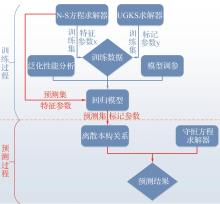
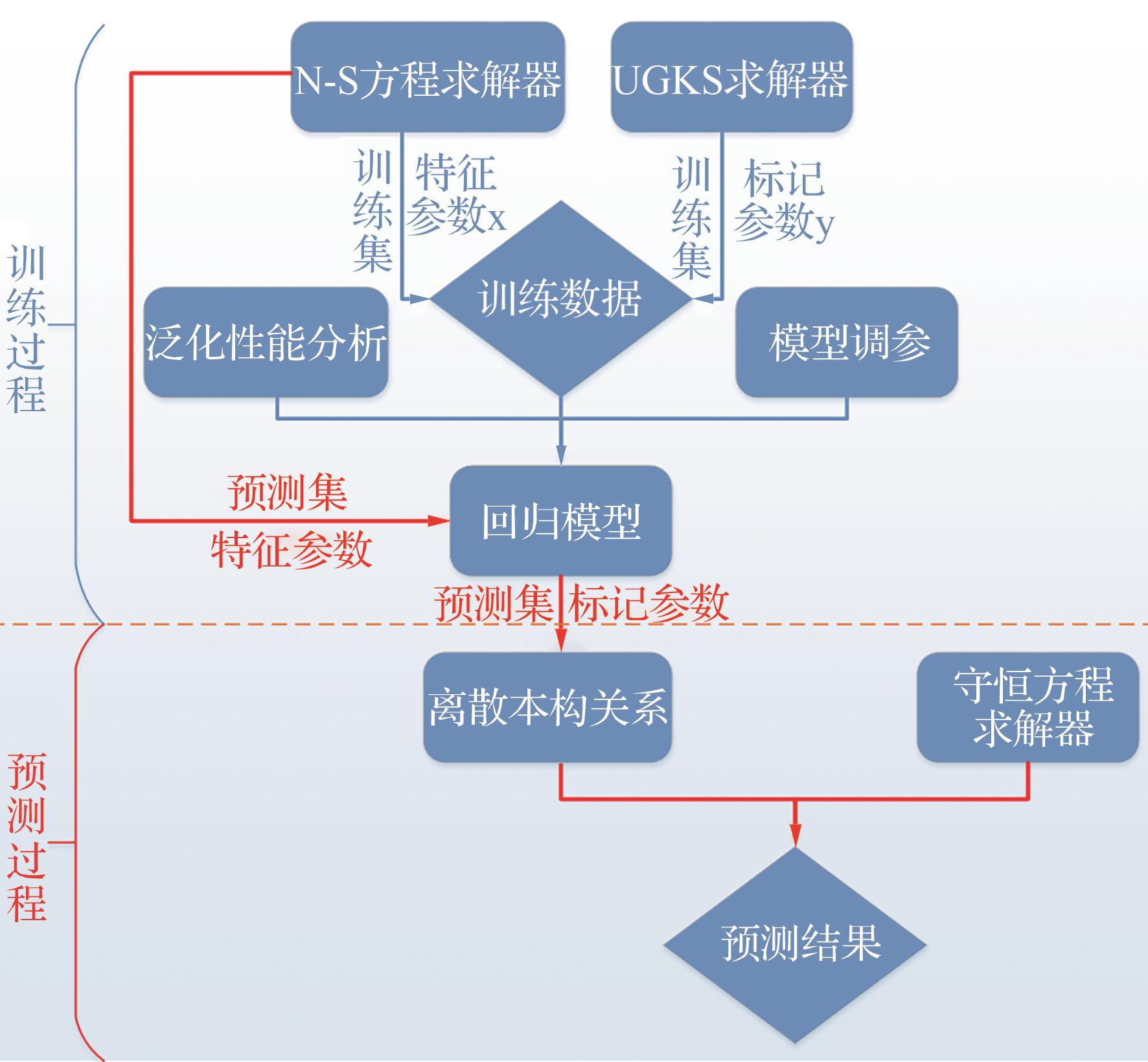
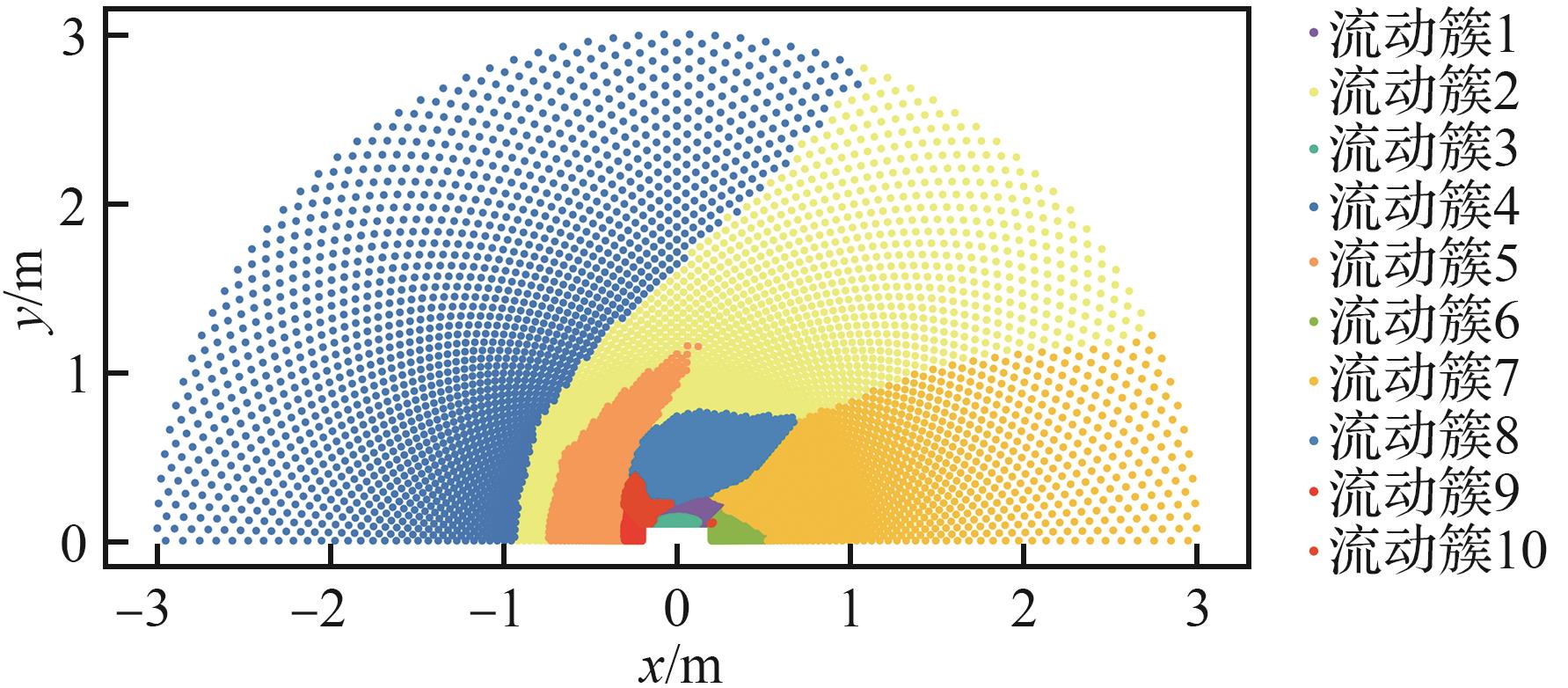
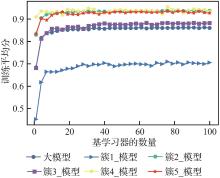
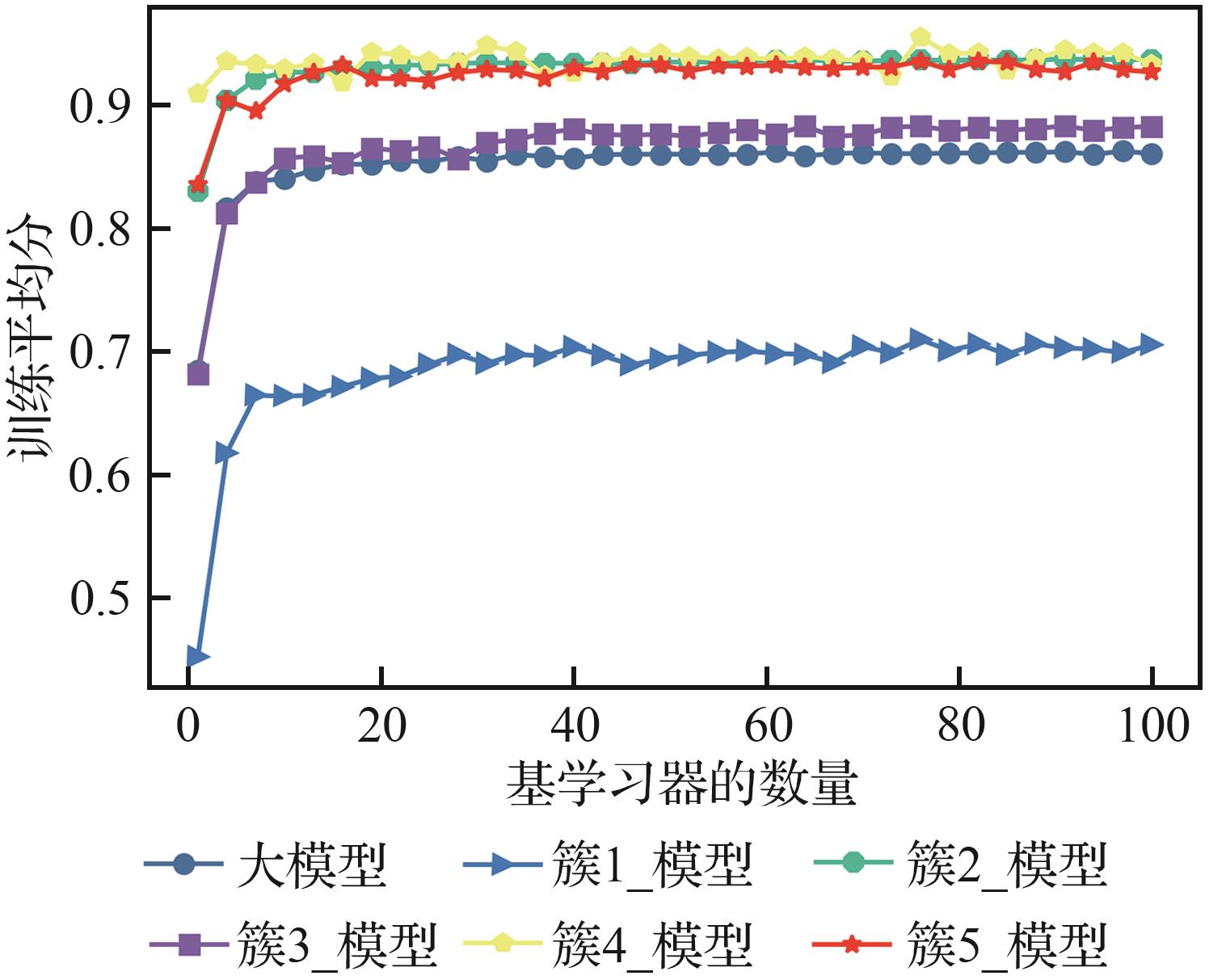
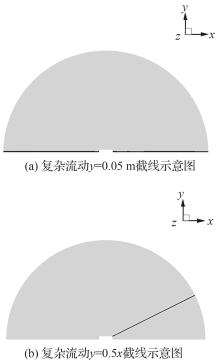
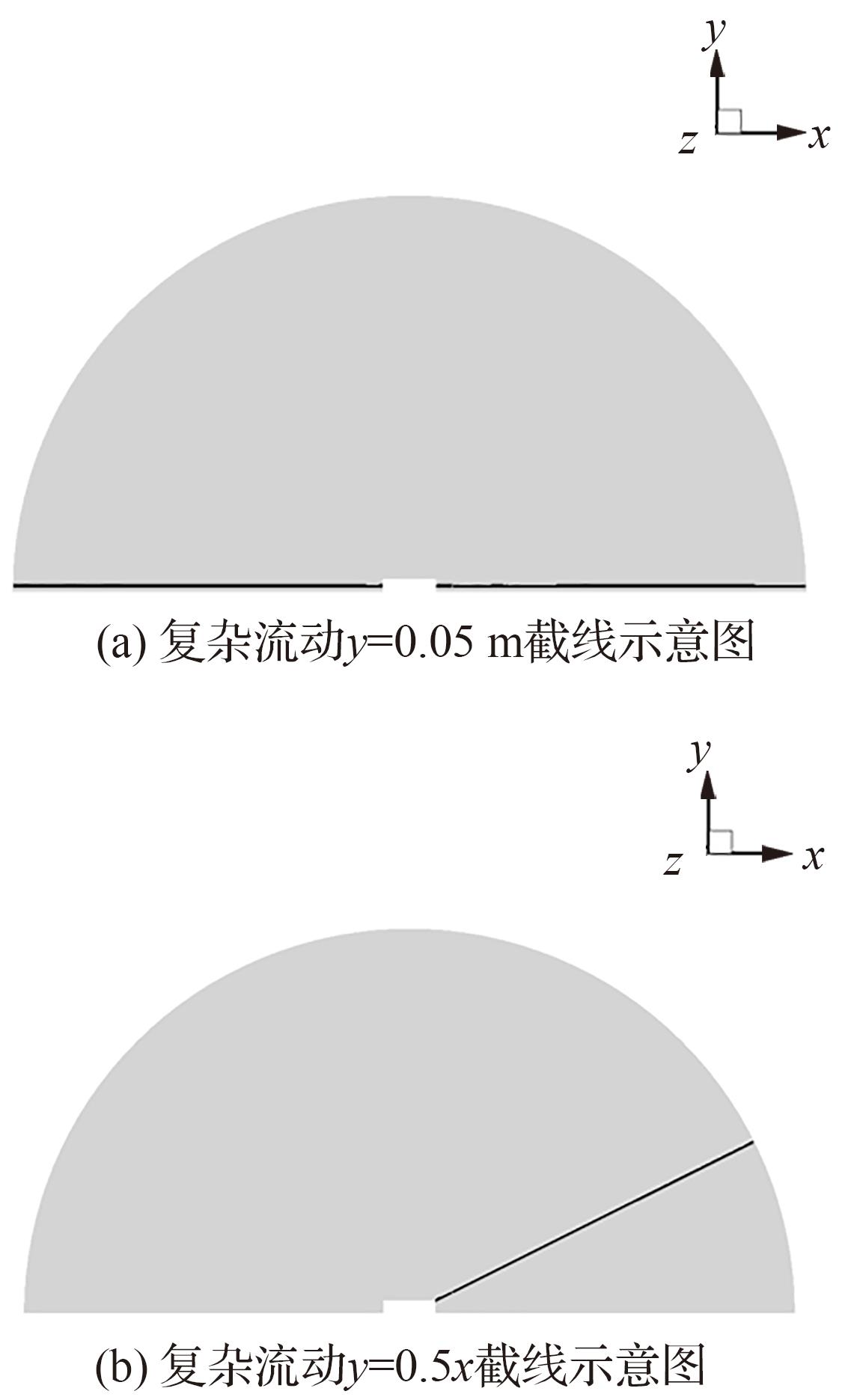
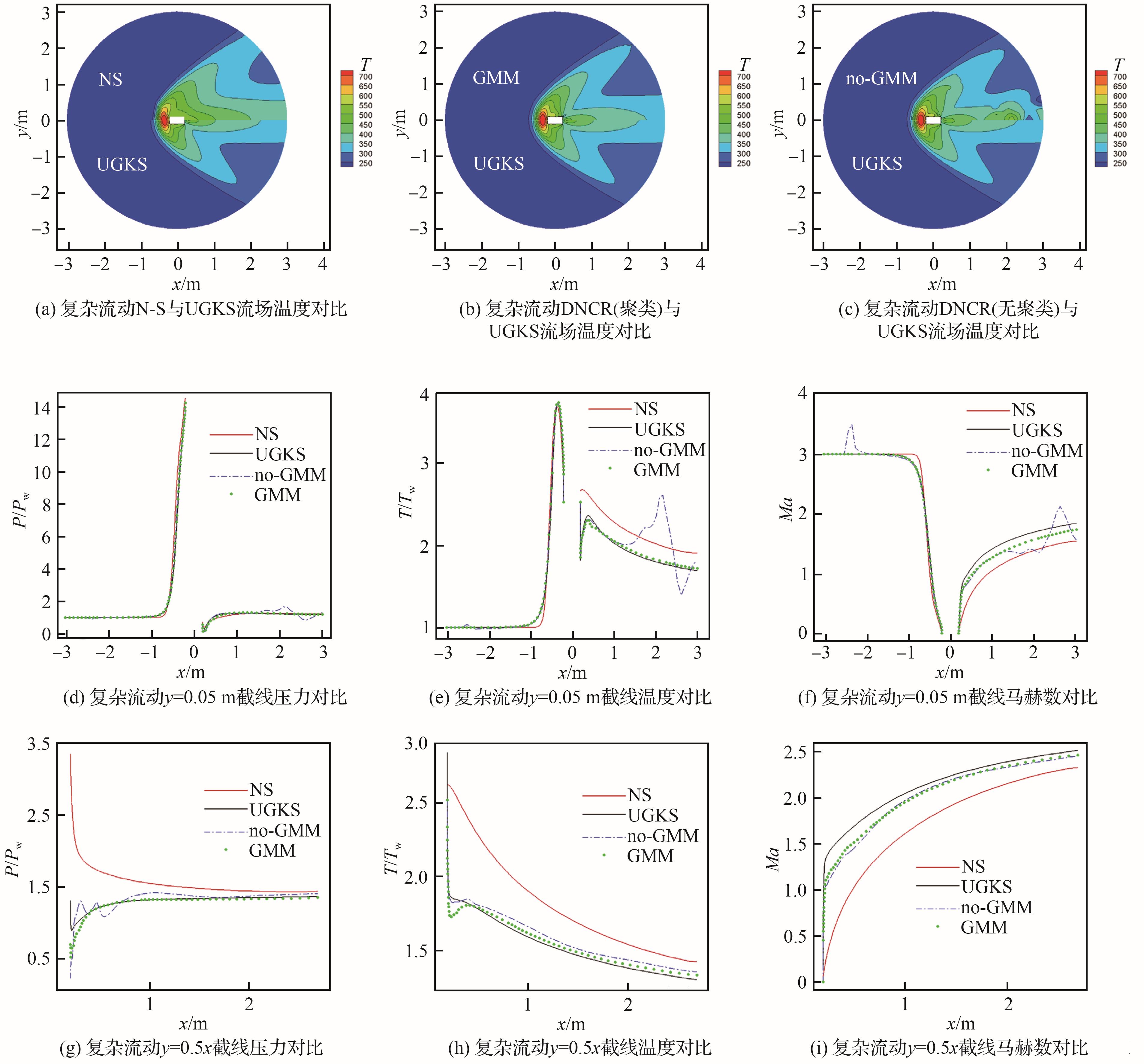
| 1 |
TSIEN H S. Superaerodynamics, mechanics of rarefied gases[J]. Journal of the Aeronautical Sciences, 1946, 13(12): 653-664.
