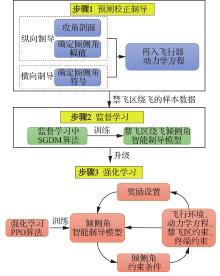
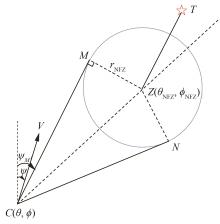
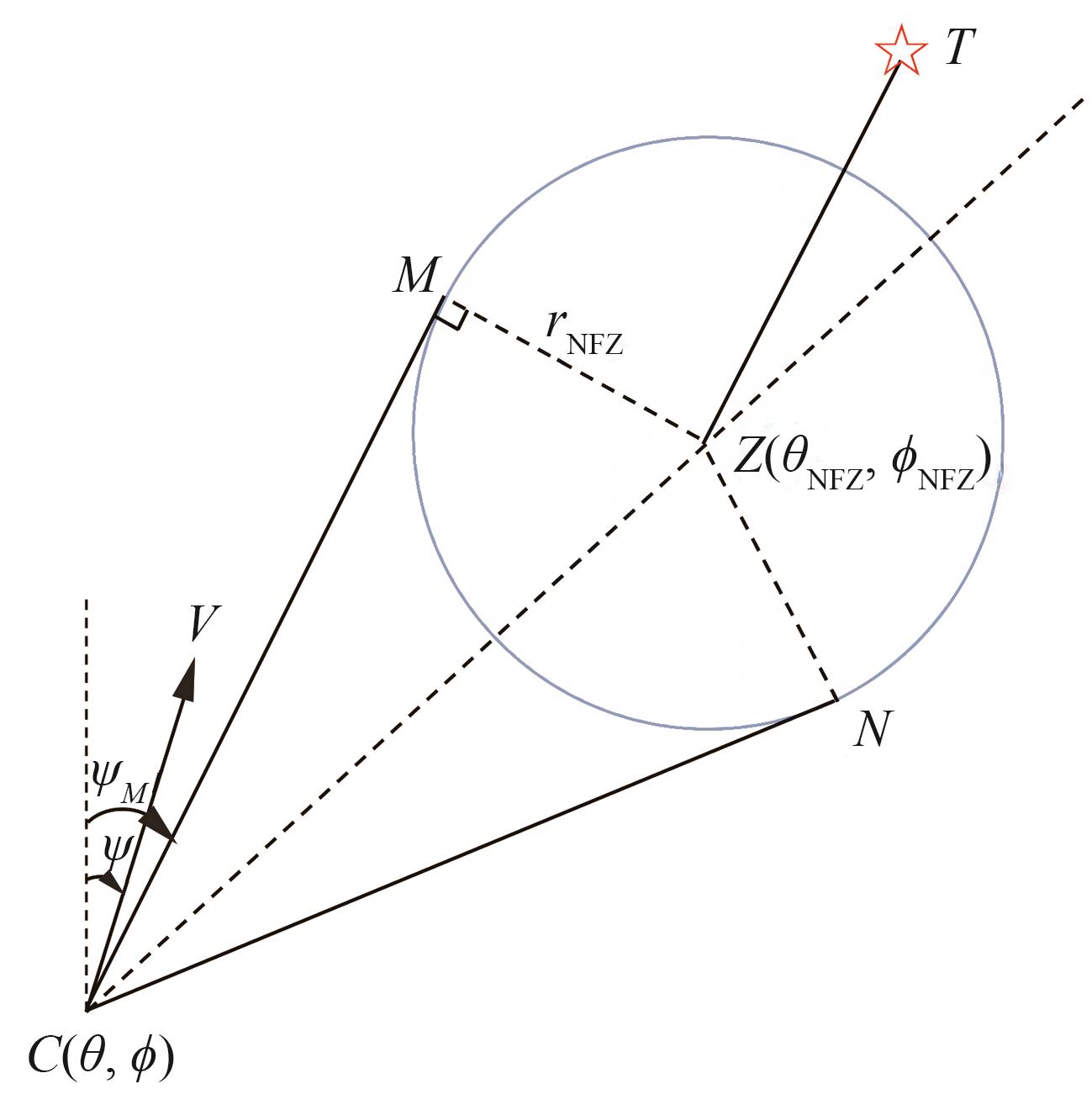
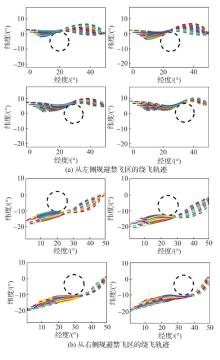
| 1 |
包为民. 航天飞行器控制技术研究现状与发展趋势[J]. 自动化学报, 2013, 39(6): 697-702.
|
|
BAO W M. Present situation and development tendency of aerospace control techniques[J]. Acta Automatica Sinica, 2013, 39(6): 697-702 (in Chinese).
|
| 2 |
高长生, 陈尔康, 荆武兴. 高超声速飞行器机动规避轨迹优化[J]. 哈尔滨工业大学学报, 2017, 49(4): 16-21.
|
|
GAO C S, CHEN E K, JING W X. Maneuver evasion trajectory optimization for hypersonic vehicles[J]. Journal of Harbin Institute of Technology, 2017, 49(4): 16-21 (in Chinese).
|
| 3 |
李柯, 聂万胜, 冯必鸣. 助推-滑翔飞行器规避能力研究[J]. 飞行力学, 2013, 31(2): 148-151, 156.
|
|
LI K, NIE W S, FENG B M. Research on elusion capability of boost-glide vehicle[J]. Flight Dynamics, 2013, 31(2): 148-151, 156 (in Chinese).
|
| 4 |
卢青, 周军, 周敏. 考虑禁飞区的高超声速飞行器再入制导[J]. 西北工业大学学报, 2017, 35(5): 749-754.
|
|
LU Q, ZHOU J, ZHOU M. Reentry guidance for hypersonic vehicle considering no-fly zone[J]. Journal of Northwestern Polytechnical University, 2017, 35(5): 749-754 (in Chinese).
|
| 5 |
高兴, 张璐, 韦常柱. 面向禁飞区约束的再入滑翔飞行器快速轨迹规划[J]. 战术导弹技术, 2018(5): 62-67, 94.
|
|
GAO X, ZHANG L, WEI C Z. Rapid trajectory planning for reentry glide vehicle satisfying no-fly zone constraint[J]. Tactical Missile Technology, 2018(5): 62-67, 94 (in Chinese).
|
| 6 |
赵江, 周锐, 张超. 考虑禁飞区规避的预测校正再入制导方法[J]. 北京航空航天大学学报, 2015, 41(5): 864-870.
|
|
ZHAO J, ZHOU R, ZHANG C. Predictor-corrector reentry guidance satisfying no-fly zone constraints[J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(5): 864-870 (in Chinese).
|
| 7 |
LIANG Z X, LIU S Y, LI Q D, et al. Lateral entry guidance with no-fly zone constraint[J]. Aerospace Science and Technology, 2017, 60: 39-47.
|
| 8 |
ZHANG D, LIU L, WANG Y J. On-line reentry guidance algorithm with both path and no-fly zone constraints[J]. Acta Astronautica, 2015, 117: 243-253.
|
| 9 |
赵亮博, 徐玮, 董超, 等. 基于虚拟目标导引的再入飞行器禁飞区规避制导方法研究[J]. 中国科学: 物理学 力学 天文学, 2021, 51(10): 65-74.
|
|
ZHAO L B, XU W, DONG C, et al. Evasion guidance of re-entry vehicle satisfying no-fly zone constraints based on virtual goals[J]. Scientia Sinica (Physica, Mechanica & Astronomica), 2021, 51(10): 65-74 (in Chinese).
|
| 10 |
章吉力, 周大鹏, 杨大鹏, 等. 禁飞区影响下的空天飞机可达区域计算方法[J]. 航空学报, 2021, 42(8): 525771.
|
|
ZHANG J L, ZHOU D P, YANG D P, et al. Computation method for reachable domain of aerospace plane under the influence of no-fly zone[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 525771 (in Chinese).
|
| 11 |
章吉力, 刘凯, 樊雅卓, 等. 考虑禁飞区规避的空天飞行器分段预测校正再入制导方法[J]. 宇航学报, 2021, 42(1): 122-131.
|
|
ZHANG J L, LIU K, FAN Y Z, et al. A piecewise predictor-corrector re-entry guidance algorithm with no-fly zone avoidance[J]. Journal of Astronautics, 2021, 42(1): 122-131 (in Chinese).
|
| 12 |
LIANG Z X, REN Z. Tentacle-based guidance for entry flight with no-fly zone constraint[J]. Journal of Guidance, Control, and Dynamics, 2018, 41(4): 996-1005.
|
| 13 |
高杨, 蔡光斌, 徐慧, 等. 虚拟多触角探测的高超声速滑翔飞行器再入机动制导[J]. 航空学报, 2020, 41(11): 623703.
|
|
GAO Y, CAI G B, XU H, et al. Reentry maneuver guidance of hypersonic glide vehicle under virtual multi-tentacle detection[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(11): 623703 (in Chinese).
|
| 14 |
LI Z H, YANG X J, SUN X D, et al. Improved artificial potential field based lateral entry guidance for waypoints passage and no-fly zones avoidance[J]. Aerospace Science and Technology, 2019, 86: 119-131.
|
| 15 |
YU W B, CHEN W C, JIANG Z G, et al. Analytical entry guidance for no-fly-zone avoidance[J]. Aerospace Science and Technology, 2018, 72: 426-442.
|
| 16 |
SUTTON R S, BARTO A G. Reinforcement learning: An introduction[M]. Cambridge: MIT Press, 2011: 119-138.
|
| 17 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
|
| 18 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[DB/OL]. arXiv perprint: 1509.02971, 2015.
