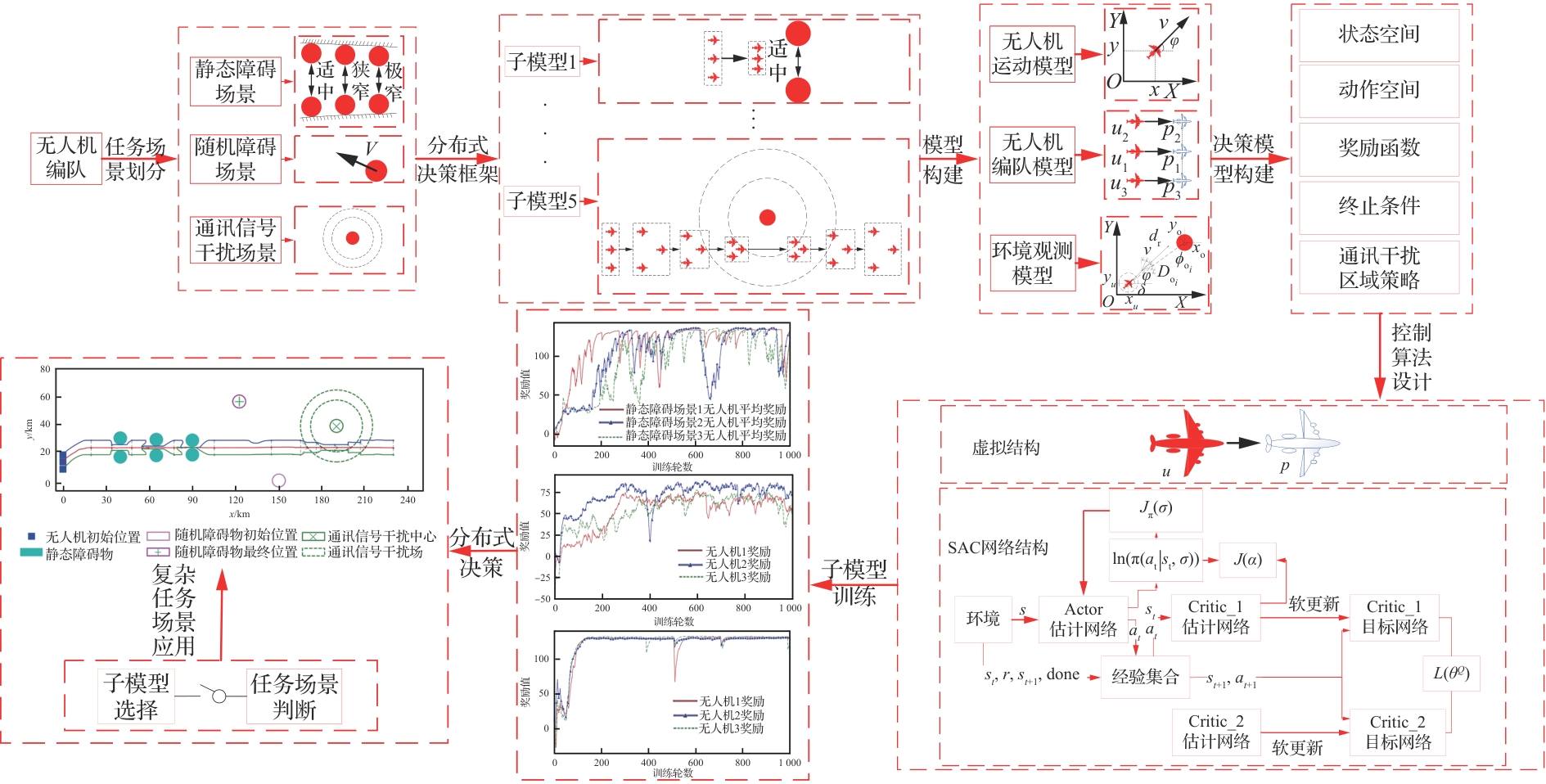
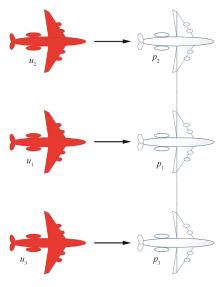
Fig.5
UAV formation model based on virtual structure
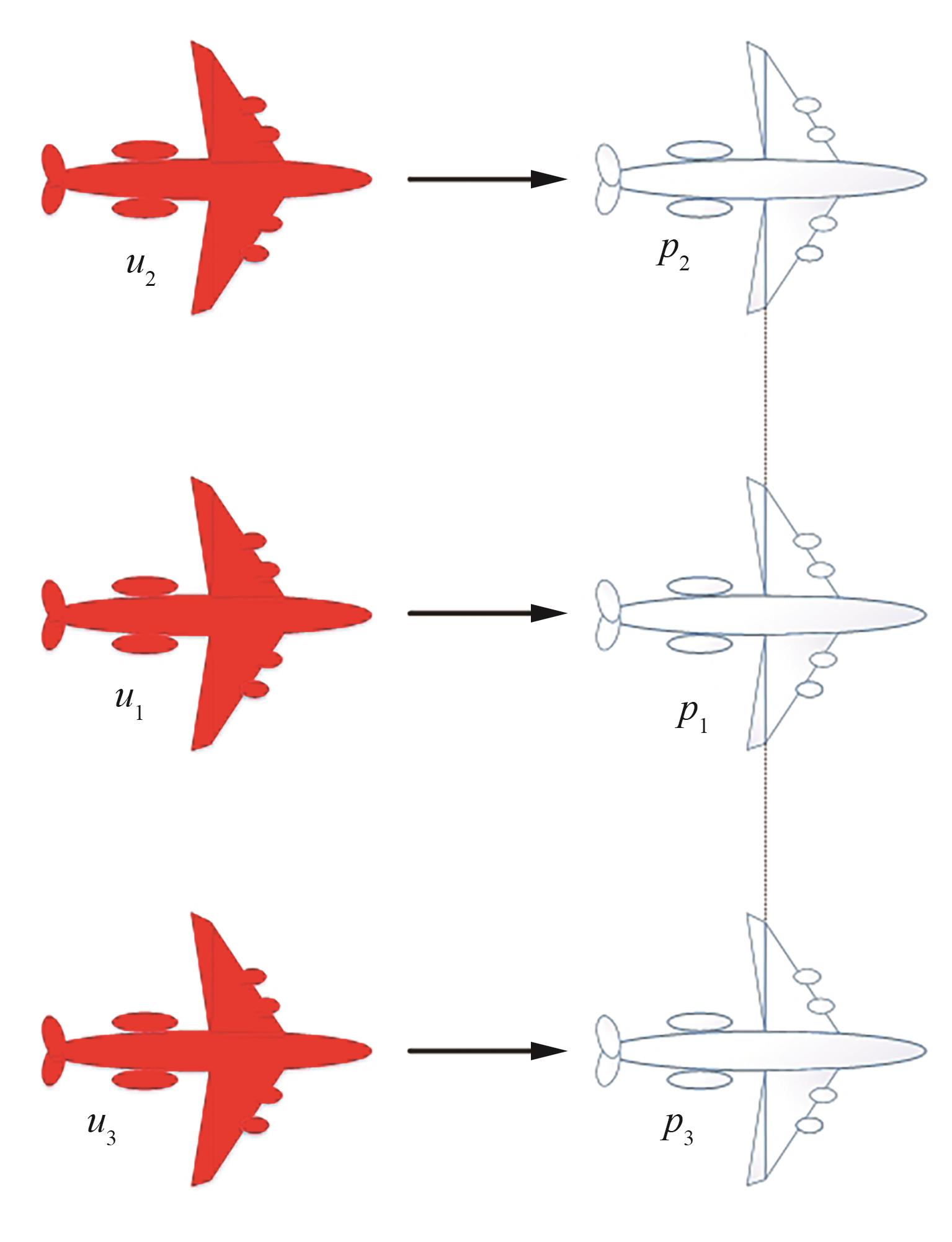
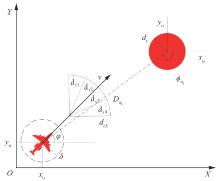
Fig.6
Environmental observation model
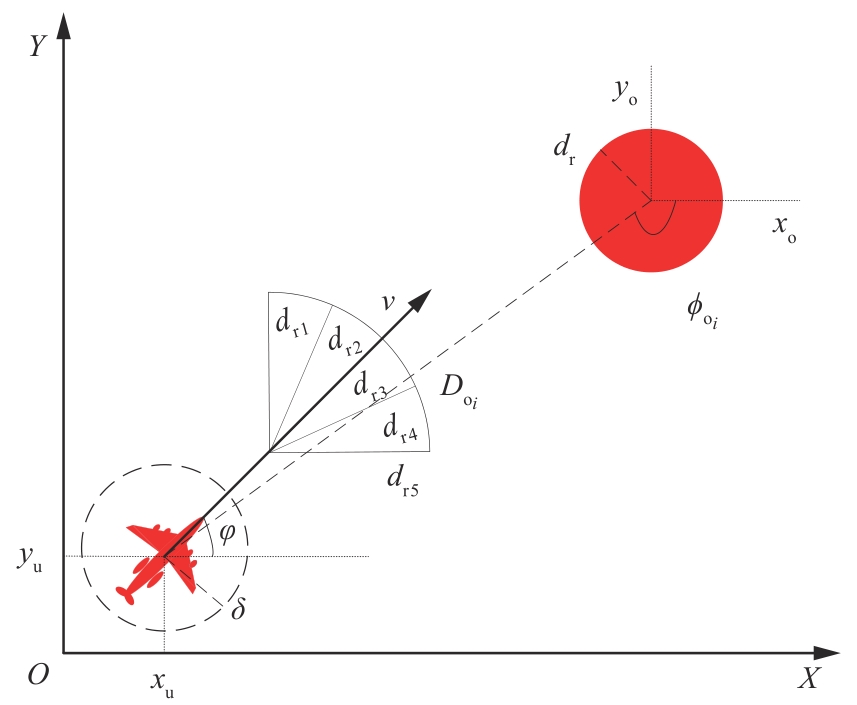
Table 1
Major environmental parameters
| 参数 | 数值 |
|---|---|
| 无人机1、2、3初始位置 | [0,25],[0,30],[0,10] |
虚拟结构点1、2、3初始位置 | [ |
| 距离传感器探测范围 | 3 |
无人机速度范围 | [100,300] |
无人机角加速度范围 | [-2,2] |
| 无人机工作时间 | 800(模型4) 1 200(模型1~3、5) |
Table 2
Hyperparameters
| 参数名称 | 数值 |
|---|---|
| 经验池大小/ | 65 536 |
| 训练批次大小/N | 64 |
| Actor网络训练率 | |
| Critic网络训练率 | |
| 奖励折扣率 | 0.96 |
| 软更新学习率 | 0.05 |
| 最大训练次数 | 1 000 |
| 无人机步数 | 800(模型4) 1 200(模型1,2,3,5) |
Fig.7
UAVs’ training curves of Submodels 1-3
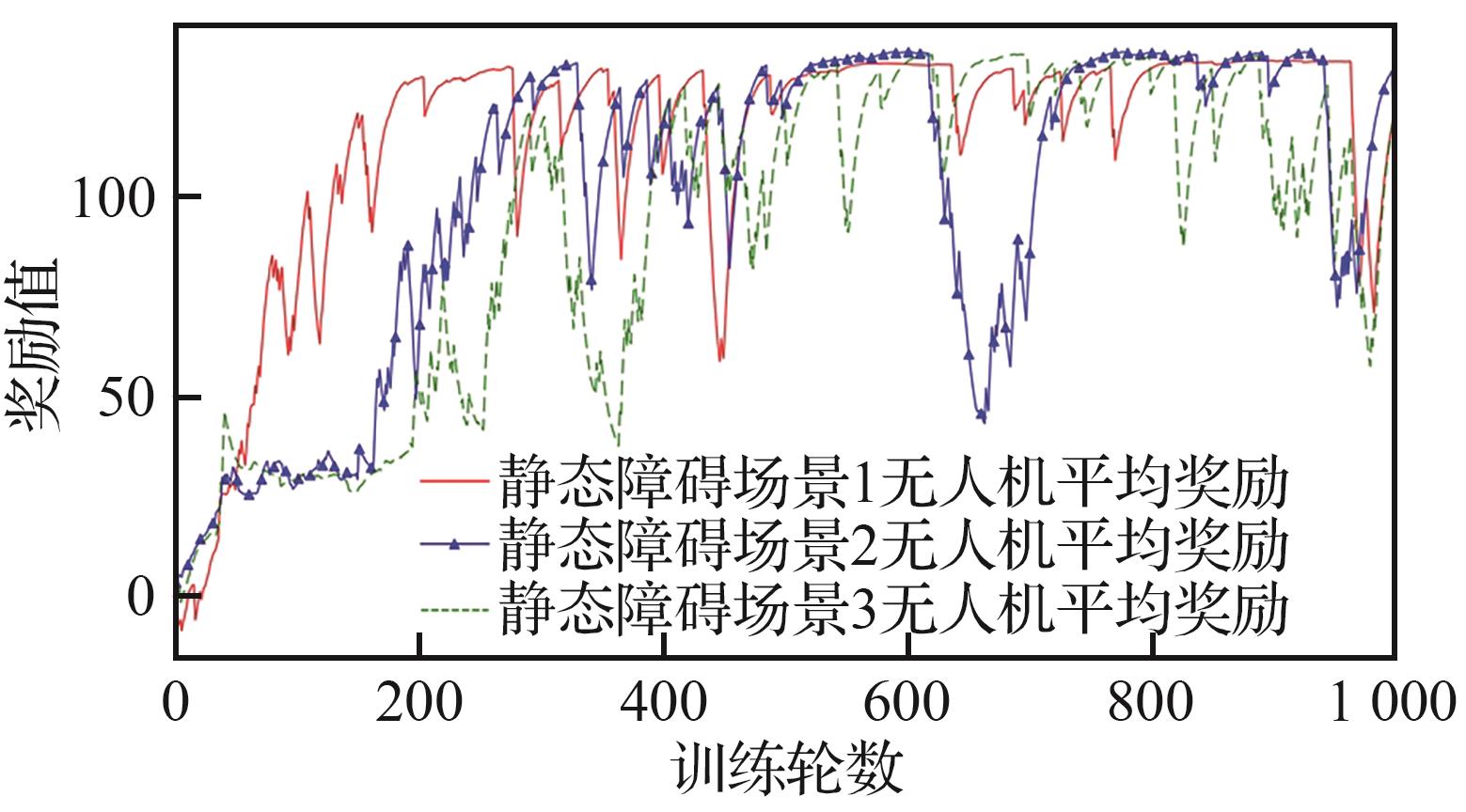
Fig.8
UAVs’ flight path of Submodel 1
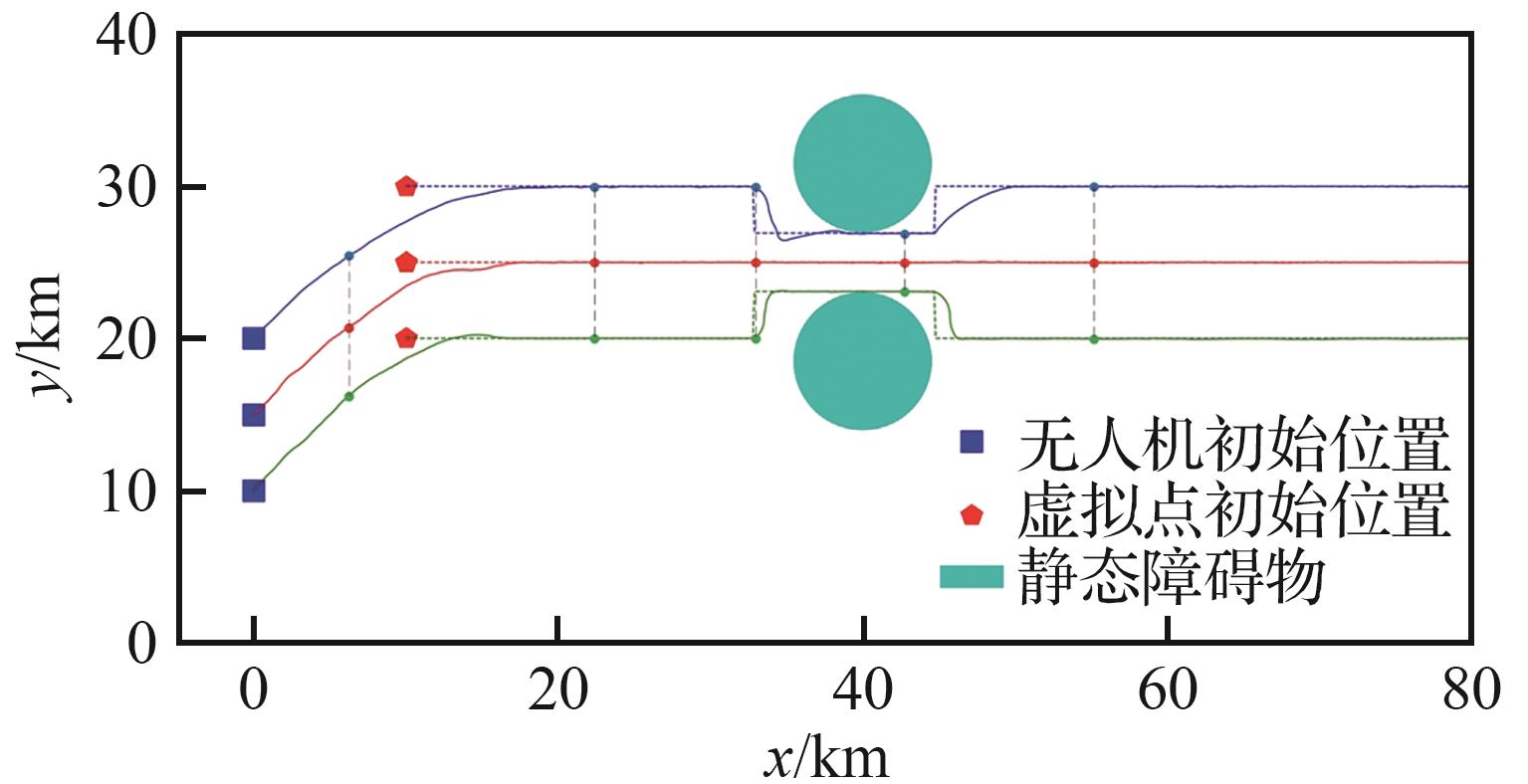
Fig.9
UAV’s flight path of Submodel 2
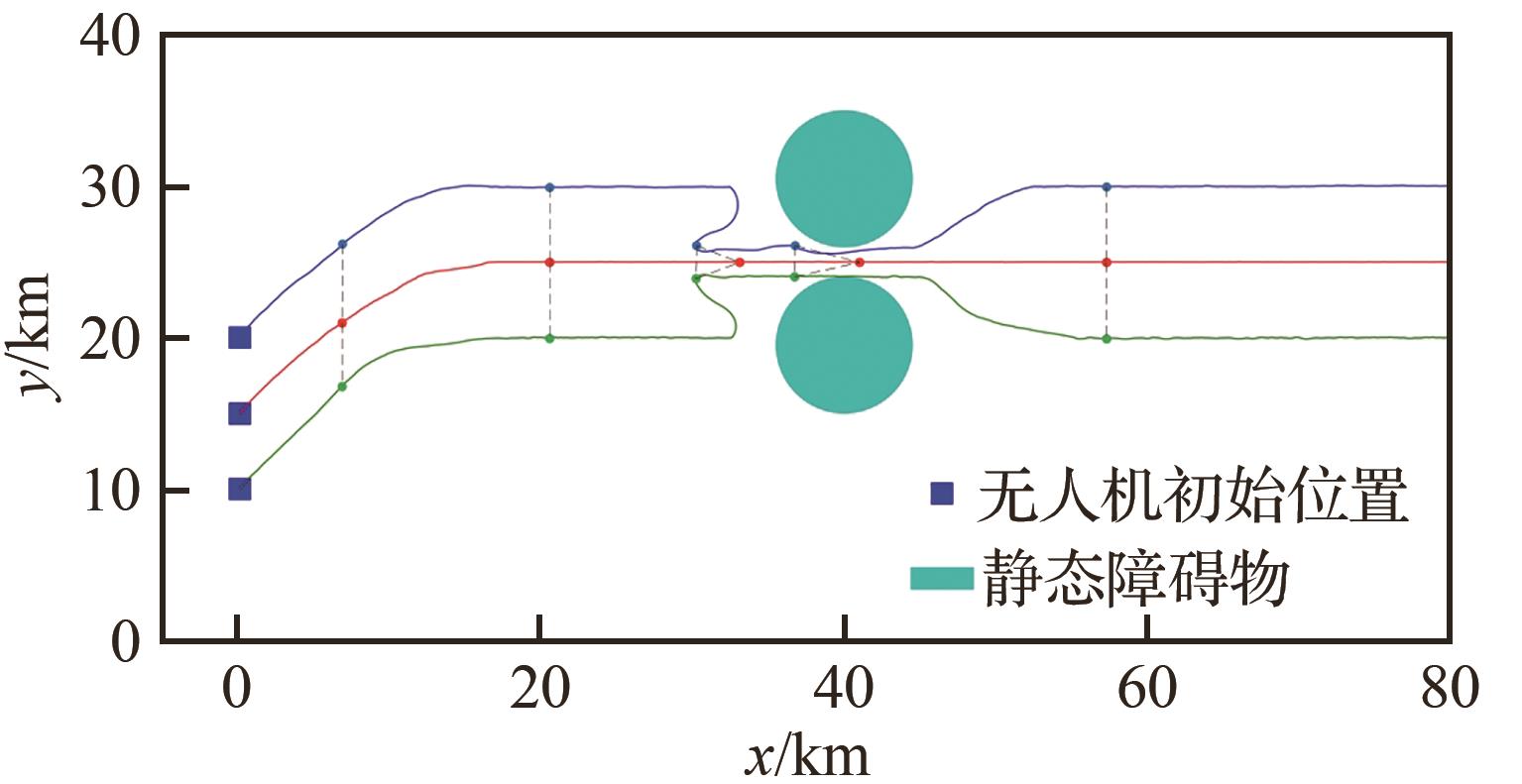
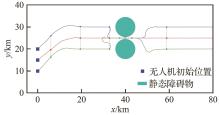
Fig.10
UAVs’ flight path of Submodel 3
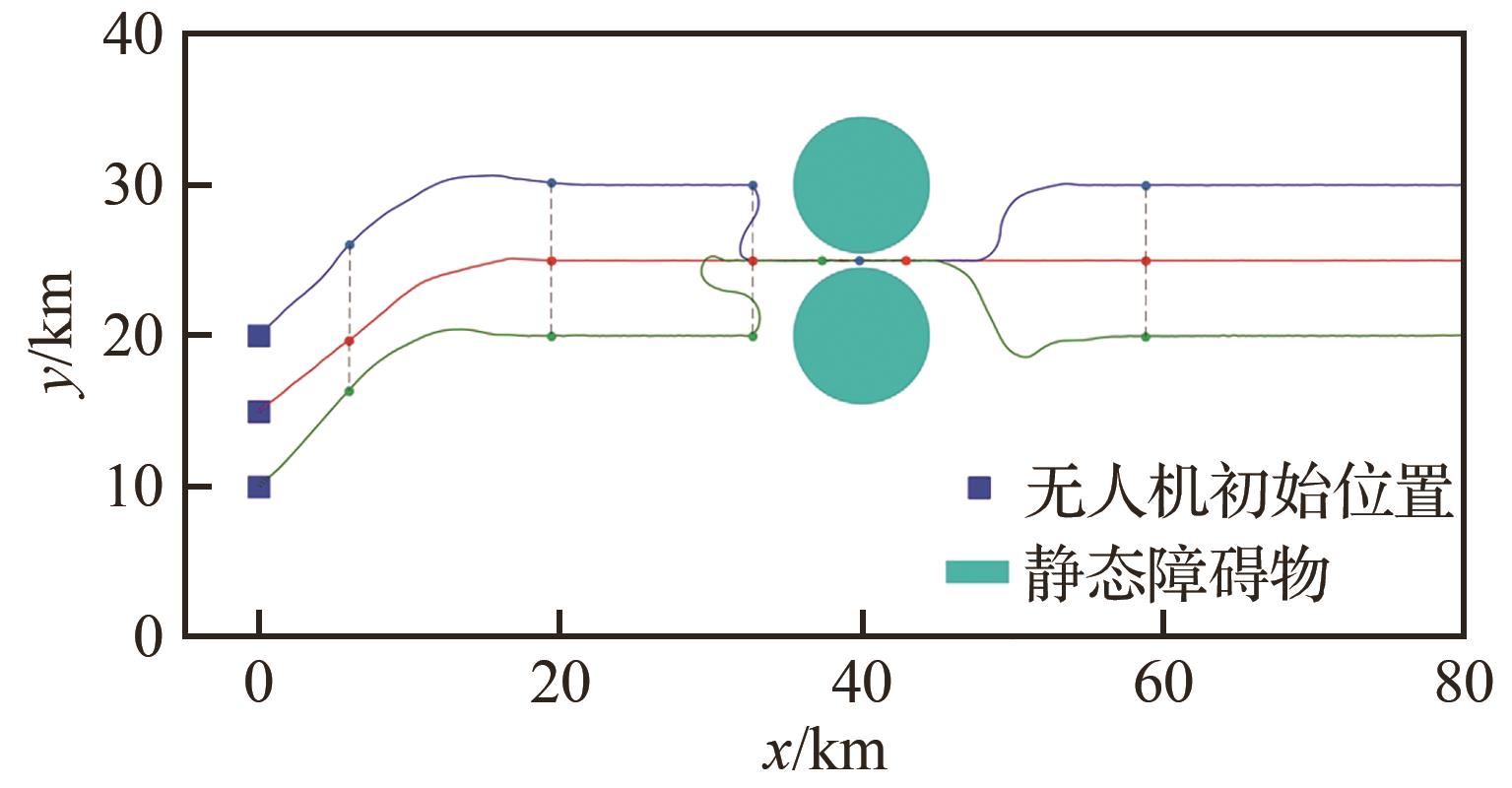
Fig.11
UAVs’ training curve of Submodel 4
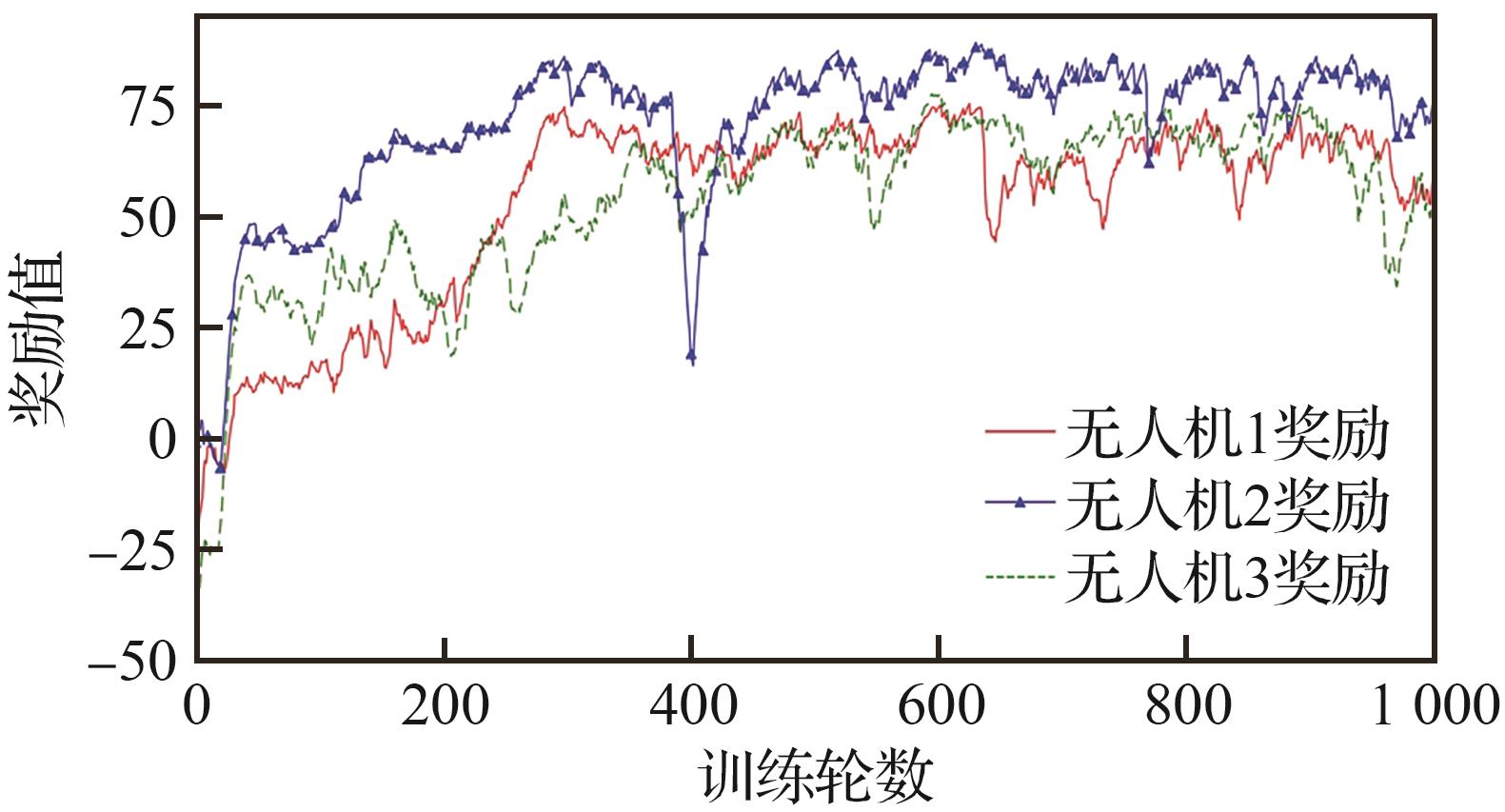
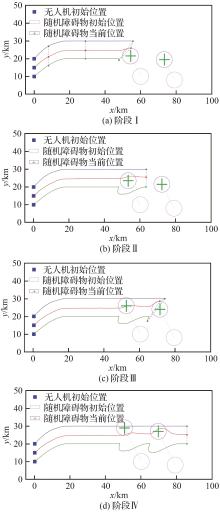
Fig.12
UAVs’ flight process trajectory of Submodel 4
Fig.13
UAVs’ training curve of Submodel 5
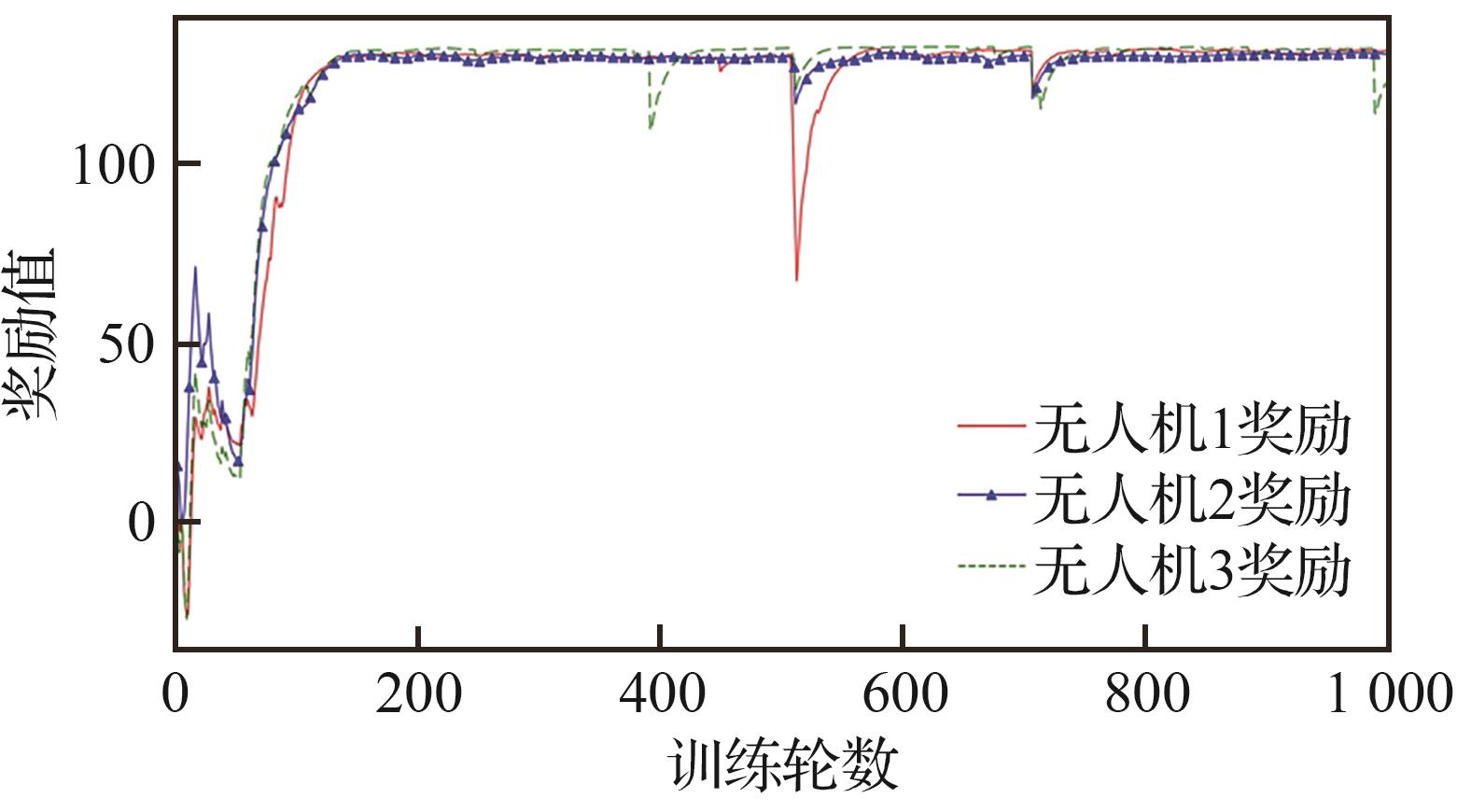