|
| 2 |
BHATNAGAR P L, GROSS E P, KROOK M. A model for collision processes in Gases. I. Small amplitude processes in charged and neutral one-component systems[J]. Physical Review, 1954, 94(3): 511-525.
|
| 3 |
XU K, HUANG J C. A unified gas-kinetic scheme for continuum and rarefied flows[J]. AIP Conference Proceedings, 2011, 1333(1): 525-530.
|
| 4 |
LIU S, YU P, XU K, et al. Unified gas-kinetic scheme for diatomic molecular simulations in all flow regimes[J]. Journal of Computational Physics, 2014, 259: 96-113.
|
| 5 |
周恒, 张涵信. 空气动力学的新问题[J]. 中国科学: 物理学 力学 天文学, 2015, 45(10): 109-113.
|
|
ZHOU H, ZHANG H X. New problems of aerodynamics[J]. Scientia Sinica (Physica, Mechanica & Astronomica), 2015, 45(10): 109-113 (in Chinese).
|
| 6 |
张伟伟, 寇家庆, 刘溢浪. 智能赋能流体力学展望[J]. 航空学报, 2021, 42(4): 524689.
|
|
ZHANG W W, KOU J Q, LIU Y L. Prospect of artificial intelligence empowered fluid mechanics[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 524689 (in Chinese).
|
| 7 |
WANG J X, WU J L, XIAO H. Physics informed machine learning approach for reconstructing Reynolds stress modeling discrepancies based on DNS data[J]. Physical Review Fluids, 2017, 2(3): 1-22.
|
| 8 |
RABAULT J, KUCHTA M, JENSEN A, et al. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control[J]. Journal of Fluid Mechanics, 2019, 865: 281-302.
|
| 9 |
SEKAR V, KHOO B C. Fast flow field prediction over airfoils using deep learning approach[J]. Physics of Fluids, 2019, 31(5): 57103.
|
| 10 |
LI Z, KOVACHKI N, AZIZZADENESHELI K, et al. Fourier neural operator for parametric partial differential equations[DB/OL]. arXiv preprint: 2010.08895, 2020.
