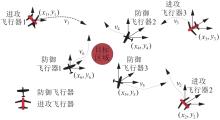
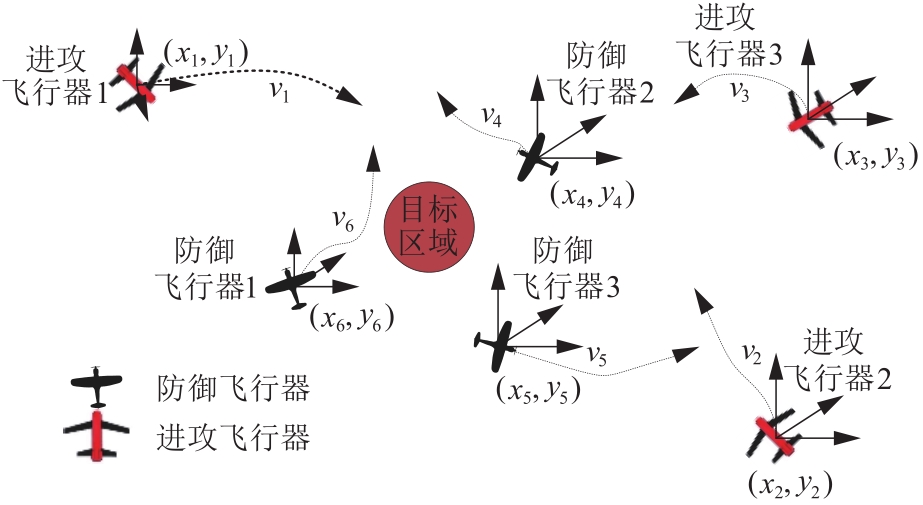
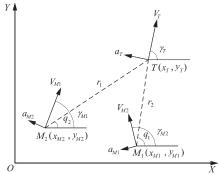
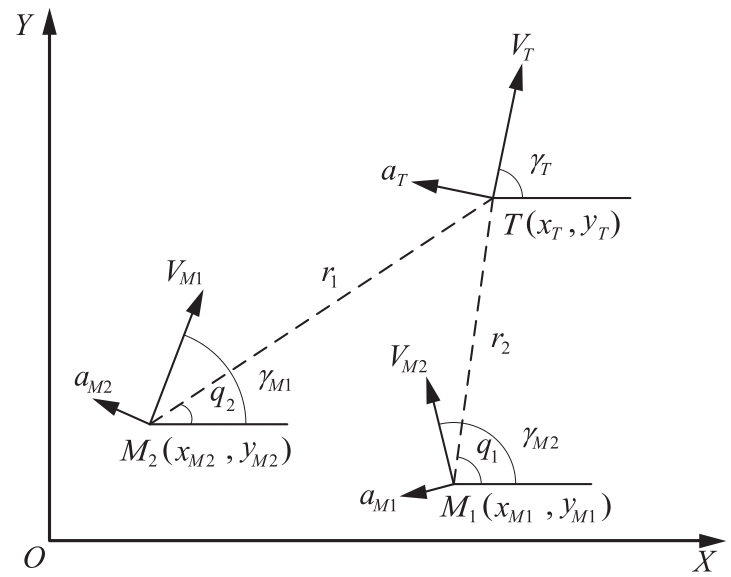
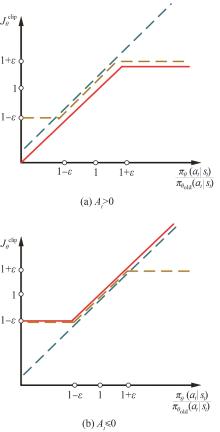
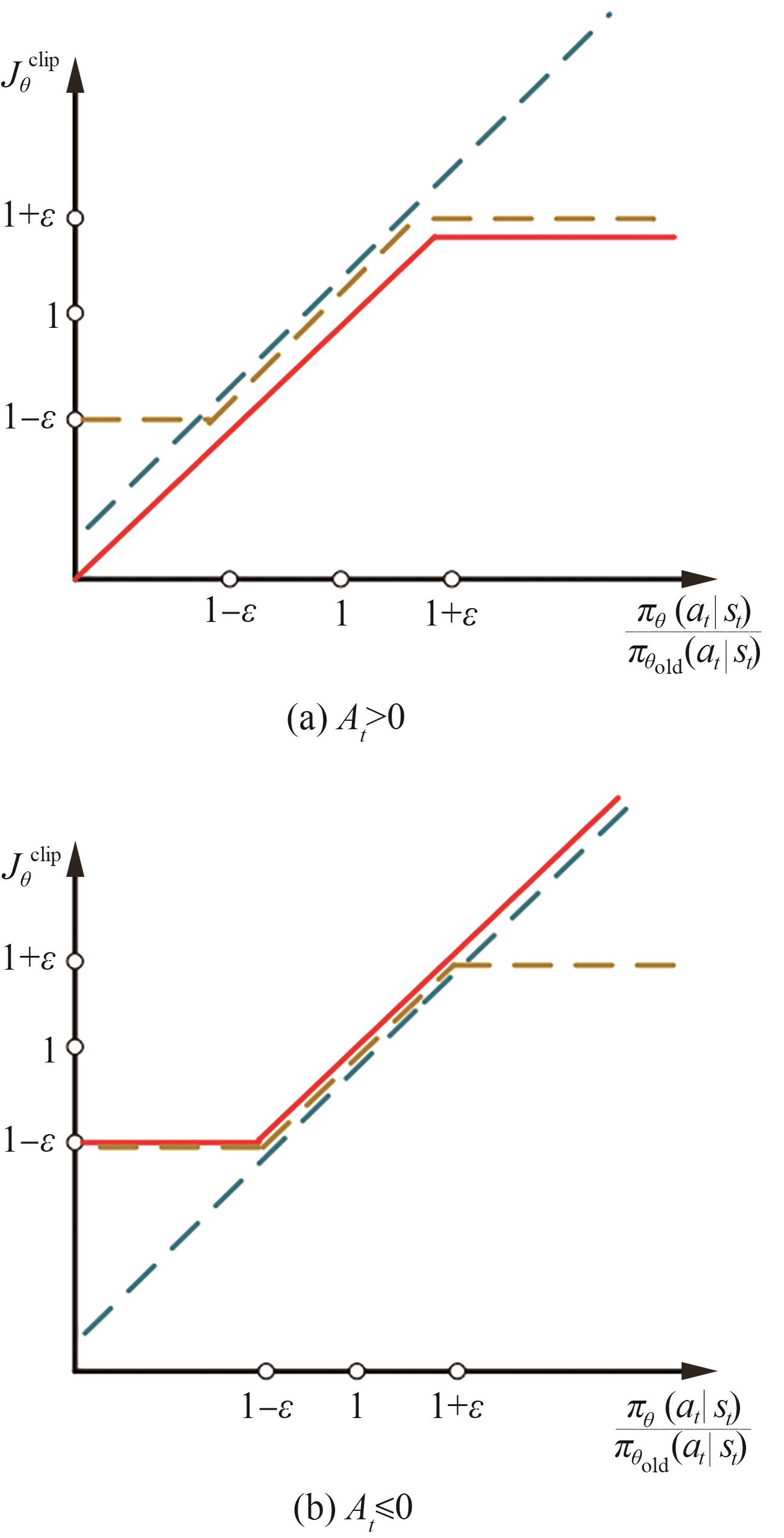
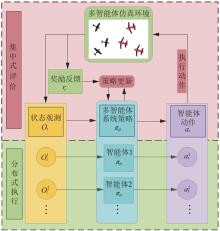
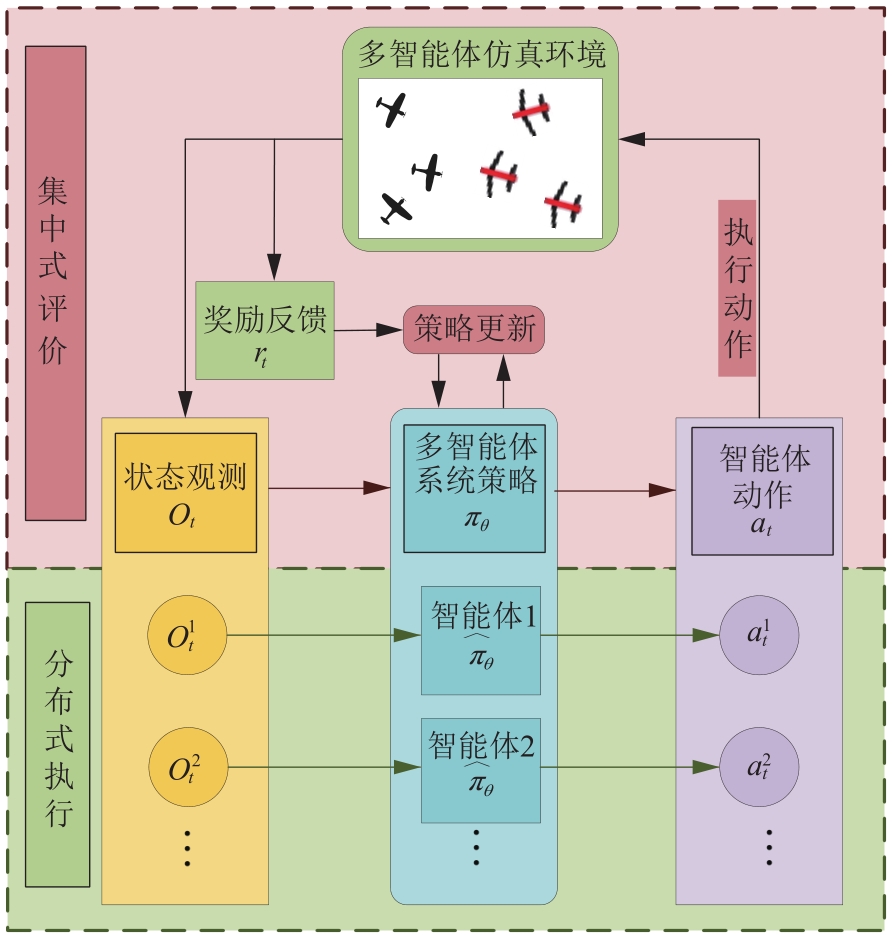
| 1 |
GUO D, LIANG Z X, JIANG P, et al. Weapon-target assignment for multi-to-multi interception with grouping constraint[J]. IEEE Access, 2019, 7: 34838-34849.
|
| 2 |
GUO J G, HU G J, GUO Z Y, et al. Evaluation model, intelligent assignment, and cooperative interception in multimissile and multitarget engagement[J]. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(4): 3104-3115.
