Acta Aeronautica et Astronautica Sinica ›› 2025, Vol. 46 ›› Issue (8): 331035.doi: 10.7527/S1000-6893.2024.31035
• Electronics and Electrical Engineering and Control • Previous Articles
Lingfeng JIANG1, Xinkai LI1( ), Hai ZHANG2, Hanwei LI1, Hongli ZHANG3
), Hai ZHANG2, Hanwei LI1, Hongli ZHANG3
Received:2024-08-02
Revised:2024-11-04
Accepted:2024-12-06
Online:2024-12-13
Published:2024-12-12
Contact:
Xinkai LI
E-mail:lxk@xju.edu.cn
Supported by:CLC Number:
Lingfeng JIANG, Xinkai LI, Hai ZHANG, Hanwei LI, Hongli ZHANG. Mapless navigation of UAVs in dynamic environments based on an improved TD3 algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331035.
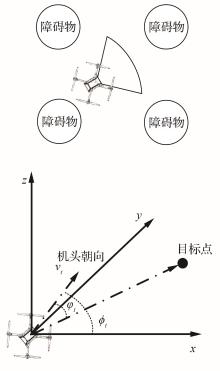
Fig.1
UAV navigation diagram

Fig.2
Depth image schematic

Fig.3
Model of UAV obstacle avoidance navigation system
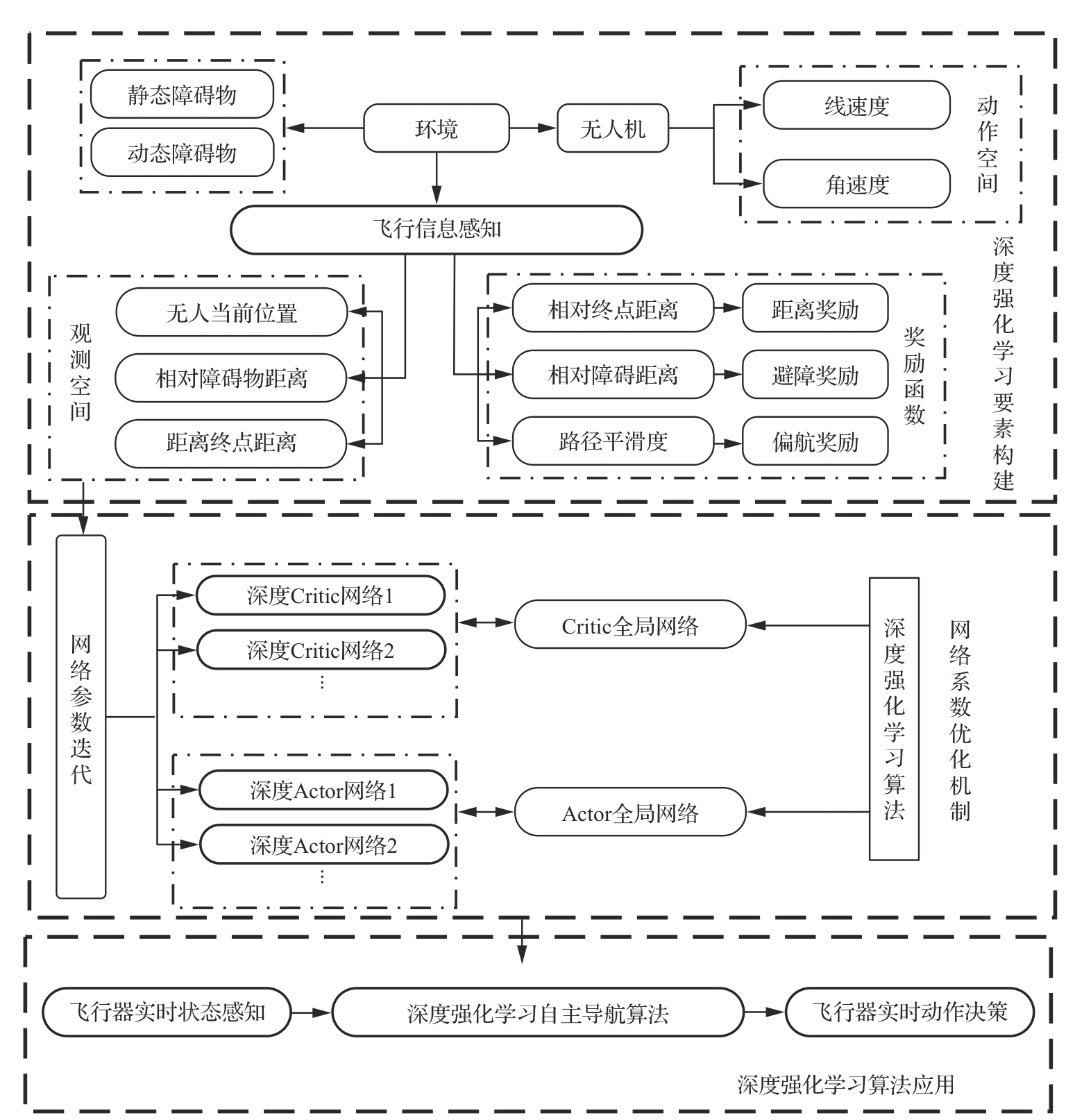
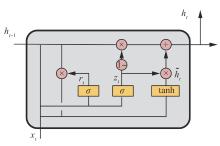
Fig.4
GRU network structure
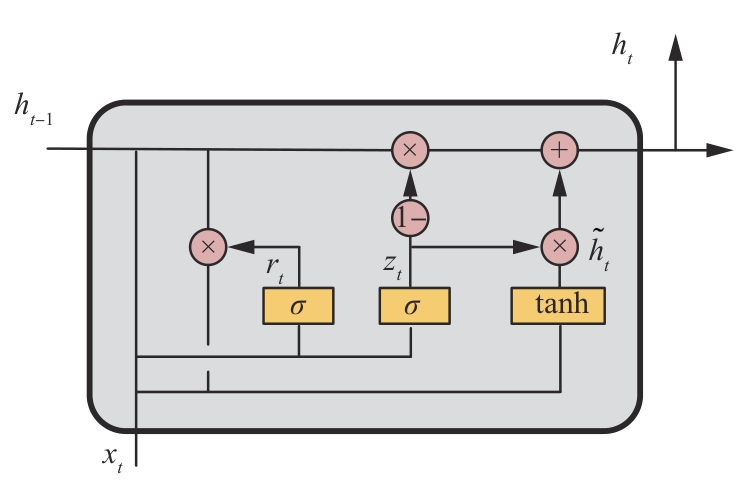
Fig.5
Feasible direction diagram
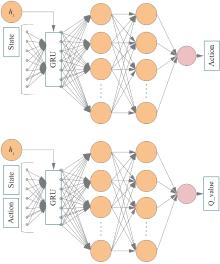
Fig.6
Structure diagram of Actor and Critic network
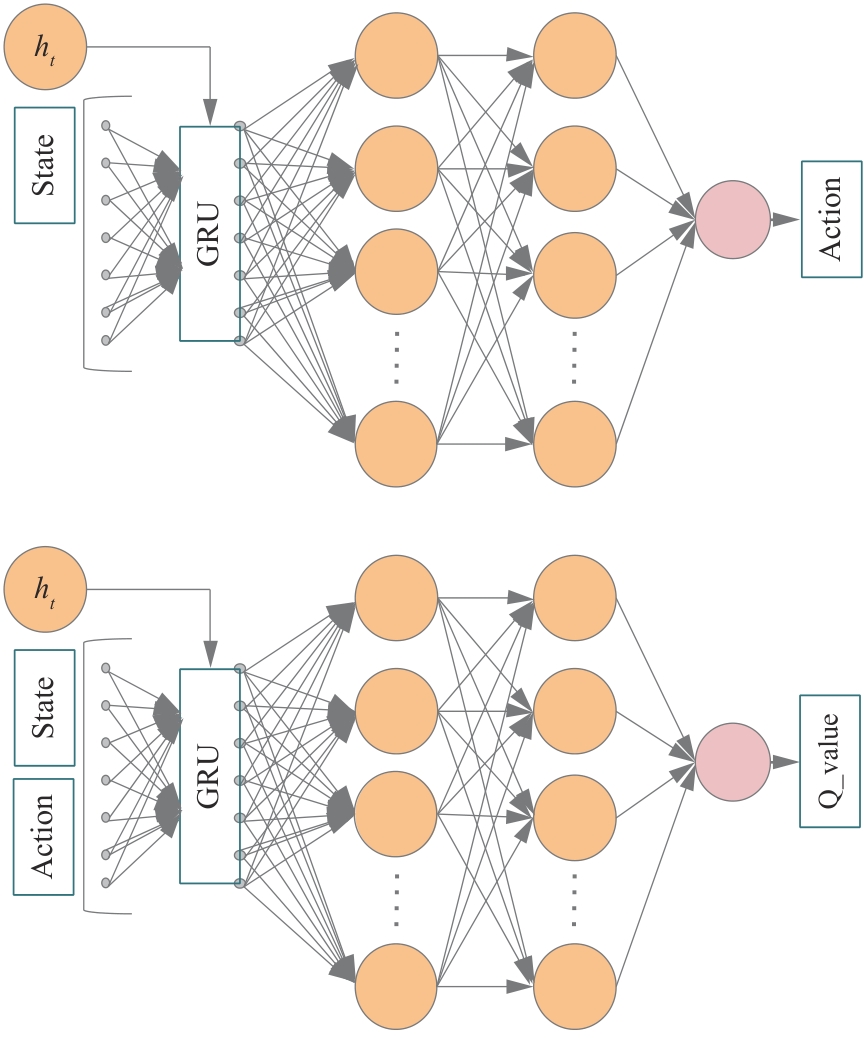
Fig.7
TD3 network structure diagram
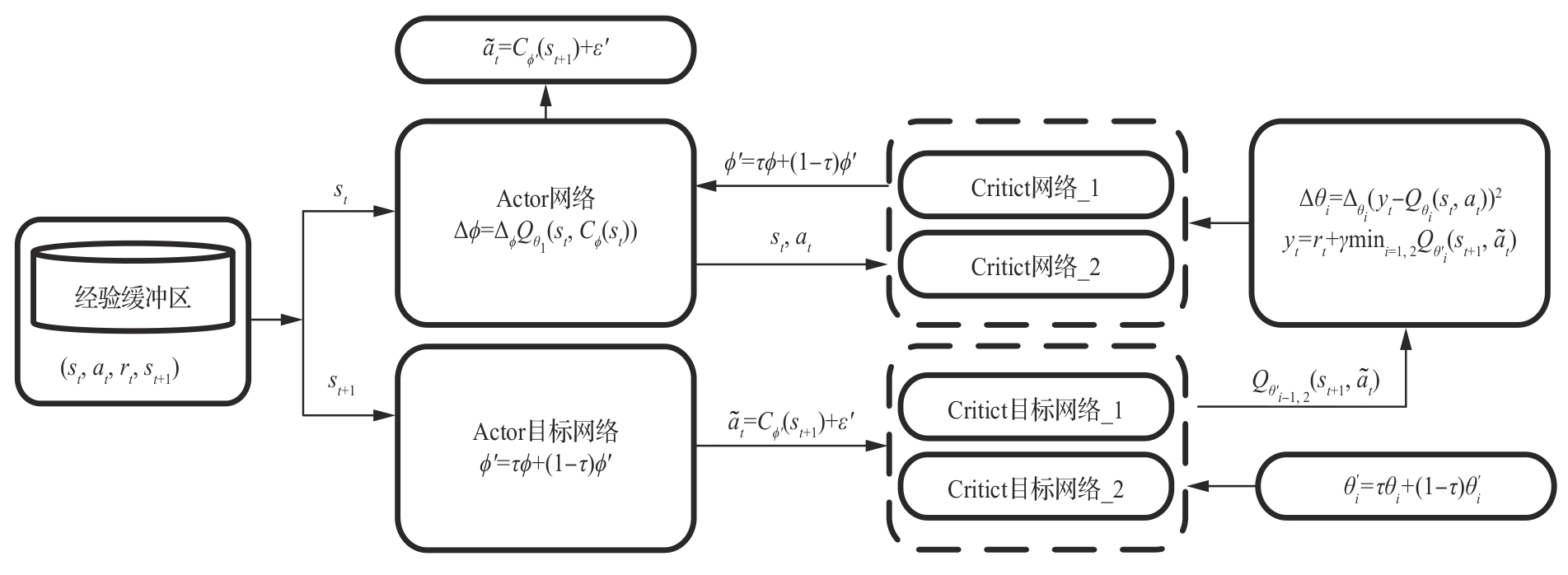
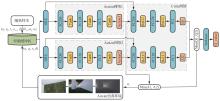
Fig.8
G-SD3 network frame diagram
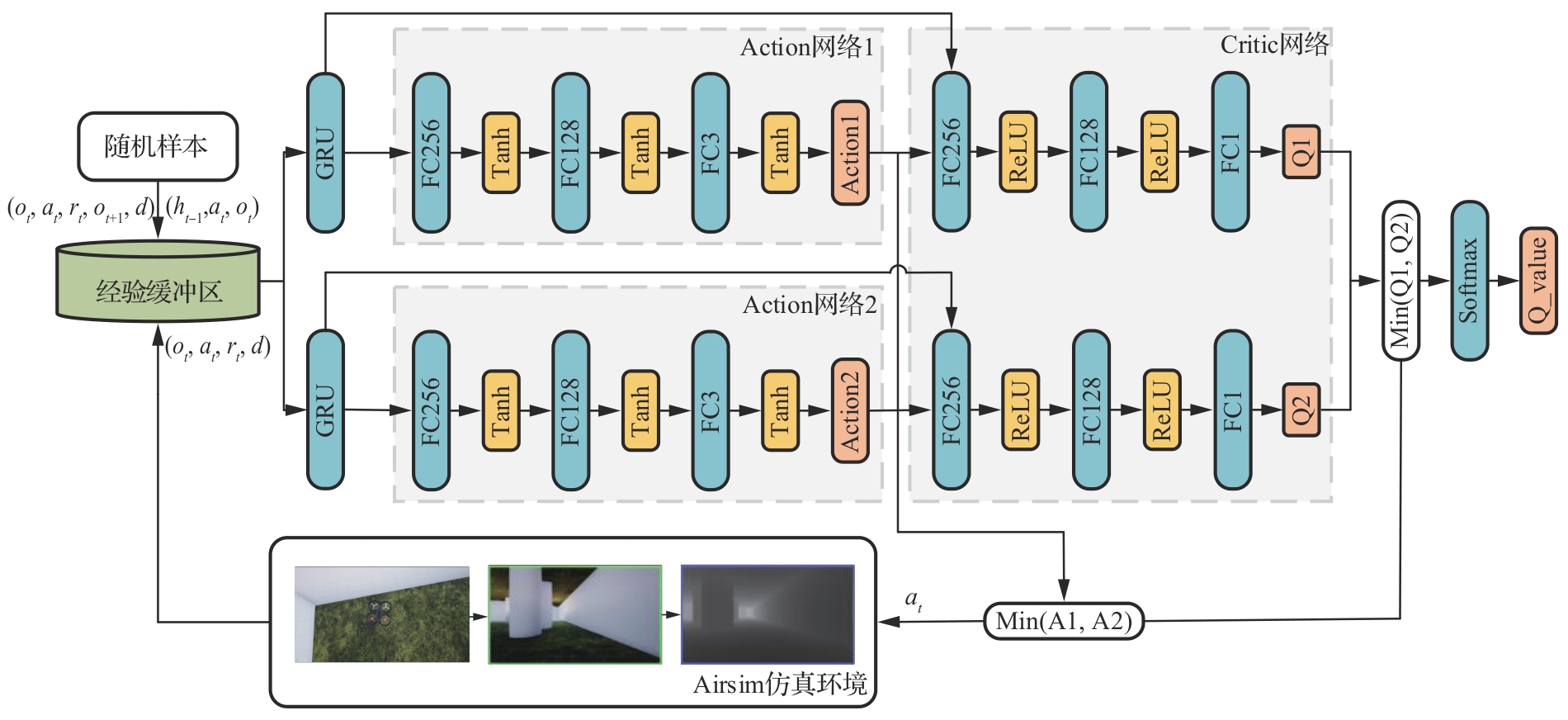

Fig.9
Training environment diagram
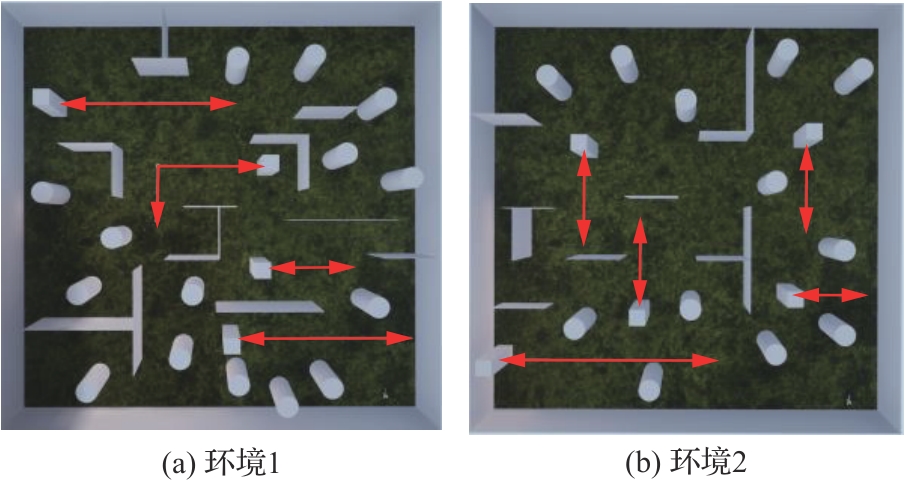
Table 1
Model hyperparameter setting
| 参数 | 数值 |
|---|---|
| 折扣率 | 0.99 |
| 学习率 | |
