高树一1, 林德福1, 郑多1( ), 徐骋2
), 徐骋2
收稿日期:2024-09-30
修回日期:2024-10-29
接受日期:2024-12-04
出版日期:2024-12-10
发布日期:2024-12-10
通讯作者:
郑多
E-mail:zhengduohello@126.com
基金资助:
Shuyi GAO1, Defu LIN1, Duo ZHENG1(), Cheng XU2
Received:2024-09-30
Revised:2024-10-29
Accepted:2024-12-04
Online:2024-12-10
Published:2024-12-10
Contact:
Duo ZHENG
E-mail:zhengduohello@126.com
Supported by:摘要:
随着防空反导拦截技术和装备的发展,进攻飞行器面临被防御武器拦截导致的战场生存率低、效能差等问题。针对拦截器拦截场景下的飞行器智能攻防博弈对抗问题,提出了一种考虑拦截器探测能力限制的飞行器智能机动突防制导策略。首先定义了拦截器视线角和探测范围,并利用拦截器与进攻飞行器之间的相对运动关系来描述攻防双方对抗态势的演变,进而基于深度强化学习原理设计了近端策略优化制导方法,构建了引导飞行器主动摆脱拦截器探测的马尔可夫决策链,并进一步优化飞行器奖励函数设计方法实现对目标的精确打击。在此基础上,通过引入信任动作探索技术来解决智能算法收敛慢的问题。仿真结果表明,智能机动突防制导策略赋予了飞行器自主学习优化属性,可以通过主动规避机动增加拦截器的探测难度,最终突破拦截器的探测能力极限实现突防逃逸。相比于传统PN-sin突防制导方法,提出的突防制导策略能够在攻防双方非对称机动能力场景下保持更高的突防成功率。
中图分类号:
高树一, 林德福, 郑多, 徐骋. 考虑拦截器探测能力限制的飞行器智能机动突防制导策略[J]. 航空学报, 2025, 46(10): 331304.
Shuyi GAO, Defu LIN, Duo ZHENG, Cheng XU. Intelligent maneuvering penetration guidance strategies for aerial vehicles considering interceptor detection capability limitations[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(10): 331304.
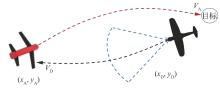
图 1
飞行器突防博弈场景
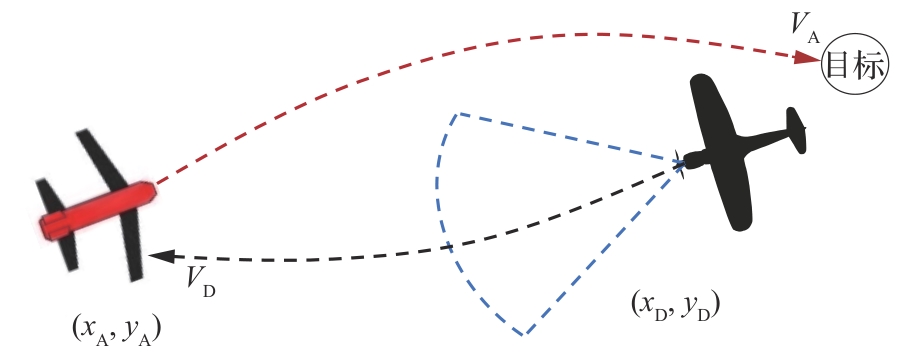
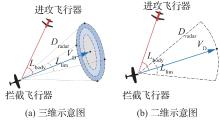
图 2
拦截器雷达探测范围
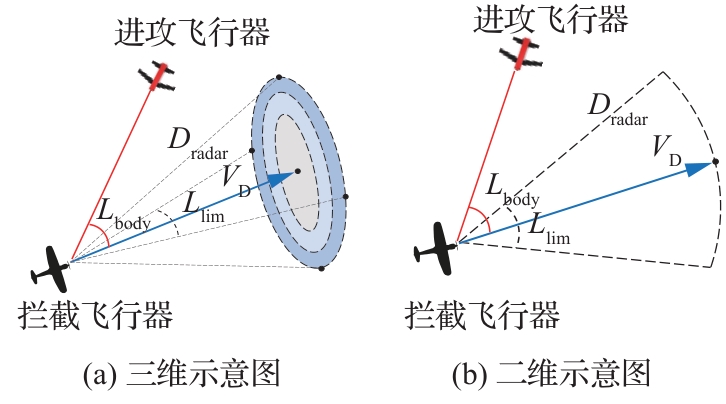
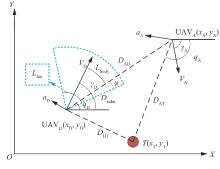
图 3
进攻方-目标-拦截器相对运动关系
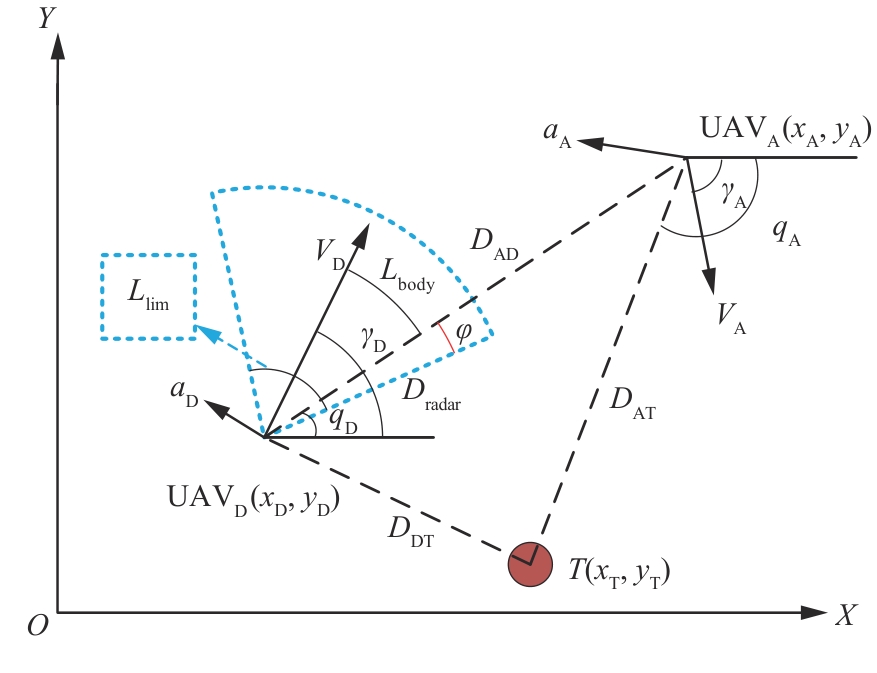
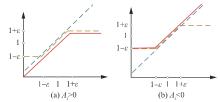
图 4
clip算法模型
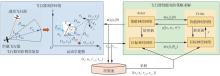
图 5
飞行器智能突防机动算法架构
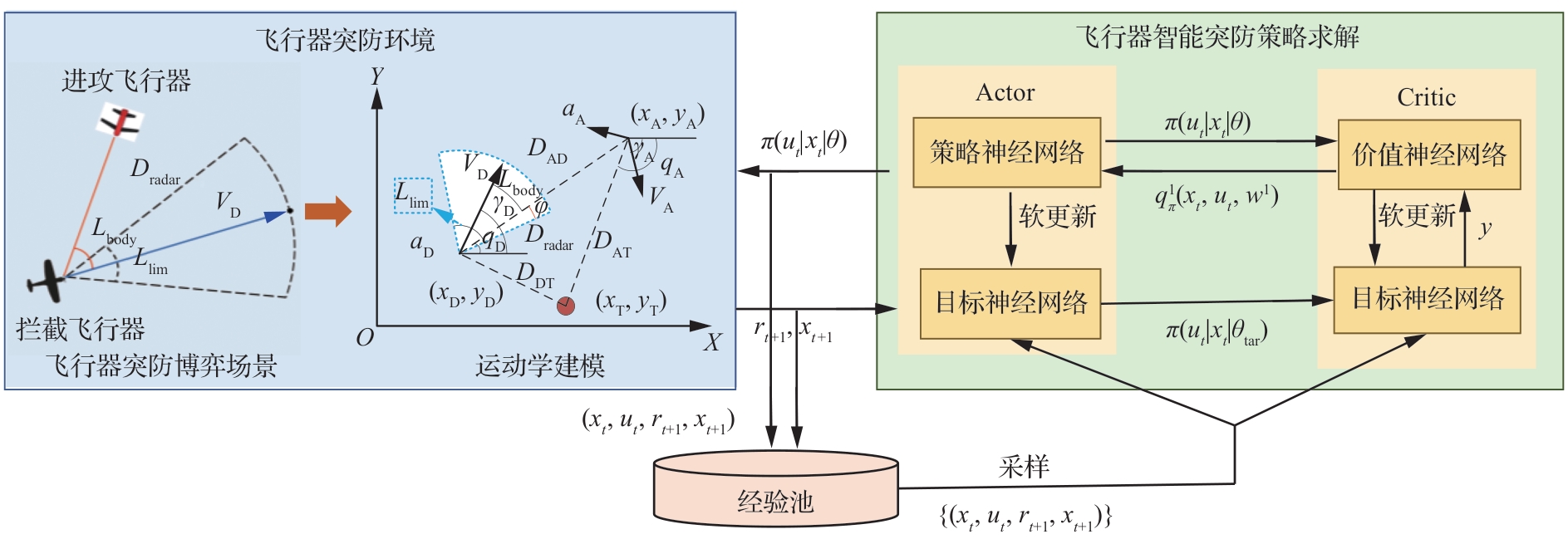

图 6
策略神经网络结构示意图
