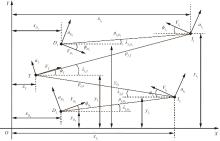
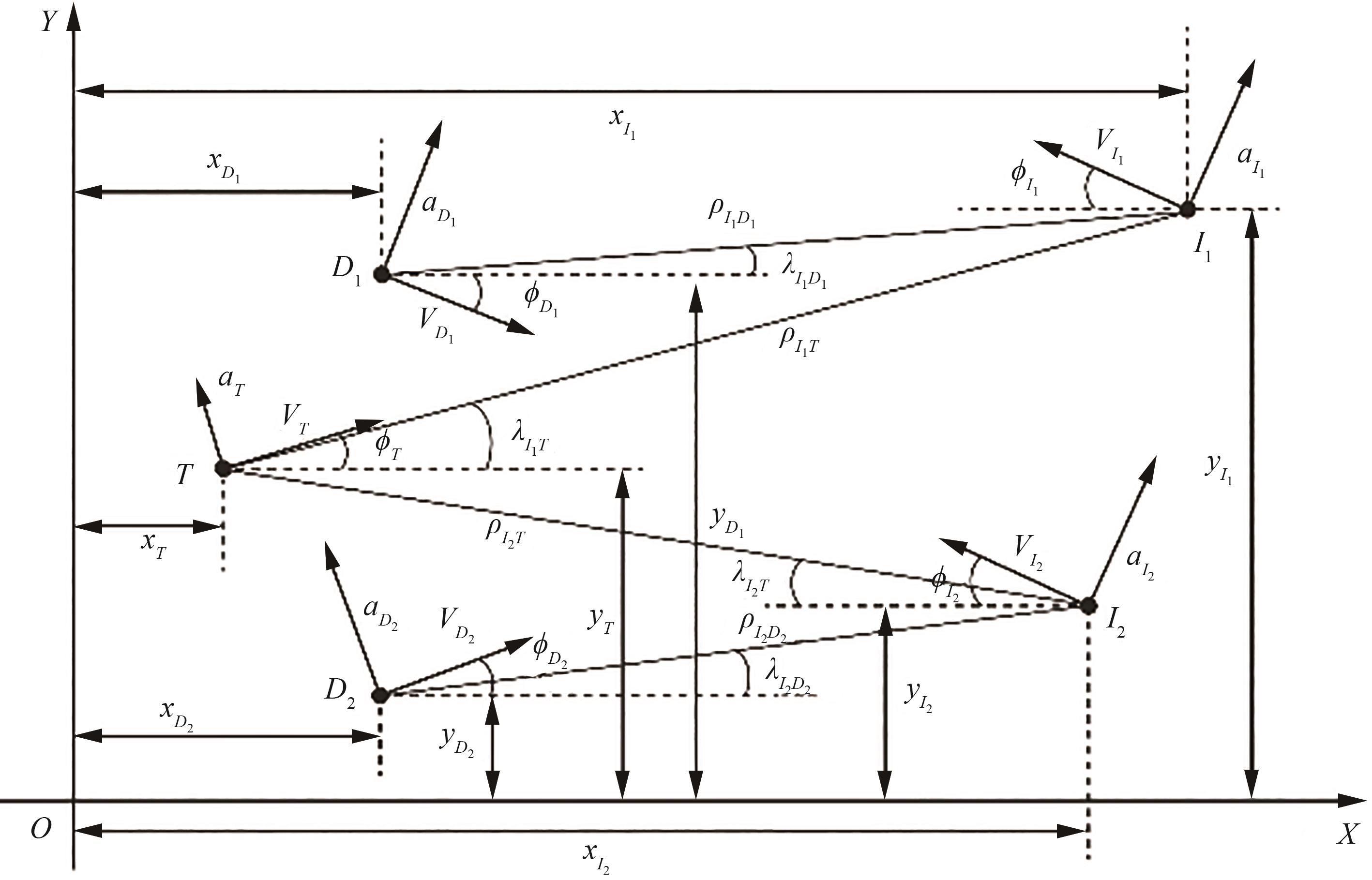
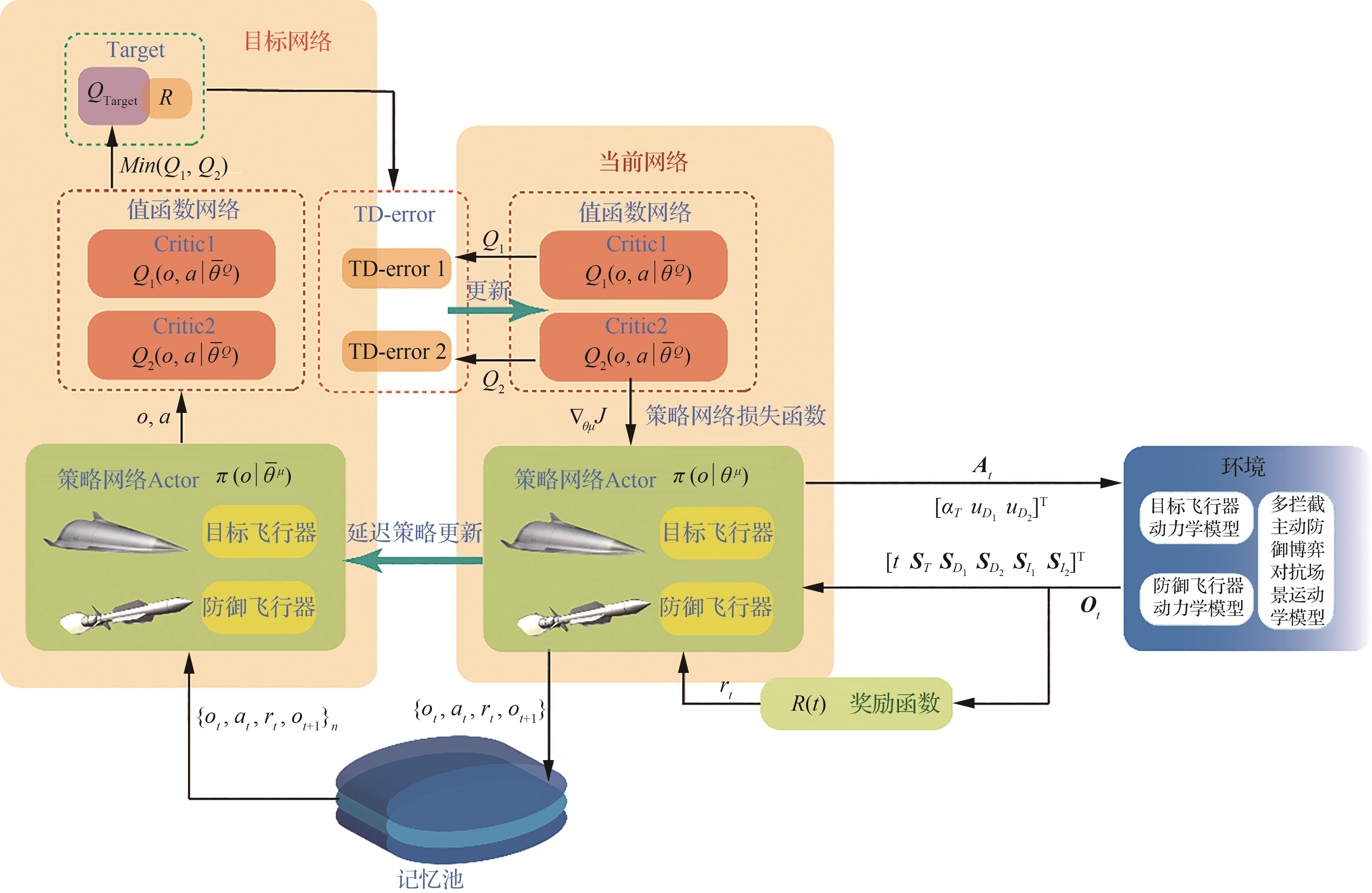
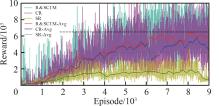
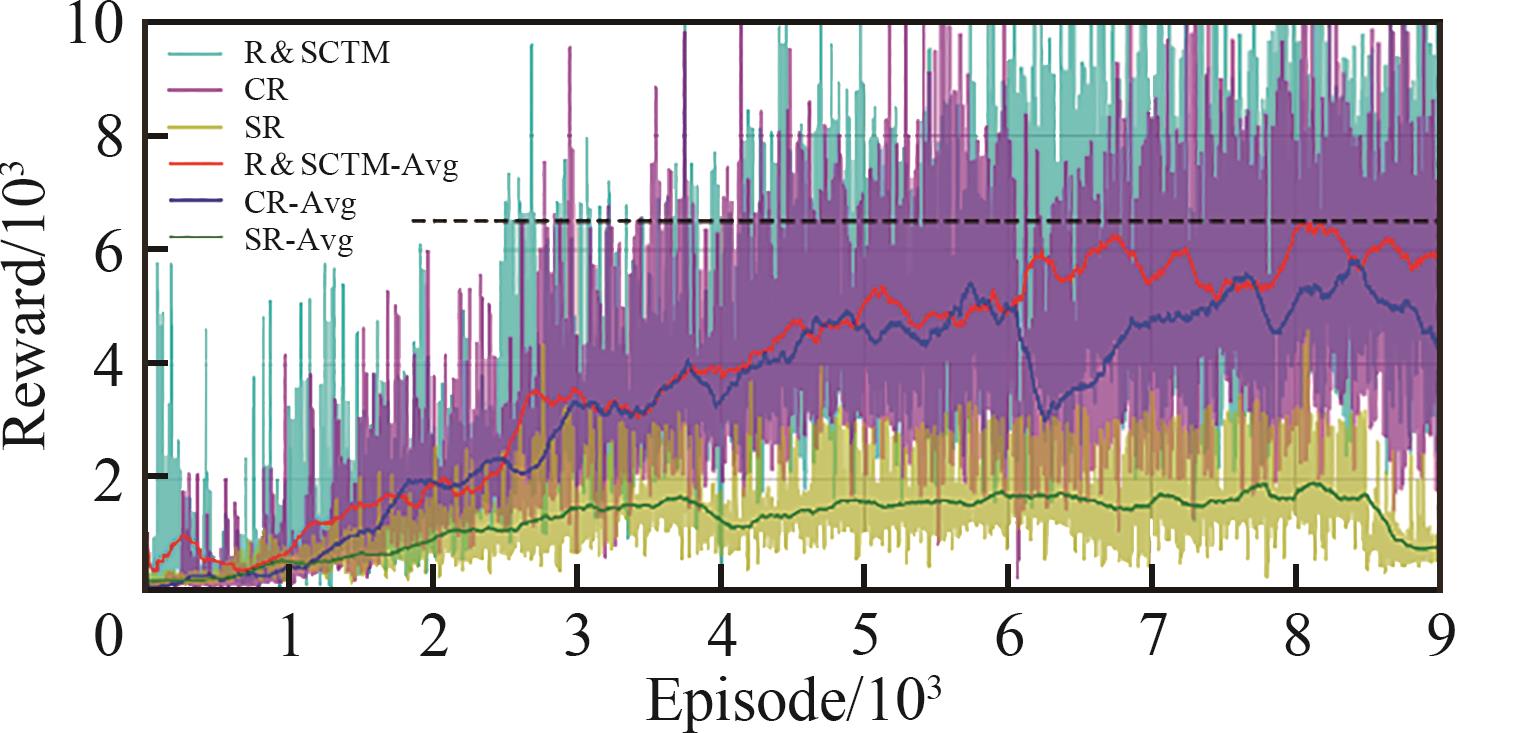
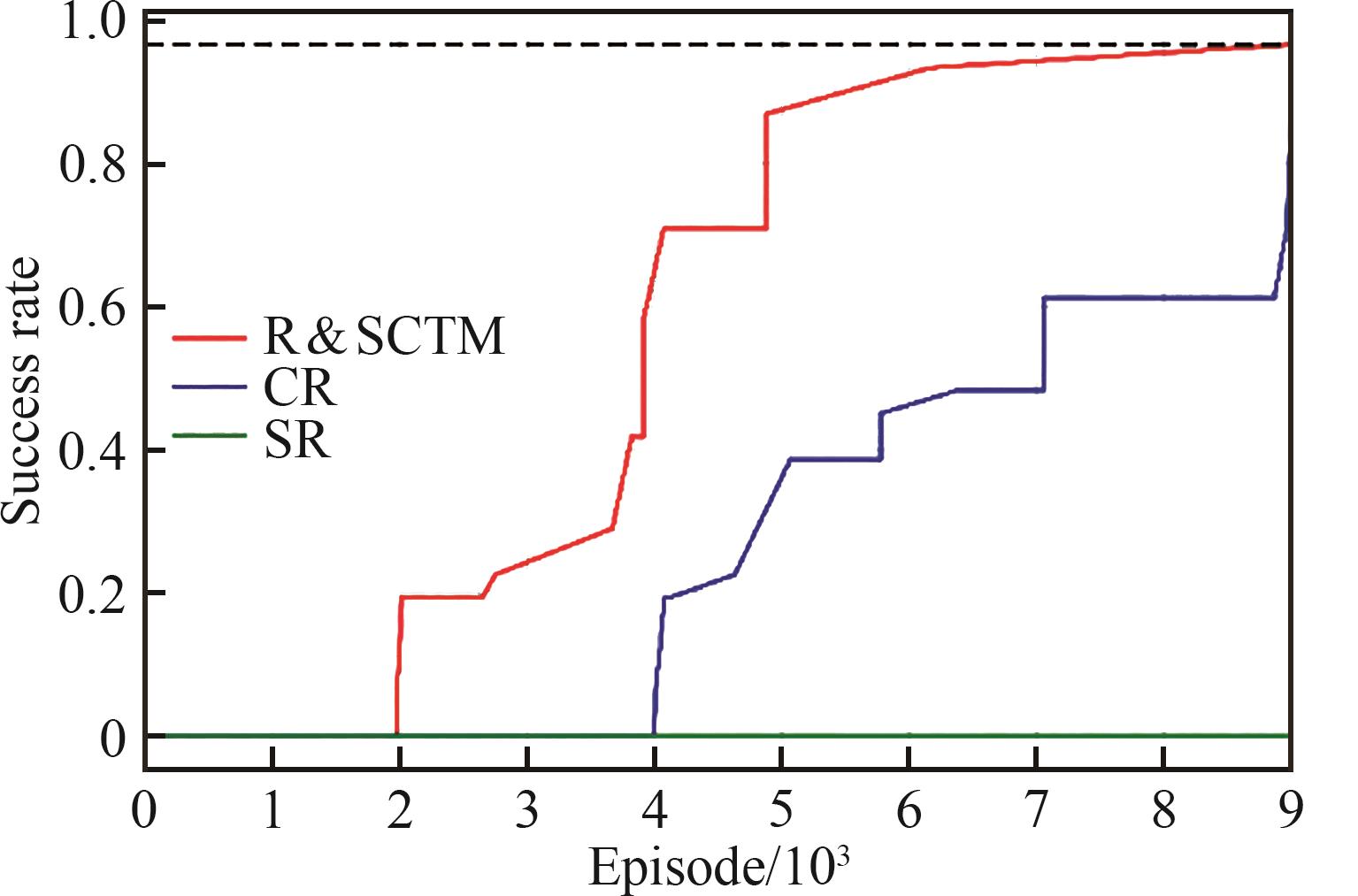
| 1 |
赵良玉, 雍恩米, 王波兰. 反临近空间高超声速飞行器若干研究进展[J]. 宇航学报, 2020, 41(10): 1239-1250.
|
|
ZHAO L Y, YONG E M, WANG B L. Some achievements on interception of