| 经验池尺寸 | |
经验池批量大小 探索噪声参数 目标网络更新率 | 256 |
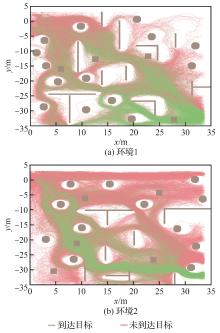
Fig.10
Training trajectory diagram
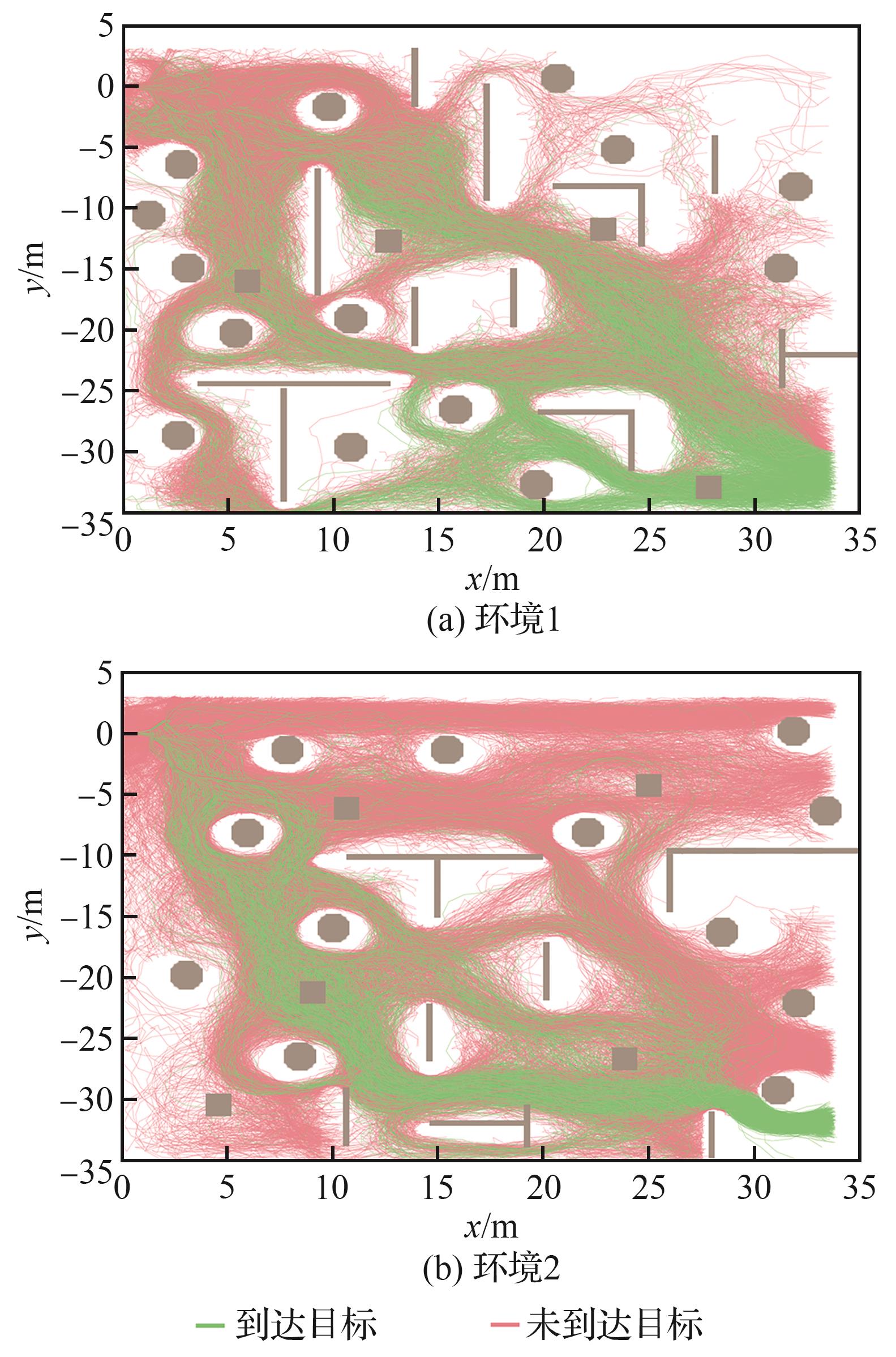
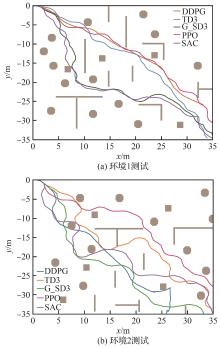
Fig.11
Navigation trajectory diagram in trainingenvironment
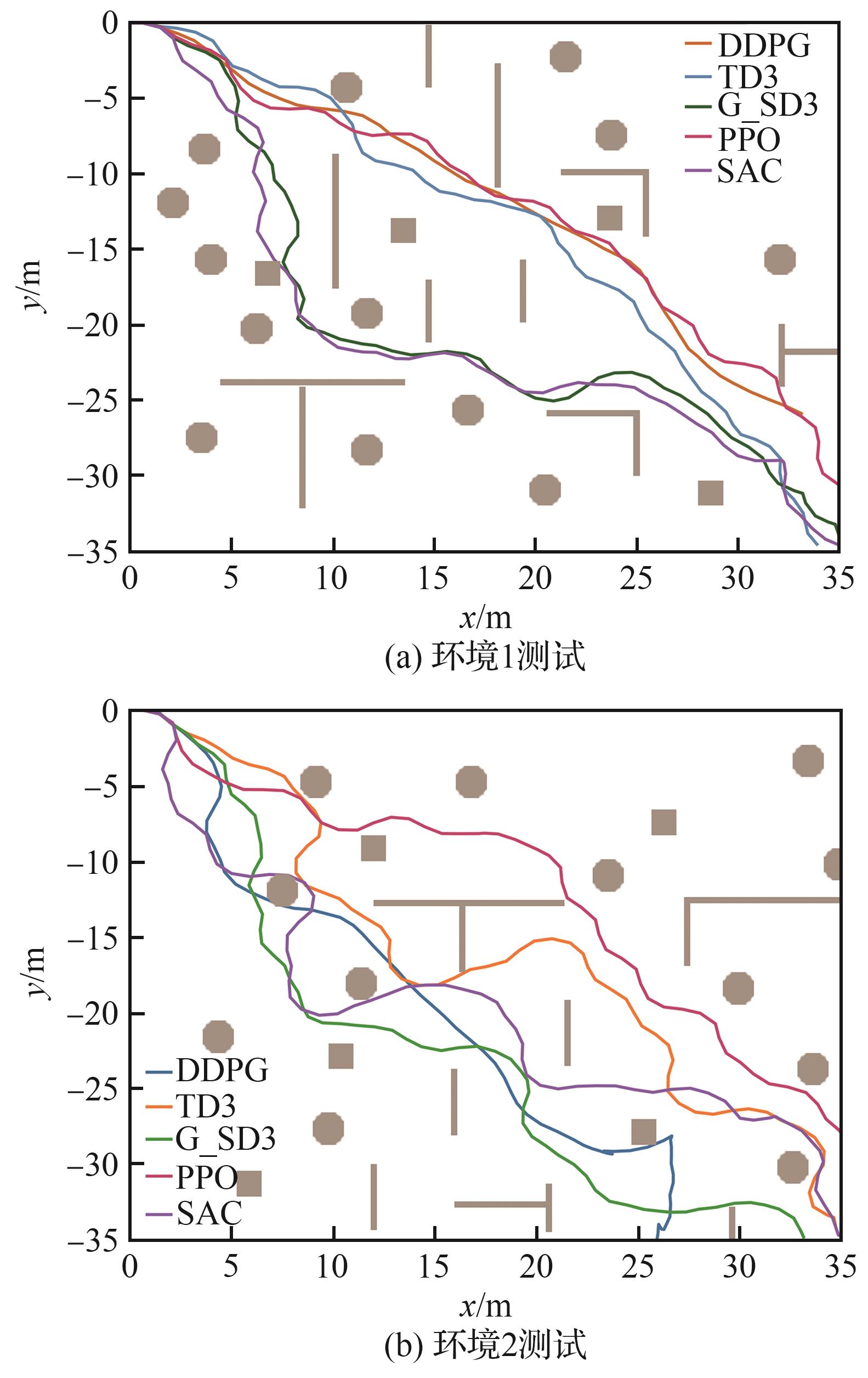
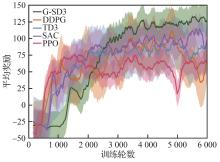
Fig.12
Training reward
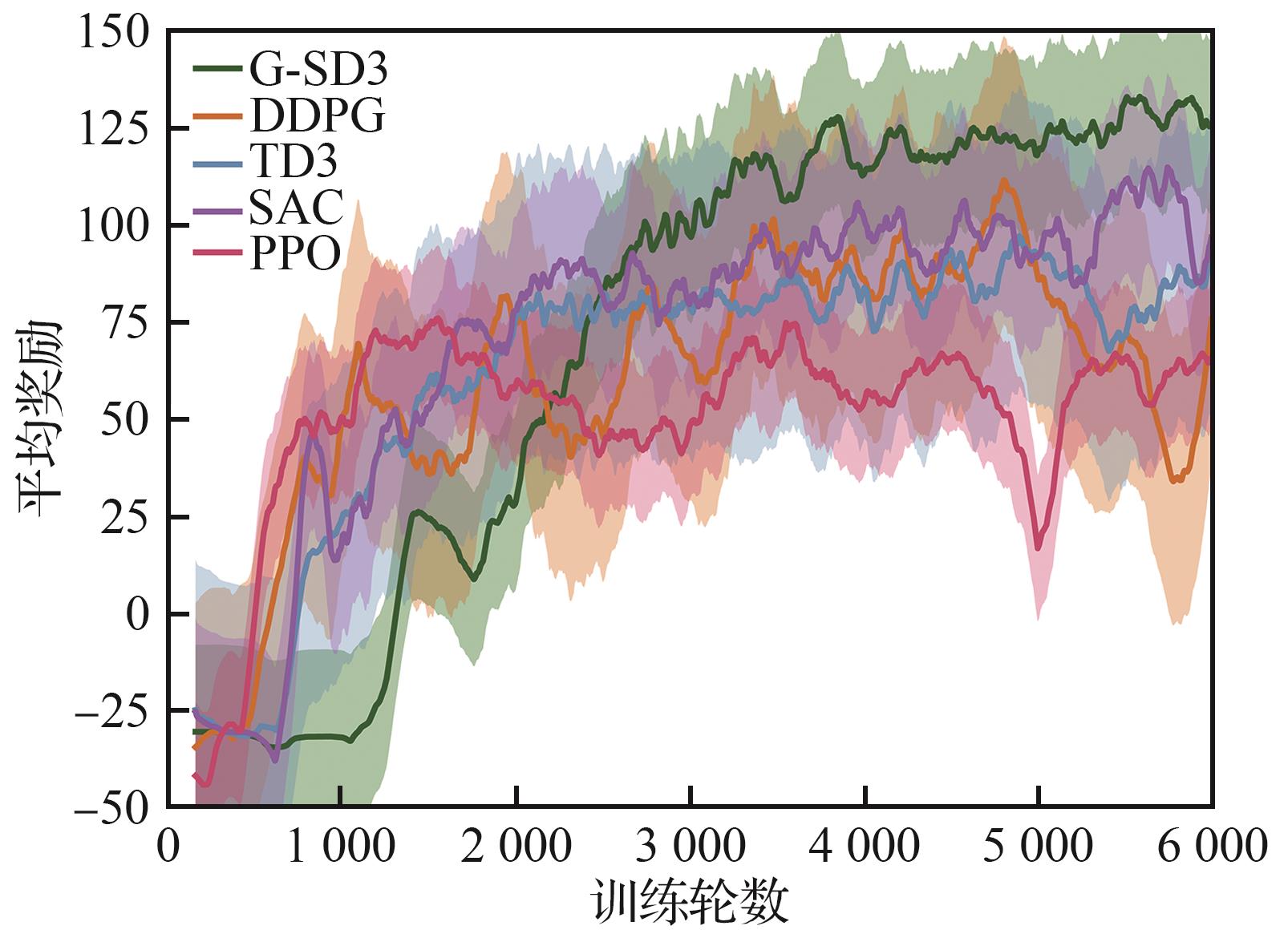

Fig.13
Ablation lab training incentives
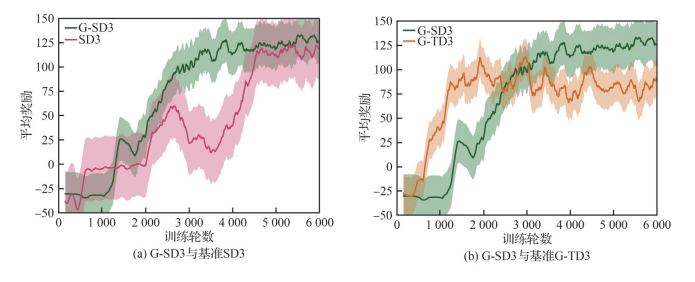
Table 2
Test environment navigation success rate comparison
| 环境 | 成功率/% | 碰撞率/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DDPG | TD3 | SAC | PPO | G-SD3 | DDPG | TD3 | SAC | PPO | G-SD3 | |
| 平均值 | 45 | 62 | 67 | 39 | 88 | 55 | 38 | 34 | 62 | 12 |
| 环境a | 48 | 67 | 68 | 41 | 86 | 52 | 33 | 32 | 59 | 14 |
| 环境b | 53 | 74 | 77 | 50 | 95 | 47 | 26 | 23 | 50 | 5 |
| 环境c | 31 | 56 | 61 | 32 | 89 | 69 | 44 | 39 | 68 | 11 |
| 环境d | 45 | 51 | 60 | 31 | 82 | 55 | 49 | 40 | 69 | 18 |
Table 3
Comprehensive comparison of navigation algorithms
| 算法 | 平均步数 | 最大步数 | 最小步数 | 平均行驶时间/s | 最小行驶时间/s | 成功率/% |
|---|---|---|---|---|---|---|
| DDPG | 67.15 | 129 | 17 | 73.71 | 18.67 | 45.0 |
| TD3 | 58.60 | 65 | 7 | 62.59 | 6.47 | 62.0 |
| PPO | 71.70 | 201 | 14 | 80.20 | 16.43 | 38.5 |
| SAC | 54.70 | 61 | 15 | 59.62 | 14.72 | 66.5 |
| G-SD3 | 53.40 | 77 | 12 | 57.68 | 12.42 | 88.0 |

Fig.14
Test environment diagram


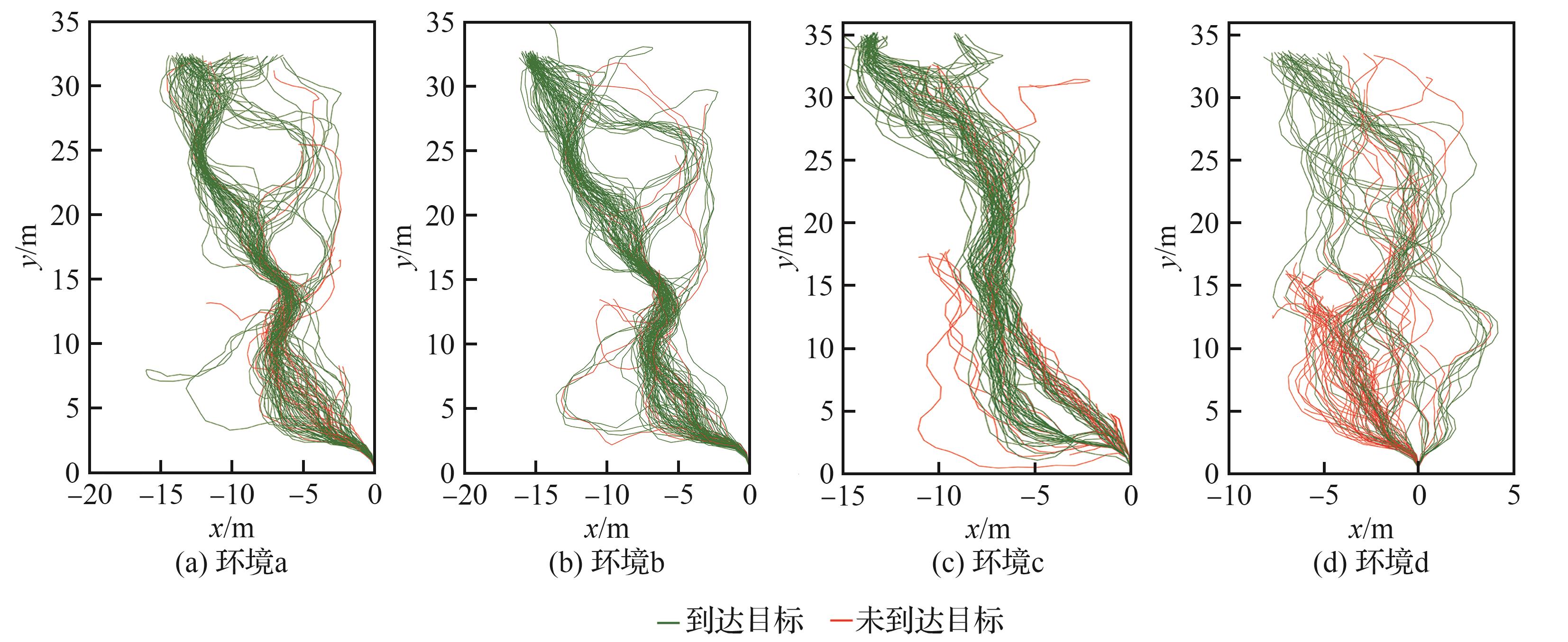
Fig.15
Test trajectory comparison diagram of G-SD3 algorithms