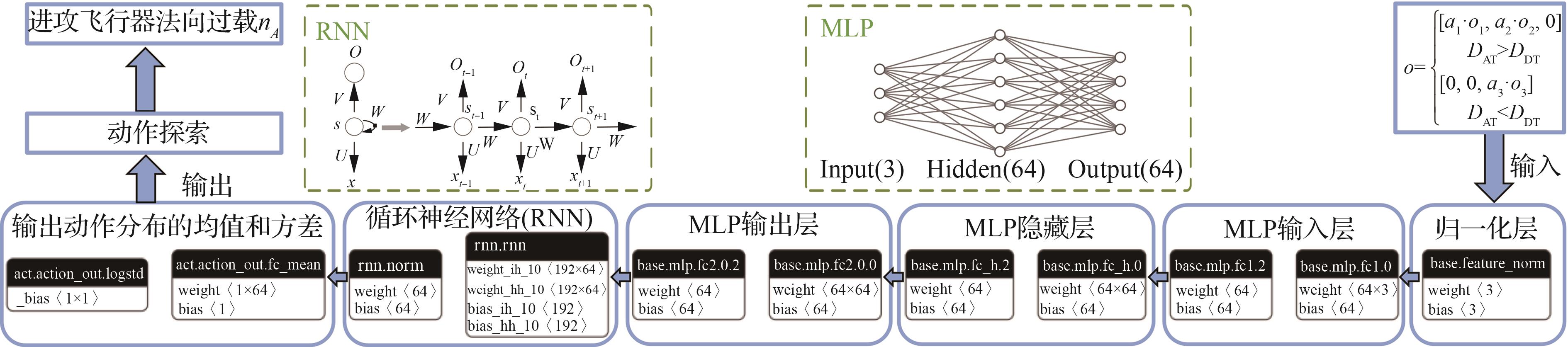
表 1
算法训练参数设置
| 参数 | 数值 |
|---|---|
| PPO裁剪系数 | 0.2 |
| 熵奖励系数 | 0.02 |
| GAE参数 | 0.98 |
| 衰减因子 | 0.998 |
| 神经网络优化器 | Adam |
| 学习率 | 2×10-4 |
表 2
攻防双方机动能力对比
| 飞行器类型 | 速度/(m·s-1) | 过载能力/g |
|---|---|---|
| 拦截器 | 70 | [-3,3] |
| 进攻飞行器 | 65 | [-1.5,1.5] |
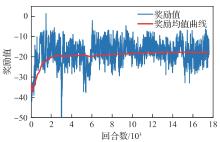
图 7
突防场景奖励函数曲线
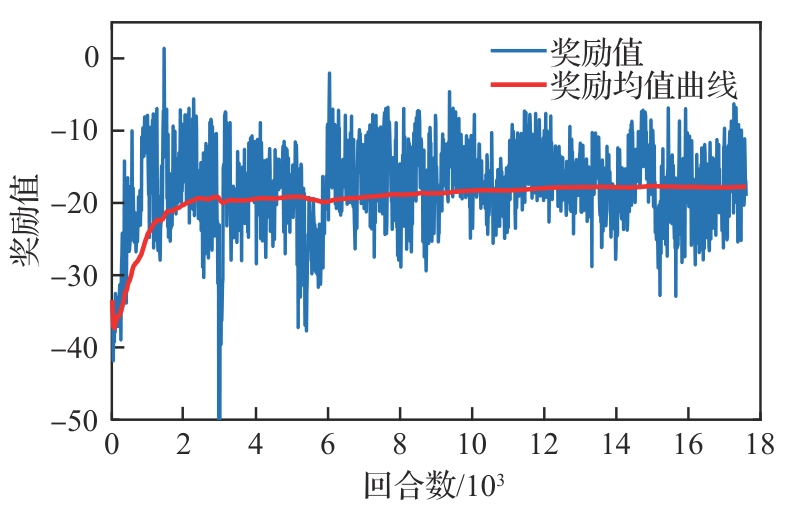
图 8
标准PPO算法与本文所提算法的奖励值对比
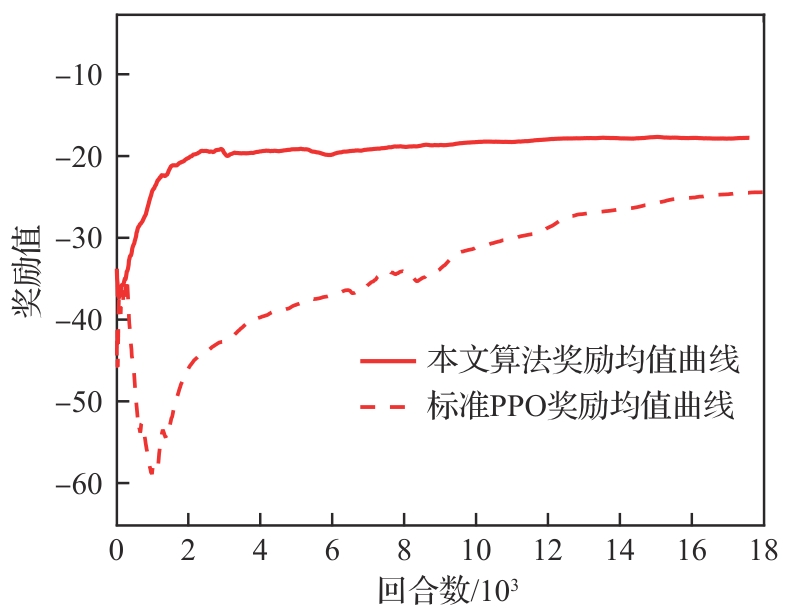
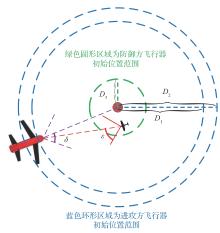
图 9
仿真场景初始化设置
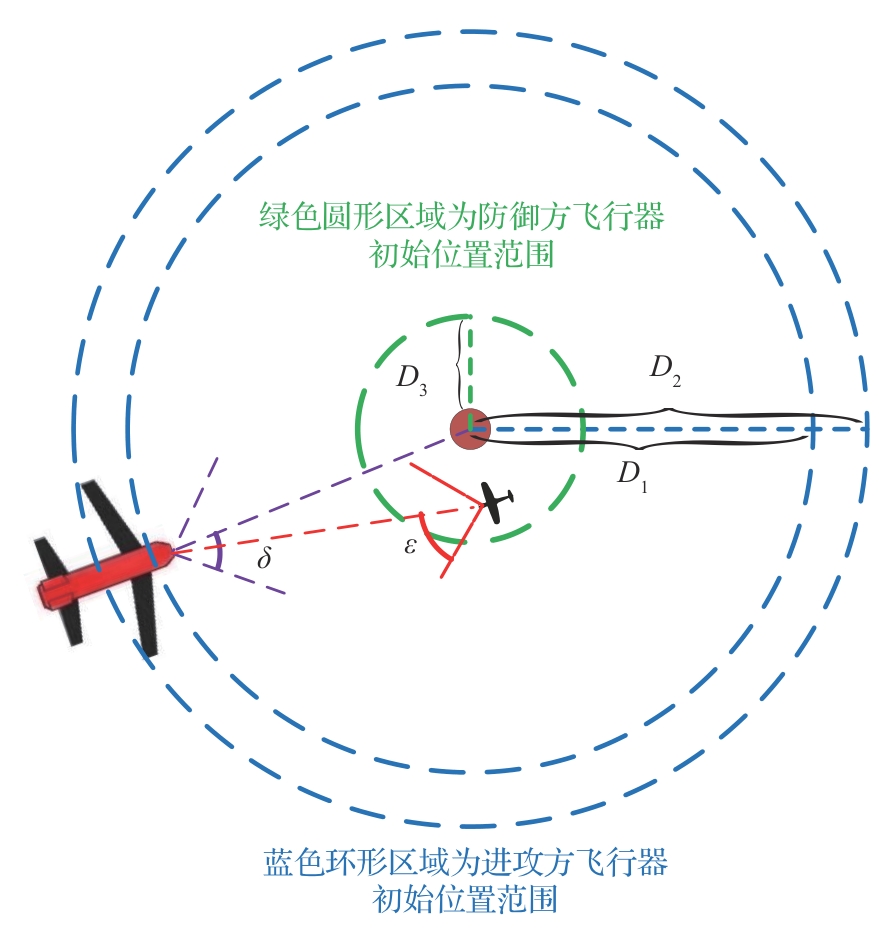
表 3
攻防双方机动能力对比(能力相同)
| 飞行器类型 | 速度/(m·s-1) | 过载能力/g |
|---|---|---|
| 拦截器 | 70 | [-1.5,1.5] |
| 进攻飞行器 | 65 | [-1.5,1.5] |
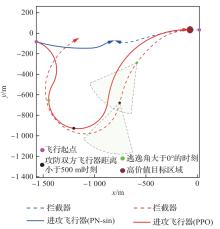
图 10
攻防双方位置曲线(能力相同)
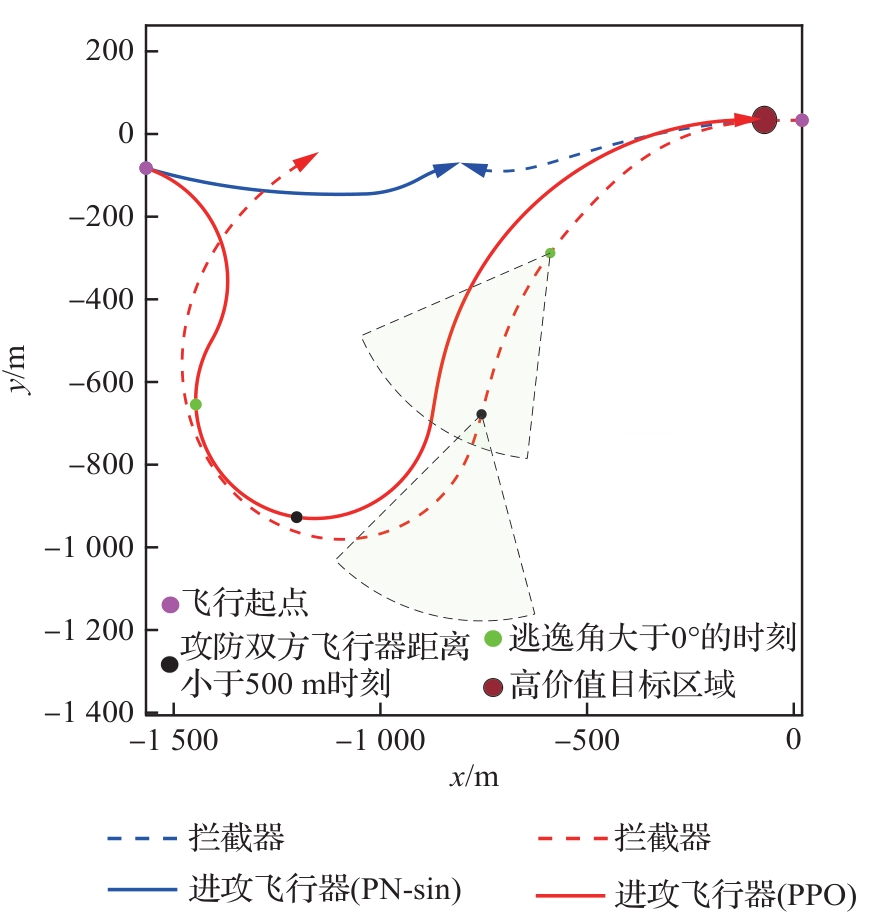
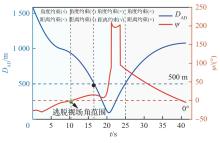
图 11
攻防双方距离和逃逸角对比曲线(PPO,能力相同)
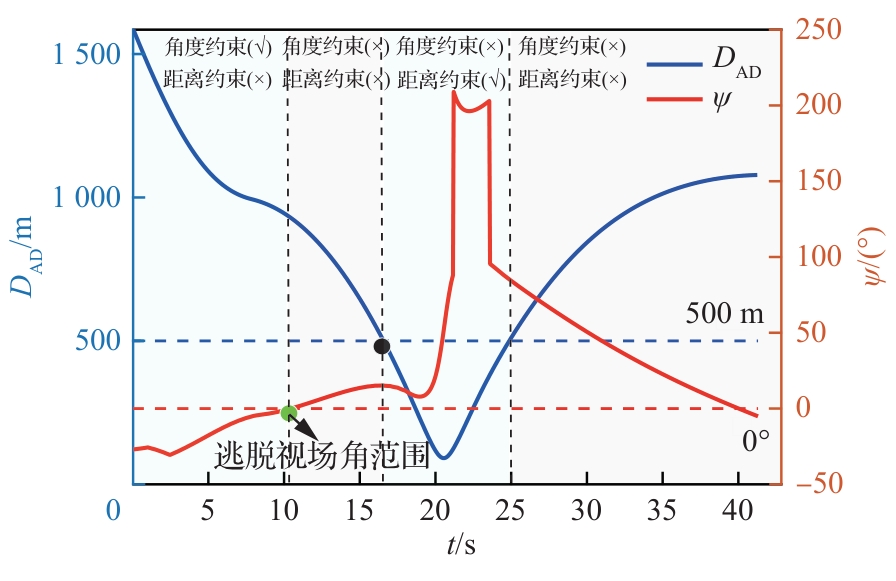
图 12
攻防双方距离和逃逸角对比曲线(PN-sin,能力相同)
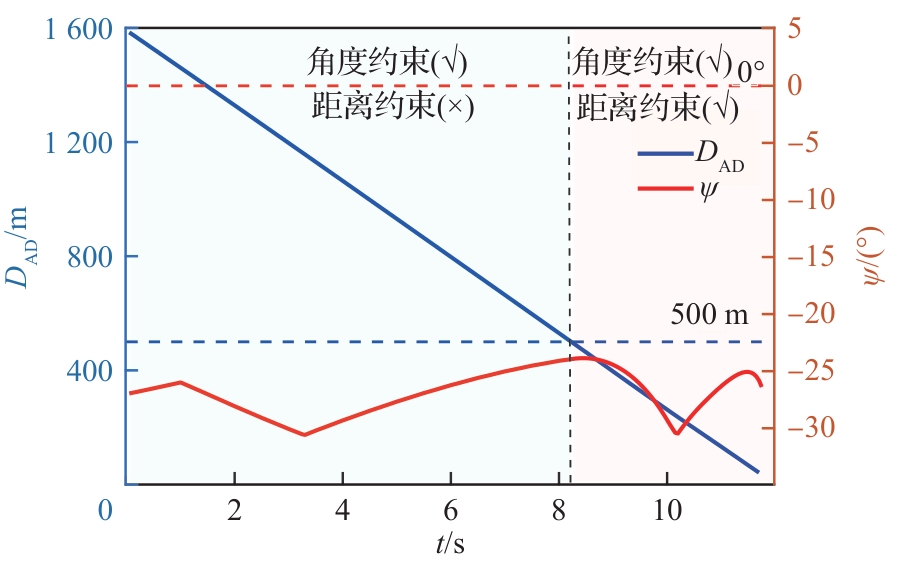
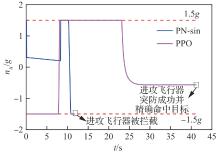
图 13
进攻飞行器法向过载(能力相同)
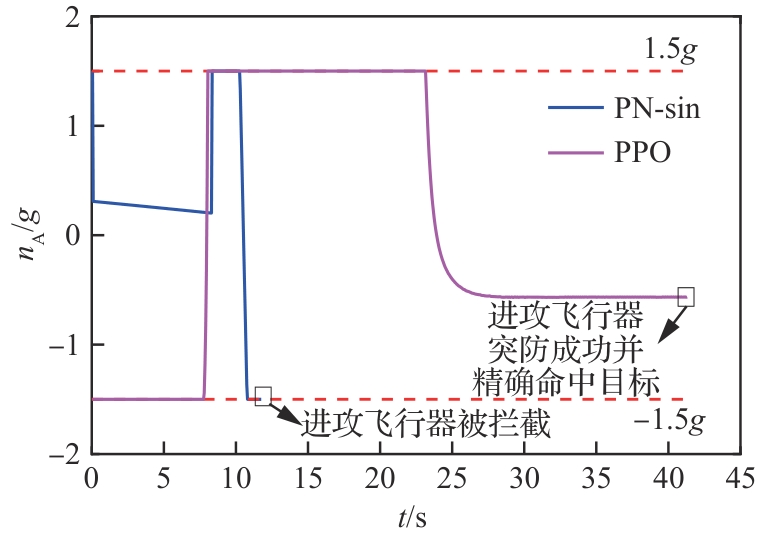
图 14
拦截器法向过载(能力相同)
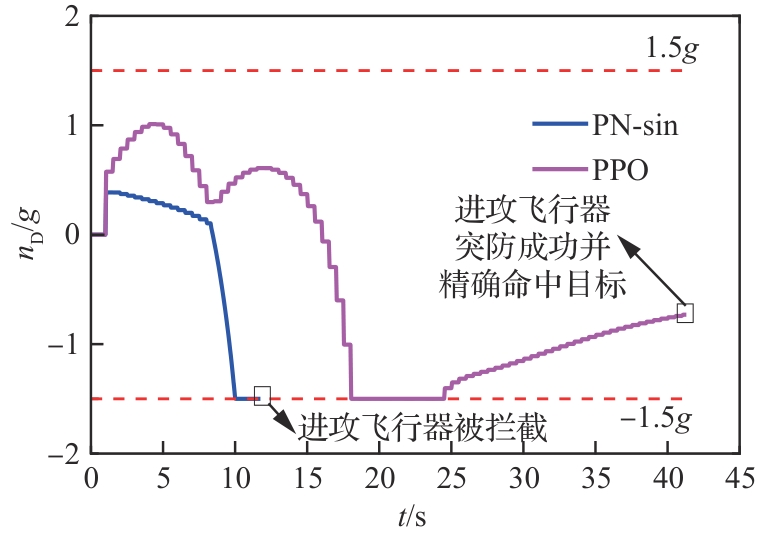
图 15
进攻飞行器航向角(能力相同)
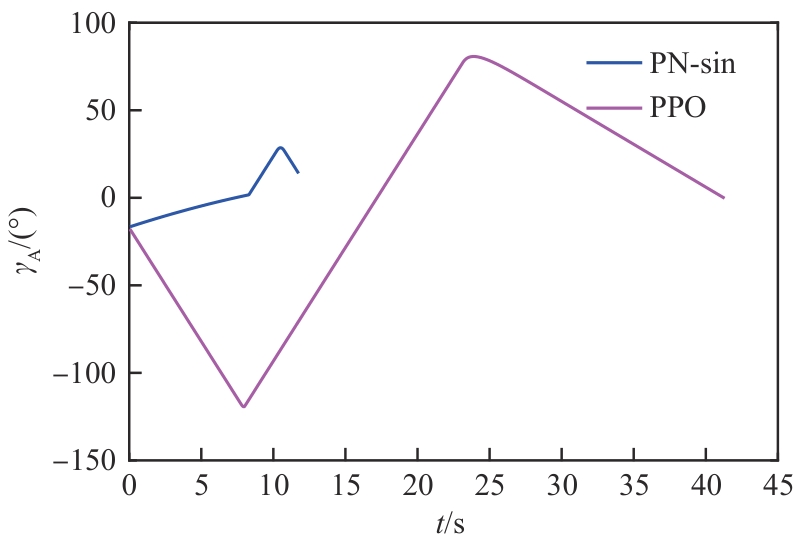
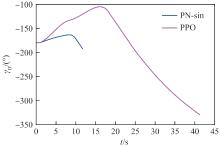
图 16
拦截器航向角(能力相同)
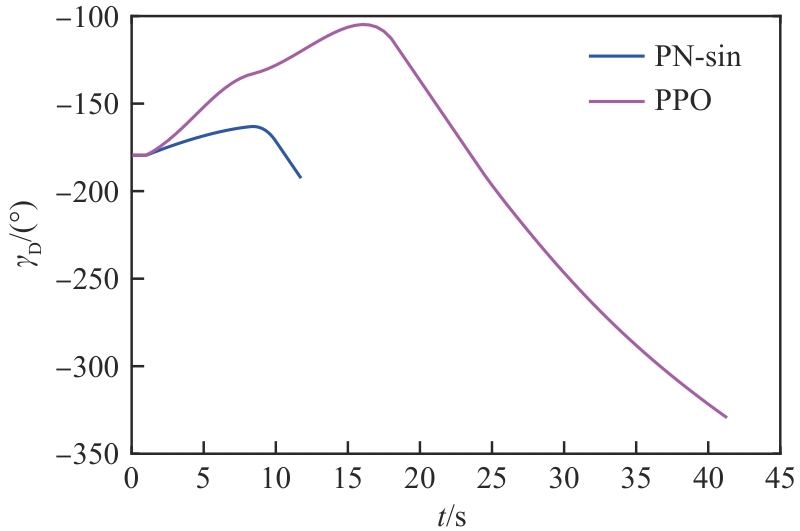
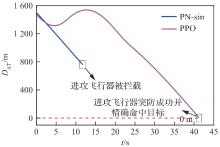
图 17
进攻飞行器和目标的距离(能力相同)
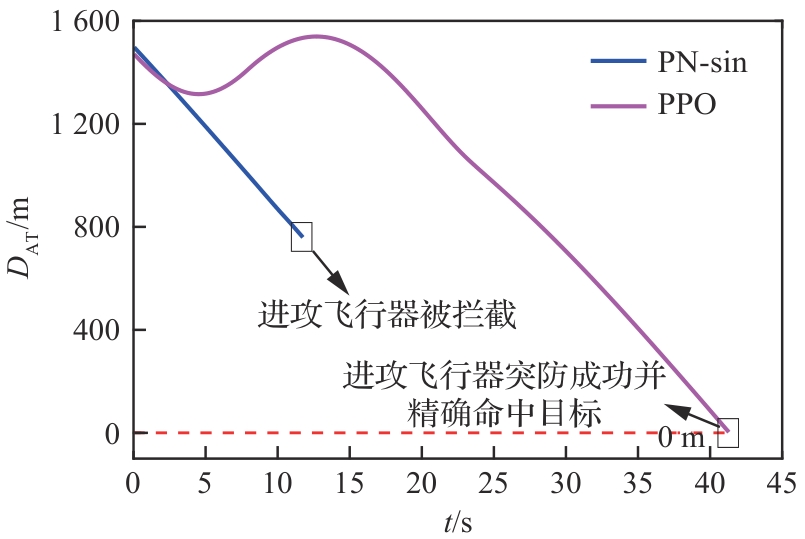
图 18
攻防双方飞行器距离(能力相同)
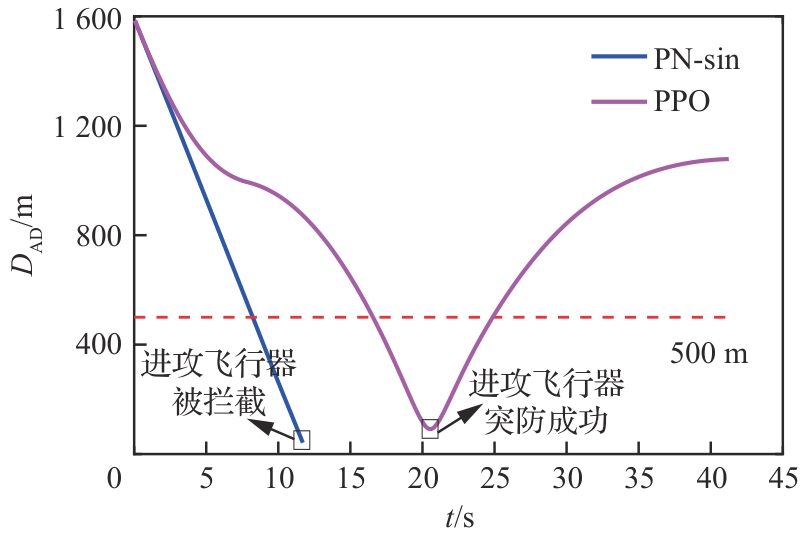
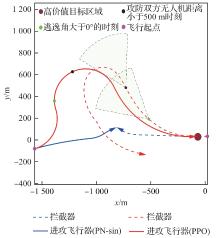
图 19
攻防双方位置曲线(进攻方<拦截器)
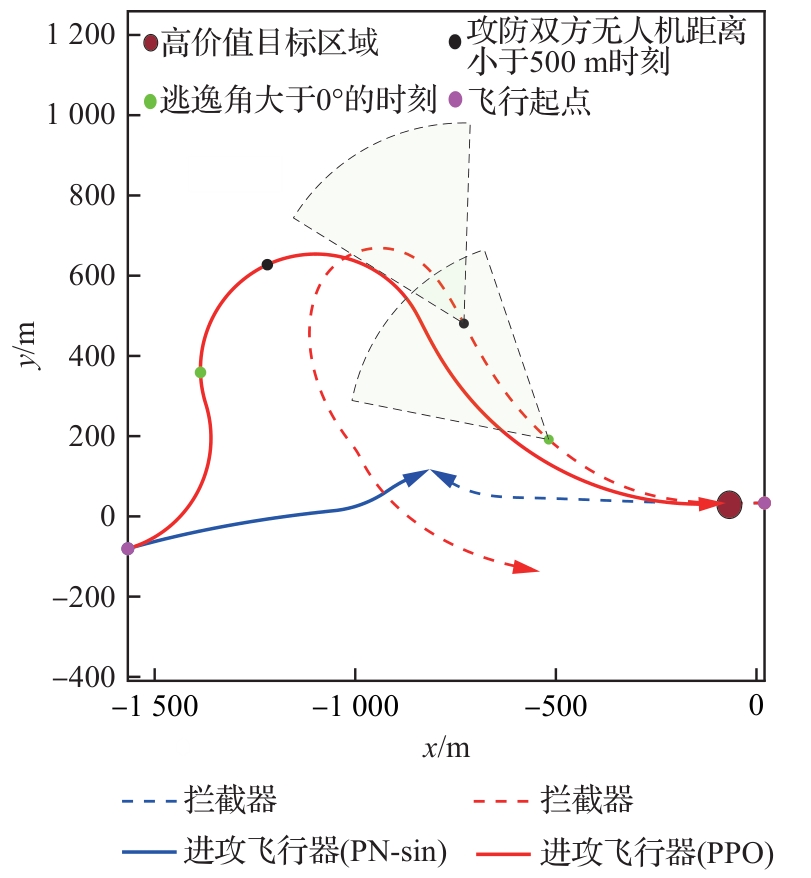
