Acta Aeronautica et Astronautica Sinica ›› 2023, Vol. 44 ›› Issue (18): 328301-328301.doi: 10.7527/S1000-6893.2023.28301
• Electronics and Electrical Engineering and Control • Previous Articles Next Articles
Shuyi GAO1, Defu LIN1, Duo ZHENG1( ), Xinyu HU2
), Xinyu HU2
Received:2022-11-23
Revised:2022-12-20
Accepted:2023-02-22
Online:2023-09-25
Published:2023-03-03
Contact:
Duo ZHENG
E-mail:zhengduohello@126.com
Supported by:CLC Number:
Shuyi GAO, Defu LIN, Duo ZHENG, Xinyu HU. Intelligent cooperative interception strategy of aircraft against cluster attack[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(18): 328301-328301.
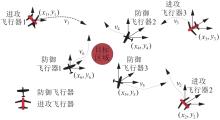
Fig.1
Multi-aircraft interception game problem
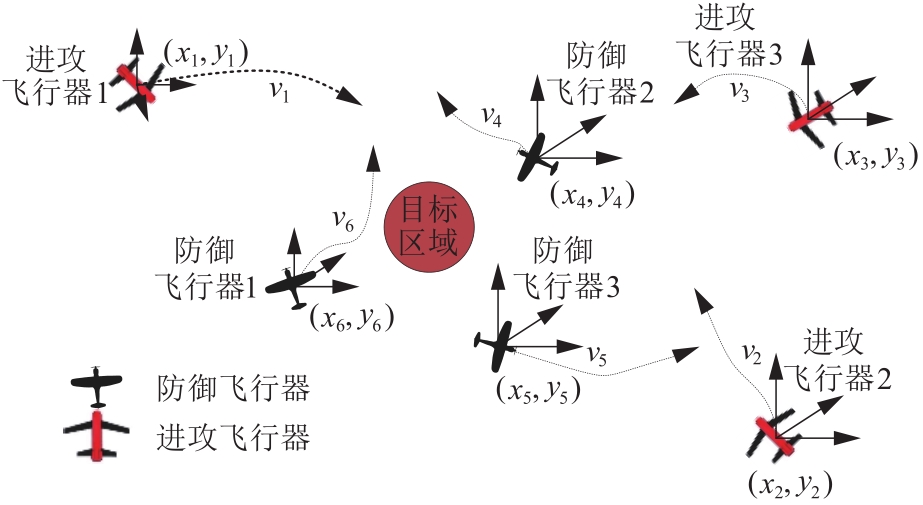
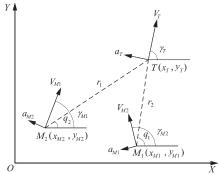
Fig.2
2D plane collaborative interception scenario
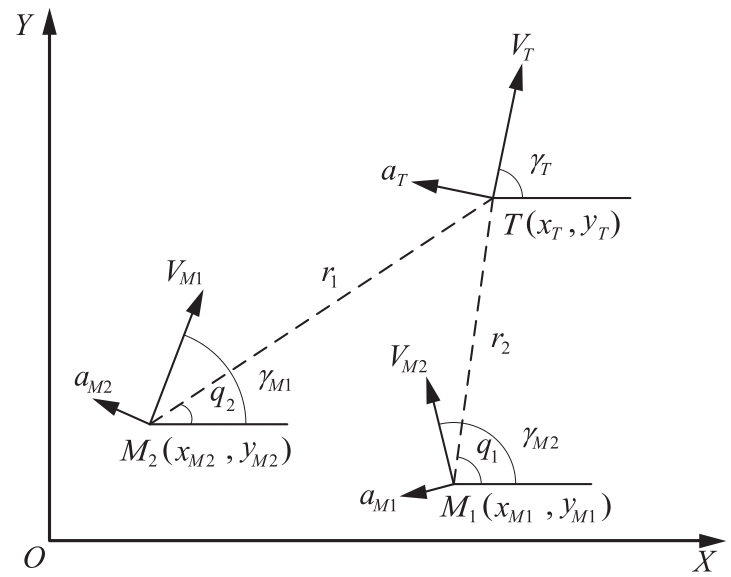
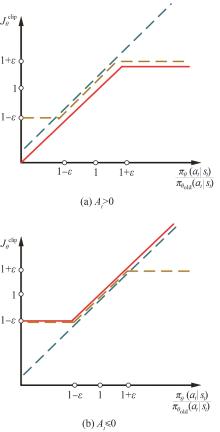
Fig.3
clip algorithm model
Fig.4
Centralized evaluation distributed execution algorithm framework
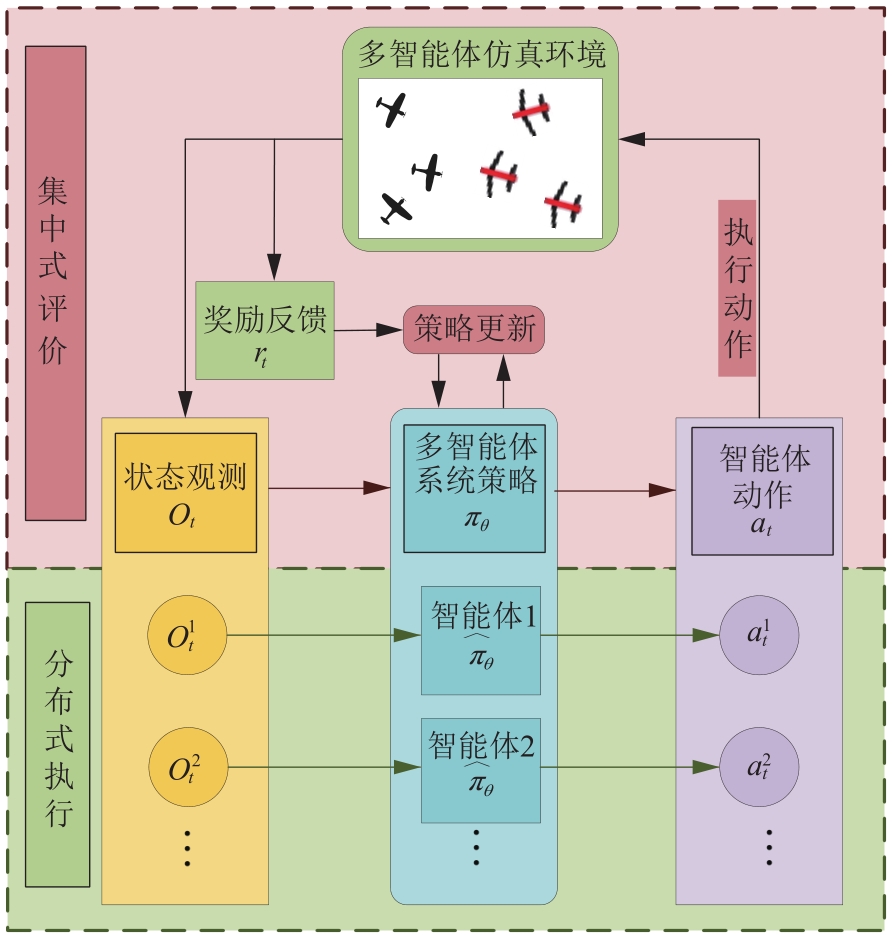
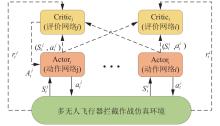
Fig.5
Multi⁃agent deep reinforcement learning algorithm model
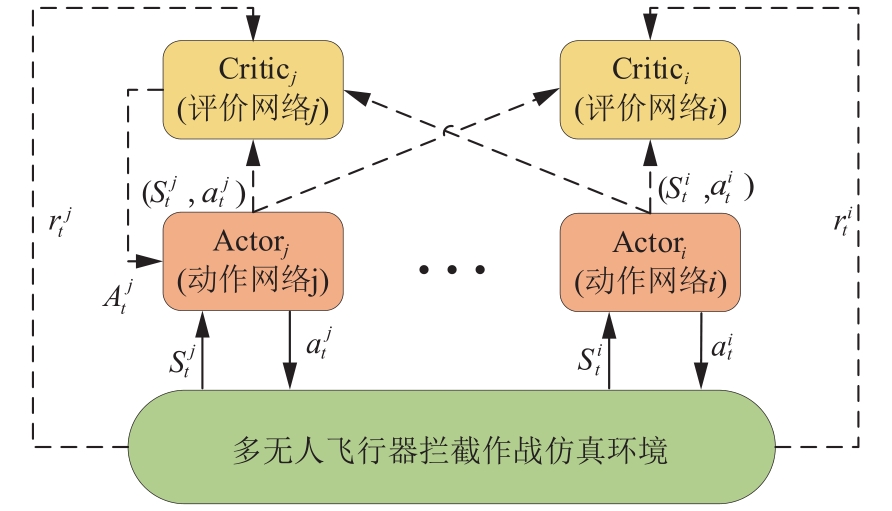
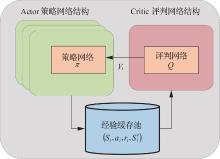
Fig.6
Algorithm architecture

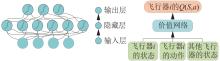
Fig.7
Value function neural network
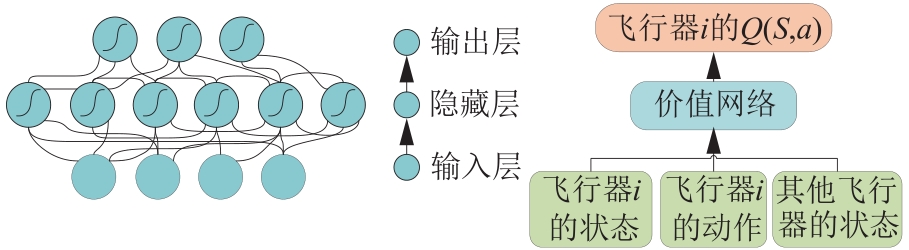
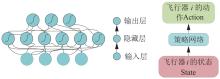
Fig.8
Strategic neural network

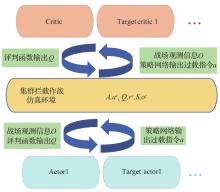
Fig.9
Markov modeling of operational scenario
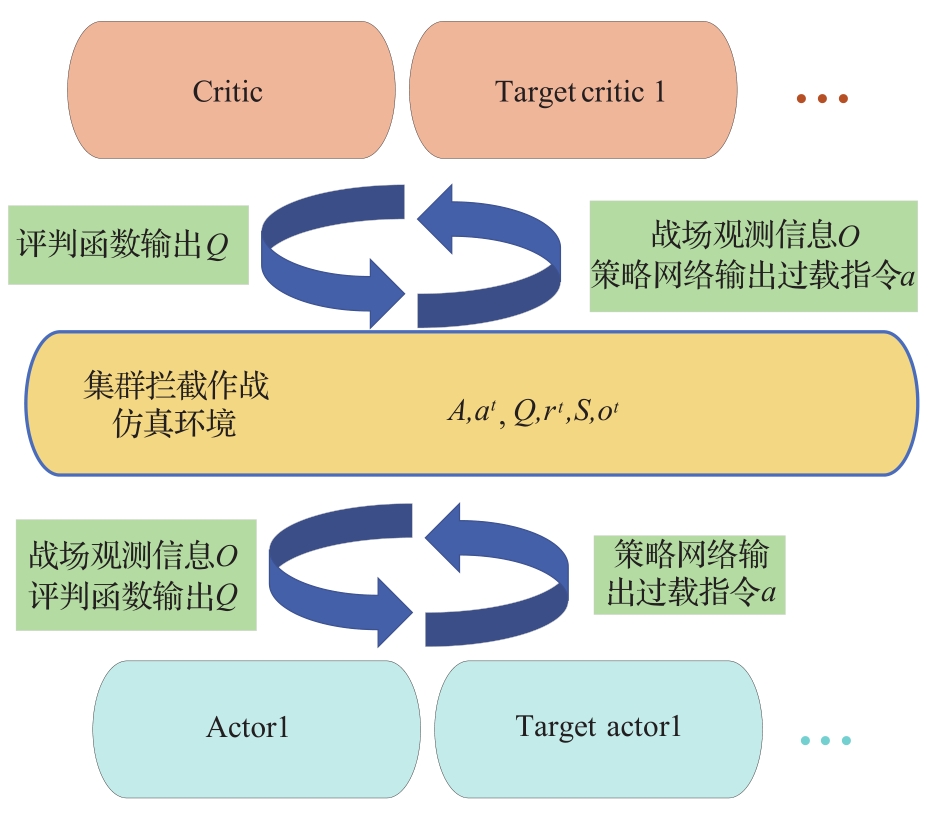
