郎荣玲, 魏才伦, 范亚( ), 高飞
), 高飞
Rongling LANG, Cailun WEI, Ya FAN(), Fei GAO
摘要:
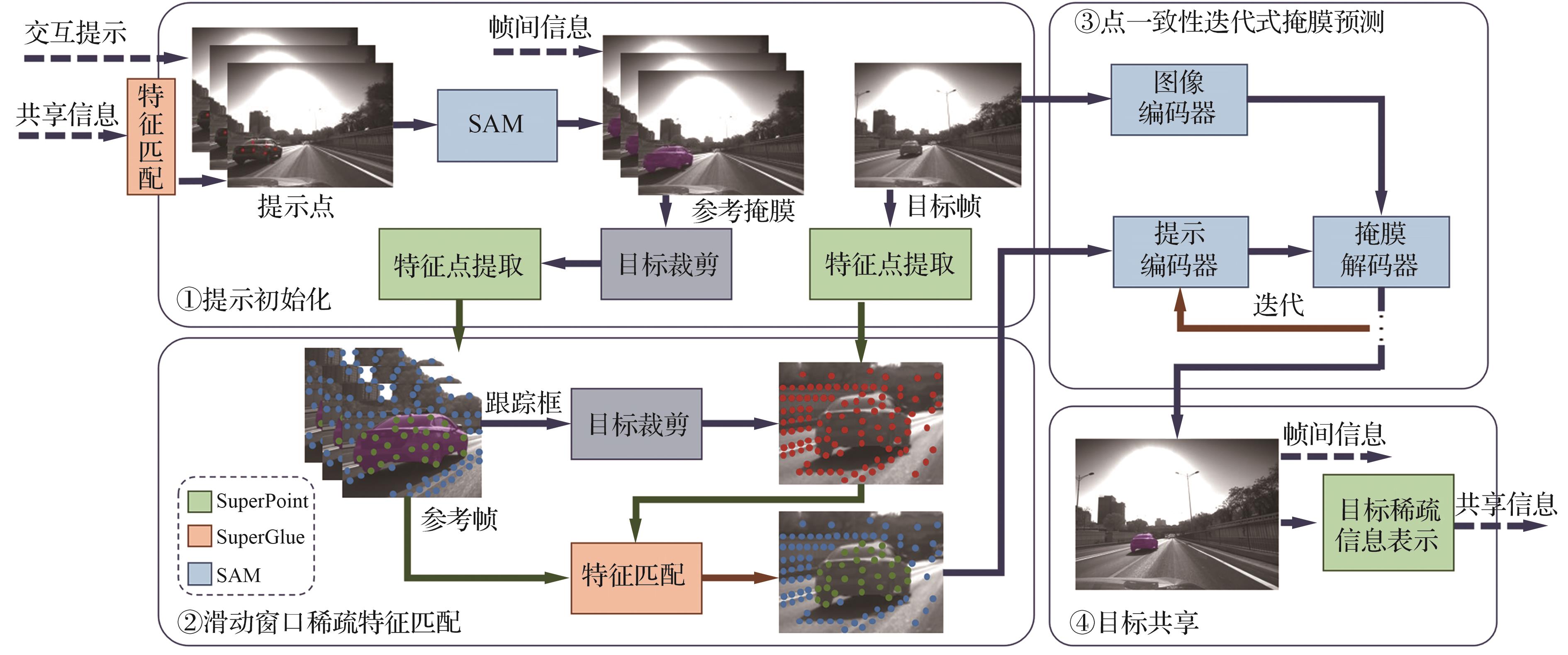
对未知目标的实时感知与持续跟踪是智能系统自主决策的重要前提,在实际应用中存在缺乏目标类别先验信息和训练样本匮乏的问题,使得未知目标的感知与跟踪更具挑战性。针对此问题,提出了一种基于任意分割模型(SAM)与稀疏特征点匹配的未知目标跟踪方法。该方法首先通过提示点引导SAM模型感知并分割图像中的未知目标,随后利用基于卷积神经网络的特征点提取模型,获取目标图像的稀疏特征点作为目标信息,并通过基于注意力机制的匹配网络在后续帧中匹配这些特征点,完成目标信息传播。在此基础上,设计了一个基于特征点一致性的迭代式SAM模块(ISPC),利用匹配的特征点持续引导SAM模型对后续图像帧的目标进行分割,从而实现未知目标的稳定跟踪。此外基于稀疏特征点的轻量化目标信息,可以在多智能体之间高效共享,构建了一个协同式目标跟踪系统。在DAVIS 2017数据集和自构建的近红外视频数据集上,评估了系统的目标跟踪性能与零训练样本目标的泛化能力。实验结果表明,该方法在处理未知类别目标的协同感知与跟踪任务中,表现出良好的鲁棒性和准确性。
中图分类号: