Acta Aeronautica et Astronautica Sinica ›› 2025, Vol. 46 ›› Issue (24): 632345.doi: 10.7527/S1000-6893.2025.32345
• special column • Previous Articles
Qichao XIE, Chengyu CAO, Yiyun ZHAO, Fanbiao LI( )
)
Received:2025-06-03
Revised:2025-06-04
Accepted:2025-06-05
Online:2025-07-01
Published:2025-06-20
Contact:
Fanbiao LI
E-mail:fanbiaoli@csu.edu.cn
Supported by:CLC Number:
Qichao XIE, Chengyu CAO, Yiyun ZHAO, Fanbiao LI. Integrated guidance and control method based on deep reinforcement learning parameter tuning[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(24): 632345.
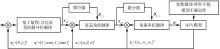
Fig.1
Control block diagram of backstepping method
Fig.2
Block diagram of TD3 algorithm training
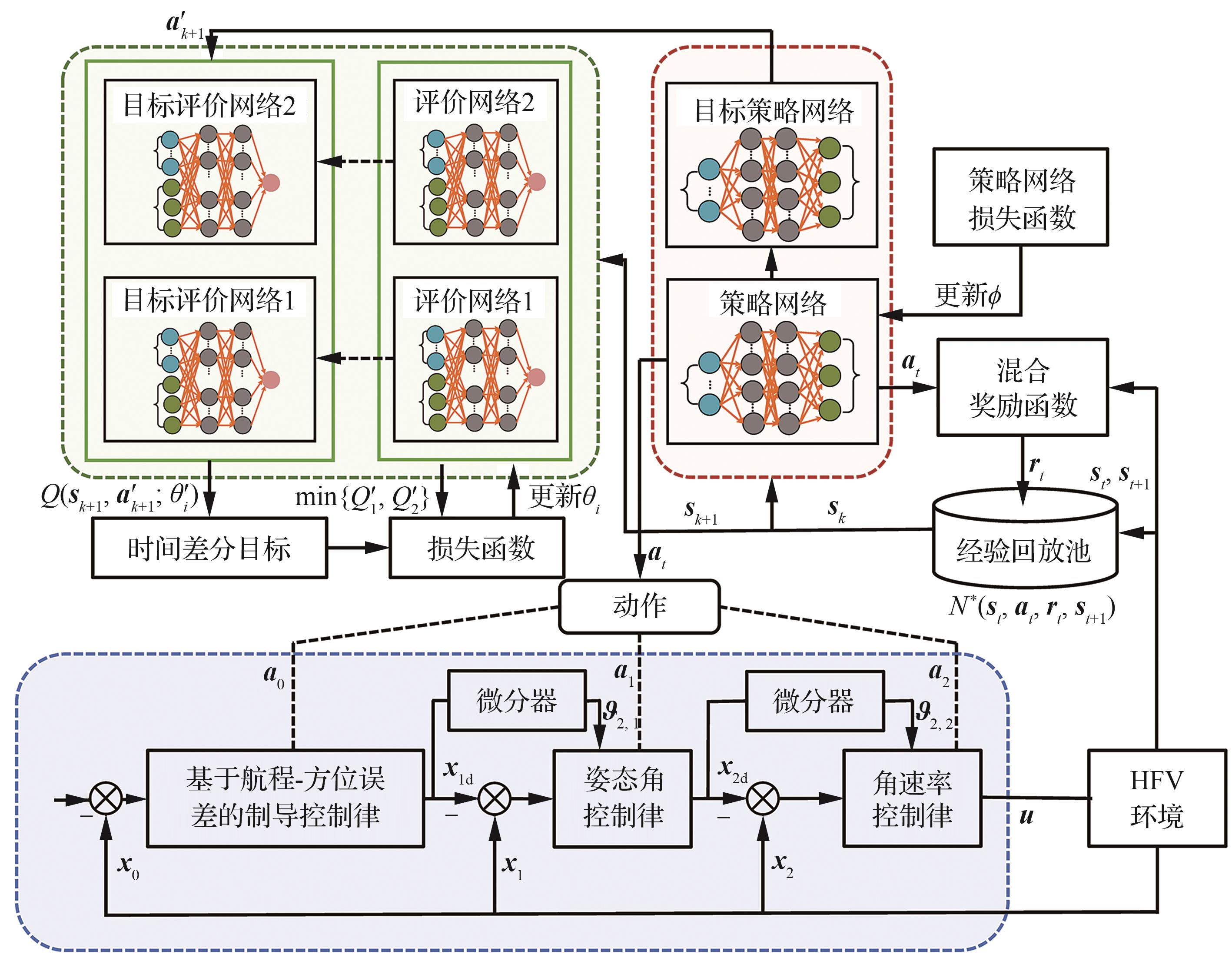
Table 1
Training hyperparameters
| 训练超参数 | 数值 |
|---|---|
| 训练回合数 | 200 |
| 单回合最大时间步 | |
| 批学习数 | |
| 折扣因子 | 0.99 |
| 策略网络学习率 | |
| 软更新率 | |
| 经验回放池容量 | 106 |
| 策略网络噪声标准差 | |
| 评价网络噪声标准差 | |
| 评价网络1学习率 | |
| 评价网络2学习率 | |
| 策略梯度更新 | 2 |
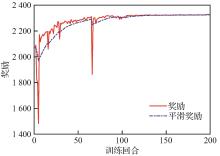
Fig.3
Reward function curves
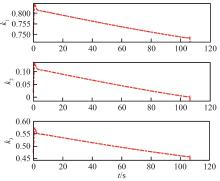
Fig.4
Parameter variation curves
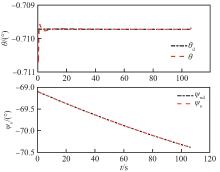
Fig.5
Track inclination and track deflection variation curves
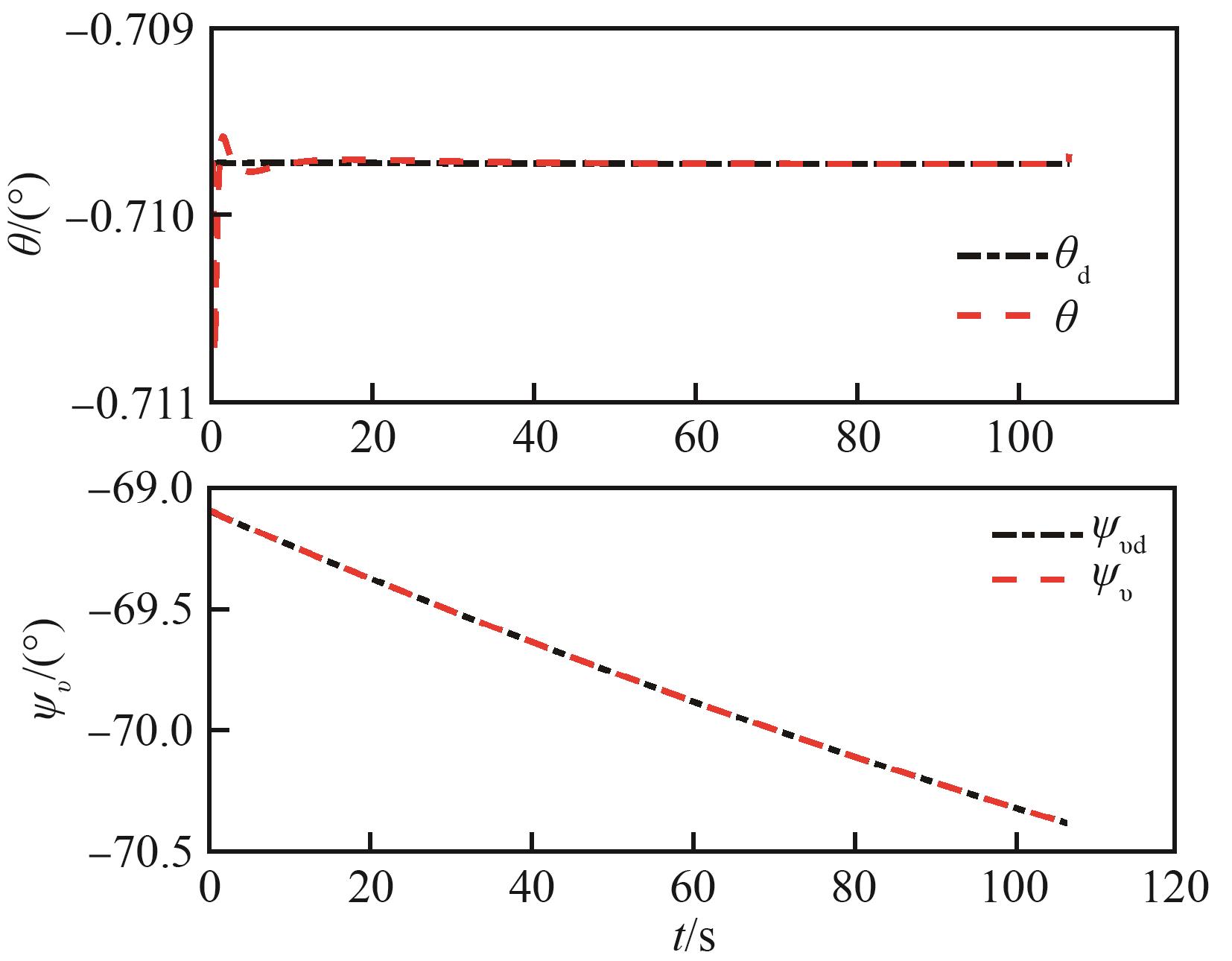
Fig.6
Attitude angle variation curves
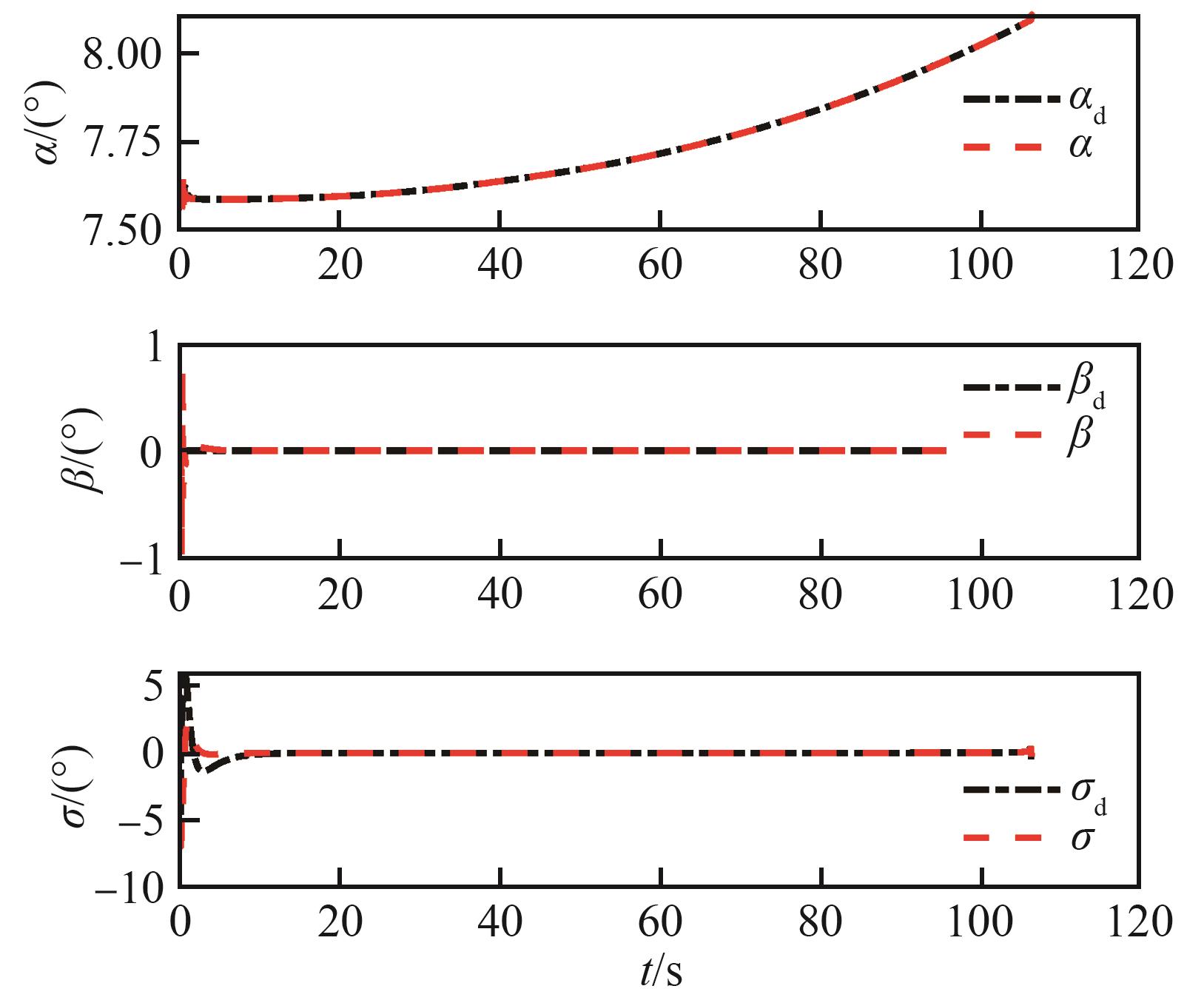
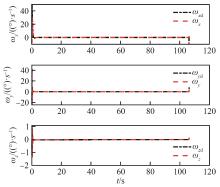
Fig.7
Variation curves of angular velocity in three axes
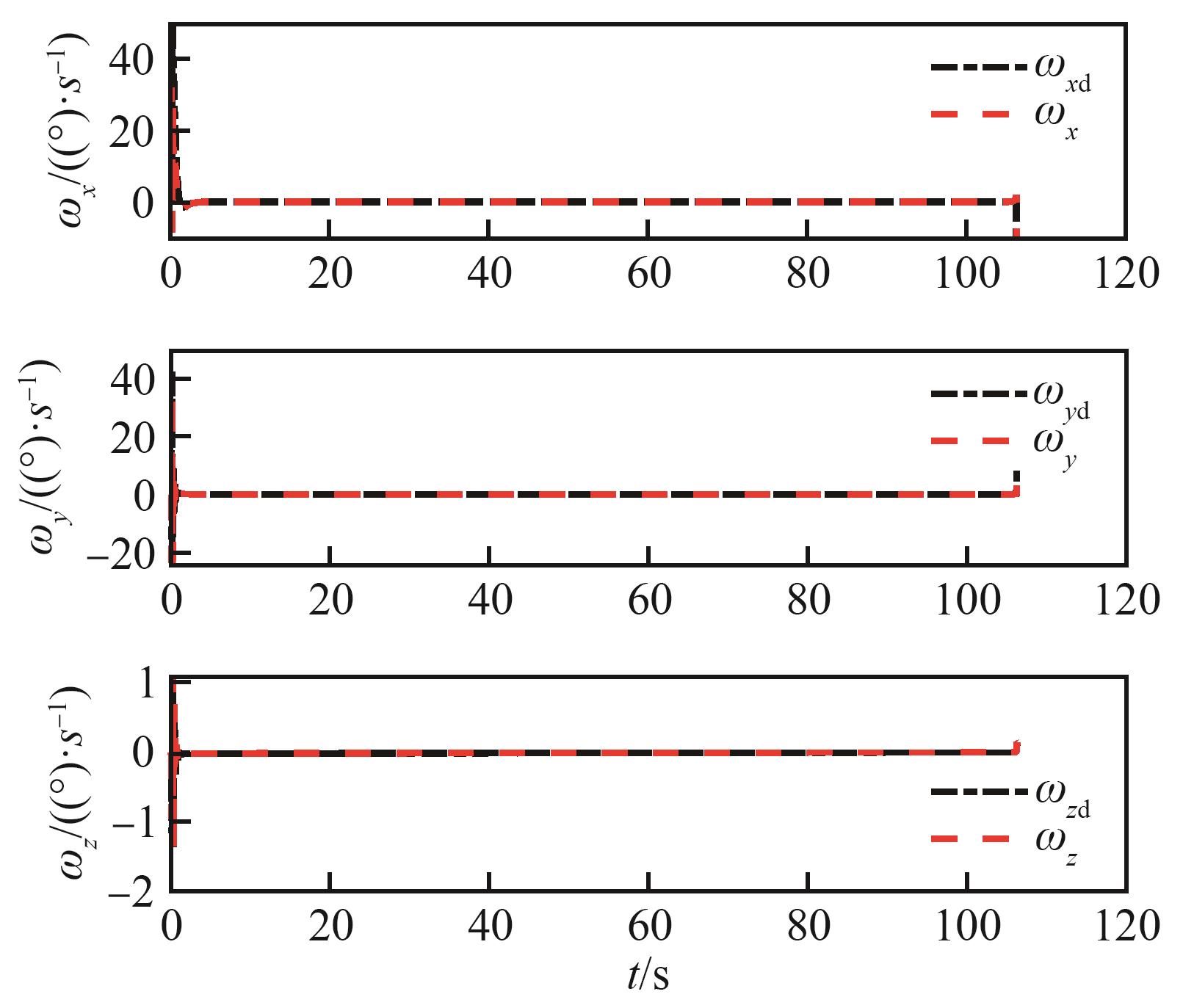