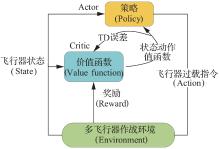
Fig.10
Reinforcement learning process
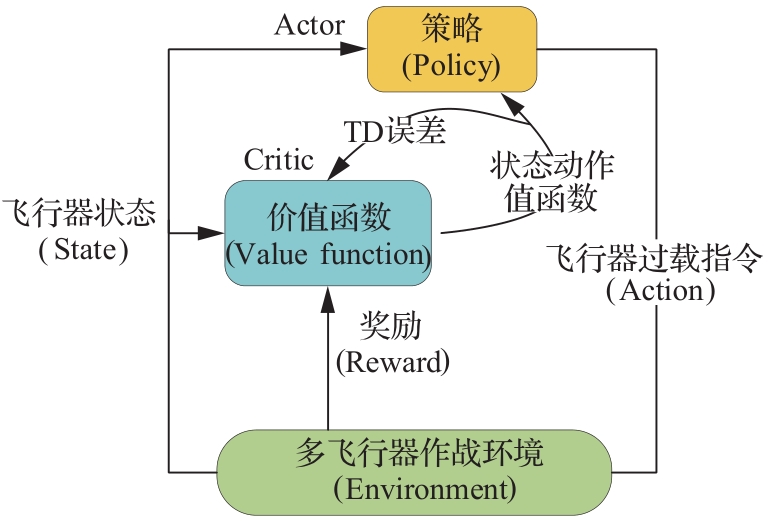
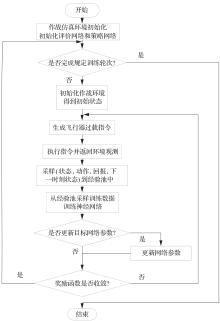
Fig.11
Algorithm training flow chart
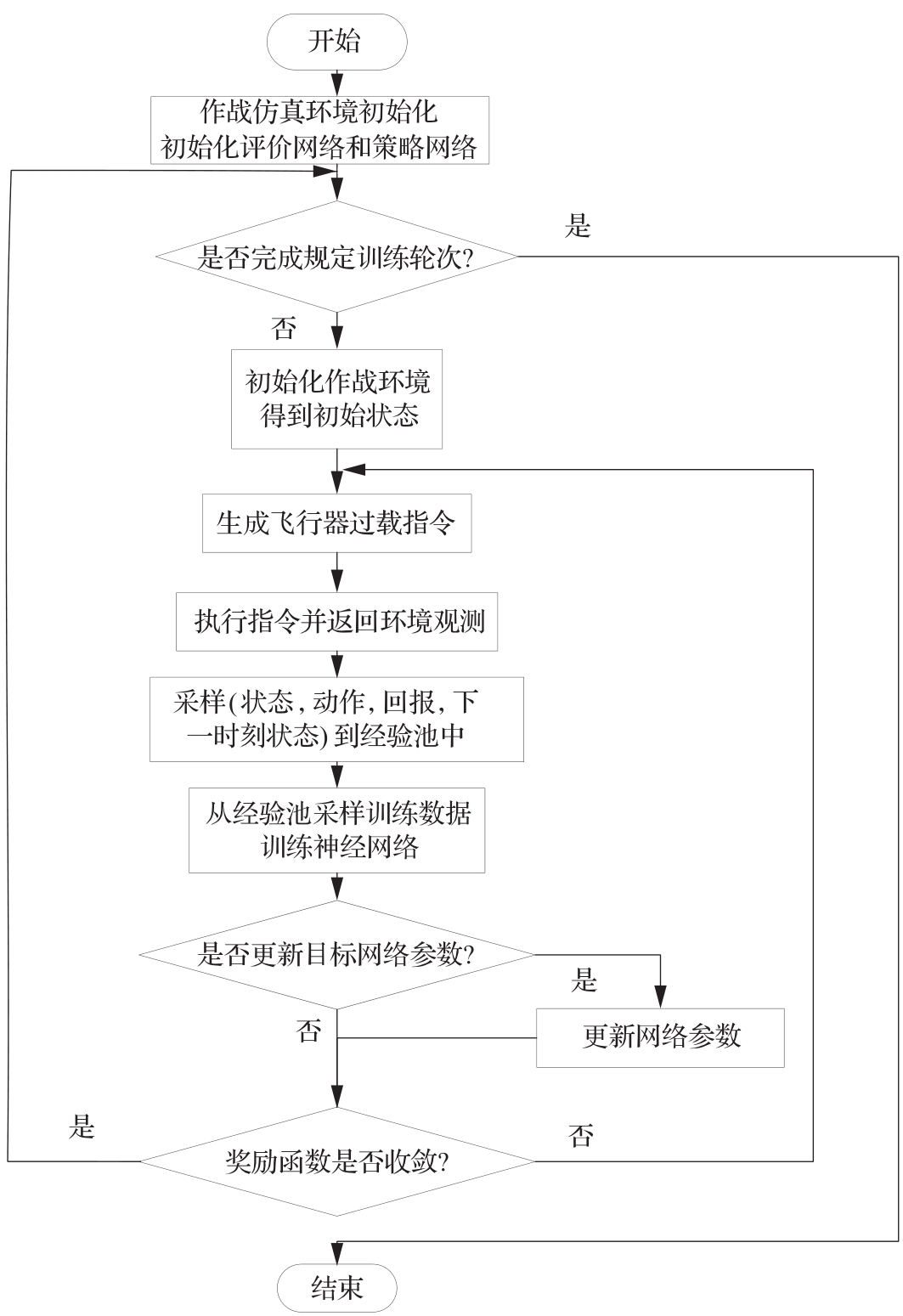
Table 1
Setting of algorithm training parameters
| 参数 | 数值 |
|---|---|
| PPO裁剪系数 | 0.2 |
| 熵奖励系数 | 0.02 |
| GAE参数 | 0.98 |
| 衰减因子 | 0.998 |
| 神经网络优化器 | Adam |
| Mini_batch数量 | 4 |
| 缓存区大小 | 4 096 |
| 学习率 | 0.000 3 |
Fig.12
Reward function curve of our algorithm
Fig.13
Reward function curve of MADDPG
Table 2
Operational scenario setting
| 场景 | 防御飞行器数量 | 进攻飞行器数量 | 防护目标数量 |
|---|---|---|---|
| 1 | 5 | 1 | 1 |
| 2 | 5 | 2 | 1 |
| 3 | 5 | 3 | 1 |
| 4 | 5 | 4 | 1 |
Table 3
Simulation environment parameters
| 防御vs进攻 | 防御飞行器 | 进攻飞行器 | 目标位置/m | ||||
|---|---|---|---|---|---|---|---|
| 初始位置/m | 初始速度 /(m·s-1) | 初始航向角 /rad | 初始位置/m | 初始速度 /(m·s-1) | 初始航向角 /rad | ||
| 5 vs 1 | (74.8,101.5) | 18.1 | 0.02 | (578.2,321.3) | 16.1 | -2.18 | (99.3,135.3) |
| (69.4,95.6) | 19.5 | -0.34 | |||||
| (98.7,100.5) | 19.4 | -0.29 | |||||
| (81.9,63.5) | 17.2 | -0.47 | |||||
| (76.7,151.5) | 18.1 | -0.26 | |||||
| 5 vs 2 | (-72.8,131.2) | 17.3 | -0.71 | (187.2,-411.6) (-593,121.8) | 18.7 19.3 | 2.33 -0.56 | (33.5,145.3) |
| (-87.3,56.9) | 17.6 | -1.28 | |||||
| (-97.9,65.2) | 18.1 | 3.27 | |||||
| (-17.5,6.6) | 18.7 | 2.75 | |||||
| (-99.6,89.4) | 15.9 | 2.91 | |||||
| 5 vs 3 | (-117.4,2.5) | 17.9 | 0.71 | (621.2,263.2) (93.7,-571.3) (-183.6,-493.2) | 20.8 16.3 17.9 | -2.38 1.58 1.33 | (-21.7,112.7) |
| (37.4,26.6) | 17.5 | 0.14 | |||||
| (87.7,71.5) | 18.5 | -1.41 | |||||
| (56.9,47.5) | 20.3 | -1.87 | |||||