图 20
攻防双方距离和逃逸角对比曲线(进攻方<拦截器,PPO)
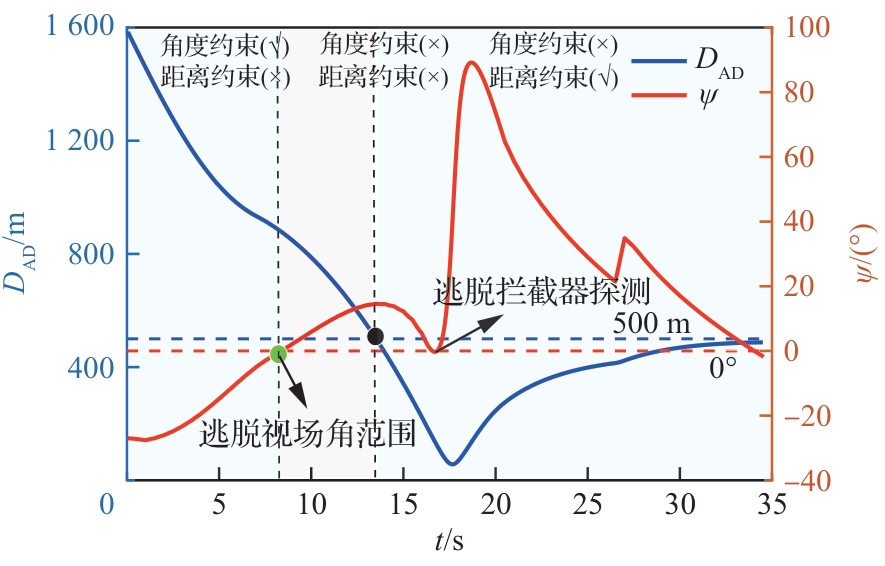
图 21
攻防双方距离和逃逸角对比曲线(进攻方<拦截器,PN-sin)
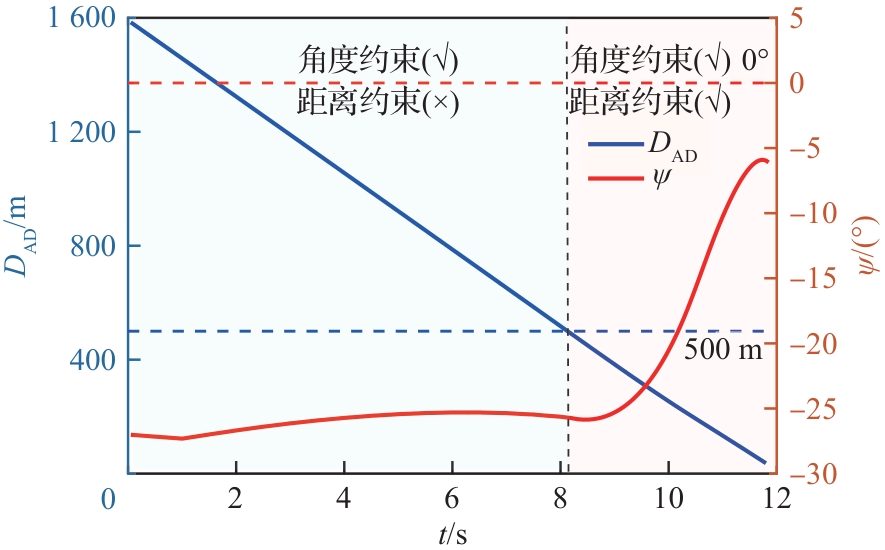
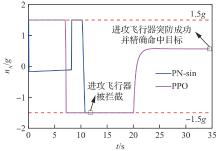
图 22
进攻飞行器法向过载(进攻方<拦截器)
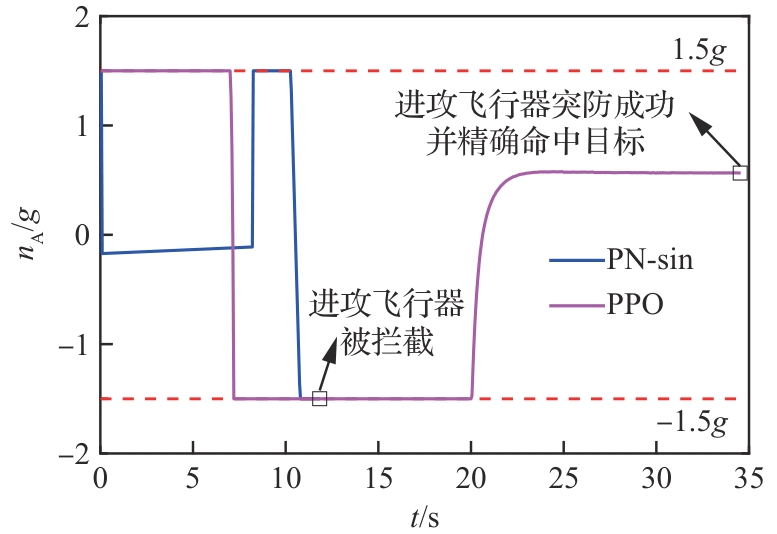
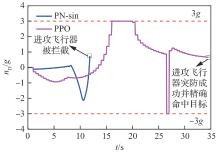
图 23
拦截器法向过载(进攻方<拦截器)
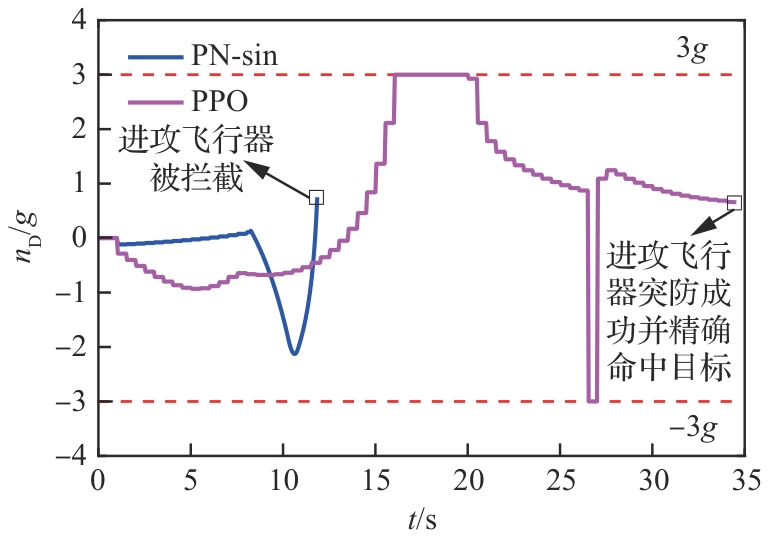
图 24
进攻飞行器航向角(进攻方<拦截器)
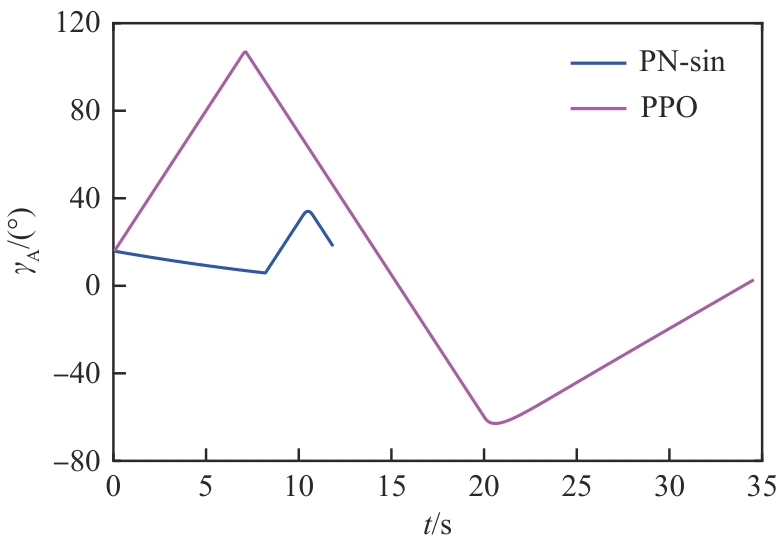
图 25
拦截器航向角(进攻方<拦截器)
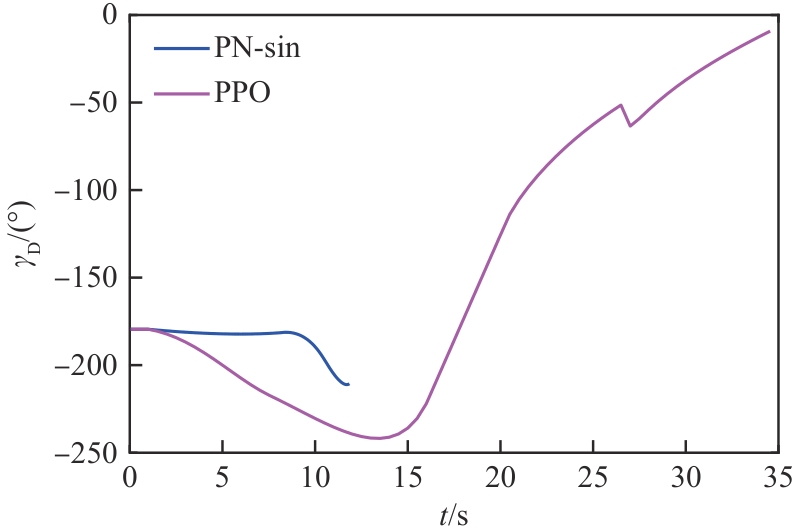
图 26
进攻飞行器和目标的距离(进攻方<拦截器)
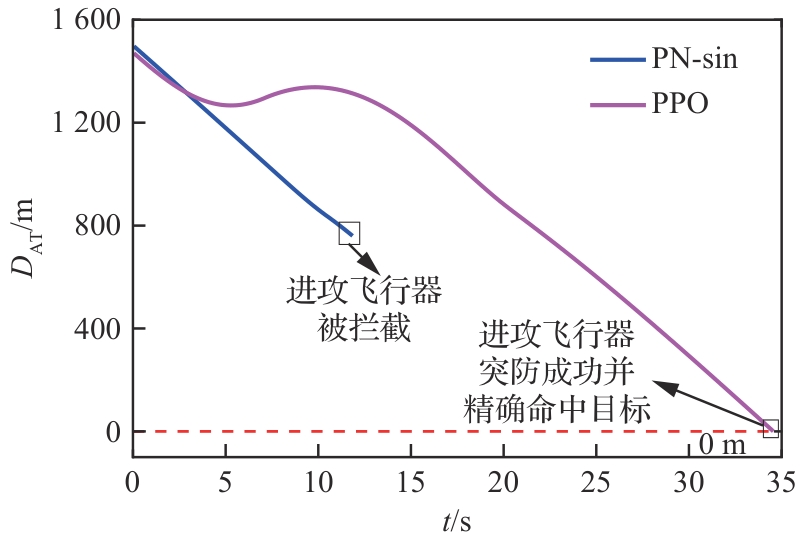
图 27
攻防双方飞行器距离(进攻方<拦截器)
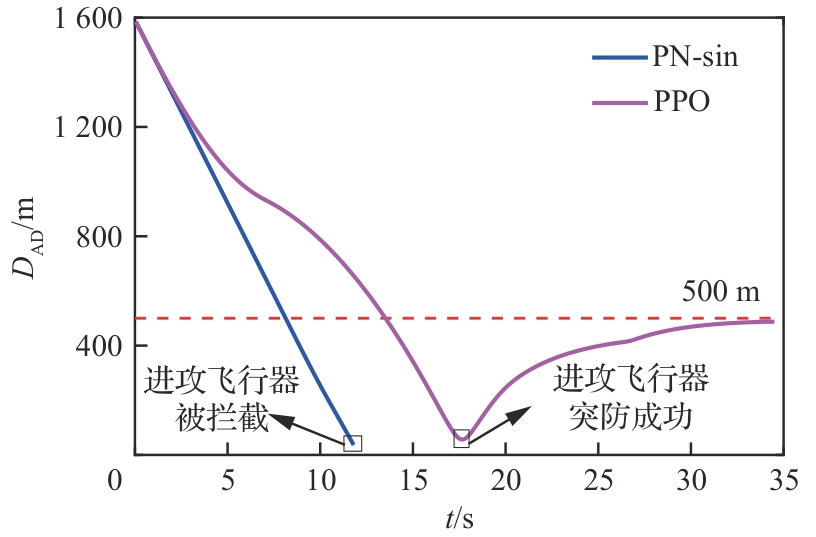
表 4
攻防双方机动能力对比(进攻方>拦截器)
| 飞行器类型 | 速度/(m·s-1) | 过载能力/g |
|---|---|---|
| 拦截器 | 70 | [-1,1] |
| 进攻飞行器 | 65 | [-1.5,1.5] |
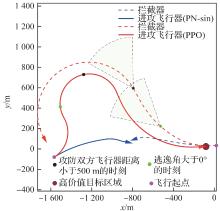
图 28
攻防双方位置曲线(进攻方>拦截器)
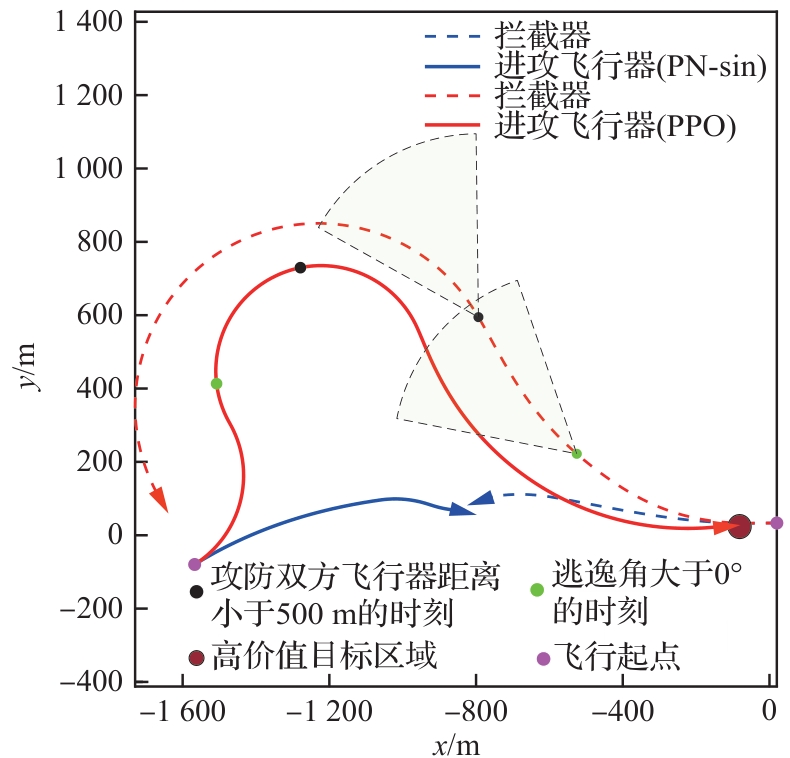
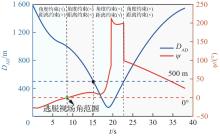
图 29
攻防双方距离和逃逸角对比曲线(进攻方>拦截器,PPO)
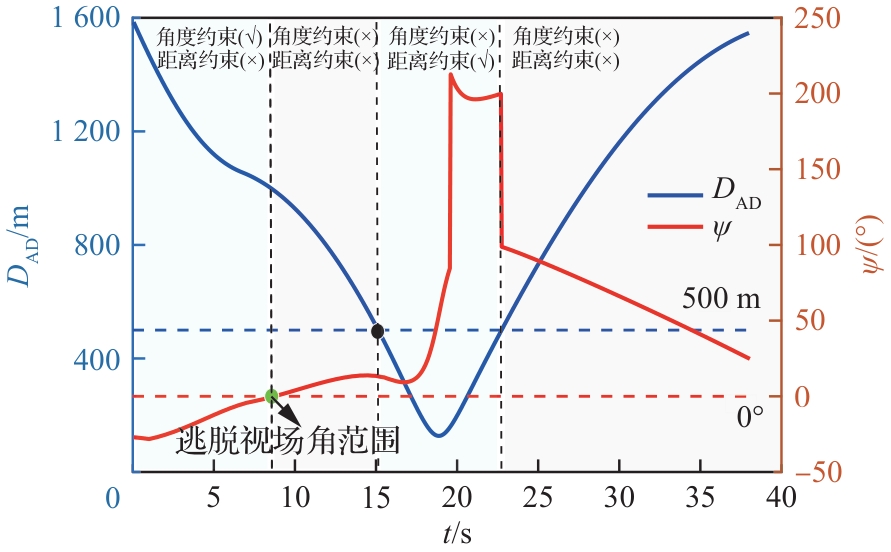
图 30
攻防双方距离和逃逸角对比曲线(进攻方>拦截器,PN-sin)
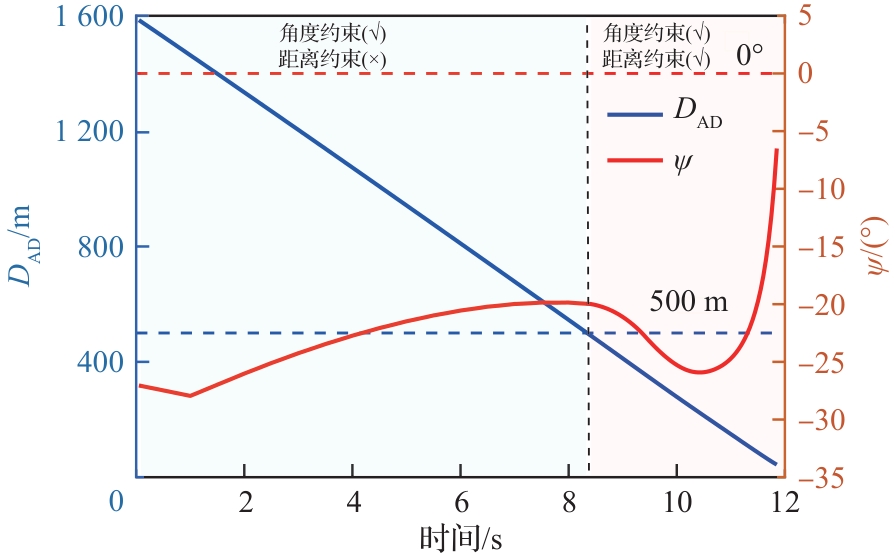
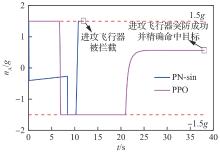
图 31
进攻飞行器法向过载(进攻方>拦截器)
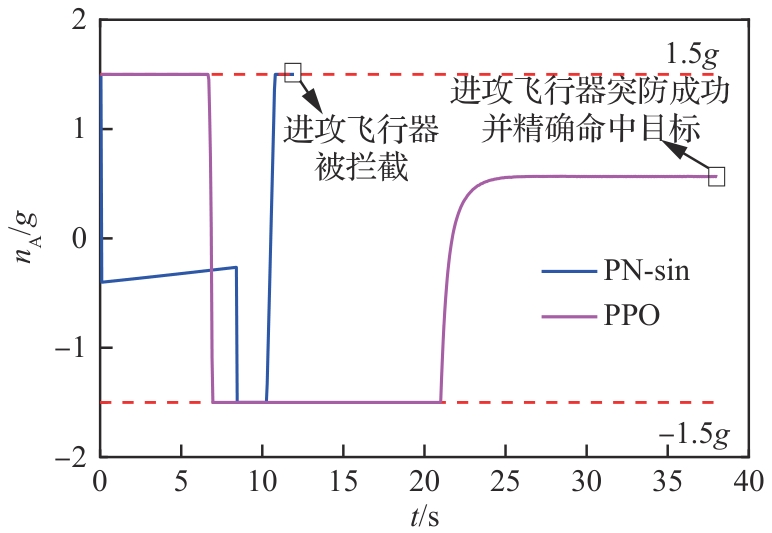
图 32
拦截器法向过载(进攻方>拦截器)
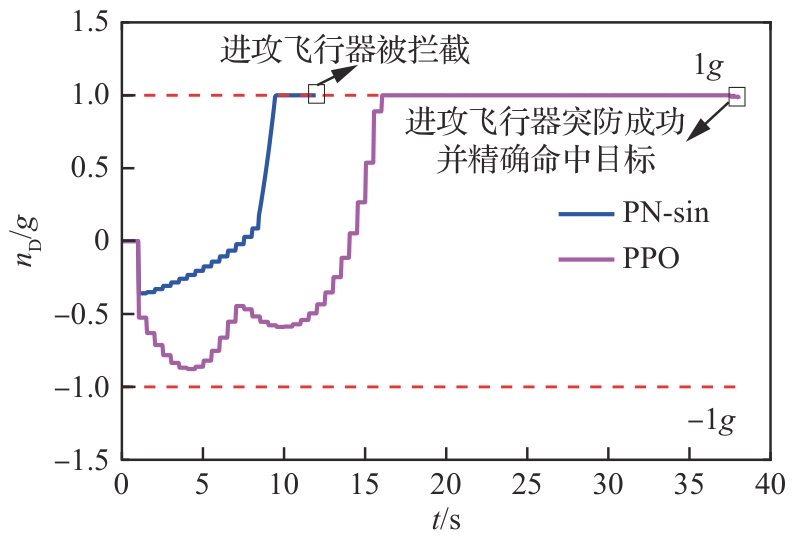
图 33
进攻飞行器航向角(进攻方>拦截器)
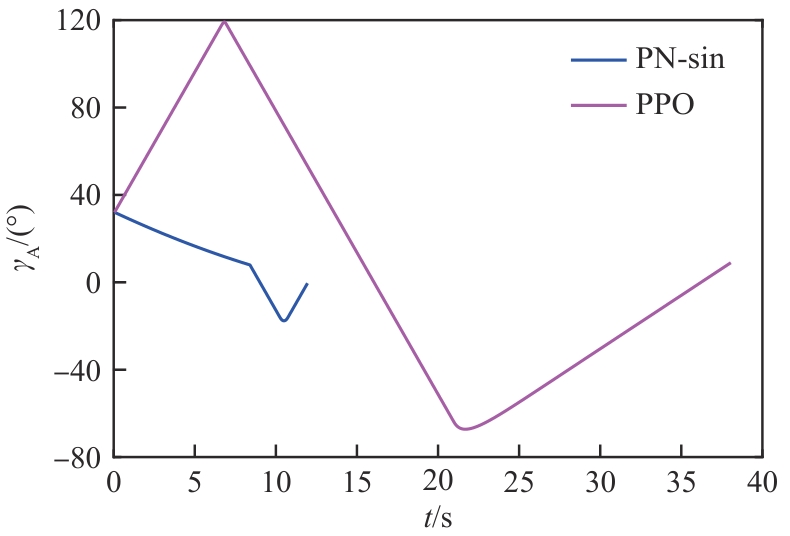
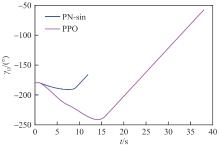
图 34
拦截器航向角(进攻方>拦截器)
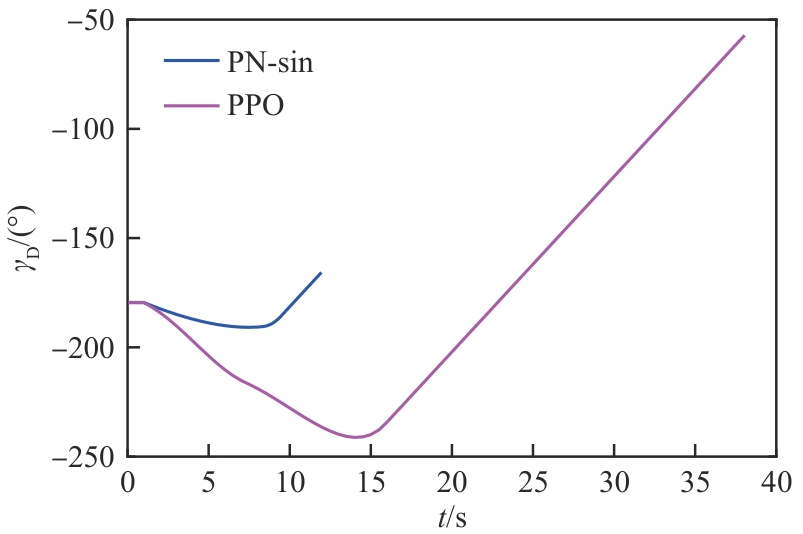
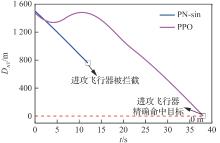
图 35
进攻飞行器和目标的距离(进攻方>拦截器)

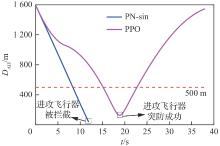
图 36
攻防双方飞行器距离(进攻方>拦截器)
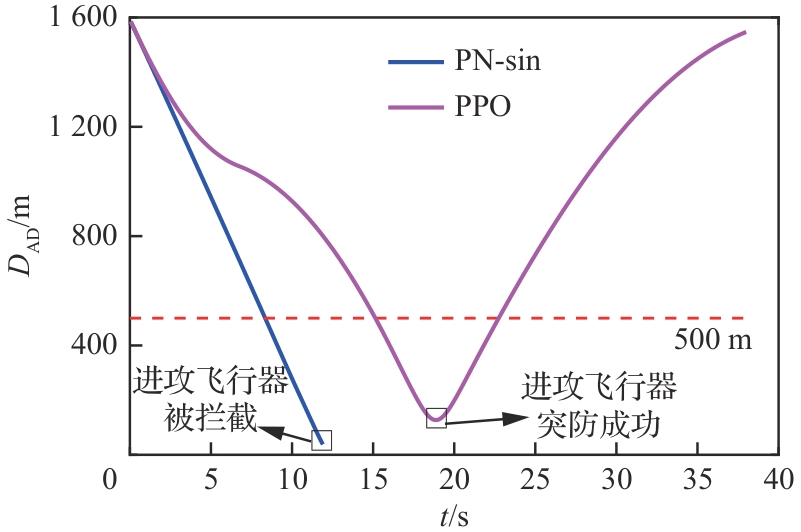
表 5
