高锡珍1,2( ), 汤亮1,2, 黄煌1,2
), 汤亮1,2, 黄煌1,2
收稿日期:2021-12-07
修回日期:2022-01-06
接受日期:2022-03-24
出版日期:2023-03-25
发布日期:2022-03-30
通讯作者:
高锡珍
E-mail:gaoxizhen_qd@126.com
基金资助:
Xizhen GAO1,2(), Liang TANG1,2, Huang HUANG1,2
Received:2021-12-07
Revised:2022-01-06
Accepted:2022-03-24
Online:2023-03-25
Published:2022-03-30
Contact:
Xizhen GAO
E-mail:gaoxizhen_qd@126.com
Supported by:摘要:
围绕地外探测任务对全自主操控的需求,阐述了智能技术的引入对地外探测操控的重要意义。根据地外探测操控任务的发展现状和特点,总结出地外探测自主操控面临的挑战与难点,对现有基于深度强化学习的操控算法进行概括。以地外探测自主操控任务难点为驱动,对深度强化学习(DRL)技术在地外探测操控中的应用及成果进行了综述与分析,概括了未来地外探测自主智能操控发展中涉及的关键技术问题。
中图分类号:
高锡珍, 汤亮, 黄煌. 深度强化学习技术在地外探测自主操控中的应用与挑战[J]. 航空学报, 2023, 44(6): 26762.
Xizhen GAO, Liang TANG, Huang HUANG. Deep reinforcement learning in autonomous manipulation for celestial bodies exploration: Applications and challenges[J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(6): 26762.
表 1
地外探测操控能力现状
| 国家/机构 | 地外星表无人探测器 | 探测距离/km | 探测时间 | 操控自主能力 |
|---|---|---|---|---|
| 美国 | “索杰纳号” | 0.1 | 83 d | 激光条纹仪自主识别地形和避碰 |
| “机遇号”/“勇气号” | 45.16/8.6 | 2 208 火星日/5 352 火星日 | 局部自主避障路径规划 | |
| “好奇号” | 20.31 | 2 708 火星日 | 局部自主避障路径规划、特定探测目标自主识别、半自主火星岩石钻孔和分析 | |
| “洞察号” | 地面规划,原位探测,火星地表钻孔和样品分析 | |||
| “毅力号” | 2.67 | 248 火星日 | 一定程度智能规划和决策能力,智能选择探测目标并自主决策采样方式 | |
| 日本 | “隼鸟号”/隼鸟2号” | 地面规划,小行星着陆、采样和返回 | ||
| 欧洲航天局 | “罗塞塔号” | 地面规划,彗星登陆 | ||
| 中国 | “玉兔号”/“玉兔2号” | 0.11/0.4 | 3月/15月 | 局部自主避障路径规划地面任务规划和全局路径规划 |
| “嫦娥”着陆器 | 自主悬停避障 | |||
| “祝融号” | 1.064 | 100 d | 地面任务规划和全局路径规划 |
表 2
典型采样操作臂设计方案
| 年份 | 探测器 | 操作臂性能 | 任务设计 |
|---|---|---|---|
| 2003 |
“勇气号”“机遇号”[ | 5自由度,臂长约1 m,重4.2 kg,安装4组科学仪器,重约2 kg,“肩2+肘1+腕2”构型设计方案,肩部关节有俯仰和偏航2个自由度,肘部关节有1个俯仰自由度,末端采样机构有2个自由度,驱动器采用有刷直流电机。 | 机械臂上装有研磨式采样设备(Rock Abrasion Tool,RAT),岩石的研磨通过带有2个金刚石尖齿的研磨轮高速(300 r/min)转动来实现,用于磨去岩石的风化表面,暴露内部物质供车载仪器研究。 |
| 2008 |
“凤凰号”[ | 4自由度,臂长2.35 m,铝钛合金低质量臂,“肩2+肘1+腕1”构型设计方案,肩部关节有俯仰和偏航2个自由度,肘部关节有1个俯仰自由度,末端采样机构有1个自由度,驱动器采用有刷直流电机。 | 末端有一个“铲斗”(Scoop)用于挖掘和采集松散土壤,并可通过“刮板”(Scraping Blade)刮取冻土样品。 |
| 2012 |
“好奇号”[ | 5自由度,臂长为2.2 m,重67 kg,末端安装有5组科学仪器,重34 kg,“肩2+肘1+腕2”构型设计方案,肩部关节有俯仰和偏航2个自由度,肘部关节有1个俯仰自由度,末端采样机构有2个自由度,驱动器采用无刷直流电机。 | 机械臂能够将5个安装在转台上的科学仪器准确放置在目标点上获取样本。钻头或者取样勺获得样本后,样本将被传送至CHIMRA加工单元,通过重力、附加振动、机械臂运动,固体样本最终被投送至巡视器上各科学仪器内。 |
| 2020 |
“毅力号”[ | 5自由度,臂长为2.2 m,末端转台安装有2组科学仪器和1台用于近距离成像的相机,“肩2+肘1+腕2”构型设计方案,重40.1 kg,肩部关节有俯仰和偏航2个自由度,肘部关节有1个俯仰自由度,末端采样机构有2个自由度,驱动器采用无刷直流电机。 | 机械臂搭载的末端执行器主要使用钻取的方式进行采样,可以对深度达l m的次表层样品进行采集,并可钻取坚硬岩石。岩石样本收集在样本管内。再将封装好后的样本管安放在样本缓存装置中。之后,将样本缓存装置存储在在轨容器中,后续任务返回地球。 |