| 1 | HUANG Z Y, WU J D, LV C. Efficient deep reinforcement learning with imitative expert priors for autonomous driving[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(10): 7391-7403. |
| 2 | ADIL M, SONG H B, AHMAD JAN M, et al. UAV-assisted IoT applications, QoS requirements and challenges with future research directions[J]. ACM Computing Surveys, 2024, 56(10): 1-35. |
| 3 | XUE Z H, GONSALVES T. Vision based drone obstacle avoidance by deep reinforcement learning[J]. AI, 2021, 2(3): 366-380. |
| 4 | LI J, QIN H, WANG J Z, et al. OpenStreetMap-based autonomous navigation for the four wheel-legged robot via 3D-lidar and CCD camera[J]. IEEE Transactions on Industrial Electronics, 2022, 69(3): 2708-2717. |
| 5 | CAI D P, LI R Q, HU Z H, et al. A comprehensive overview of core modules in visual SLAM framework[J]. Neurocomputing, 2024, 590: 127760. |
| 6 | YANG C G, CHEN C Z, HE W, et al. Robot learning system based on adaptive neural control and dynamic movement primitives[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(3): 777-787. |
| 7 | ALMAZROUEI K, KAMEL I, RABIE T. Dynamic obstacle avoidance and path planning through reinforcement learning[J]. Applied Sciences, 2023, 13(14): 8174. |
| 8 | SATHYAMOORTHY A J, PATEL U, GUAN T R, et al. Frozone: Freezing-free, pedestrian-friendly navigation in human crowds[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4352-4359. |
| 9 | 周彬, 郭艳, 李宁, 等. 基于导向强化Q学习的无人机路径规划[J]. 航空学报, 2021, 42(9): 325109. |
