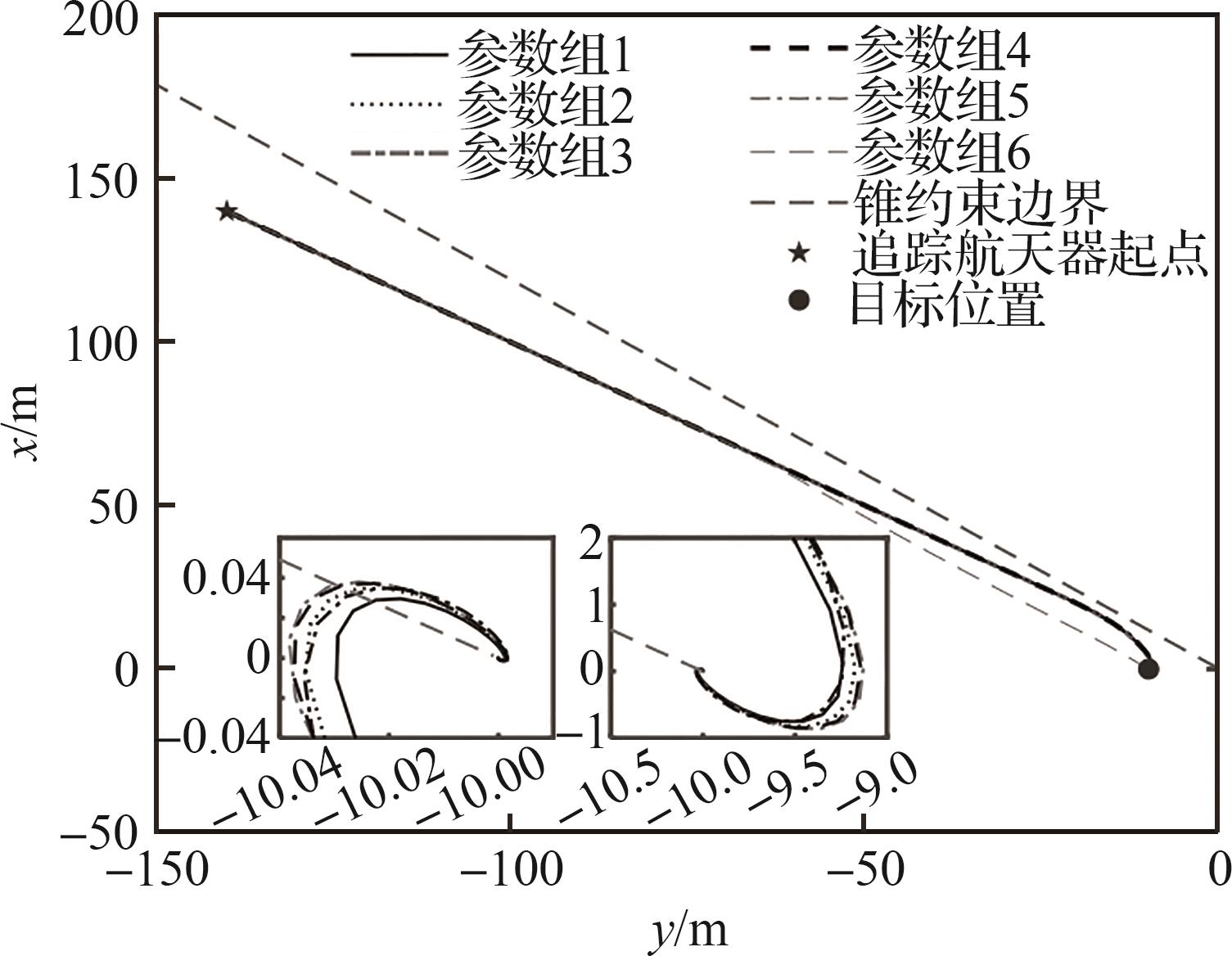
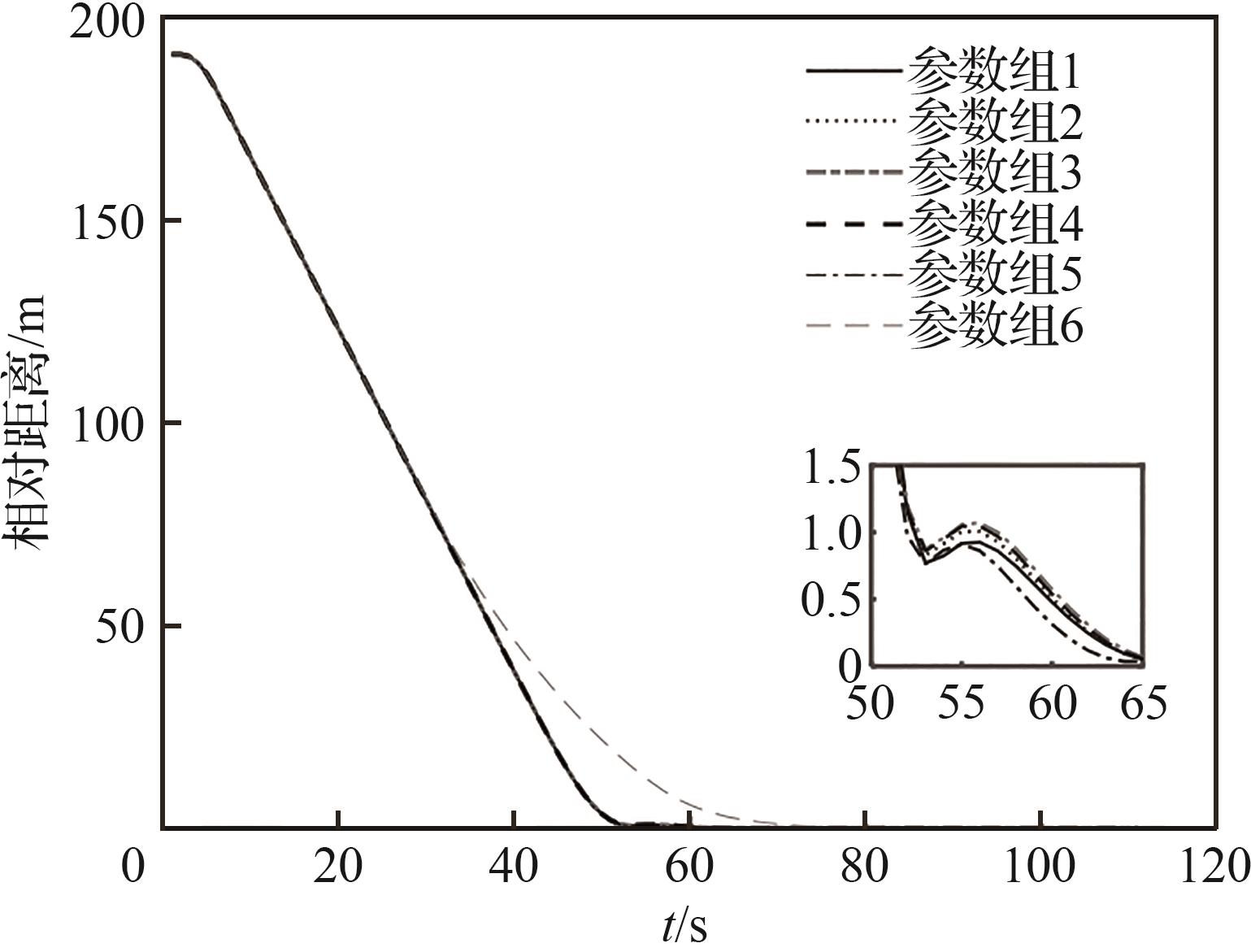
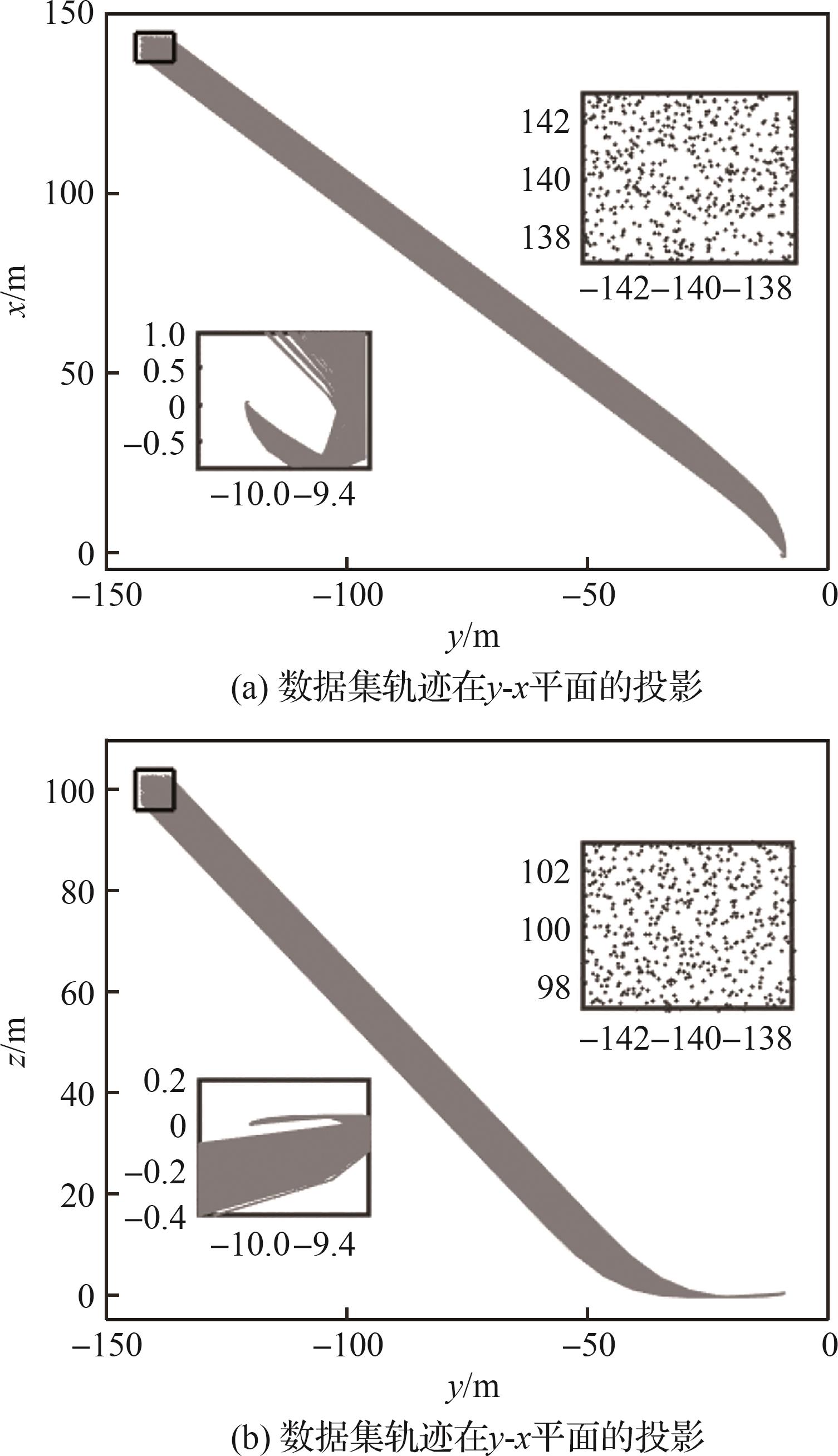
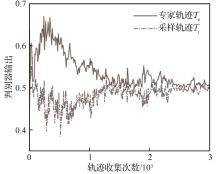
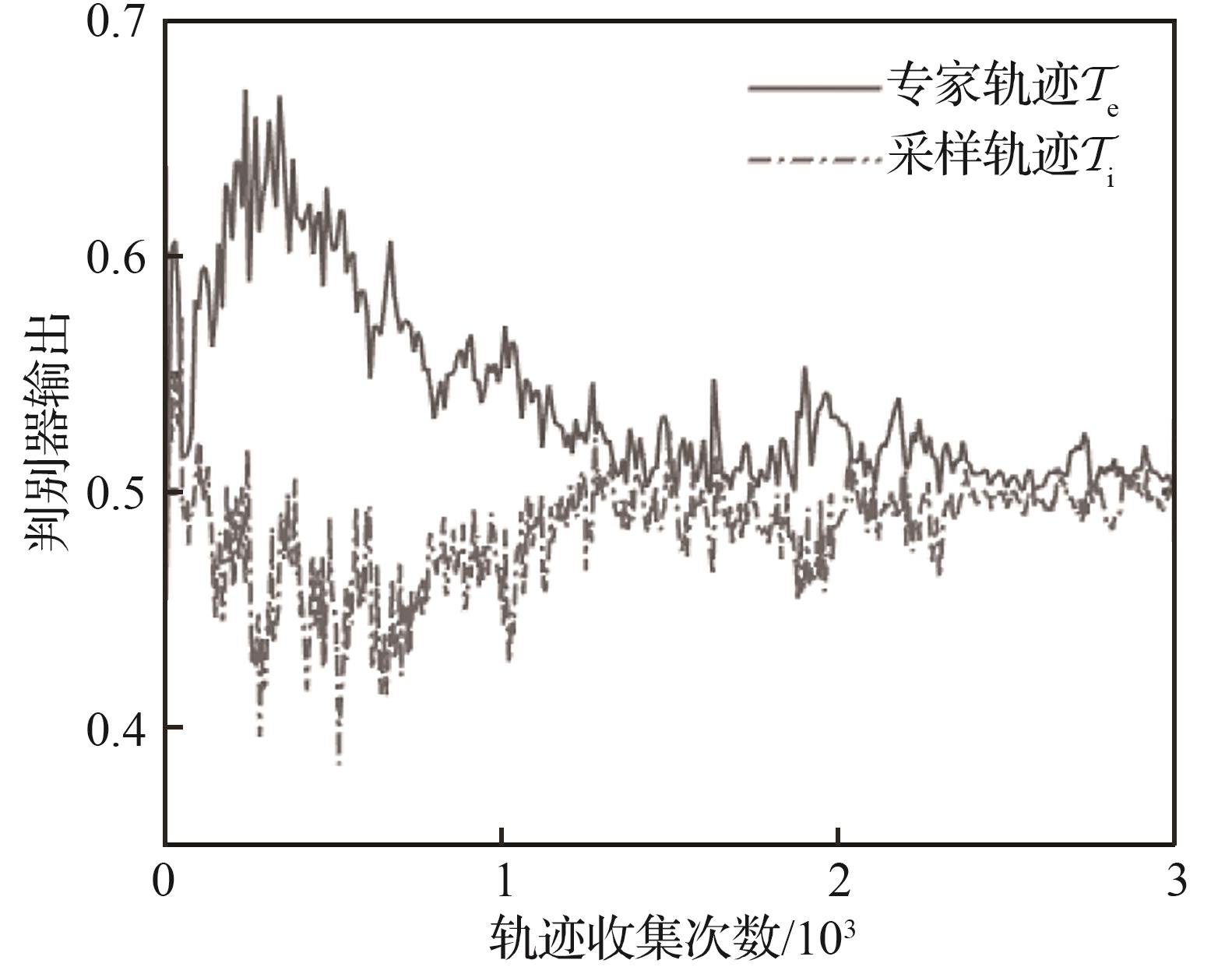
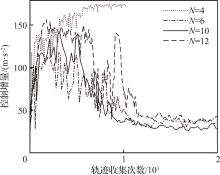
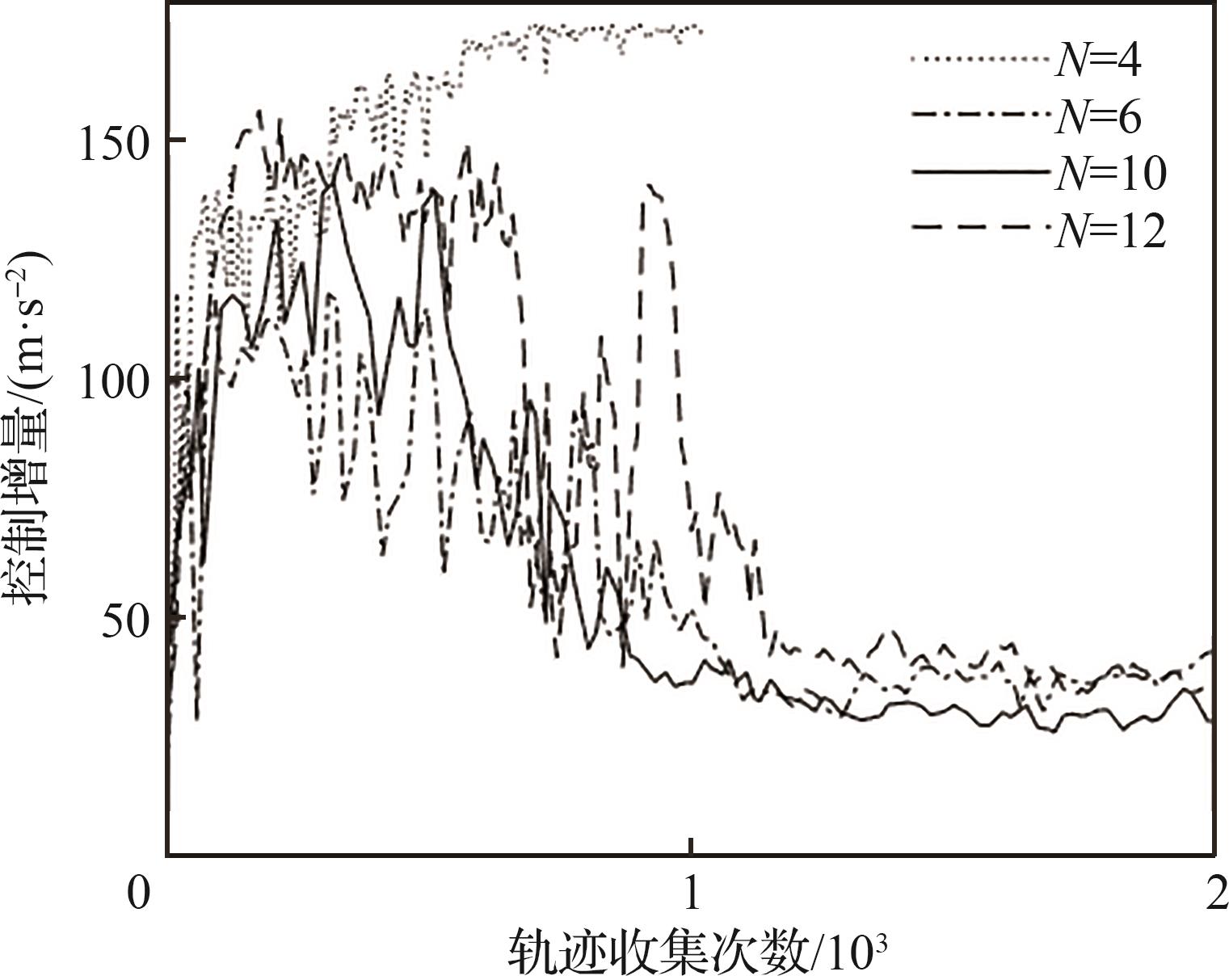
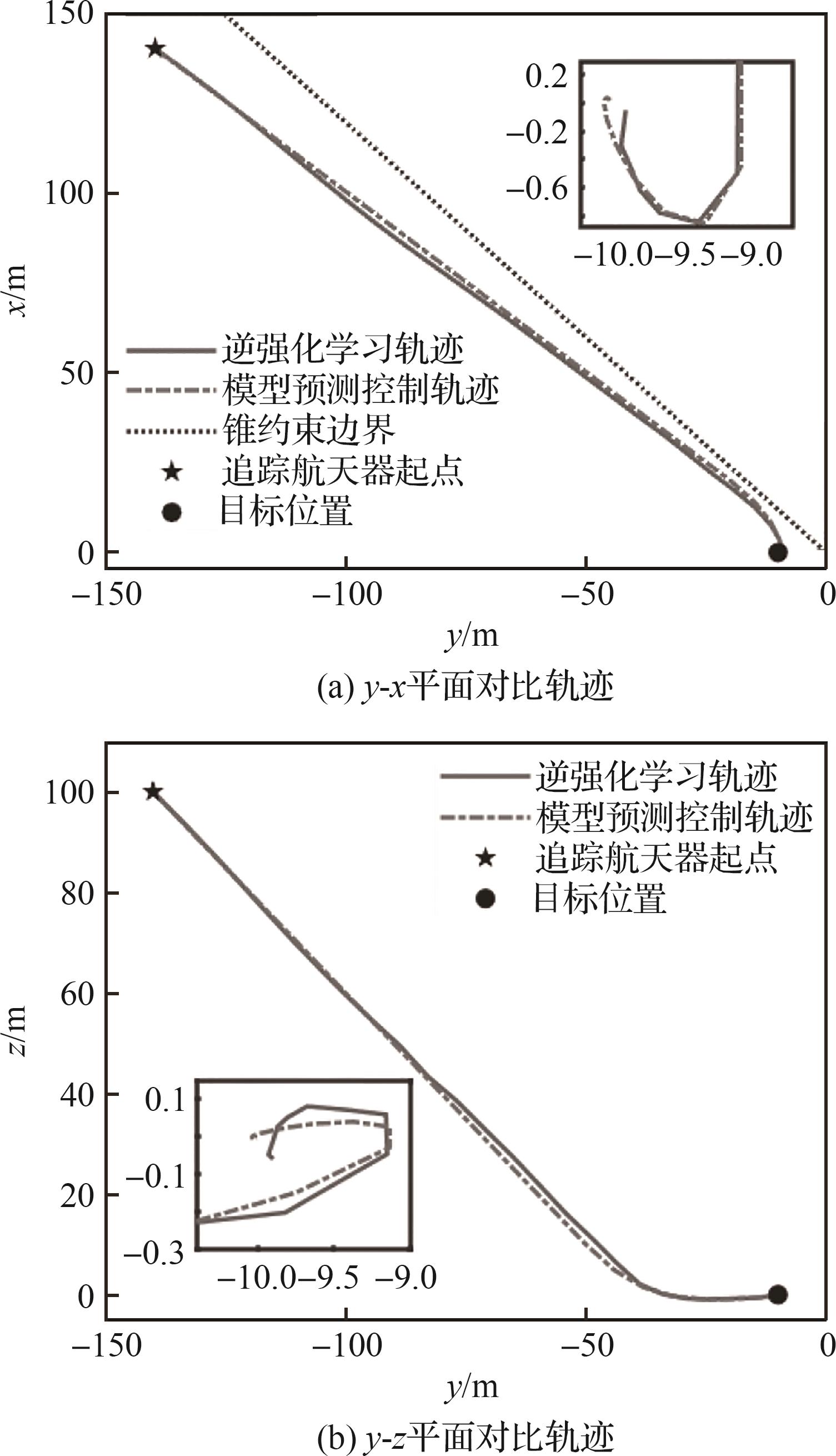
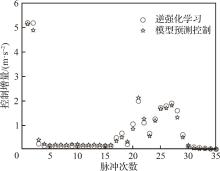
| 1 |
林来兴. 空间碎片现状与清理[J]. 航天器工程, 2012, 21(3): 1-10.
|
|
LIN L X. Status and removal of space debris[J]. Spacecraft Engineering, 2012, 21(3): 1-10 (in Chinese).
|
| 2 |
孟云鹤. 近地轨道航天器编队飞行控制与应用研究[D]. 长沙: 国防科学技术大学, 2006: 1-6.
|
|
MENG Y H. Research on control and application of LEO spacecraft formation flying[D]. Changsha: National University of Defense Technology, 2006 : 1-6 (in Chinese).
|
| 3 |
赵力冉, 党朝辉, 张育林. 空间轨道博弈: 概念、原理与方法[J]. 指挥与控制学报, 2021, 7(3): 215-224.
|
|
ZHAO L R, DANG Z H, ZHANG Y L. Orbital game: Concepts, principles and methods[J]. Journal of Command and Control, 2021, 7(3): 215-224 (in Chinese).
|
| 4 |
LI Q, YUAN J P, ZHANG B, et al. Model predictive control for autonomous rendezvous and docking with a tumbling target[J]. Aerospace Science and Technology, 2017, 69: 700-711.
|
| 5 |
MAMMARELLA M, CAPELLO E, PARK H, et al. Tube-based robust model predictive control for spacecraft proximity operations in the presence of persistent disturbance[J]. Aerospace Science and Technology, 2018, 77: 585-594.