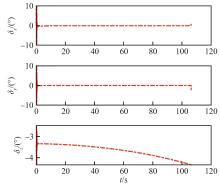
Fig.8
Rudderangle variation curves
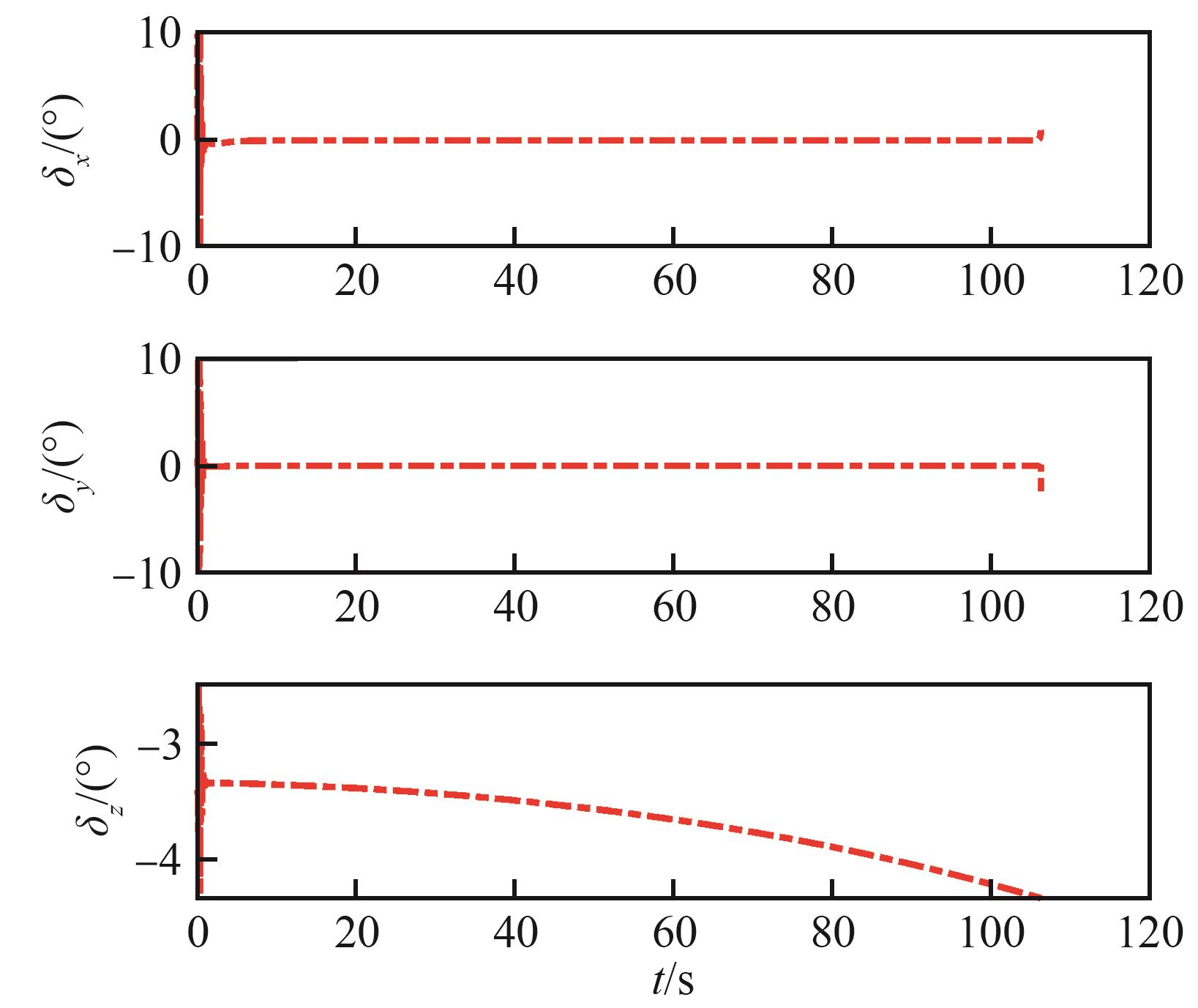
Table 2
Initial state variables of each round
| 参数域 | 数学形式 | 偏差 | |
|---|---|---|---|
| 高度 | |||
| 速度 | |||
| 经度 | |||
| 纬度 | |||
| 航迹倾角 | |||
| 航迹偏角 | |||
Table 3
Normal distribution of uncertain parameters
| 参数域 | 数学形式 | 偏差 |
|---|---|---|
| 气动力系数偏差 | ||
| 气动力矩系数偏差 | ||
| 大气密度 |
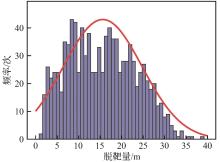
Fig.9
Miss distance histogram
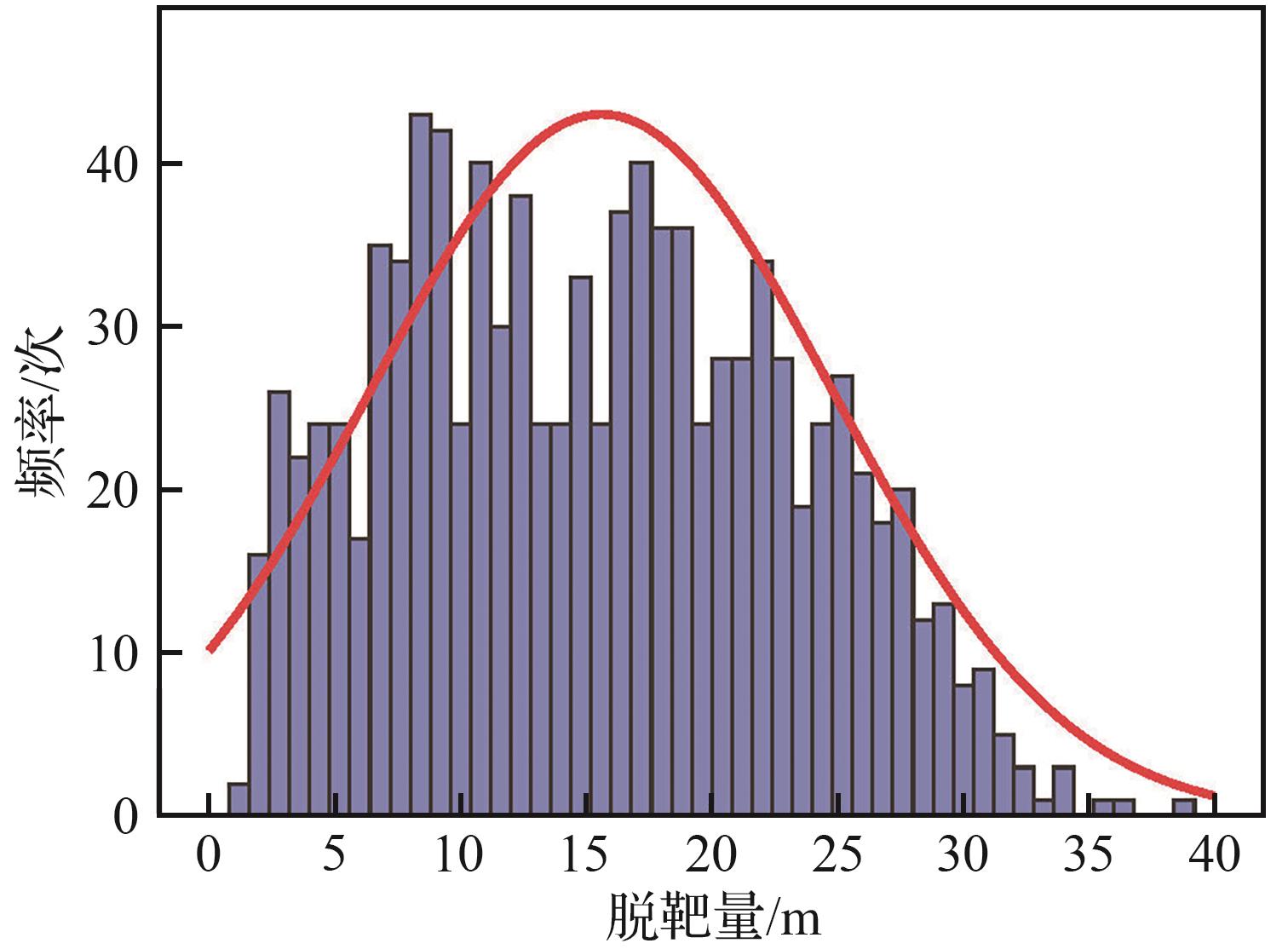
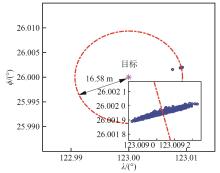
Fig.10
Terminal position distribution
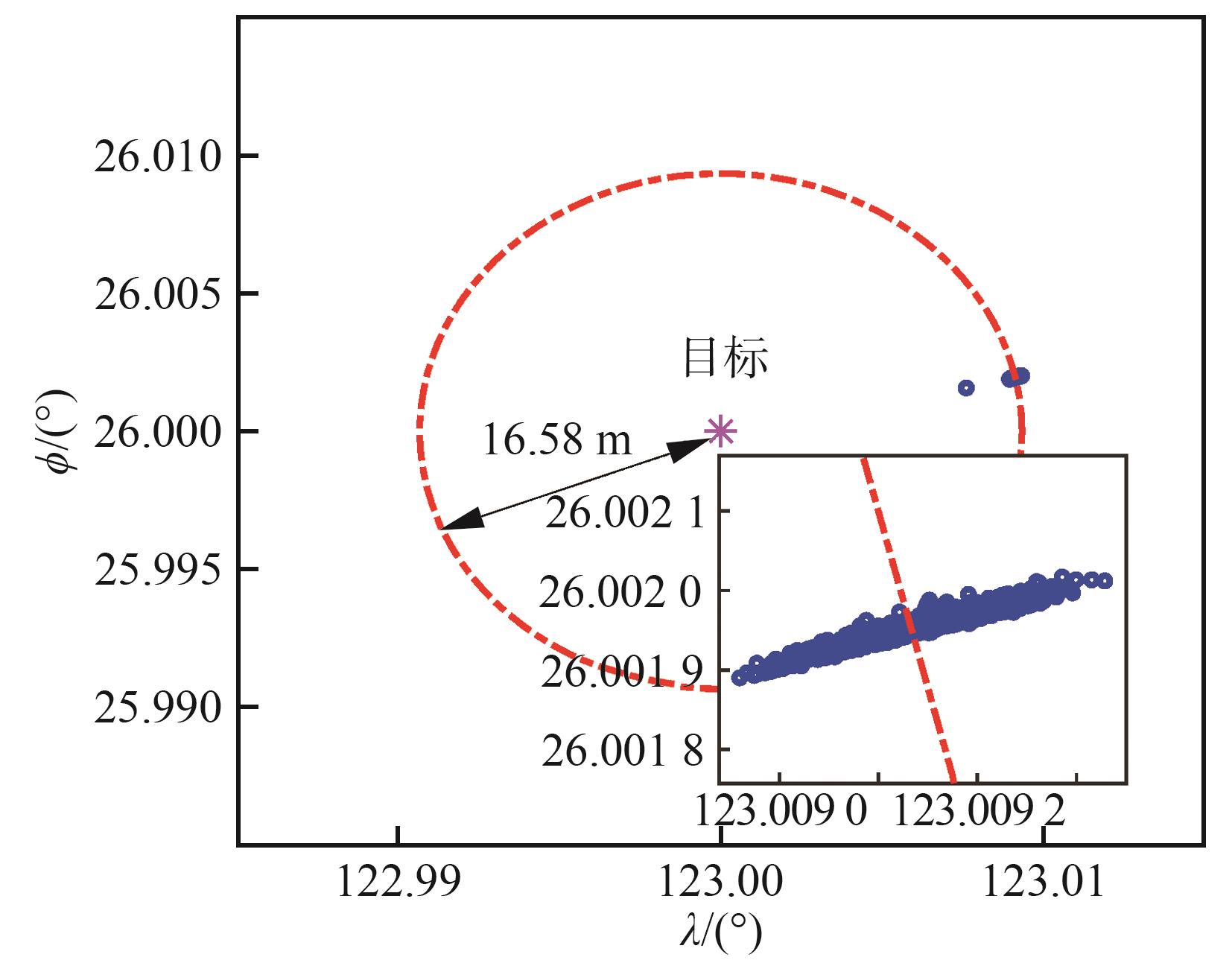
Table 4
Comparison of miss distance
| 控制方法 | 脱靶量均值/m | 脱靶量标准差/m |
|---|---|---|
| 基于TD3的参数自适应方法 | 15.620 | 7.291 |
| 反步控制 | 18.576 | 9.425 |
| [1] | 黄伟, 罗世彬, 王振国. 临近空间高超声速飞行器关键技术及展望[J]. 宇航学报, 2010, 31(5): 1259-1265. |
| HUANG W, LUO S B, WANG Z G. Key techniques and prospect of near-space hypersonic vehicle[J]. Journal of Astronautics, 2010, 31(5): 1259-1265 (in Chinese). | |
| [2] | 吴宏鑫, 孟斌. 高超声速飞行器控制研究综述[J]. 力学进展, 2009, 39(6): 756-765. |
| WU H X, MENG B. Review on the control of hypersonic flight vehicles[J]. Advances in Mechanics, 2009, 39(6): 756-765 (in Chinese). | |
| [3] | 张超凡, 宗群, 董琦, 等. 高超声速飞行器模型及控制若干问题综述[J]. 信息与控制, 2017, 46(1): 90-102. |
| ZHANG C F, ZONG Q, DONG Q, et al. A survey of models and control problems of hypersonic vehicles[J]. Information and Control, 2017, 46(1): 90-102 (in Chinese). | |
| [4] | 孙长银, 穆朝絮, 余瑶. 近空间高超声速飞行器控制的几个科学问题研究[J]. 自动化学报, 2013, 39(11): 1901-1913. |
| SUN C Y, MU C X, YU Y. Some control problems for near space hypersonic vehicles[J]. Acta Automatica Sinica, 2013, 39(11): 1901-1913 (in Chinese). | |
| [5] | 穆凌霞, 王新民, 谢蓉, 等. 高超音速飞行器及其制导控制技术综述[J]. 哈尔滨工业大学学报, 2019, 51(3): 1-14. |
| MU L X, WANG X M, XIE R, et al. A survey of the hypersonic flight vehicle and its guidance and control technology[J]. Journal of Harbin Institute of Technology, 2019, 51(3): 1-14 (in Chinese). | |
| [6] | LIANG Z X, LV C, ZHU S Y. Lateral entry guidance with terminal time constraint[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(3): 2544-2553. |
| [7] | ZHANG F, DUAN G R. Coupled dynamics and integrated control for position and attitude motions of spacecraft: A survey[J]. IEEE/CAA Journal of Automatica Sinica, 2023, 10(12): 2187-2208. |
| [8] | LI Z B, ZHANG X Y, ZHANG H R, et al. Three-dimensional approximate cooperative integrated guidance and control with fixed-impact time and azimuth constraints[J]. Aerospace Science and Technology, 2023, 142: 108617. |
| [9] | ZHAO Q, DUAN G R. Exponential position and attitude tracking control of spacecraft with unbiased parameter identification[J]. IEEE Transactions on Aerospace and Electronic Systems, 2024, 60(1): 1113-1128. |
| [10] | ZHOU M, LU M F, HU G J, et al. Koopman operator-based integrated guidance and control for strap-down high-speed missiles[J]. IEEE Transactions on Control Systems Technology, 2024, 32(6): 2436-2443. |
| [11] | 王肖, 郭杰, 唐胜景, 等. 吸气式高超声速飞行器鲁棒非奇异Terminal滑模反步控制[J]. 航空学报, 2017, 38(3): 320287. |
| WANG X, GUO J, TANG S J, et al. Robust nonsingular Terminal sliding mode backstepping control for air-breathing hypersonic vehicles[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(3): 320287 (in Chinese). | |
| [12] | 李亚苹, 王芳, 周超. 全状态受限的高超声速飞行器的预定性能滤波反步控制[J]. 航空学报, 2020, 41(11): 623857. |
| LI Y P, WANG F, ZHOU C. Prescribed performance filter backstepping control of hypersonic vehicle with full state constraints[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(11): 623857 (in Chinese). | |
| [13] | 周觐, 雷虎民, 李炯, 等. 基于神经网络的导弹制导控制一体化反演设计[J]. 航空学报, 2015, 36(5): 1661-1672. |
| ZHOU J, LEI H M, LI J, et al. Integrated missile guidance and control design based on neural network and back-stepping control theory[J]. Acta Aeronautica et Astronautica Sinica, 2015, 36(5): 1661-1672 (in Chinese). | |
| [14] | 王伟, 张晶涛, 柴天佑. PID参数先进整定方法综述[J]. 自动化学报, 2000, 26(3): 347-355. |
| WANG W, ZHANG J T, CHAI T Y. A survey of advanced pid parameter tuning methods[J]. Acta Automatica Sinica, 2000, 26(3): 347-355 (in Chinese). | |
| [15] | 余胜威, 曹中清. 基于人群搜索算法的PID控制器参数优化[J]. 计算机仿真, 2014, 31(9): 347-350, 373. |
| YU S W, CAO Z Q. Optimization parameters of PID controller parameters based on seeker optimization algorithm[J]. Computer Simulation, 2014, 31(9): 347-350, 373 (in Chinese). | |
| [16] | 杨侃, 王昭磊, 强艳辉, 等. 一种面向变体飞行器的控制器设计方法[J]. 航天控制, 2024, 42(3): 3-8. |
| YANG K, WANG Z L, QIANG Y H, et al. A controller design method oriented to variant vehicles[J]. Aerospace Control, 2024, 42(3): 3-8 (in Chinese). | |