| ZHOU B, GUO Y, LI N, et al. Path planning of UAV using guided enhancement Q-learning algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(9): 325109 (in Chinese). | |
| 10 | CHAI R Q, NIU H L, CARRASCO J, et al. Design and experimental validation of deep reinforcement learning-based fast trajectory planning and control for mobile robot in unknown environment[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5778-5792. |
| 11 | XIE Z T, DAMES P. DRL-VO: Learning to navigate through crowded dynamic scenes using velocity obstacles[J]. IEEE Transactions on Robotics, 2023, 39(4): 2700-2719. |
| 12 | CAO X, REN L, SUN C Y. Research on obstacle detection and avoidance of autonomous underwater vehicle based on forward-looking sonar[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(11): 9198-9208. |
| 13 | WANG W Y, MA F, LIU J L. Course tracking control for smart ships based on A deep deterministic policy gradient-based algorithm[C]∥2019 5th International Conference on Transportation Information and Safety (ICTIS). Piscataway: IEEE Press, 2019. |
| 14 | LILLICRAP T P, HUNT J, PRITZEL A, et al. Continuous control with deep reinforcement learning[DB/OL]. arXiv preprint: 1509.02971,2019. |
| 15 | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]∥Proceedings of the 31st International Conference on International Conference on Machine Learning. New York: ACM, 2014. |
| 16 | FUJIMOTO S, HOOF H V, MEGER D. Addressing function approximation error in actor-critic methods[C]∥Proceedings of the 35th International Conference on Machine Learning. New York: ACM, 2018 |
| 17 | 寇凯, 杨刚, 张文启, 等. 基于SAC的无人机自主导航方法研究[J]. 西北工业大学学报, 2024, 42(2): 310-318. |
| KOU K, YANG G, ZHANG W Q, et al. Exploring UAV autonomous navigation algorithm based on soft actor-critic[J]. Journal of Northwestern Polytechnical University, 2024, 42(2): 310-318 (in Chinese). | |
| 18 | SINGLA A, PADAKANDLA S, BHATNAGAR S. Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(1): 107-118. |
| 19 | CUI Z Y, WANG Y. UAV path planning based on multi-layer reinforcement learning technique[J]. IEEE Access, 2021, 9: 59486-59497. |
| 20 | XUE Y T, CHEN W S. A UAV navigation approach based on deep reinforcement learning in large cluttered 3D environments[J]. IEEE Transactions on Vehicular Technology, 2023, 72(3): 3001-3014. |
| 21 | EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning[C]∥2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2018. |
| 22 | KAELBLING L P, LITTMAN M L, CASSANDRA A R. Planning and acting in partially observable stochastic domains[J]. Artificial Intelligence, 1998, 101(1): 99-134. |
| 23 | XIAO C X, LU P, HE Q Z. Flying through a narrow gap using end-to-end deep reinforcement learning augmented with curriculum learning and Sim2Real[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(5): 2701-2708. |
| 24 | JIA J Y, XING X W, CHANG D E. GRU-attention based TD3 network for mobile robot navigation[C]∥2022 22nd International Conference on Control, Automation and Systems (ICCAS). Piscataway: IEEE Press, 2022. |