不同任务场景下进攻飞行器突防成功率统计
| 场景编号 | 任务编号 | 拦截器 | 进攻飞行器 | PPO制导突 防成功率/% | PN-sin制导突防 成功率/% | ||
|---|---|---|---|---|---|---|---|
| 速度/(m·s-1) | 过载能力/g | 速度/(m·s-1) | 过载能力/g | ||||
| ① | 1 | 60 | [-1.5,1.5] | 65 | [-1.5,1.5] | 99.4 | 79.6 |
| 2 | 65 | [-1.5,1.5] | 99.2 | 79.1 | |||
| 3 | 70 | [-1.5,1.5] | 98.7 | 76.2 | |||
| 4 | 75 | [-1.5,1.5] | 92.3 | 72.9 | |||
| 5 | 80 | [-1.5,1.5] | 86.1 | 68.7 | |||
| 6 | 85 | [-1.5,1.5] | 51.2 | 60.5 | |||
| ② | 7 | 65 | [-3,3] | 65 | [-1.5,1.5] | 96.7 | 0 |
| 8 | 65 | [-4.5,4.5] | 34.9 | 0 | |||
| 9 | 65 | [-6,6] | 0 | 0 | |||
| 10 | 70 | [-3,3] | 93.9 | 0 | |||
| 11 | 60 | [-3,3] | 96.9 | 0 | |||
| ③ | 12 | 60 | [-1,1] | 65 | [-1.5,1.5] | 100 | 100 |
| 13 | 65 | [-1,1] | 99.2 | 91.7 | |||
| 14 | 70 | [-1,1] | 92.4 | 89.7 | |||
| 1 | LAYNO S B. A model of the ABM-vs.-RV engagement with imperfect RV discrimination[J]. Operations Research, 1971, 19(6): 1502-1517. |
| 2 | HE L, YAN X D. Adaptive terminal guidance law for spiral-diving maneuver based on virtual sliding targets[J]. Journal of Guidance, Control, and Dynamics, 2018, 41(7): 1591-1601. |
| 3 | ZARCHAN P. Proportional navigation and weaving targets[J]. Journal of Guidance, Control, and Dynamics, 1995, 18(5): 969-974. |
| 4 | 吴炎烜, 陆胥坛, 王正杰. 基于滑模控制的飞行器螺旋机动、制导与控制一体化设计研究[J]. 北京理工大学学报, 2022, 42(5): 523-529. |
| WU Y X, LU X T, WANG Z J. Research on integrated design of aircraft spiral maneuver, guidance and control based on sliding mode control[J]. Transactions of Beijing Institute of Technology, 2022, 42(5): 523-529 (in Chinese). | |