|
| 3 |
KHOSRAVI M, AGHDAM A G. Cooperative receding horizon control for multi-target interception in uncertain environments[C]∥ 53rd IEEE Conference on Decision and Control. Piscataway: IEEE Press, 2015: 4497-4502.
|
| 4 |
MENG X Q, SUN B, ZHU D Q. Harbour protection: Moving invasion target interception for multi-AUV based on prediction planning interception method[J]. Ocean Engineering, 2021, 219: 108268.
|
| 5 |
SUN Z Y, YANG J Y. Multi-missile interception for multi-targets: Dynamic situation assessment, target allocation and cooperative interception in groups[J]. Journal of the Franklin Institute, 2022, 359(12): 5991-6022.
|
| 6 |
ZHU R, SUN D, ZHOU Z Y. Cooperation strategy of unmanned air vehicles for multitarget interception[J]. Journal of Guidance, Control, and Dynamics, 2005, 28(5): 1068-1072.
|
| 7 |
JEON I S, LEE J I, TAHK M J. Impact-time-control guidance law for anti-ship missiles[J]. IEEE Transactions on Control Systems Technology, 2006, 14(2): 260-266.
|
| 8 |
吕腾,吕跃勇,李传江,等.带空间协同的多导弹时间协同制导律[J].航空学报,2018,39(10):322115.
|
|
LYU T, LYU Y Y, LI C J, et al. Time cooperative guidance law for multiple missiles with space coopera-tion [J]. Acta Aeronautica et Astronautica Sinica, 2018, 39(10): 322115 (in Chinese).
|
| 9 |
SINHA A, KUMAR S R. Supertwisting control-based cooperative salvo guidance using leader-follower approach[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(5): 3556-3565.