| 25 | DEY R, SALEM F M. Gate-variants of gated recurrent unit (GRU) neural networks[C]∥2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS). Piscataway: IEEE Press, 2017. |
| 26 | KALIDAS A P, JOSHUA C J, MD A Q, et al. Deep reinforcement learning for vision-based navigation of UAVs in avoiding stationary and mobile obstacles[J]. Drones, 2023, 7(4): 245. |
| 27 | 杨卫平. 新一代飞行器导航制导与控制技术发展趋势[J]. 航空学报, 2024, 45(5): 529720. |
| YANG W P. Development trend of navigation guidance and control technology for new generation aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(5): 529720 (in Chinese). | |
| 28 | ZHANG F J, LI J, LI Z. A TD3-based multi-agent deep reinforcement learning method in mixed cooperation-competition environment[J]. Neurocomputing, 2020, 411: 206-215. |
| 29 | PAN L, CAI Q P, HUANG L B. Softmax deep double deterministic policy gradients[DB/OL]. arXiv preprint: 2010. 09177, 2020. |
| 30 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arXiv preprint: 1707. 06347, 2017. |
| 31 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[DB/OL]. arXiv preprint: 1801. 01290, 2018. |
| [1] | Kaifang WAN, Zhilin WU, Yunhui WU, Haozhi QIANG, Yibo WU, Bo LI. Cooperative location of multiple UAVs with deep reinforcement learning in GPS-denied environment [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331024-331024. |