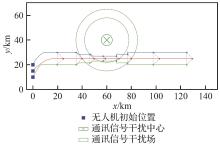
Fig.14
UAVs’ flight path of Submodel 5
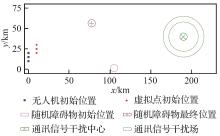
Fig.15
Training scenarios of different methods
Fig.16
Training curves of different methods
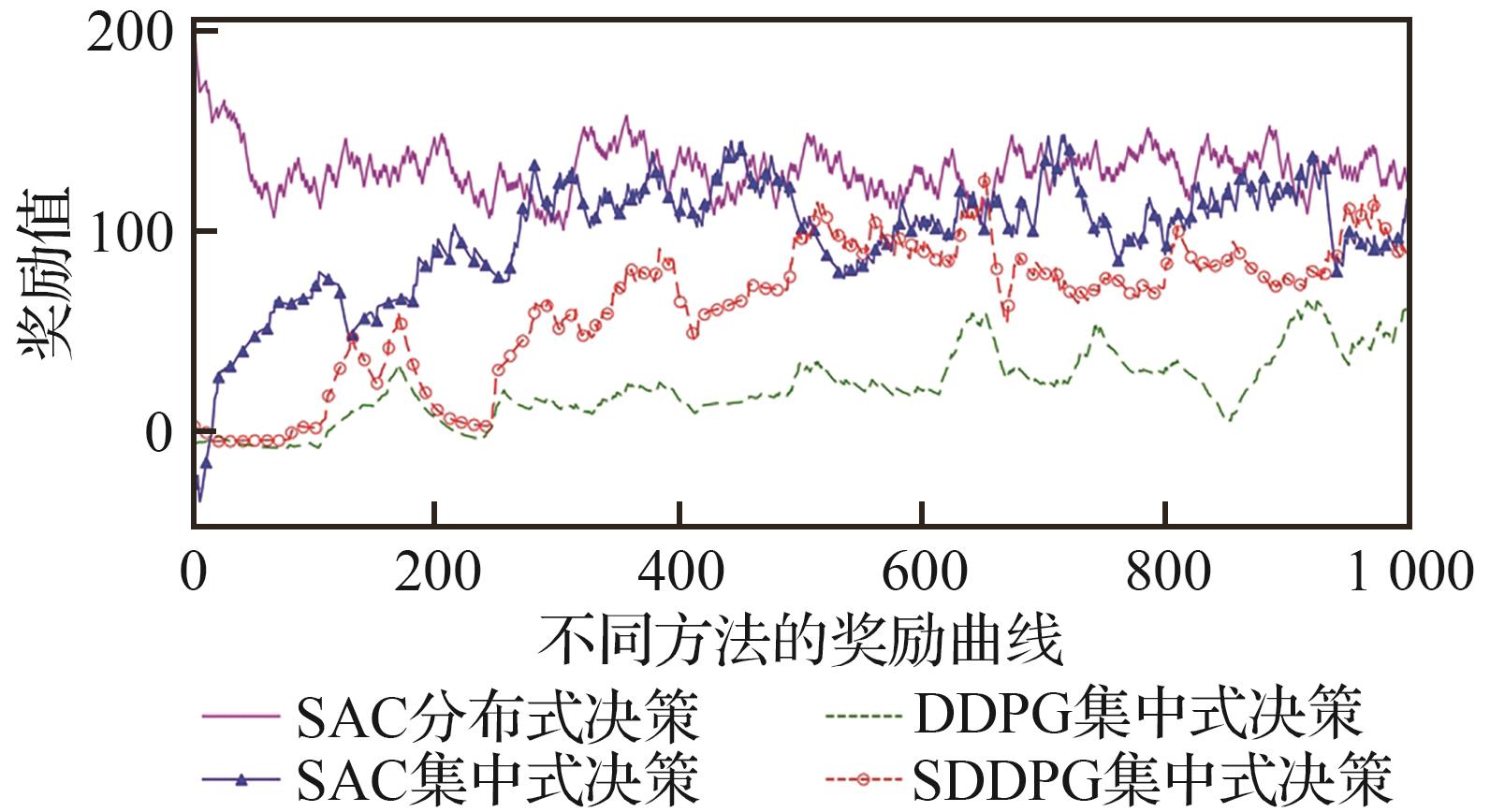
Fig.17
Distributed decision-making of VS-SAC in integrated task scenarios
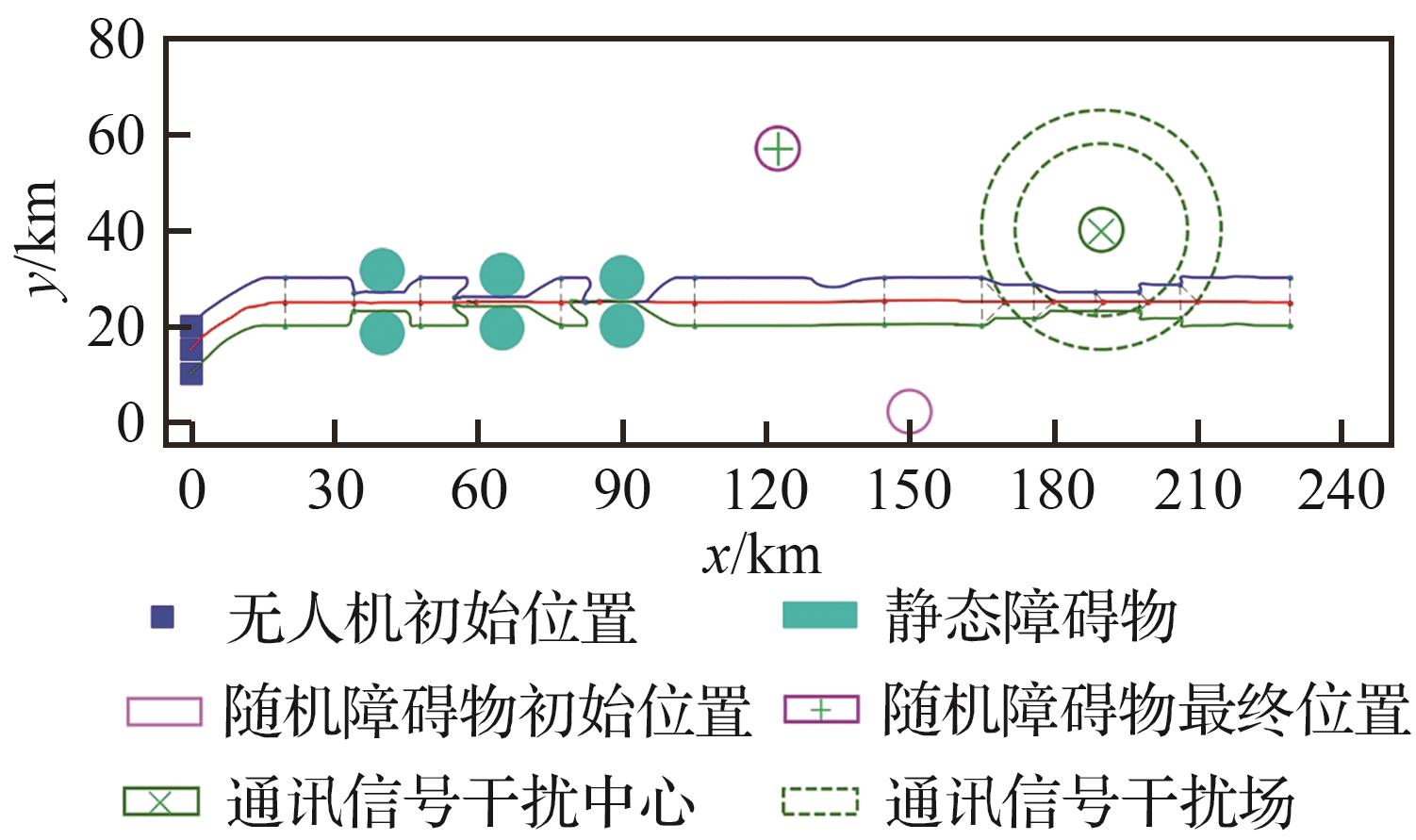
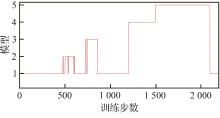
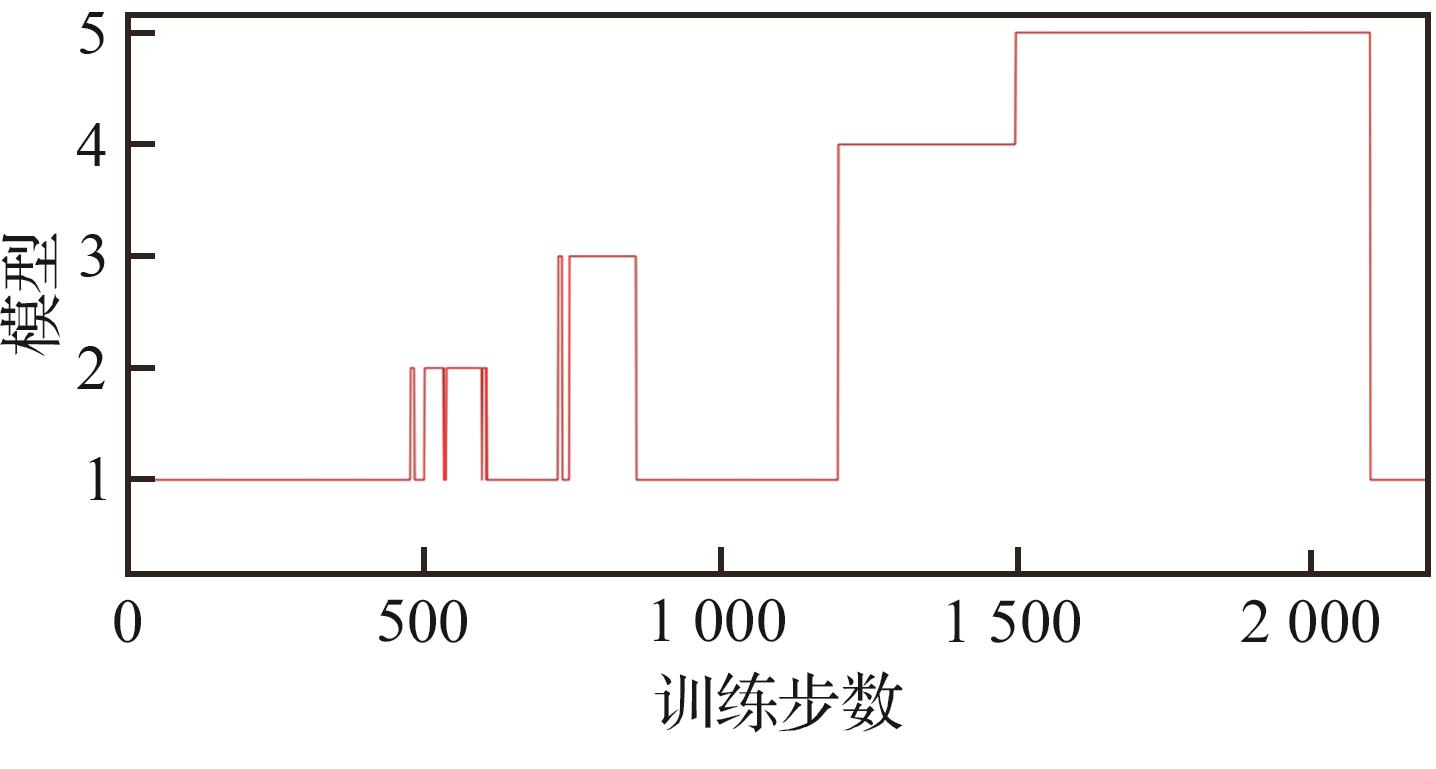
Fig.18
VS-SAC distributed decision model switching
| [1] | 王琳, 张庆杰, 陈宏伟. 基于领航者跟随者的群系统保性能编队控制[J]. 北京航空航天大学学报, 2024, 50(3): 1037-1046. |
| WANG L, ZHANG Q J, CHEN H W. Guaranteed-performance formation control of swarm systems based on leader-follower strategy[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(3): 1037-1046 (in Chinese). | |
| [2] | 彭建帅, 付兴建. 仿雁群行为的领航-跟随无人机编队控制[J]. 控制工程, 2023, 30(1): 113-118. |
| PENG J S, FU X J. Formation control of leader-follower UAV based on the behavior of geese swarm[J]. Control Engineering of China, 2023, 30(1): 113-118 (in Chinese). | |
| [3] | 吴立尧, 韩维, 张勇, 等. 基于领航-跟随的有人/无人机编队队形保持控制[J]. 控制与决策, 2021, 36(10): 2435-2441. |
| WU L Y, HAN W, ZHANG Y, et al. Formation keeping control for manned/unmanned aerial vehicle formation based on leader-follower strategy[J]. Control and Decision, 2021, 36(10): 2435-2441 (in Chinese). | |