| 2020 |
“嫦娥5号”[ | 4自由度,臂长为3.6 m,重22 kg,月面负载能力超过30 kg,“肩2+肘1+腕1”构型设计方案,肩部关节有俯仰和偏航2个自由度,肘部关节有1个俯仰自由度,末端采样机构有1个自由度,驱动器采用无刷直流电机。 | 利用2种不同采样形式的采样器组成,可对不同指定区域浅层月壤进行铲、挖、浅钻等多种形式采样。 |

图 1
地外探测操控任务所遇到的几个问题典型案例[17-20]

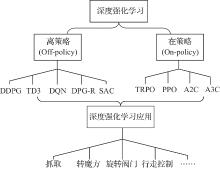
图 2
深度强化学习算法分类及应用


图 3
基于深度强化学习的火星着陆GNC系统[48]


图 4
不同算法生成轨迹比较 [55]
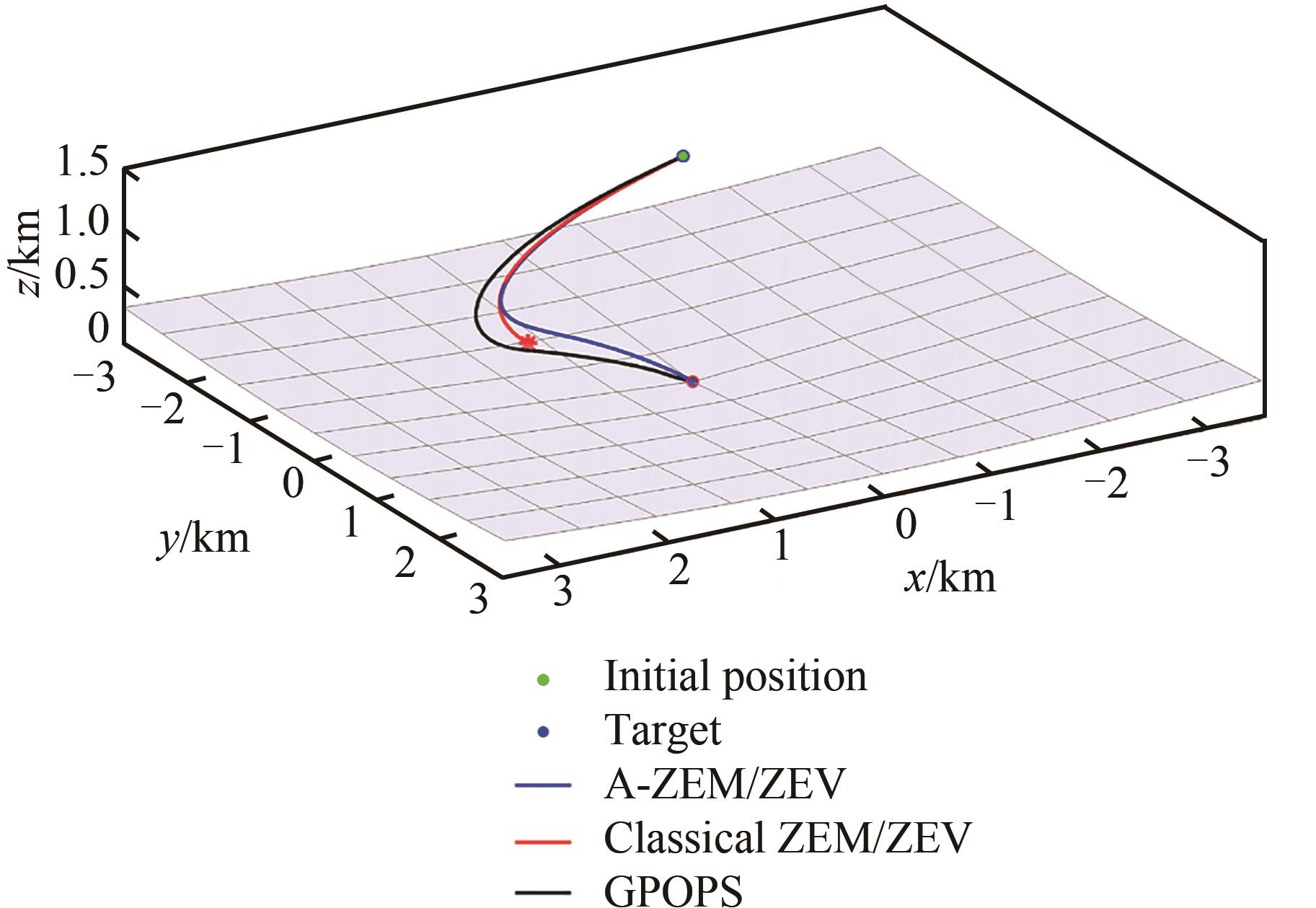
图 5
带路径地图 [66]
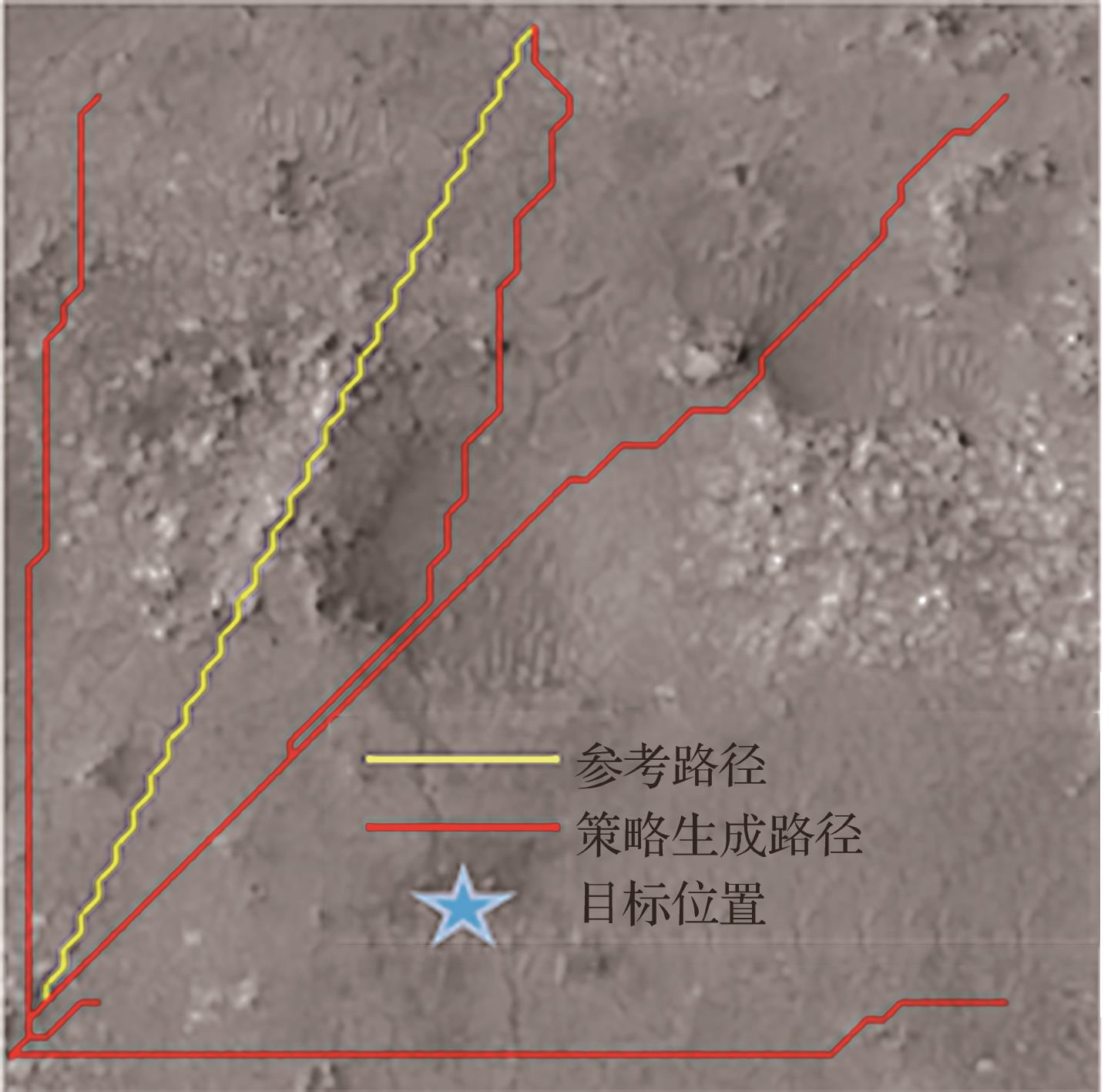

图 6
火星巡视器协同探索方案[67]
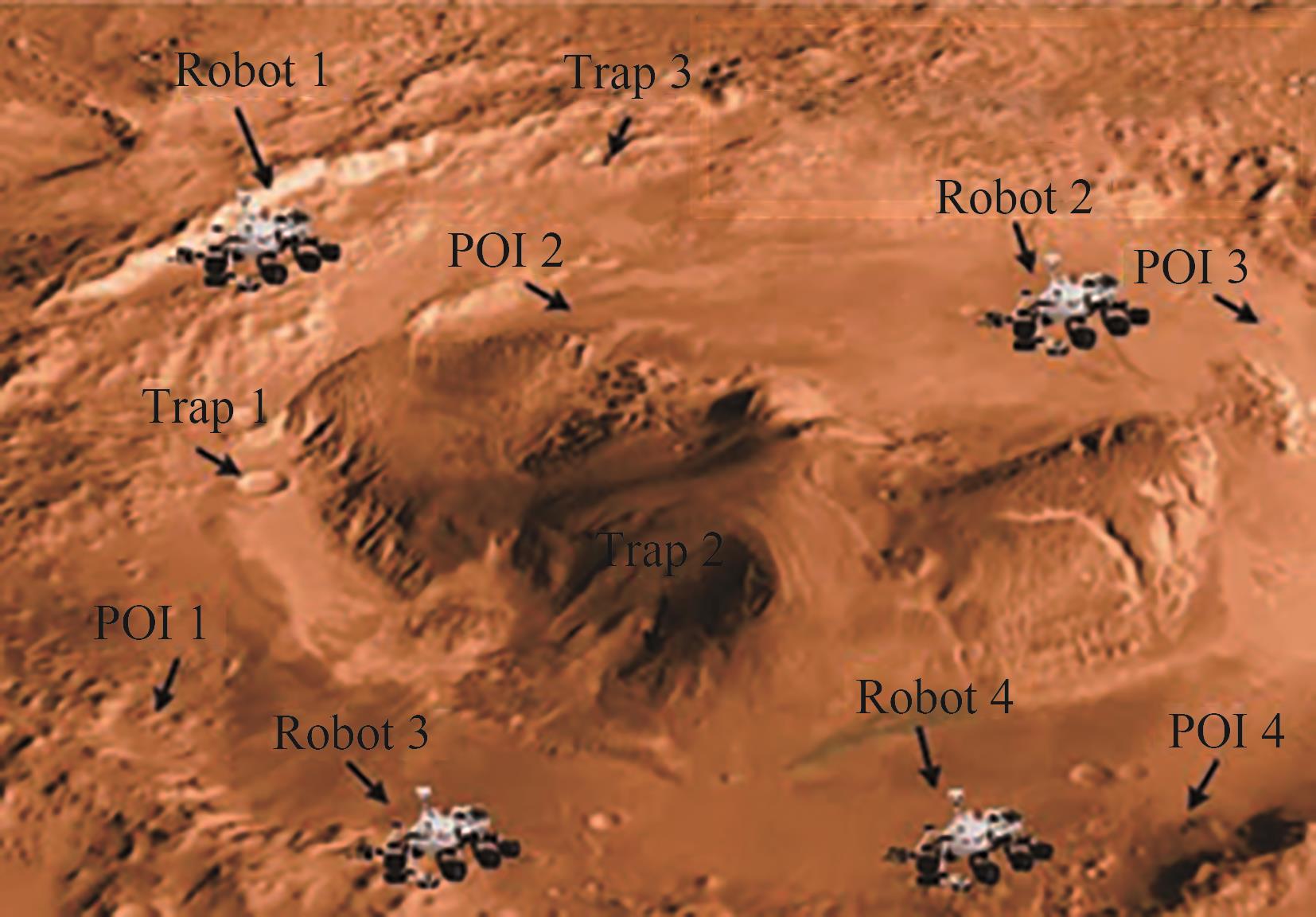

图 7
真实环境抓取


图 8
试验场环境抓取

表 3
地外探测和机器人应用中深度强化学习比较
| 类别 | 地外探测应用 | 机器人应用 |
|---|---|---|
| 环境状态 | 环境状态部分可观测 | 环境状态可完全观测 |
| 训练数据 | 任务有限,真实环境及虚拟环境获取数据难 | 真实环境:数据获取会损耗硬件,有潜在危险,成本高;虚拟环境:数据获取方便 |
| 奖励设计 | 任务及环境复杂,奖励函数难以设计 | 任务较单一,奖励函数固定不变 |
| 训练成本 | 仿真环境高,真实环境难以实现 | 仿真环境低,真实环境高 |
| 其他 | 不确定性因素多,计算资源有限,安全可靠性要求高 | 不确定性因素较多,计算资源充足 |
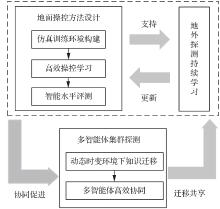
图 9
地外探测智能操控关键技术相互关系
| 1 | GE D T, CUI P Y, ZHU S Y. Recent development of autonomous GNC technologies for small celestial body descent and landing[J]. Progress in Aerospace Sciences, 2019, 110: 100551. |
| 2 | FRANCIS R, ESTLIN T, DORAN G, et al. AEGIS autonomous targeting for ChemCam on Mars science laboratory: Deployment and results of initial science team use[J]. Science Robotics, 2017, 2(7): 4582. |
| 3 | TREBI-OLLENNU A, KIM W, ALI K, et al. Insight Mars lander robotics instrument deployment system[J]. Space Science Reviews, 2018, 214(5): 93. |
| 4 | 张洪华, 梁俊, 黄翔宇, 等. 嫦娥三号自主避障软着陆控制技术[J]. 中国科学: 技术科学, 2014, 44(6): 559-568. |
| ZHANG H H, LIANG J, HUANG X Y, et al. Autonomous hazard avoidance control for Chang’e-3 soft landing[J]. Scientia Sinica (Technologica), 2014, 44(6): 559-568 (in Chinese). | |
| 5 | 任德鹏, 李青, 张正峰, 等. 嫦娥五号探测器地面试验验证技术[J]. 中国科学: 技术科学, 2021, 51(7): 778-787. |
| REN D P, LI Q, ZHANG Z F, et al. Ground-test validation technologies for Chang’e-5 lunar probe[J]. Scientia Sinica (Technologica), 2021, 51(7): 778-787 (in Chinese). | |
| 6 | 于登云, 张哲, 泮斌峰, 等. 深空探测人工智能技术研究与展望[J]. 深空探测学报, 2020, 7(1): 11-23. |
| YU D Y, ZHANG Z, PAN B F, et al. Development and trend of artificial intelligent in deep space exploration[J]. Journal of Deep Space Exploration, 2020, 7(1): 11-23 (in Chinese). | |
| 7 | ROTHROCK B, KENNEDY R, CUNNINGHAM C, et al. SPOC: Deep learning-based terrain classification for Mars rover missions: AIAA-2016-5539[R]. Reston: AIAA, 2016. |