| [2] | Jinwu XIANG, Kai MA, Zi KAN, Daochun LI, Kexin ZHENG, Hanxuan CHEN. Review of key technologies for hydrogen powered unmanned aerial vehicles [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(5): 531603-531603. |
| [3] | Min YANG, Guanjun LIU, Ziyuan ZHOU. Control of lunar landers based on secure reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(3): 630553-630553. |
| [4] | Wei ZHANG, Ruojun HE. Autonomous trajectory design for IoT data collection by UAV [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329054-329054-1. |
| [5] | Honglin ZHANG, Jianjun LUO, Weihua MA. Spacecraft game decision making for threat avoidance of space targets based on machine learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329136-329136. |
| [6] | Yunpeng CAI, Dapeng ZHOU, Jiangchuan DING. Intelligent collaborative control of UAV swarms with collision avoidance safety constraints [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(5): 529683-529683. |
| [7] | Shengzhe SHAN, Weiwei ZHANG. Air combat intelligent decision-making method based on self-play and deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(4): 328723-328723. |
| [8] | Bing GAO, Zhejie ZHANG, Qijie ZOU, Zhiguo LIU, Xiling ZHAO. Multi-agent communication cooperation based on deep reinforcement learning and information theory [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(18): 329862-329862. |
| [9] | Wentao LI, Feng FANG, Zhenya WANG, Yichao ZHU, Dongliang PENG. Intelligent maneuvering decision-making in two-UCAV cooperative air combat based on improved MADDPG with hybrid hyper network [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(17): 529460-529460. |