| [4] | 李正平, 鲜斌. 基于虚拟结构法的分布式多无人机鲁棒编队控制[J]. 控制理论与应用, 2020, 37(11): 2423-2431. |
| LI Z P, XIAN B. Robust distributed formation control of multiple unmanned aerial vehicles based on virtual structure[J]. Control Theory & Applications, 2020, 37(11): 2423-2431 (in Chinese). | |
| [5] | 黄勇, 李小将, 杨业伟, 等. 应用虚拟结构的卫星编队飞行自适应协同控制[J]. 中国空间科学技术, 2015, 35(3): 75-83. |
| HUANG Y, LI X J, YANG Y W, et al. Adaptive cooperative control for satellites formation flying using virtual structure[J]. Chinese Space Science and Technology, 2015, 35(3): 75-83 (in Chinese). | |
| [6] | GUO J D, LIU Z G, SONG Y G, et al. Research on multi-UAV formation and semi-physical simulation with virtual structure[J]. IEEE Access, 2023, 11: 126027-126039. |
| [7] | LIU Y P, CHEN C, WANG Y, et al. A fast formation obstacle avoidance algorithm for clustered UAVs based on artificial potential field[J]. Aerospace Science and Technology, 2024, 147: 108974. |
| [8] | 高运克, 唐宏伟, 高方坤, 等. 无线紫外光通信下基于改进人工势场法的无人机编队控制研究[J]. 电气传动自动化, 2023, 45(6): 6-12, 5. |
| GAO Y K, TANG H W, GAO F K, et al. Research on UAV formation control based on improved artificial potential field method[J]. Electric Drive Automation, 2023, 45(6): 6-12, 5 (in Chinese). | |
| [9] | 陈博琛, 唐文兵, 黄鸿云, 等. 基于改进人工势场的未知障碍物无人机编队避障[J]. 计算机科学, 2022, 49(S1): 686-693. |
| CHEN B C, TANG W B, HUANG H Y, et al. Pop-up obstacles avoidance for UAV formation based on improved artificial potential field[J]. Computer Science, 2022, 49(S1): 686-693 (in Chinese). | |
| [10] | 葛宇, 廖煜雷, 王博, 等. 基于零空间行为融合的多智能体编队控制综述[J]. 哈尔滨工程大学学报, 2024, 45(8): 1442-1450. |
| GE Y, LIAO Y L, WANG B, et al. A review of multiagent formation control based on the null-space-based behavioral fusion algorithm[J]. Journal of Harbin Engineering University, 2024, 45(8): 1442-1450 (in Chinese). | |
| [11] | TAN G G, ZHUANG J Y, ZOU J, et al. Coordination control for multiple unmanned surface vehicles using hybrid behavior-based method[J]. Ocean Engineering, 2021, 232: 109147. |
| [12] | HACENE N, MENDIL B. Behavior-based autonomous navigation and formation control of mobile robots in unknown cluttered dynamic environments with dynamic target tracking[J]. International Journal of Automation and Computing, 2021, 18(5): 766-786. |
| [13] | GUO M, JAYAWARDHANA B, LEE J, et al. Maintaining and steering a formation in an unknown dynamic environment via a consistent distributed dynamic map[J]. International Journal of Robust and Nonlinear Control, 2024, 34(13): 8785-8801. |
| [14] | PEI H Q, LAN Z Y. Multi-agent consistent formation control operation optimization for high-speed trains[J]. IEEE Access, 2023, 11: 139201-139210. |
| [15] | LIU W J, LYU S K, LIU T, et al. Multi-target optimization strategy for unmanned aerial vehicle formation in forest fire monitoring based on deep Q-network algorithm[J]. Drones, 2024, 8(5): 201. |
| [16] | 赵启, 甄子洋, 龚华军, 等. 基于D3QN的无人机编队控制技术[J]. 北京航空航天大学学报, 2023, 49(8): 2137-2146. |
| ZHAO Q, ZHEN Z Y, GONG H J, et al. UAV formation control based on dueling double DQN[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(8): 2137-2146 (in Chinese). | |
| [17] | 黄号, 马文卉, 李家诚, 等. 未知环境下无人机编队智能避障控制方法[J]. 清华大学学报(自然科学版), 2024, 64(2): 358-369. |
| HUANG H, MA W H, LI J C, et al. Intelligent obstacle avoidance control method for unmanned aerial vehicle formations in unknown environments[J]. Journal of Tsinghua University (Science and Technology), 2024, 64(2): 358-369 (in Chinese). | |
| [18] | XU D, GUO Y X, YU Z Y, et al. PPO-exp: Keeping fixed-wing UAV formation with deep reinforcement learning[J]. Drones, 2023, 7(1): 28. |
| [19] | LI Y D, YUAN Y L, CHENG Y, et al. Predictive air combat decision model with segmented reward allocation[J]. Complex & Intelligent Systems, 2024, 10(6): 7513-7530. |
| [20] | ZHOU Y X, SHU J S, HAO H, et al. UAV 3D online track planning based on improved SAC algorithm[J]. Journal of the Brazilian Society of Mechanical Sciences and Engineering, 2023, 46(1): 12. |
| [21] | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[DB/OL]. arXiv preprint: 1801.01290; 2018. |