| [17] | 康朝海, 王博宇, 杨永英. 基于精英高斯学习的改进鱼群粒子群混合算法[J]. 吉林大学学报(信息科学版), 2018, 36(4): 430-438. |
| KANG C H, WANG B Y, YANG Y Y. Improved hybrid algorithm with fish swarm-particle swarm optimization based on elite Gaussian learning[J]. Journal of Jilin University (Information Science Edition), 2018, 36(4): 430-438 (in Chinese). | |
| [18] | 李墨吟, 马泽远, 周建平, 等. 基于神经网络的变后掠翼飞行器自适应控制方法研究[J]. 弹箭与制导学报, 2021, 41(5): 73-77, 85. |
| LI M Y, MA Z Y, ZHOU J P, et al. Research on adaptive control method of variable-sweep wing aircraft based on neural network[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2021, 41(5): 73-77, 85 (in Chinese). | |
| [19] | ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al. Deep reinforcement learning: A brief survey[J]. IEEE Signal Processing Magazine, 2017, 34(6): 26-38. |
| [20] | 王建华, 刘鲁华, 王鹏, 等. 高超声速飞行器俯冲段制导控制一体化设计方法[J]. 航空学报, 2017, 38(3): 320328. |
| WANG J H, LIU L H, WANG P, et al. Integrated guidance and control scheme for hypersonic vehicles in dive phase[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(3): 320328 (in Chinese). | |
| [21] | 李惠峰, 肖进, 林平. 基于参数化外形的通用大气飞行器建模与分析[J]. 宇航学报, 2011, 32(11): 2305-2311. |
| LI H F, XIAO J, LIN P. Modeling and analyzing of common aero vehicle with parametric configuration[J]. Journal of Astronautics, 2011, 32(11): 2305-2311 (in Chinese). | |