| 8 | 吴伟仁, 周建亮, 王保丰, 等. 嫦娥三号“玉兔号”巡视器遥操作中的关键技术[J]. 中国科学: 信息科学, 2014, 44(4): 425-440. |
| WU W R, ZHOU J L, WANG B F, et al. Key technologies in the teleoperation of Chang’e-3 “Jade Rabbit” rover[J]. Scientia Sinica: Informationis, 2014, 44(4): 425-440 (in Chinese). | |
| 9 | 胡浩, 裴照宇, 李春来, 等. 无人月球采样返回工程总体设计: 嫦娥五号任务[J]. 中国科学: 技术科学, 2021, 51(11): 1275-1286. |
| HU H, PEI Z Y, LI C L, et al. Overall design of unmanned lunar sampling and return project: Chang'e-5 mission[J]. Scientia Sinica (Technologica), 2021, 51(11): 1275-1286 (in Chinese). | |
| 10 | TREBI-OLLENNU A, BAUMGARTNER E T, LEGER P C, et al. Robotic arm in situ operations for the Mars Exploration Rovers surface mission[C]∥2005 IEEE International Conference on Systems, Man and Cybernetics. Piscataway: IEEE Press, 2005: 1799-1806. |
| 11 | BAUMGARTNER E T, BONITZ R G, MELKO J P, et al. The Mars Exploration Rover instrument positioning system[C]∥2005 IEEE Aerospace Conference. Piscataway: IEEE Press, 2005: 1-19. |
| 12 | BONITZ R, SHIRAISHI L, ROBINSON M, et al. The phoenix Mars lander robotic arm[C]∥2009 IEEE Aerospace conference. Piscataway: IEEE Press, 2009: 1-12. |
| 13 | BILLING P, FLEISCHNER C. Mars science laboratory robotic arm[J]. 14th European Space Mechanisms & Tribology Symposium-ESMATS 2011. 2011: 363-370. |
| 14 | MOELLER R C, JANDURA L, ROSETTE K, et al. The Sampling and Caching Subsystem (SCS) for the scientific exploration of jezero crater by the Mars 2020 perseverance rover[J]. Space Science Reviews, 2021, 217(1): 1-43. |
| 15 | 马如奇, 姜水清, 刘宾, 等. 月球采样机械臂系统设计及试验验证[J]. 宇航学报, 2018, 39(12): 1315-1322. |
| MA R Q, JIANG S Q, LIU B, et al. Design and verification of a lunar sampling manipulator system[J]. Journal of Astronautics, 2018, 39(12): 1315-1322 (in Chinese). | |
| 16 | ROBINSON M, COLLINS C, LEGER P, et al. In-situ operations and planning for the Mars science laboratory robotic arm: The first 200 sols[C]∥2013 8th International Conference on System of Systems Engineering. Piscataway: IEEE Press, 2013: 153-158. |
| 17 | CALLAS J L. Mars exploration rover spirit end of mission report[R]. Pasadena: Jet Propulsion Laboratory, National Aeronautics and Space Administration, 2015. |
| 18 | DLR. The InSight mission logbook (February 2019-July 2020) [EB/OL]. (2020-07-07) [2021-09-02]. . |