| [22] | HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[DB/OL]. arXiv preprint, 1812.05905; 2018. |
| [23] | LEVINE S, KUMAR A, TUCKER G, et al. Offline reinforcement learning: Tutorial, review, and perspectives on open problems[DB/OL]. arXiv preprint: 2005.01643; 2020. |
| [24] | ZHANG L J, PENG J B, YI W G, et al. A state-decomposition DDPG algorithm for UAV autonomous navigation in 3-D complex environments[J]. IEEE Internet of Things Journal, 2024, 11(6): 10778-10790. |
| [1] | Kaifang WAN, Zhilin WU, Yunhui WU, Haozhi QIANG, Yibo WU, Bo LI. Cooperative location of multiple UAVs with deep reinforcement learning in GPS-denied environment [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331024-331024. |
| [2] | Lingfeng JIANG, Xinkai LI, Hai ZHANG, Hanwei LI, Hongli ZHANG. Mapless navigation of UAVs in dynamic environments based on an improved TD3 algorithm [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331035-331035. |
| [3] | Min YANG, Guanjun LIU, Ziyuan ZHOU. Control of lunar landers based on secure reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(3): 630553-630553. |
| [4] | Wei CHEN, Lulu LI, Dong CHEN, Shaohui ZHANG, Yafei LI, Ke WANG, Yuanyuan JIN, Mingliang XU. Multi-aircraft cooperative decision-making methods driven by differentiated support demands for carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531274-531274. |