|
| 6 |
LI P, ZHU Z H. Line-of-sight nonlinear model predictive control for autonomous rendezvous in elliptical orbit[J]. Aerospace Science and Technology, 2017, 69: 236-243.
|
| 7 |
李成录. 大数据背景下机器学习算法的综述[J]. 信息记录材料, 2018, 19(5): 4-5.
|
|
LI C L. Under the background of big data review of machine learning algorithms[J]. Information Recording Materials, 2018, 19(5): 4-5 (in Chinese).
|
| 8 |
龙慧, 朱定局, 田娟. 深度学习在智能机器人中的应用研究综述[J]. 计算机科学, 2018, 45(S2): 43-47, 52.
|
|
LONG H, ZHU D J, TIAN J. Research on deep learning used in intelligent robots[J]. Computer Science, 2018, 45(S2): 43-47, 52 (in Chinese).
|
| 9 |
吴今培. 智能故障诊断技术的发展和展望[J]. 振动 测试与诊断, 1999, 19(2): 79-86.
|
|
WU J P. Development and prospect of intelligent fault diagnosis[J]. Journal of Vibration, Measurement & Diagnosis, 1999, 19(2): 79-86. (in Chinese)
|
| 10 |
HUA J A, ZENG L C, LI G F, et al. Learning for a robot: Deep reinforcement learning, imitation learning, transfer learning[J]. Sensors, 2021, 21(4): 1278.
|
| 11 |
FANG B, JIA S D, GUO D, et al. Survey of imitation learning for robotic manipulation[J]. International Journal of Intelligent Robotics and Applications, 2019, 3(4): 362-369.
|
| 12 |
NG A Y, RUSSELL S J. Algorithms for inverse reinforcement learning[C]∥International Conference on Machine Learning. San Franciso: Morgan Kaufmann Publishers Inc., 2000: 663-670.
|
| 13 |
ZIEBART B D, MAAS A, BAGNELL J A, et al. Maximum entropy inverse reinforcement learning[C]∥ Proceedings of the National Conference on Artificial Intelligence.Washington, D.C.: AAAI, 2008: 1433-1438.
|
| 14 |
AGHASADEGHI N, BRETL T. Maximum entropy inverse reinforcement learning in continuous state spaces with path integrals[C]∥ 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE Press, 2011: 1561-1566.
|
| 15 |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[DB/OL]. arXiv preprint: 1406.2661, 2014.
|
| 16 |
FINN C, CHRISTIANO P, ABBEEL P, et al. A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models[DB/OL]. arXiv preprint: 1611.03852, 2016.
|
| 17 |
BING Z S, LEMKE C, CHENG L, et al. Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning[J]. Neural Networks, 2020, 129: 323-333.
|
| 18 |
LI F J, WAGNER J, WANG Y E. Safety-aware adversarial inverse reinforcement learning for highway autonomous driving[J]. Journal of Autonomous Vehicles and Systems, 2021, 1(4): 041004.
|
| 19 |
FEDERICI L, BENEDIKTER B, ZAVOLI A. Machine learning techniques for autonomous spacecraft guidance during proximity operations:AIAA-2021-0668[R]. Reston: AIAA, 2021.
|
| 20 |
CLOHESSY W H, WILTSHIRE R S. Terminal guidance system for satellite rendezvous[J]. Journal of the Aerospace Sciences, 1960, 27(9): 653-658.
|
| 21 |
袁亚湘, 孙文瑜. 最优化理论与方法[M]. 北京: 科学出版社, 1997.422-426.
|
|
YUAN Y X, SUN W Y. Optimization theory and method[M]. Beijing: Science Press, 1997. 422-426 (in Chinese).
|
| 22 |
陈希亮, 曹雷, 何明, 等. 深度逆向强化学习研究综述[J]. 计算机工程与应用, 2018, 54(5): 24-35.
|
|
CHEN X L, CAO L, HE M, et al. Overview of deep inverse reinforcement learning[J]. Computer Engineering and Applications, 2018, 54(5): 24-35 (in Chinese).
|
| 23 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arXiv preprint: 1707.06347, 2017.
|
 ), 岳晓奎1,2, 宋婷3,4
), 岳晓奎1,2, 宋婷3,4