| 19 | ABBEY W, ANDERSON R, BEEGLE, et al. A look back, part II: The drilling campaign of the Curiosity rover during the Mars Science Laboratory’s second and third Martian years[J]. Icarus, 2020, 350: 113885. |
| 20 | NASA. Assessing perseverance’s first sample attempt[EB/OL]. (2021-08-11) [2021-09-02]. . |
| 21 | 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7): 1301-1312. |
| SUN C Y, MU C X. Important scientific problems of multi-agent deep reinforcement learning[J]. Acta Automatica Sinica, 2020, 46(7): 1301-1312 (in Chinese). | |
| 22 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. |
| 23 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. 4th International Conference on Learning Representations, ICLR 2016-Conference Track Proceedings. OpenReview. Net, 2016: 1-14 |
| 24 | FUJIMOTO S, van HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[DB/OL]. arXiv preprint: 1802.09477, 2018. |
| 25 | POPOV I, HEESS N, LILLICRAP T, et al. Data-efficient deep reinforcement learning for dexterous manipulation[DB/OL]. arXiv preprint: 1704.03073, 2017. |
| 26 | FUJIMOTO S, MEGER D, PRECUP D. Off-policy deep reinforcement learning without exploration [DB/OL]. arXiv preprint: 1812.02900, 2018. |
| 27 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor [DB/OL]. arXiv preprint: 1801.01290, 2018. |
| 28 | SCHULMAN J. Optimizing expectations: From deep reinforcement learning to stochastic computation graphs[D]. Berkeley: UC Berkeley, 2016 |
| 29 | SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation [DB/OL]. arXiv preprint: 1506.02438, 2015. |
| 30 | DUAN Y, CHEN X, HOUTHOOFT R, et al. Benchmarking deep reinforcement learning for continuous control[C]∥Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48. New York: ACM, 2016: 1329-1338. |
| 31 | ANTONOVA R, CRUCIANI S, SMITH C, et al. Reinforcement learning for pivoting task [DB/OL]. arXiv preprint: 1703.00472, 2017. |
| 32 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms [DB/OL]. arXiv preprint: 1707.06347, 2017. |
| 33 | HEESS N, TB D, SRIRAM S, et al. Emergence of locomotion behaviours in rich environments [DB/OL]. arXiv preprint: 1707.02286, 2017. |
| 34 | PENG X B, ABBEEL P, LEVINE S, et al. DeepMimic: Example-guided deep reinforcement learning of physics-based character skills [DB/OL]. arXiv preprint: 1804.02717, 2018. |