| 5 | FONOD R, SHIMA T. Multiple model adaptive evasion against a homing missile[J]. Journal of Guidance, Control, and Dynamics, 2016, 39(7): 1578-1592. |
| 6 | 黄鲁豫, 曲鑫, 凡永华, 等. 多约束下的导弹螺旋机动制导控制一体化设计[J]. 宇航学报, 2021, 42(9): 1108-1118. |
| HUANG L Y, QU X, FAN Y H, et al. Integrated guidance and control design for spiral maneuvering missile with multiple constraints[J]. Journal of Astronautics, 2021, 42(9): 1108-1118 (in Chinese). | |
| 7 | ZHAO D J, SONG Z Y. Reentry trajectory optimization with waypoint and no-fly zone constraints using multiphase convex programming[J]. Acta Astronautica, 2017, 137: 60-69. |
| 8 | AKDAG R, ALTILAR D. Modeling evasion tactics of a fighter against missiles in three dimensions: AIAA-2006-6604[R]. Reston: AIAA, 2006. |
| 9 | EXARCHOS I, TSIOTRAS P, PACHTER M. UAV collision avoidance based on the solution of the suicidal pedestrian differential game: AIAA-2016-2100[R]. Reston: AIAA, 2016. |
| 10 | YU P, SHTESSEL Y B, EDWARDS C. Adaptive continuous higher order sliding mode control of air breathing hypersonic missile for maximum target penetration: AIAA-2015-2003[R]. Reston: AIAA, 2015. |
| 11 | 武天才, 王宏伦, 任斌, 等. 考虑规避与突防的高超声速飞行器智能容错制导控制一体化设计[J]. 航空学报, 2024, 45(15): 329607. |
| WU T C, WANG H L, REN B, et al. Learning-based integrated fault-tolerant guidance and control for hypersonic vehicles considering avoidance and penetration[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(15): 329607 (in Chinese). | |
| 12 | BARES P, LAZARUS S, TSOURDOS A, et al. Adaptive guidance for UAV based on dubins path: AIAA-2013-5181[R]. Reston: AIAA, 2013. |