| [22] | BU X W, WU X Y, HUANG J Q, et al. A guaranteed transient performance-based adaptive neural control scheme with low-complexity computation for flexible air-breathing hypersonic vehicles[J]. Nonlinear Dynamics, 2016, 84(4): 2175-2194. |
| [23] | 李小华, 徐波, 刘洋. 非线性扩展结构大系统自适应神经网络跟踪控制[J]. 控制与决策, 2016, 31(10): 1860-1866. |
| LI X H, XU B, LIU Y. Adaptive neural network tracking control for a class of nonlinear largescale systems with expanding construction[J]. Control and Decision, 2016, 31(10): 1860-1866 (in Chinese). | |
| [24] | 何昊, 王鹏. 高速变形飞行器制导控制一体化设计方法[J]. 航空学报, 2024, 45(S1):730692. |
| HE H, WANG P. Integrated guidance and control method for high-speed morphing wing aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(S1):730692 (in Chinese). | |
| [25] | CAO C Y, LI F B, DING R, et al. Intelligent attitude control for morphing flight vehicle: a deep reinforcement learning approach[J]. IEEE Transactions on Vehicular Technology, 2025, 74(6): 8851-8865. |
| [26] | CAO C Y, LI F B, XIE Q C, et al. Integrated guidance and control of morphing flight vehicle via sliding-mode-based robust reinforcement learning[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025, 55(5): 3350-3362. |
| [1] | Kaifang WAN, Zhilin WU, Yunhui WU, Haozhi QIANG, Yibo WU, Bo LI. Cooperative location of multiple UAVs with deep reinforcement learning in GPS-denied environment [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331024-331024. |
| [2] | Lingfeng JIANG, Xinkai LI, Hai ZHANG, Hanwei LI, Hongli ZHANG. Mapless navigation of UAVs in dynamic environments based on an improved TD3 algorithm [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331035-331035. |