| 35 | TANG Y H, AGRAWAL S. Discretizing continuous action space for on-policy optimization[C]∥ Proceedings of the AAAI Conference on Artificial Intelligence. Washington, D.C.: AAAI, 2020: 5981-5988. |
| 36 | YIN M Z, YUE Y G, ZHOU M Y. ARSM: Augment-REINFORCE-swap-merge estimator for gradient backpropagation through categorical variables [DB/OL]. arXiv preprint: 1905.01413, 2019. |
| 37 | YUE Y G, TANG Y H, YIN M Z, et al. Discrete action on-policy learning with action-value critic [DB/OL]. arXiv preprint: 2002.03534, 2020. |
| 38 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]∥ Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48. New York: ACM, 2016: 1928-1937. |
| 39 | DEISENROTH M P, RASMUSSEN C E. PILCO: A model-based and data-efficient approach to policy search[C]∥ Proceedings of the 28th International Conference on International Conference on Machine Learning. New York: ACM, 2011: 465-472. |
| 40 | OH J, GUO X X, LEE H, et al. Action-conditional video prediction using deep networks in Atari games[C]∥ Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 2. New York: ACM, 2015: 2863-2871. |
| 41 | WATTER M, SPRINGENBERG J T, BOEDECKER J, et al. Embed to control: A locally linear latent dynamics model for control from raw images [DB/OL]. arXiv preprint: 1506.07365, 2015. |
| 42 | HA D, SCHMIDHUBER J. World models [DB/OL]. arXiv preprint: 1803.10122, 2018. |
| 43 | LEVINE S, FINN C, DARRELL T, et al. End-to-end training of deep visuomotor policies [DB/OL]. arXiv preprint: 1504.00702, 2015. |
| 44 | 刘乃军, 鲁涛, 蔡莹皓, 等. 机器人操作技能学习方法综述[J]. 自动化学报, 2019, 45(3): 458-470. |
| LIU N J, LU T, CAI Y H, et al. A review of robot manipulation skills learning methods[J]. Acta Automatica Sinica, 2019, 45(3): 458-470 (in Chinese). | |
| 45 | 赵冬斌, 邵坤, 朱圆恒, 等. 深度强化学习综述: 兼论计算机围棋的发展[J]. 控制理论与应用, 2016, 33(6): 701-717. |
| ZHAO D B, SHAO K, ZHU Y H, et al. Review of deep reinforcement learning and discussions on the development of computer Go[J]. Control Theory & Applications, 2016, 33(6): 701-717 (in Chinese). | |
| 46 | GAUDET B, FURFARO R. Adaptive pinpoint and fuel efficient Mars landing using reinforcement learning[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(4): 397-411. |
| 47 | CHENG L, WANG Z B, JIANG F H. Real-time control for fuel-optimal Moon landing based on an interactive deep reinforcement learning algorithm[J]. Astrodynamics, 2019, 3(4): 375-386. |
| 48 | GAUDET B, LINARES R. Integrated guidance and control for pinpoint Mars landing using reinforcement learning: AAS 18-290[R]. Washington, D.C.: AAS, 2018. |
| 49 | JIANG X Q. Integrated guidance for Mars entry and powered descent using reinforcement learning and pseudospectral method[J]. Acta Astronautica, 2019, 163: 114-129. |
| 50 | GAUDET B, LINARES R, FURFARO R. Deep reinforcement learning for six degree-of-freedom planetary powered descent and landing [DB/OL]. arXiv preprint: 1810.08719, 2018. |
| 51 | GAUDET B, LINARES R, FURFARO R. Deep reinforcement learning for six degree-of-freedom planetary landing[J]. Advances in Space Research, 2020, 65(7): 1723-1741. |
| 52 | SHIROBOKOV M. Survey of machine learning techniques in spacecraft control design[J]. Acta Astronautica, 2021, 186: 87-97. |
| 53 | 黄旭星, 李爽, 杨彬, 等. 人工智能在航天器制导与控制中的应用综述[J]. 航空学报, 2021, 42(4): 524201. |
| HUANG X X, LI S, YANG B, et al. Spacecraft guidance and control based on artificial intelligence: Review[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 524201 (in Chinese). | |
| 54 | FURFARO R, SCORSOGLIO A, LINARES R, et al. Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach [DB/OL]. arXiv preprint: 2003.02182, 2020. |
| 55 | FURFARO R. Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach[J]. Acta Astronautica, 2020, 171: 156-171. |
| 56 | FURFARO R, WIBBEN D R, GAUDET B, et al. Terminal multiple surface sliding guidance for planetary landing: Development, tuning and optimization via reinforcement learning[J]. The Journal of the Astronautical Sciences, 2015, 62(1): 73-99. |
| 57 | IIYAMA K, TOMITA K, JAGATIA B A, et al. Deep reinforcement learning for safe landing site selection with concurrent consideration of divert maneuvers [DB/OL]. arXiv preprint: 2102.12432, 2021. |
| 58 | GAUDET B. Terminal adaptive guidance via reinforcement meta-learning: Applications to autonomous asteroid close-proximity operations[J]. Acta Astronautica, 2020, 171: 1-13. |
| 59 | GAUDET B. Adaptive guidance and integrated navigation with reinforcement meta-learning[J]. Acta Astronautica, 2020, 169: 180-190. |
| 60 | BATTIN R H. An introduction to the mathematics and methods of astrodynamics[M]. Reston: AIAA, 1999: 10-12. |