near space hypersonic vehicles[J]. Journal of Astronautics, 2020, 41(10): 1239-1250 (in Chinese).
|
| 2 |
魏明英, 崔正达, 李运迁. 多弹协同拦截综述与展望[J]. 航空学报, 2020, 41(S1): 723804.
|
|
WEI M Y, CUI Z D, LI Y Q. Review and future development of multi-missile coordinated interception[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S1): 723804 (in Chinese).
|
| 3 |
赵亮博, 朱广生, 张耀, 等. 智能飞行器追逃博弈中的关键技术及发展趋势[J]. 飞航导弹, 2021(12): 134-139.
|
|
ZHAO L B, ZHU G S, ZHANG Y, et al. Key technology and development trend of intelligent aircraft pursuit game[J]. Aerodynamic Missile Journal, 2021(12): 134-139 (in Chinese).
|
| 4 |
LEWIS F L, VRABIE D L, SYRMOS V L. Optimal Control[M]. Hoboken: Wiley, 2012.
|
| 5 |
ANDERSON G M. Comparison of optimal control and differential game intercept missile guidance laws[J]. Journal of Guidance and Control, 1981, 4(2): 109-115.
|
| 6 |
SHINAR J, STEINBERG D. Analysis of optimal evasive maneuvers based on a linearized two-dimensional kinematic model[J]. Journal of Aircraft, 1977, 14(8): 795-802.
|
| 7 |
BEN-ASHER J Z, CLIFF E M. Optimal evasion against a proportionally guided pursuer[J]. Journal of Guidance, Control, and Dynamics, 1989, 12(4): 598-600.