| (57.7,-2.5) | 16.1 | -2.16 | |||||
| 5 vs 4 | (-31.4,39.5) | 17.1 | -0.41 | (541.2,-188.5) (-331.8,531) (-119.2,-421.1) (468.4,438.2) | 21.4 22.5 17.3 15.6 | 2.89 -1.16 1.36 -2.13 | (-1.5,193.9) |
| (-53.4,38.6) | 16.8 | -0.26 | |||||
| (-19.7,12.5) | 20.3 | 2.51 | |||||
| (-135.9,40.5) | 16.9 | -1.86 | |||||
| (-11.7,93.5) | 20.5 | 1.13 | |||||

Fig.14
5 defense vs 1 attack cooperative intercept countermeasure simulation results
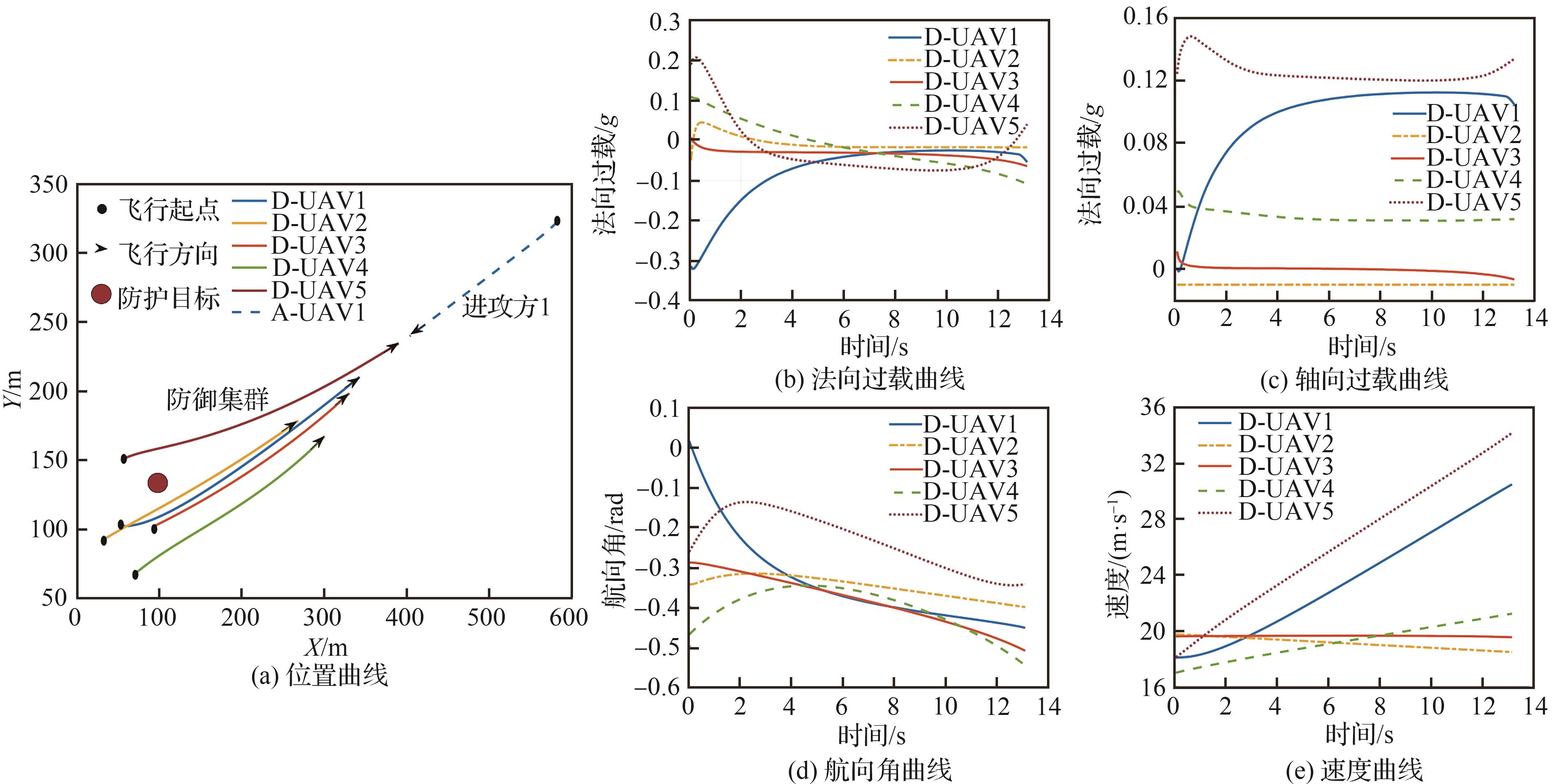

Fig.15
5 defense vs 2 attack cooperative intercept countermeasure simulation results
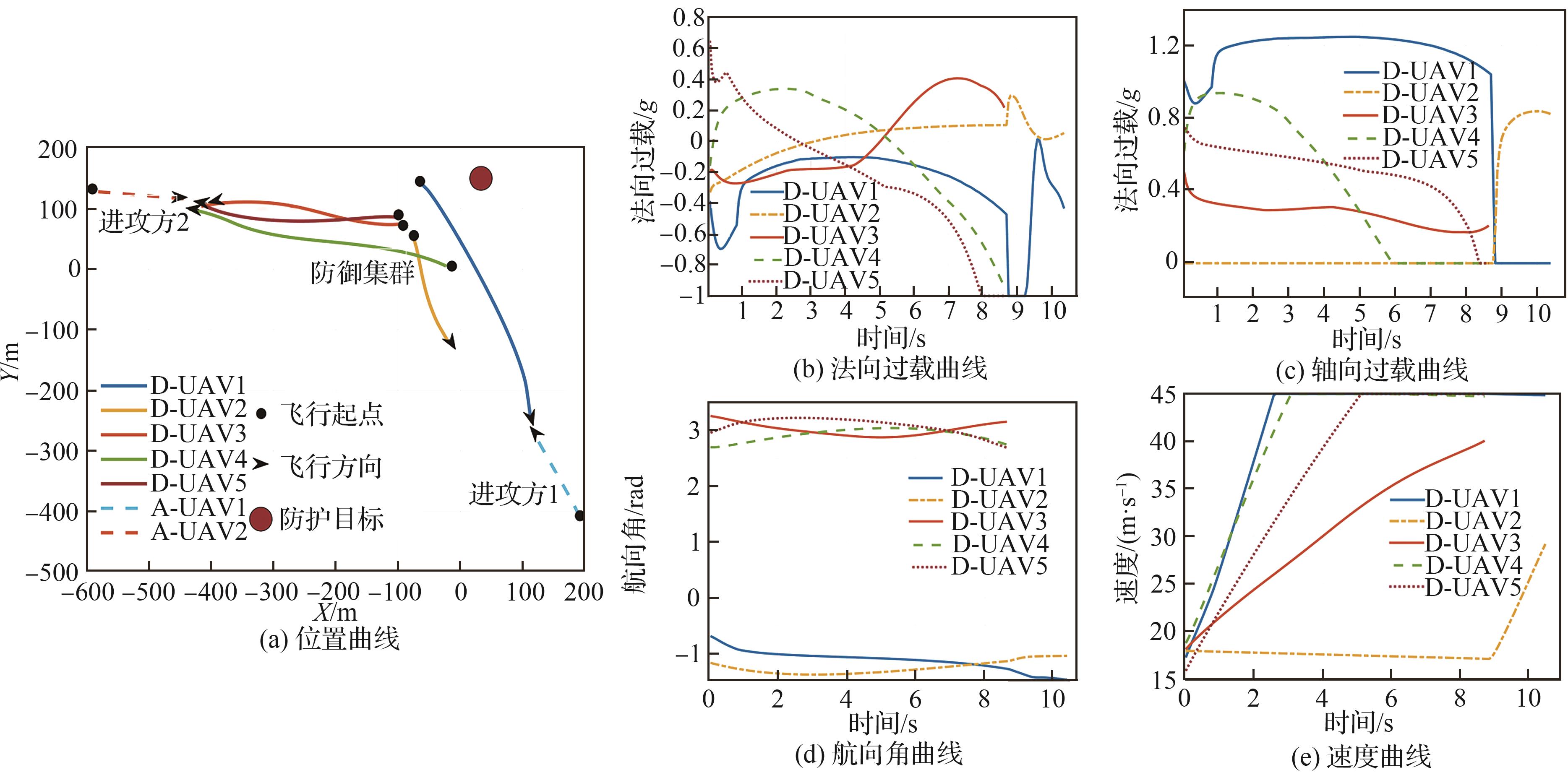

Fig.16
5 defense vs 3 attack cooperative intercept countermeasure simulation results
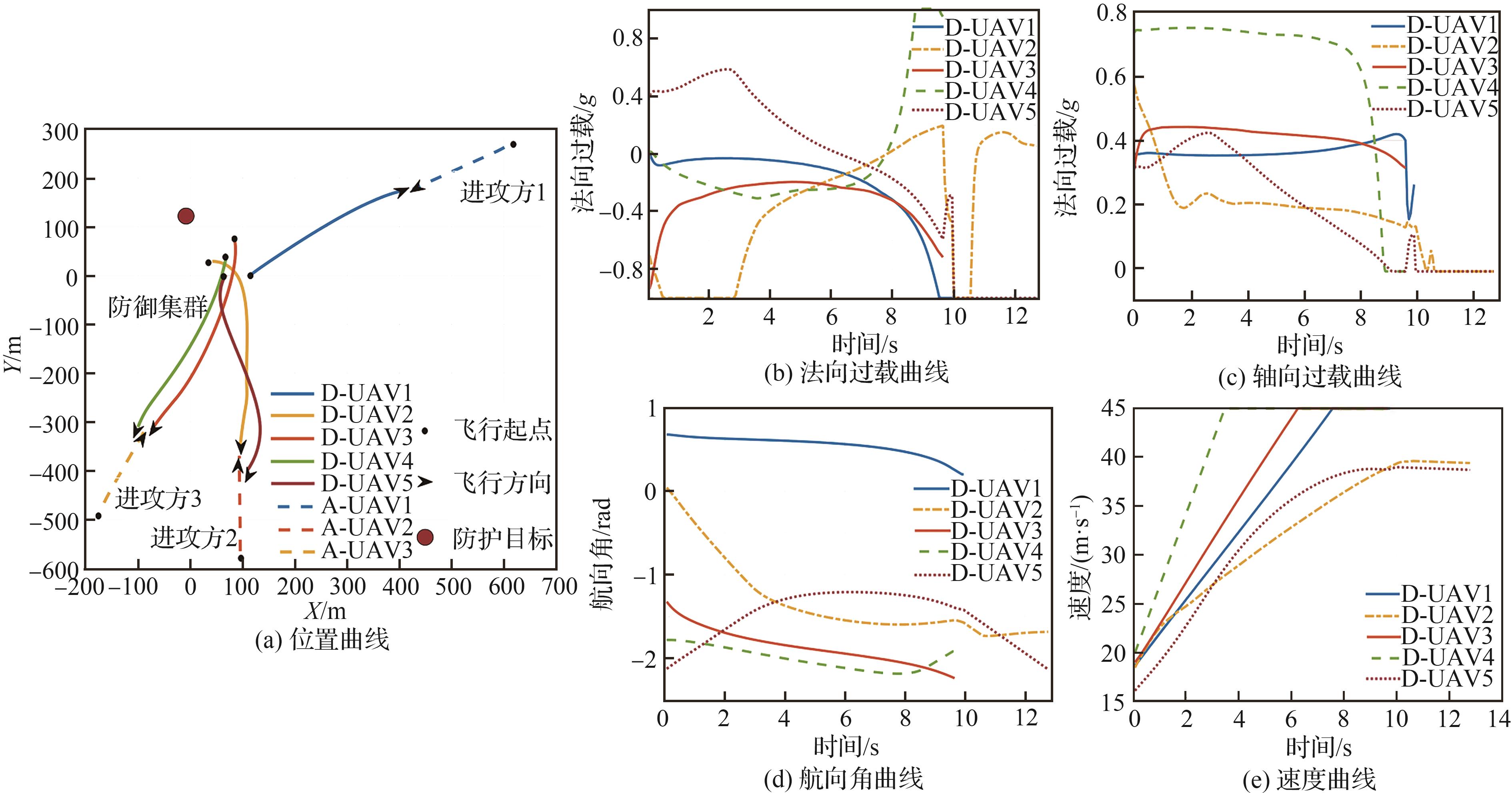
Table 4
Task allocation
| 防御方 | 智能任务分配 | |||
|---|---|---|---|---|
| 1架进攻 | 2架进攻 | 3架进攻 | 4架进攻 | |
| D-UAV1 | A-UAV1 | A-UAV2 | A-UAV2 | A-UAV1 |
| D-UAV2 | A-UAV1 | A-UAV1 | A-UAV1 | A-UAV1 |
| D-UAV3 | A-UAV1 | A-UAV2 | A-UAV1 | A-UAV2 |
| D-UAV4 | A-UAV1 | A-UAV2 | A-UAV2 | A-UAV3 |
| D-UAV5 | A-UAV1 | A-UAV2 | A-UAV3 | A-UAV4 |

Fig.17
5 Defense vs 4 attack cooperative intercept countermeasure simulation resultsTask allocation
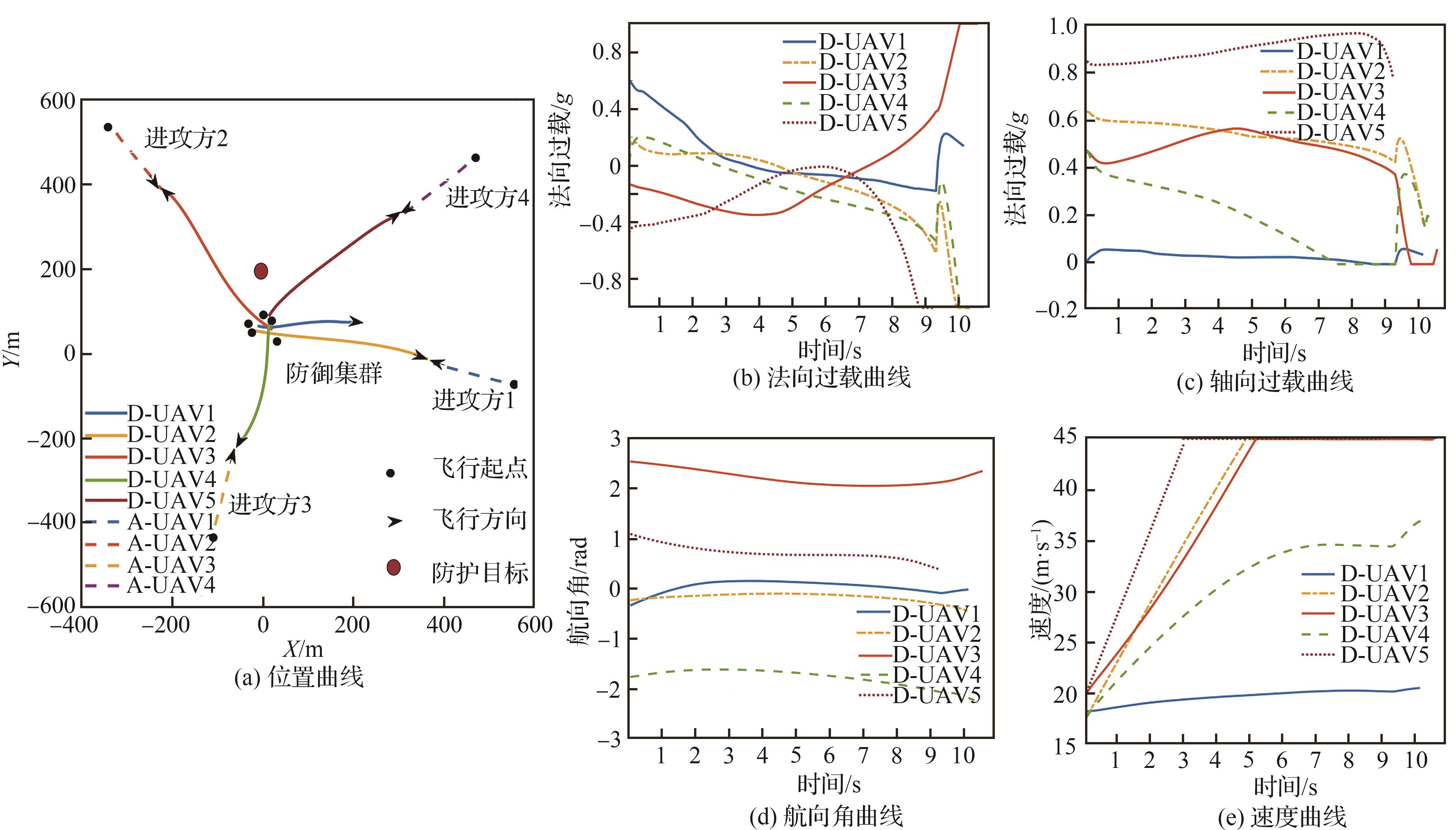
Table 5
1 000 battle simulation results statistics
| 防御vs进攻 | 成功率/% | 平均脱靶量/m |
|---|---|---|
| 5 vs 1 | 100 | 1.1 |
| 5 vs 2 | 84 | 1.7 |
| 5 vs 3 | 78 | 2.1 |
| 5 vs 4 | 70 | 2.8 |
| 1 | GUO D, LIANG Z X, JIANG P, et al. Weapon-target assignment for multi-to-multi interception with grouping constraint[J]. IEEE Access, 2019, 7: 34838-34849. |