| [3] | Min YANG, Guanjun LIU, Ziyuan ZHOU. Control of lunar landers based on secure reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(3): 630553-630553. |
| [4] | Chen WANG, Caisheng WEI, Zeyang YIN, Kai JIN, Xingchen LI. Collaborative planning of multi-UAV trajectories and communication strategies considering channel resource constraints [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(18): 331837-331837. |
| [5] | Yu WANG, Zhipeng XIE, Yongjian TIAN, Guanglei MENG. Distributed UAV formation control with virtual structure guided reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(15): 331354-331354. |
| [6] | Wei CHEN, Lulu LI, Dong CHEN, Shaohui ZHANG, Yafei LI, Ke WANG, Yuanyuan JIN, Mingliang XU. Multi-aircraft cooperative decision-making methods driven by differentiated support demands for carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531274-531274. |
| [7] | Xudong CHEN, Qiqi CHEN, Yizhe LUO, Jiabao WANG, Mingliang XU. Dynamic parallel scheduling of heterogeneous carrier-based aircraft deck support operations [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531329-531329. |
| [8] | Zheng WANG, Hua WANG, Keke CUI, Chaochao LI, Junnan LIU, Mingliang XU. Locally guided reinforcement learning for autonomous dispatching of carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531333-531333. |
| [9] | Wenhui LING, Chunhui MU, Lingcong NIE, Xian DU, Ximing SUN. Improved DDPG-based multipoint pressure distribution control of variable geometry scramjet combustor at wide range velocities [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(12): 131092-131092. |
| [10] | Zijie YU, Zheng ZHENG, Qingdong LI, Lin GUO, Suping REN, Jian GUO. Trajectory planning for solar-powered UAVs based on deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(12): 331420-331420. |
| [11] | Shuyi GAO, Defu LIN, Duo ZHENG, Cheng XU. Intelligent maneuvering penetration guidance strategies for aerial vehicles considering interceptor detection capability limitations [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(10): 331304-331304. |
| [12] | Hao HE, Peng WANG. Integrated guidance and control method for high-speed morphing wing aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(S1): 730692-730692. |
| [13] | Shuai LIANG, Guangle GAO, Xiaolei QU, Yajun LI. Asymptotic control of hypersonic flight vehicle based on error accumulation factor [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(S1): 730745-730745. |
| [14] | Honglin ZHANG, Jianjun LUO, Weihua MA. Spacecraft game decision making for threat avoidance of space targets based on machine learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329136-329136. |
| [15] | Yunpeng CAI, Dapeng ZHOU, Jiangchuan DING. Intelligent collaborative control of UAV swarms with collision avoidance safety constraints [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(5): 529683-529683. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341