|
| 8 |
RYOO C K, CHO H, TAHK M J. Optimal guidance laws with terminal impact angle constraint[J]. Journal of Guidance, Control, and Dynamics, 2005, 28(4): 724-732.
|
| 9 |
SHAFERMAN V, OSHMAN Y. Stochastic cooperative interception using information sharing based on engagement staggering[J]. Journal of Guidance, Control, and Dynamics, 2016, 39(9): 2127-2141.
|
| 10 |
SHAFERMAN V, SHIMA T. Cooperative multiple-model adaptive guidance for an aircraft defending missile[J]. Journal of Guidance, Control, and Dynamics, 2010, 33(6): 1801-1813.
|
| 11 |
FONOD R, SHIMA T. Multiple model adaptive evasion against a homing missile[J]. Journal of Guidance, Control, and Dynamics, 2016, 39(7): 1578-1592.
|
| 12 |
ISAACS R. Differential games: A mathematical theory with applications to warfare and pursuit, control and optimization [M]. Courier Corporation, 1999.
|
| 13 |
李运迁, 齐乃明, 孙小雷, 等. 大气层内拦截弹微分对策制导律对策空间分布研究[J]. 航空学报, 2010, 31(8): 1600-1607.
|
|
LI Y Q, QI N M, SUN X L, et al. Game space decomposition study of differential game guidance law for endoatmospheric interceptor missiles[J]. Acta Aeronautica et Astronautica Sinica, 2010, 31(8): 1600-1607 (in Chinese).
|
| 14 |
胡艳艳, 张莉, 夏辉, 等. 不完全信息下基于微分对策的机动目标协同捕获[J]. 航空学报, 2022, 43(S1): 726905.
|
|
HU Y Y, ZHANG L, XIA H, et al. Cooperative capture of maneuvering targets with incomplete information based on differential game[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(S1): 726905 (in Chinese).
|
| 15 |
王雨琪, 宁国栋, 王晓峰, 等. 基于微分对策的临近空间飞行器机动突防策略[J]. 航空学报, 2020, 41(S2): 724276.
|
|
WANG Y Q, NING G D, WANG X F, et al. Maneuver penetration strategy of near space vehicle based on differential game[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S2): 724276 (in Chinese).
|
| 16 |
MCRUER D. Design and modeling issues for integrated airframe/propulsion control of hypersonic flight vehicles[C]∥ 1991 American Control Conference. Piscataway: IEEE Press, 2009: 729-734.
|
| 17 |
DALLE D, FRENDREIS S, DRISCOLL J, et al. Hypersonic vehicle flight dynamics with coupled aerodynamic and reduced-order propulsive models: AIAA-2010-7930[R]. Reston: AIAA, 2010.
|
| 18 |
李广华, 张洪波, 汤国建. 高超声速滑翔飞行器典型弹道特性分析[J]. 宇航学报, 2015, 36(4): 397-403.
|
|
LI G H, ZHANG H B, TANG G J. Typical trajectory characteristics of hypersonic glide vehicle[J]. Journal of Astronautics, 2015, 36(4): 397-403 (in Chinese).
|
| 19 |
李淑艳, 任利霞, 宋秋贵, 等. 临近空间高超音速武器防御综述[J]. 现代雷达, 2014, 36(6): 13-15, 18.
|
|
LI S Y, REN L X, SONG Q G, et al. Overview of anti-hypersonic weapon in near space[J]. Modern Radar, 2014, 36(6): 13-15, 18 (in Chinese).
|
| 20 |
GAUDET B, LINARES R, FURFARO R. Deep reinforcement learning for six degree-of-freedom planetary landing[J]. Advances in Space Research, 2020, 65(7): 1723-1741.
|
| 21 |
GAUDET B, FURFARO R. Missile homing-phase guidance law design using reinforcement learning: AIAA-2012-4470[R]. Reston: AIAA, 2012.
|
| 22 |
GAUDET B, LINARES R, FURFARO R. Adaptive guidance and integrated navigation with reinforcement meta-learning[J]. Acta Astronautica, 2020, 169: 180-190.
|
| 23 |
GAUDET B, FURFARO R, LINARES R. Reinforcement learning for angle-only intercept guidance of maneuvering targets [J]. Aerospace Science and Technology, 2020, 99: 105746.
|
| 24 |
LAU M, STEFFENS M J, MAVRIS D N. Closed-loop control in active target defense using machine learning: AIAA-2019-0143[R]. Reston: AIAA, 2019.