|
| 11 |
BAR-SINAI Y, HOYER S, HICKEY J, et al. Learning data-driven discretizations for partial differential equations[J]. Proceedings of the National Academy of Sciences of the United States of America, 2019, 116(31): 15344-15349.
|
| 12 |
KOCHKOV D, SMITH J A, ALIEVA A, et al. Machine learning-accelerated computational fluid dynamics[J]. Proceedings of the National Academy of Sciences of the United States of America, 2021, 118(21): e2101784118.
|
| 13 |
RAISSI M, PERDIKARIS P, KARNIADAKIS G E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations[J]. Journal of Computational Physics, 2019, 378: 686-707.
|
| 14 |
HU L, XIANG Y, ZHAN J, et al. Aerodynamic data predictions based on multi-task learning[J]. Applied Soft Computing, 2021, 116: 108369.
|
| 15 |
ZHANG J, MA W. Data-driven discovery of governing equations for fluid dynamics based on molecular simulation[J]. Journal of Fluid Mechanics, 2020, 892: A5.
|
| 16 |
XING H Y, ZHANG J, MA W J, et al. Using gene expression programming to discover macroscopic governing equations hidden in the data of molecular simulations[J]. Physics of Fluids, 2022, 34(5): 057109.
|
| 17 |
ZHAO W W, JIANG L J, YAO S B, et al. Data-driven nonlinear constitutive relations for rarefied flow computations[J]. Advances in Aerodynamics, 2021, 3(1): 540-558.
|
| 18 |
李廷伟, 张莽, 赵文文, 等. 面向稀薄流非线性本构预测的机器学习方法[J]. 航空学报, 2021, 42(4): 524386.
|
|
LI T W, ZHANG M, ZHAO W W, et al. Machine learning method for correction of rarefied nonlinear constitutive relations[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 524386 (in Chinese).
|
| 19 |
蒋励剑,赵文文,陈伟芳,等. 旋转不变的数据驱动稀薄非线性本构计算方法[J/OL].航空学报, (2021-10-14)[2022-06-30]. .
|
|
JIANG L J, ZHAO W W, CHEN W F, et al. Data-driven rarefied nonlinear constitutive relations based on rotation in-variants[J/OL]. Acta Aeronautica et As-tronautica Sinica, (2021-10-14)[2022-06-30]. .
|
| 20 |
SAFAVIAN S R, LANDGREBE D. A survey of decision tree classifier methodology[J]. IEEE Transactions on Systems, Man, and Cybernetics, 1991, 21(3): 660-674.
|
| 21 |
孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008, 19(1): 48-61.
|
|
SUN J G, LIU J, ZHAO L Y. Clustering algorithms research[J]. Journal of Software, 2008, 19(1): 48-61 (in Chinese).
|
| 22 |
贺玲, 吴玲达, 蔡益朝. 数据挖掘中的聚类算法综述[J]. 计算机应用研究, 2007, 24(1): 10-13.
|
|
HE L, WU L D, CAI Y C. Survey of clustering algorithms in data mining[J]. Application Research of Computers, 2007, 24(1): 10-13 (in Chinese).
|
| 23 |
SUNG H G. Gaussian mixture regression and classification[D]. Houston: Rice University, 2004: 23-47.
|
| 24 |
ZOU H, HASTIE T, TIBSHIRANI R. Sparse principal component analysis[J]. Journal of Computational and Graphical Statistics, 2006, 15(2): 265-286.
|
| 25 |
TSIEN H S. Superaerodynamics, mechanics of rarefied gases[M]. Collected Works of H.S. Tsien (1938-1956). Amsterdam: Elsevier, 2012: 406-429.
|
| 26 |
HARTIGAN J A, WONG M A. Algorithm AS 136: A K-means clustering algorithm[J]. Applied Statistics, 1979, 28(1): 100.
|
| 27 |
WOLD S, ESBENSEN K, GELADI P. Principal component analysis[J]. Chemometrics and Intelligent Laboratory Systems, 1987, 2(1-3): 37-52.
|
| 28 |
CALLAHAM J L, KOCH J V, BRUNTON B W, et al. Learning dominant physical processes with data-driven balance models[J]. Nature Communications, 2021, 12: 1016.
|
| 29 |
GEURTS P, ERNST D, WEHENKEL L. Extremely randomized trees[J]. Machine Learning, 2006, 63(1): 3-42.
|
 ), 卢铮2, 吴昌聚1, 陈伟芳1
), 卢铮2, 吴昌聚1, 陈伟芳1