| 61 | D'SOUZA C, D'SOUZA C. An optimal guidance law for planetary landing: AIAA-1997-3709[R]. Reston: AIAA, 1997. |
| 62 | 周思雨, 白成超. 基于深度强化学习的行星车路径规划方法研究[J]. 无人系统技术, 2019, 2(4): 38-45. |
| ZHOU S Y, BAI C C. Research on planetary rover path planning method based on deep reinforcement learning[J]. Unmanned Systems Technology, 2019, 2(4): 38-45 (in Chinese). | |
| 63 | SERNA J G, VANEGAS F, GONZALEZ F, et al. A review of current approaches for UAV autonomous mission planning for Mars biosignatures detection[C]∥2020 IEEE Aerospace Conference. Piscataway: IEEE Press, 2020: 1-15. |
| 64 | MCEWEN A S, ELIASON E M, BERGSTROM J W, et al. Mars reconnaissance orbiter’s High Resolution Imaging Science Experiment (HiRISE)[J]. Journal of Geophysical Research, 2007, 112(E5): E05S02. |
| 65 | TAVALLALI P, KARUMANCHI S, BOWKETT J, et al. A reinforcement learning framework for space missions in unknown environments[C]∥2020 IEEE Aerospace Conference. Piscataway: IEEE Press, 2020: 1-8. |
| 66 | PFLUEGER M, AGHA A, SUKHATME G S. Rover-IRL: Inverse reinforcement learning with soft value iteration networks for planetary rover path planning[J]. IEEE Robotics and Automation Letters, 2019, 4(2): 1387-1394. |
| 67 | HUANG Y X, WU S F, MU Z C, et al. A multi-agent reinforcement learning method for swarm robots in space collaborative exploration[C]∥2020 6th International Conference on Control, Automation and Robotics (ICCAR). Piscataway: IEEE Press, 2020 : 139-144. |
| 68 | WACHI A, SUI Y N. Safe reinforcement learning in constrained Markov decision processes[C]∥ Proceedings of the 37th International Conference on Machine Learning. New York: ACM, 2020: 9797-9806. |
| 69 | TURCHETTA M, BERKENKAMP F, KRAUSE A. Safe exploration in finite Markov decision processes with Gaussian processes[C]∥ Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 4312-4320. |
| 70 | WACHI A, SUI Y N, YUE Y S, et al. Safe exploration and optimization of constrained MDPs using Gaussian processes[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 52-58. |
| 71 | BERNSTEIN D S, ZILBERSTEIN S. Reinforcement learning for weakly-coupled MDPs and an application to planetary rover control[C]∥6th European Conference on Planning. Washington, D. C.: AAAI, 2014: 240-243. |