| [10] | Zuolong LI, Jihong ZHU, Minchi KUANG, Jie ZHANG, Jie REN. Hierarchical decision algorithm for air combat with hybrid action based on deep reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(17): 530053-530053. |
| [11] | Tiancai WU, Honglun WANG, Bin REN, Yiheng LIU, Xingyu WU, Guocheng YAN. Learning-based integrated fault-tolerant guidance and control for hypersonic vehicles considering avoidance and penetration [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(15): 329607-329607. |
| [12] | Wenkang HAO, Suyan BAO, Qifeng CHEN. Distributed control of UAVs formation based on port⁃Hamiltonian system [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S2): 729868-729868. |
| [13] | Xuejian WANG, Yongming WEN, Xiaorong SHI, Ningning ZHANG, Jiexi LIU. Design of hybrid intelligent decision framework for multi⁃agent and multi⁃coupling tasks [J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S2): 729770-729770. |
| [14] | Yajie MA, Juan WANG, Bin JIANG, Jianye GONG. A fault⁃tolerant control scheme for UAVs-UGVs formation systems [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(8): 327216-327216. |
| [15] | Xiaowei FU, Zhe XU, Jindong ZHU, Nan WANG. Maneuvering decision-making of multi-UAV attack-defence confrontation based on PER-MATD3 [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2023, 44(7): 327083-327083. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341