| 13 | KIM Y H, RYOO C K, TAHK M J. Guidance synthesis for evasive maneuver of anti-ship missiles against close-in weapon systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2010, 46(3): 1376-1388. |
| 14 | HOU L, WANG J, KUANG M, et al. Practical implementation of optimal bang-bang evasive guidance[J]. Journal of Guidance, Control, and Dynamics, 2024: 1-7. |
| 15 | 邱潇颀, 高长生, 荆武兴, 拦截大气层内机动目标的深度强化学习制导律 [J]. 宇航学报, 2022. 43(5): 685-695. |
| QIU X X, GAO C S, JING W X. (2022). Deep reinforcement learning guidance law for intercepting maneuvering targets within the atmosphere[J]. Journal of Astronautics, 43(5), 685-695 (in Chinese). | |
| 16 | HE S M, SHIN H S, TSOURDOS A. Computational missile guidance: A deep reinforcement learning approach[J]. Journal of Aerospace Information Systems, 2021, 18(8): 571-582. |
| 17 | WU M Y, HE X J, QIU Z M, et al. Guidance law of interceptors against a high-speed maneuvering target based on deep Q-Network[J]. Transactions of the Institute of Measurement and Control, 2022, 44(7): 1373-1387. |
| 18 | MERKULOV G, ICELAND E, MICHAELI S, et al. Reinforcement learning based decentralized weapon-target assignment and guidance: AIAA-2024-0125[R]. Reston: AIAA, 2024. |
| 19 | 肖柳骏, 李雅轩, 刘新福. 基于强化学习的高超声速滑翔飞行器自适应末制导[J]. 兵工学报, 2025, 46(02): 57-66. |
| XIAO L J, LI Y X, LIU X F. Adaptive terminal guidance for hypersonic gliding vehicle based on reinforcement learning[J]. Acta Armamentarii, 2025,46(02):57-66. (in Chinese). | |