| 2 | GUO J G, HU G J, GUO Z Y, et al. Evaluation model, intelligent assignment, and cooperative interception in multimissile and multitarget engagement[J]. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(4): 3104-3115. |
| 3 | KHOSRAVI M, AGHDAM A G. Cooperative receding horizon control for multi-target interception in uncertain environments[C]∥ 53rd IEEE Conference on Decision and Control. Piscataway: IEEE Press, 2015: 4497-4502. |
| 4 | MENG X Q, SUN B, ZHU D Q. Harbour protection: Moving invasion target interception for multi-AUV based on prediction planning interception method[J]. Ocean Engineering, 2021, 219: 108268. |
| 5 | SUN Z Y, YANG J Y. Multi-missile interception for multi-targets: Dynamic situation assessment, target allocation and cooperative interception in groups[J]. Journal of the Franklin Institute, 2022, 359(12): 5991-6022. |
| 6 | ZHU R, SUN D, ZHOU Z Y. Cooperation strategy of unmanned air vehicles for multitarget interception[J]. Journal of Guidance, Control, and Dynamics, 2005, 28(5): 1068-1072. |
| 7 | JEON I S, LEE J I, TAHK M J. Impact-time-control guidance law for anti-ship missiles[J]. IEEE Transactions on Control Systems Technology, 2006, 14(2): 260-266. |
| 8 | 吕腾,吕跃勇,李传江,等.带空间协同的多导弹时间协同制导律[J].航空学报,2018,39(10):322115. |
| LYU T, LYU Y Y, LI C J, et al. Time cooperative guidance law for multiple missiles with space coopera-tion [J]. Acta Aeronautica et Astronautica Sinica, 2018, 39(10): 322115 (in Chinese). | |
| 9 | SINHA A, KUMAR S R. Supertwisting control-based cooperative salvo guidance using leader-follower approach[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(5): 3556-3565. |