|
| 25 |
SHALUMOV V. Cooperative online Guide-Launch-Guide policy in a target-missile-defender engagement using deep reinforcement learning[J]. Aerospace Science and Technology, 2020, 104: 105996.
|
| 26 |
GAUDET B, FURFARO R. Adaptive pinpoint and fuel efficient Mars landing using reinforcement learning[J]. IEEE/CAA Journal of Automatica Sinica, 2014, 1(4): 397-411.
|
| 27 |
GAUDET B, LINARES R, FURFARO R. Integrated guidance and control for pinpoint Mars landing using reinforcement learning[C]∥ Proceedings of the AAS/AIAA Astrodynamics Specialist Conference. Reston: AIAA, 2018: 1-20.
|
| 28 |
刘子超, 王江, 何绍溟, 等. 基于预测校正的落角约束计算制导方法[J]. 航空学报, 2022, 43(8): 325433.
|
|
LIU Z C, WANG J, HE S M, et al. A computational guidance algorithm for impact angle control based on predictor-corrector concept[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(8): 325433 (in Chinese).
|
| 29 |
HE S M, SHIN H S, TSOURDOS A. Computational missile guidance: A deep reinforcement learning approach[J]. Journal of Aerospace Information Systems, 2021, 18(8): 571-582.
|
| 30 |
AINSWORTH M, SHIN Y. Plateau phenomenon in gradient descent training of RELU networks: Explanation, quantification, and avoidance[J]. SIAM Journal on Scientific Computing, 2021, 43(5): A3438-A3468.
|
| 31 |
LI Z, WU J Z, WU Y P, et al. Real-time guidance strategy for active defense aircraft via deep reinforcement learning[C]∥ NAECON 2021-IEEE National Aerospace and Electronics Conference. Piscataway: IEEE Press, 2022: 177-183.
|
| 32 |
LIANG H Z, WANG J Y, WANG Y H, et al. Optimal guidance against active defense ballistic missiles via differential game strategies[J]. Chinese Journal of Aeronautics, 2020, 33(3): 978-989.
|
| 33 |
LIANG H Z, WANG J Y, LIU J Q, et al. Guidance strategies for interceptor against active defense spacecraft in two-on-two engagement[J]. Aerospace Science and Technology, 2020, 96: 105529.
|
| 34 |
QIU C R, HU Y, CHEN Y, et al. Deep deterministic policy gradient (DDPG)-based energy harvesting wireless communications[J]. IEEE Internet of Things Journal, 2019, 6(5): 8577-8588.
|
| 35 |
DANKWA S, ZHENG W F. Twin-delayed DDPG: A deep reinforcement learning technique to model a continuous movement of an intelligent robot agent[C]∥ Proceedings of the 3rd International Conference on Vision, Image and Signal Processing. New York: ACM, 2019: 1-5.
|
| 36 |
GULLAPALLI V, BARTO A G. Shaping as a method for accelerating reinforcement learning[C]∥ Proceedings of the 1992 IEEE International Symposium on Intelligent Control. Piscataway: IEEE Press, 2002: 554-559.
|
| 37 |
BENGIO Y, LOURADOUR J, COLLOBERT R, et al. Curriculum learning[C]∥ Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 41-48.
|
| 38 |
LI X, VASILE C I, BELTA C. Reinforcement learning with temporal logic rewards[C]∥ 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2017: 3834-3839.
|
| 39 |
SHANI G, HECKERMAN D, BRAFMAN R. An MDP-based recommender system[J]. J Mach Learn Res, 2002, 6: 1265-1295.
|
| 40 |
LIU F, DONG X W, LI Q D, et al. Cooperative differential games guidance laws for multiple attackers against an active defense target[J]. Chinese Journal of Aeronautics, 2022, 35(5): 374-389.
|
| 41 |
SHIMA T, SHINAR J. Time-varying linear pursuit-evasion game models with bounded controls[J]. Journal of Guidance, Control, and Dynamics, 2002, 25(3): 425-432.
|
| 42 |
SHALUMOV V. Optimal cooperative guidance laws in a multiagent target-missile-defender engagement[J]. Journal of Guidance, Control, and Dynamics, 2019, 42(9): 1993-2006.
|
| 43 |
ZHOU D, SUN S, TEO K L. Guidance laws with finite time convergence[J]. Journal of Guidance, Control, and Dynamics, 2009, 32(6): 1838-1846.
|
 )
)