|
| 19 |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[DB/OL]. arXiv preprint: 1801.01290, 2018.
|
| 20 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arXiv preprint: 1707.06347, 2017.
|
| 21 |
张秦浩, 敖百强, 张秦雪. Q-learning强化学习制导律[J]. 系统工程与电子技术, 2020, 42(2): 414-419.
|
|
ZHANG Q H, AO B Q, ZHANG Q X. Reinforcement learning guidance law of Q-learning[J]. Systems Engineering and Electronics, 2020, 42(2): 414-419 (in Chinese).
|
| 22 |
GAUDET B, FURFARO R, LINARES R. Reinforcement learning for angle-only intercept guidance of maneuvering targets[DB/OL]. arXiv preprint: 1906.02113, 2019.
|
| 23 |
HOVELL K, ULRICH S. Deep reinforcement learning for spacecraft proximity operations guidance[J]. Journal of Spacecraft and Rockets, 2021, 58(2): 254-264.
|
| 24 |
HOVELL K, ULRICH S. On deep reinforcement learning for spacecraft guidance: AIAA-2020-1600[R]. Reston: AIAA, 2020.
|
| 25 |
郭冬子, 黄荣, 许河川, 等. 再入飞行器深度确定性策略梯度制导方法研究[J/OL]. 系统工程与电子技术, (2021-09-29) [2022-05-11]. .
|
|
GUO D Z, HUANG R, XU H C, et al. Research on deep deterministic policy gradient reinforcement learning guidance method for reentry vehicle[J/OL]. Systems Engineering and Electronics, (2021-09-29) [2022-05-11]. .
|
| 26 |
刘扬, 何泽众, 王春宇, 等. 基于DDPG算法的末制导律设计研究[J]. 计算机学报, 2021, 44(9): 1854-1865.
|
|
LIU Y, HE Z Z, WANG C Y, et al. Terminal guidance law design based on DDPG algorithm[J]. Chinese Journal of Computers, 2021, 44(9): 1854-1865 (in Chinese).
|
| 27 |
张晚晴, 余文斌, 李静琳, 等. 基于纵程解析解的飞行器智能横程机动再入协同制导[J]. 兵工学报, 2021, 42(7): 1400-1411.
|
|
ZHANG W Q, YU W B, LI J L, et al. Cooperative reentry guidance for intelligent lateral maneuver of hypersonic vehicle based on downrange analytical solution[J]. Acta Armamentarii, 2021, 42(7): 1400-1411 (in Chinese).
|
| 28 |
CHAI R Q, TSOURDOS A, SAVVARIS A, et al. Six-DOF spacecraft optimal trajectory planning and real-time attitude control: A deep neural network-based approach[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(11): 5005-5013.
|
| 29 |
黄旭, 柳嘉润, 贾晨辉, 等. 深度确定性策略梯度算法用于无人飞行器控制[J]. 航空学报, 2021, 42(11): 524688.
|
|
HUANG X, LIU J R, JIA C H, et al. Deep deterministic policy gradient algorithm for UAV control[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(11): 524688 (in Chinese).
|
| 30 |
裴培, 何绍溟, 王江, 等. 一种深度强化学习制导控制一体化算法[J]. 宇航学报, 2021, 42(10): 1293-1304.
|
|
PEI P, HE S M, WANG J, et al. Integrated guidance and control for missile using deep reinforcement learning[J]. Journal of Astronautics, 2021, 42(10): 1293-1304 (in Chinese).
|
| 31 |
郭继峰, 陈宇燊, 白成超. 基于强化学习的在轨目标逼近[J]. 航天控制, 2021, 39(5): 44-50.
|
|
GUO J F, CHEN Y S, BAI C C. On-orbit target approach based on reinforcement learning[J]. Aerospace Control, 2021, 39(5): 44-50 (in Chinese).
|
| 32 |
惠俊鹏, 汪韧, 俞启东. 基于强化学习的再入飞行器“新质”走廊在线生成技术[J]. 航空学报, 2022, 43(9): 325960.
|
|
HUI J P, WANG R, YU Q D. Generating new quality flight corridor for reentry aircraft based on reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(9): 325960 (in Chinese).
|
| 33 |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
|
| 34 |
SUTSKEVER I, MARTENS J, DAHL G, et al. On the importance of initialization and momentum in deep learning[C]∥ Proceedings of the 30th International Conference on International Conference on Machine Learning-Volume 28. New York: ACM, 2013: 1139-1147.
|
| 35 |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
|
| 36 |
汪韧, 惠俊鹏, 俞启东, 等. 基于LSTM模型的飞行器智能制导技术研究[J]. 力学学报, 2021, 53(7): 2047-2057.
|
|
WANG R, HUI J P, YU Q D, et al. Research of LSTM model-based intelligent guidance of flight aircraft[J]. Chinese Journal of Theoretical and Applied Mechanics, 2021, 53(7): 2047-2057 (in Chinese).
|
 ), 汪韧2, 郭继峰1
), 汪韧2, 郭继峰1