| 10 | ZHANG P, ZHANG X Y. Multiple missiles fixed-time cooperative guidance without measuring radial velocity for maneuvering targets interception[J]. ISA Transactions, 2022, 126: 388-397. |
| 11 | SHAFERMAN V, SHIMA T. Linear quadratic guidance laws for imposing a terminal intercept angle[J]. Journal of Guidance, Control, and Dynamics, 2008, 31(5): 1400-1412. |
| 12 | SUN X J, ZHOU R, HOU D L, et al. Consensus of leader-followers system of multi-missile with time-delays and switching topologies[J]. Optik, 2014, 125(3): 1202-1208. |
| 13 | ERER K, MERTTOPÇUOGLU O. Indirect control of impact angle against stationary targets using biased PPN: AIAA-2010-8184[R]. Reston: AIAA, 2010. |
| 14 | HARL N, BALAKRISHNAN S N. Impact time and angle guidance with sliding mode control[J]. IEEE Transactions on Control Systems Technology, 2012, 20(6): 1436-1449. |
| 15 | KUMAR S R, RAO S, GHOSE D. Nonsingular terminal sliding mode guidance with impact angle constraints[J]. Journal of Guidance, Control, and Dynamics, 2014, 37(4): 1114-1130. |
| 16 | DONG X F, REN Z. Impact angle constrained distributed cooperative guidance against maneuvering targets with undirected communication topologies[J]. IEEE Access, 2020, 8: 117867-117876. |
| 17 | KANG S, KIM H J. Differential game missile guidance with impact angle and time constraints[J]. IFAC Proceedings Volumes, 2011, 44(1): 3920-3925. |
| 18 | WANG B L, LI S G, GAO X Z, et al. UAV swarm confrontation using hierarchical multiagent reinforcement learning[J]. International Journal of Aerospace Engineering, 2021, 2021: 1-12. |
| 19 | 陈灿, 莫雳, 郑多, 等. 非对称机动能力多无人机智能协同攻防对抗[J]. 航空学报, 2020, 41(12): 324152. |