| 20 | SINHA A, WHITE D, CAO Y C. Deep reinforcement learning-based optimal time-constrained intercept guidance: AIAA-2024-2206[R]. Reston: AIAA, 2006. |
| 21 | FEDERICI L, BENEDIKTER B, ZAVOLI A. Deep learning techniques for autonomous spacecraft guidance during proximity operations[J]. Journal of Spacecraft and Rockets, 2021, 58(6): 1774-1785. |
| 22 | CHEN W X, GAO C S, JING W X. Proximal policy optimization guidance algorithm for intercepting near-space maneuvering targets[J]. Aerospace Science and Technology, 2023, 132: 108031. |
| 23 | 惠俊鹏, 汪韧, 郭继峰, 基于强化学习的禁飞区绕飞智能制导技术 [J]. 航空学报, 2023. 44(11): 327416. |
| HUI J P, WANG R, GUO J F. Intelligent guidance technology for bypassing no-fly zones based on reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(11): 327416 (in Chinese). | |
| 24 | 高树一, 林德福, 郑多, 等. 针对集群攻击的飞行器智能协同拦截策略[J]. 航空学报, 2023, 44(18): 328301. |
| GAO S Y, LIN D F, ZHENG D, et al. Intelligent cooperative interception strategy of aircraft against cluster attack[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(18): 328301 (in Chinese). | |
| 25 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arxiv preprint: 1707.06347; 2017. |
| 26 | DENG T B, HUANG H, FANG Y W, et al. Reinforcement learning-based missile terminal guidance of maneuvering targets with decoys[J]. Chinese Journal of Aeronautics, 2023, 36(12): 309-324. |
| 27 | 王雨琪, 宁国栋, 王晓峰, 等. 基于微分对策的临近空间飞行器机动突防策略[J]. 航空学报, 2020, 41(S2): 724276. |
| WANG Y Q, NING G D, WANG X F, et al. Maneuvering penetration strategy of near space vehicle based on differential game[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S2): 724276 (in Chinese). |