| 72 | SONG X G, GAO H B, DING L, et al. Diagonal recurrent neural networks for parameters identification of terrain based on wheel-soil interaction analysis[J]. Neural Computing and Applications, 2017, 28(4): 797-804. |
| 73 | ARREGUIN A L, MONTENEGRO S, DILGER E. Towards in-situ characterization of regolith strength by inverse terramechanics and machine learning: A survey and applications to planetary rovers[J]. Planetary and Space Science, 2021, 204: 105271. |
| 74 | 黄煌, 高锡珍, 汤亮, 等. 一种端到端的地外探测样品智能抓取方法: CN113524173A[P]. 2021-10-22. |
| HUANG H, GAO X Z, TANG L, et al. End-to-end extraterrestrial detection sample intelligent grabbing method: CN113524173A[P]. 2021-10-22 (in Chinese). | |
| 75 | 张浩东, 吴建华. 基于深度强化学习的机器人推拨优化装箱问题研究[J]. 空间控制技术与应用, 2021, 47(6): 52-58. |
| ZHANG H D, WU J H. Optimization of robotic Bin packing via pushing based on algorithm[J]. Aerospace Control and Application, 2021, 47(6): 52-58 (in Chinese). |
| [1] | 万开方, 吴志林, 武韫晖, 强皓植, 吴艺博, 李波. 拒止环境下基于深度强化学习的多无人机协同定位[J]. 航空学报, 2025, 46(8): 331024-331024. |
| [2] | 姜凌峰, 李新凯, 张海, 李涵玮, 张宏立. 基于改进TD3算法的无人机动态环境无地图导航[J]. 航空学报, 2025, 46(8): 331035-331035. |
| [3] | 杨敏, 刘关俊, 周子渊. 基于安全强化学习的月球着陆器控制[J]. 航空学报, 2025, 46(3): 630553-630553. |
| [4] | 王辰, 魏才盛, 殷泽阳, 靳锴, 李星辰. 考虑信道资源约束的多无人机航迹与通信策略协同规划[J]. 航空学报, 2025, 46(18): 331837-331837. |
| [5] | 王昱, 谢志鹏, 田永健, 孟光磊. 虚拟结构引领强化学习分布式无人机编队控制[J]. 航空学报, 2025, 46(15): 331354-331354. |
| [6] | 陈伟, 李璐璐, 陈董, 张少辉, 李亚飞, 王可, 靳远远, 徐明亮. 差异化保障需求驱动的舰载机多机协同决策方法[J]. 航空学报, 2025, 46(13): 531274-531274. |
| [7] | 陈旭东, 陈琦琦, 罗祎喆, 王佳宝, 徐明亮. 异构舰载机舰面保障作业动态并行调度[J]. 航空学报, 2025, 46(13): 531329-531329. |
| [8] | 王政, 王华, 崔可可, 李超超, 刘俊楠, 徐明亮. 局部引导强化学习的舰载机自主调运方法[J]. 航空学报, 2025, 46(13): 531333-531333. |
| [9] | 凌文辉, 牟春晖, 聂聆聪, 杜宪, 孙希明. 基于改进DDPG的宽速域几何可调燃烧室压力分布控制[J]. 航空学报, 2025, 46(12): 131092-131092. |
| [10] | 余子杰, 郑征, 李清东, 郭林, 任素萍, 郭健. 基于深度强化学习的太阳能无人机航迹规划[J]. 航空学报, 2025, 46(12): 331420-331420. |
| [11] | 高树一, 林德福, 郑多, 徐骋. 考虑拦截器探测能力限制的飞行器智能机动突防制导策略[J]. 航空学报, 2025, 46(10): 331304-331304. |
| [12] | 王志祥, 雷勇军, 张大鹏, 崔辉如. 大型运载火箭加筋圆柱壳混合整数序列近似优化方法[J]. 航空学报, 2025, 46(10): 230189-230189. |
| [13] | 贺靖, 谭鸽伟. 基于ALPFT参数估计的运动目标高分辨率成像[J]. 航空学报, 2025, 46(1): 330502-330502. |
| [14] | 张鸿林, 罗建军, 马卫华. 基于机器学习的航天器规避目标威胁博弈决策[J]. 航空学报, 2024, 45(8): 329136-329136. |
| [15] | 蔡章博, 张征宇, 余皓, 占书恒. 荧光油膜速度场的自适应快速光流解法[J]. 航空学报, 2024, 45(7): 128047-128047. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 航空学报编辑部
版权所有 © 2011航空学报杂志社
主管单位:中国科学技术协会 主办单位:中国航空学会 北京航空航天大学