| CHEN C, MO L, ZHENG D, et al. Cooperative attack-defense game of multiple UAVs with asymmetric maneuverability[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(12): 324152 (in Chinese). | |
| 20 | IMADO F, KURODA T. Family of local solutions in a missile-aircraft differential game[J]. Journal of Guidance, Control, and Dynamics, 2011, 34(2): 583-591. |
| 21 | Bowling M, Veloso M. Rational and convergent learning in stochastic games[C]∥ International Joint Conference On Artificial Intelligence. Hillsdale: Lawrence Erlbaum Associates Ltd, 2001: 1021-1026. |
| 22 | 罗德林, 段海滨, 吴顺详, 等. 基于启发式蚁群算法的协同多目标攻击空战决策研究[J]. 航空学报, 2006, 27(6): 1166-1170. |
| LUO D L, DUAN H B, WU S X, et al. Research on air combat decision-making for cooperative multiple target attack using heuristic ant colony algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2006, 27(6): 1166-1170 (in Chinese). | |
| 23 | 裴培, 何绍溟, 王江, 等. 一种深度强化学习制导控制一体化算法[J]. 宇航学报, 2021, 42(10): 1293-1304. |
| PEI P, HE S M, WANG J, et al. Integrated guidance and control for missile using deep reinforcement learning[J]. Journal of Astronautics, 2021, 42(10): 1293-1304 (in Chinese). | |
| 24 | LEE S M, KIM H, MYUNG H, et al. Cooperative coevolutionary algorithm-based model predictive control guaranteeing stability of multirobot formation[J]. IEEE Transactions on Control Systems Technology, 2015, 23(1): 37-51. |
| 25 | WU X, LIU Y, XIE S R, et al. Collaborative defense with multiple USVs and UAVs based on swarm intelligence[J]. Journal of Shanghai Jiaotong University (Science), 2020, 25(1): 51-56. |