|
| 10 |
ZHANG P, ZHANG X Y. Multiple missiles fixed-time cooperative guidance without measuring radial velocity for maneuvering targets interception[J]. ISA Transactions, 2022, 126: 388-397.
|
| 11 |
SHAFERMAN V, SHIMA T. Linear quadratic guidance laws for imposing a terminal intercept angle[J]. Journal of Guidance, Control, and Dynamics, 2008, 31(5): 1400-1412.
|
| 12 |
SUN X J, ZHOU R, HOU D L, et al. Consensus of leader-followers system of multi-missile with time-delays and switching topologies[J]. Optik, 2014, 125(3): 1202-1208.
|
| 13 |
ERER K, MERTTOPÇUOGLU O. Indirect control of impact angle against stationary targets using biased PPN: AIAA-2010-8184[R]. Reston: AIAA, 2010.
|
| 14 |
HARL N, BALAKRISHNAN S N. Impact time and angle guidance with sliding mode control[J]. IEEE Transactions on Control Systems Technology, 2012, 20(6): 1436-1449.
|
| 15 |
KUMAR S R, RAO S, GHOSE D. Nonsingular terminal sliding mode guidance with impact angle constraints[J]. Journal of Guidance, Control, and Dynamics, 2014, 37(4): 1114-1130.
|
| 16 |
DONG X F, REN Z. Impact angle constrained distributed cooperative guidance against maneuvering targets with undirected communication topologies[J]. IEEE Access, 2020, 8: 117867-117876.
|
| 17 |
KANG S, KIM H J. Differential game missile guidance with impact angle and time constraints[J]. IFAC Proceedings Volumes, 2011, 44(1): 3920-3925.
|
| 18 |
WANG B L, LI S G, GAO X Z, et al. UAV swarm confrontation using hierarchical multiagent reinforcement learning[J]. International Journal of Aerospace Engineering, 2021, 2021: 1-12.
|
| 19 |
陈灿, 莫雳, 郑多, 等. 非对称机动能力多无人机智能协同攻防对抗[J]. 航空学报, 2020, 41(12): 324152.
|
|
CHEN C, MO L, ZHENG D, et al. Cooperative attack-defense game of multiple UAVs with asymmetric maneuverability[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(12): 324152 (in Chinese).
|
| 20 |
IMADO F, KURODA T. Family of local solutions in a missile-aircraft differential game[J]. Journal of Guidance, Control, and Dynamics, 2011, 34(2): 583-591.
|
| 21 |
Bowling M, Veloso M. Rational and convergent learning in stochastic games[C]∥ International Joint Conference On Artificial Intelligence. Hillsdale: Lawrence Erlbaum Associates Ltd, 2001: 1021-1026.
|
| 22 |
罗德林, 段海滨, 吴顺详, 等. 基于启发式蚁群算法的协同多目标攻击空战决策研究[J]. 航空学报, 2006, 27(6): 1166-1170.
|
|
LUO D L, DUAN H B, WU S X, et al. Research on air combat decision-making for cooperative multiple target attack using heuristic ant colony algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2006, 27(6): 1166-1170 (in Chinese).
|
| 23 |
裴培, 何绍溟, 王江, 等. 一种深度强化学习制导控制一体化算法[J]. 宇航学报, 2021, 42(10): 1293-1304.
|
|
PEI P, HE S M, WANG J, et al. Integrated guidance and control for missile using deep reinforcement learning[J]. Journal of Astronautics, 2021, 42(10): 1293-1304 (in Chinese).
|
| 24 |
LEE S M, KIM H, MYUNG H, et al. Cooperative coevolutionary algorithm-based model predictive control guaranteeing stability of multirobot formation[J]. IEEE Transactions on Control Systems Technology, 2015, 23(1): 37-51.
|
| 25 |
WU X, LIU Y, XIE S R, et al. Collaborative defense with multiple USVs and UAVs based on swarm intelligence[J]. Journal of Shanghai Jiaotong University (Science), 2020, 25(1): 51-56.
|
| 26 |
LUO Y X, SONG J A, ZHAO K, et al. UAV-cooperative penetration dynamic-tracking interceptor method based on DDPG[J]. Applied Sciences, 2022, 12(3): 1618.
|
 ), 胡馨予2
), 胡馨予2