| [1] | 万开方, 吴志林, 武韫晖, 强皓植, 吴艺博, 李波. 拒止环境下基于深度强化学习的多无人机协同定位[J]. 航空学报, 2025, 46(8): 331024-331024. |
| [2] | 姜凌峰, 李新凯, 张海, 李涵玮, 张宏立. 基于改进TD3算法的无人机动态环境无地图导航[J]. 航空学报, 2025, 46(8): 331035-331035. |
| [3] | 杨敏, 刘关俊, 周子渊. 基于安全强化学习的月球着陆器控制[J]. 航空学报, 2025, 46(3): 630553-630553. |
| [4] | 张鸿林, 罗建军, 马卫华. 基于机器学习的航天器规避目标威胁博弈决策[J]. 航空学报, 2024, 45(8): 329136-329136. |
| [5] | 蔡云鹏, 周大鹏, 丁江川. 具有防撞安全约束的无人机集群智能协同控制[J]. 航空学报, 2024, 45(5): 529683-529683. |
| [6] | 单圣哲, 张伟伟. 基于自博弈深度强化学习的空战智能决策方法[J]. 航空学报, 2024, 45(4): 328723-328723. |
| [7] | 高兵, 张哲婕, 邹启杰, 刘治国, 赵锡玲. 基于深度强化学习和信息论的多智能体通信方法[J]. 航空学报, 2024, 45(18): 329862-329862. |
| [8] | 李佐龙, 朱纪洪, 匡敏驰, 张杰, 任洁. 基于混合动作的空战分层强化学习决策算法[J]. 航空学报, 2024, 45(17): 530053-530053. |
| [9] | 武天才, 王宏伦, 任斌, 刘一恒, 吴星雨, 严国乘. 考虑规避与突防的高超声速飞行器智能容错制导控制一体化设计[J]. 航空学报, 2024, 45(15): 329607-329607. |
| [10] | 倪炜霖, 王永海, 徐聪, 赤丰华, 梁海朝. 基于强化学习的高超飞行器协同博弈制导方法[J]. 航空学报, 2023, 44(S2): 729400-729400. |
| [11] | 王雪鉴, 文永明, 石晓荣, 张宁宁, 刘洁玺. 多智能体多耦合任务混合式智能决策架构设计[J]. 航空学报, 2023, 44(S2): 729770-729770. |
| [12] | 高锡珍, 汤亮, 黄煌. 深度强化学习技术在地外探测自主操控中的应用与挑战[J]. 航空学报, 2023, 44(6): 26762-026762. |
| [13] | 周攀, 黄江涛, 章胜, 刘刚, 舒博文, 唐骥罡. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4): 126731-126731. |
| [14] | 朱祥维, 沈丹, 肖凯, 马岳鑫, 廖祥, 古富强, 余芳文, 高柯夫, 刘经南. 类脑导航的机理、算法、实现与展望[J]. 航空学报, 2023, 44(19): 28569-028569. |
| [15] | 高树一, 林德福, 郑多, 胡馨予. 针对集群攻击的飞行器智能协同拦截策略[J]. 航空学报, 2023, 44(18): 328301-328301. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 航空学报编辑部
版权所有 © 2011航空学报杂志社
主管单位:中国科学技术协会 主办单位:中国航空学会 北京航空航天大学