| 26 | LUO Y X, SONG J A, ZHAO K, et al. UAV-cooperative penetration dynamic-tracking interceptor method based on DDPG[J]. Applied Sciences, 2022, 12(3): 1618. |
| [1] | Jiaqi LIU, Rongqian CHEN, Jinhua LOU, Xu HAN, Hao WU, Yancheng YOU. Aerodynamic shape optimization of high-speed helicopter rotor airfoil based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(9): 529828-529828. |
| [2] | Xudong LUO, Yiquan WU, Jinlin CHEN. Research progress on deep learning methods for object detection and semantic segmentation in UAV aerial images [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(6): 28822-028822. |
| [3] | Haiqiao LIU, Meng LIU, Zichao GONG, Jing DONG. A review of image matching methods based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(3): 28796-028796. |
| [4] | Xin SU, Runcheng GUAN, Qiao WANG, Weizheng YUAN, Xianglian LYU, Yang HE. Ice area and thickness detection method based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S2): 729283-729283. |
| [5] | Liqun CHEN, Xu ZOU, Lei ZHANG, Yingpan ZHU, Gang WANG, Jinyong CHEN. On⁃board intelligent target detection technology based on domestic commercial components [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S2): 728860-728860. |
| [6] | Pengyu LIU, Xueyao ZHU. Semantic parsing technology of air traffic control instruction in fusion airspace based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S1): 727592-727592. |
| [7] | Xiaowei FU, Zhe XU, Jindong ZHU, Nan WANG. Maneuvering decision-making of multi-UAV attack-defence confrontation based on PER-MATD3 [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(7): 327083-327083. |