| [5] | Xudong CHEN, Qiqi CHEN, Yizhe LUO, Jiabao WANG, Mingliang XU. Dynamic parallel scheduling of heterogeneous carrier-based aircraft deck support operations [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531329-531329. |
| [6] | Zheng WANG, Hua WANG, Keke CUI, Chaochao LI, Junnan LIU, Mingliang XU. Locally guided reinforcement learning for autonomous dispatching of carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531333-531333. |
| [7] | Wenhui LING, Chunhui MU, Lingcong NIE, Xian DU, Ximing SUN. Improved DDPG-based multipoint pressure distribution control of variable geometry scramjet combustor at wide range velocities [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(12): 131092-131092. |
| [8] | Zijie YU, Zheng ZHENG, Qingdong LI, Lin GUO, Suping REN, Jian GUO. Trajectory planning for solar-powered UAVs based on deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(12): 331420-331420. |
| [9] | Shuyi GAO, Defu LIN, Duo ZHENG, Cheng XU. Intelligent maneuvering penetration guidance strategies for aerial vehicles considering interceptor detection capability limitations [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(10): 331304-331304. |
| [10] | Honglin ZHANG, Jianjun LUO, Weihua MA. Spacecraft game decision making for threat avoidance of space targets based on machine learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329136-329136. |
| [11] | Yunpeng CAI, Dapeng ZHOU, Jiangchuan DING. Intelligent collaborative control of UAV swarms with collision avoidance safety constraints [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(5): 529683-529683. |
| [12] | Shengzhe SHAN, Weiwei ZHANG. Air combat intelligent decision-making method based on self-play and deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(4): 328723-328723. |
| [13] | Bing GAO, Zhejie ZHANG, Qijie ZOU, Zhiguo LIU, Xiling ZHAO. Multi-agent communication cooperation based on deep reinforcement learning and information theory [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(18): 329862-329862. |
| [14] | Zuolong LI, Jihong ZHU, Minchi KUANG, Jie ZHANG, Jie REN. Hierarchical decision algorithm for air combat with hybrid action based on deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(17): 530053-530053. |
| [15] | Tiancai WU, Honglun WANG, Bin REN, Yiheng LIU, Xingyu WU, Guocheng YAN. Learning-based integrated fault-tolerant guidance and control for hypersonic vehicles considering avoidance and penetration [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(15): 329607-329607. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341