| [8] | Lei HE, Weiqi QIAN, Kangsheng DONG, Xian YI, Congcong CHAI. Aerodynamic characteristics modeling of iced airfoil based on convolution neural networks [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(5): 126434-126434. |
| [9] | Peng DING, Yafei SONG. A cost-sensitive method for aerial target intention recognition [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(24): 328551-328551. |
| [10] | Xiaohang LI, Jianjiang ZHOU. Multi⁃scale modality fusion network based on adaptive memory length [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(22): 628977-628977. |
| [11] | Haowen LUO, Shaoming HE, Tianyu JIN, Zichao LIU. Impact-angle-constrained with time-minimum guidance algorithm based on transfer learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(19): 328400-328400. |
| [12] | Yunhe ZHAO, Shengnan WANG. Solution to stress intensity factor by weight function method based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(19): 228367-228367. |
| [13] | Yubin YUAN, Yiquan WU, Langyue ZHAO, Jinlin CHEN, Qichang ZHAO. Research progress of UAV aerial video multi⁃object detection and tracking based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(18): 28334-028334. |
| [14] | Rongsheng ZHANG, Yansheng WU, Xudong QIN, Puzhuo ZHANG. A real⁃time in⁃flight wind estimation and prediction method based on deep learning [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(13): 327860-327860. |
| [15] | Qiang WANG, Letian WU, Yong WANG, Huan WANG, Wankou YANG. An infrared small target detection method based on key point [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(10): 328173-328173. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341