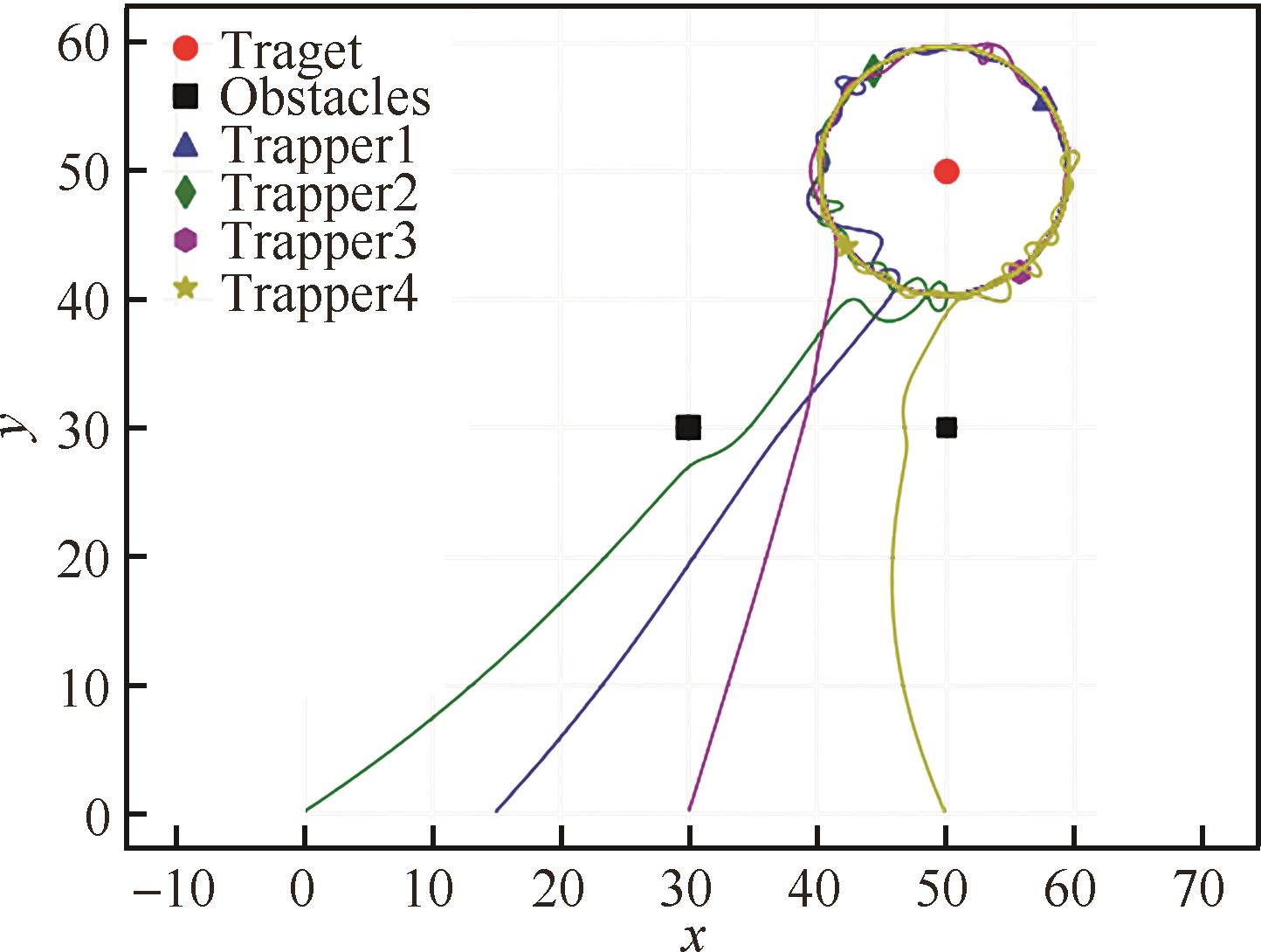
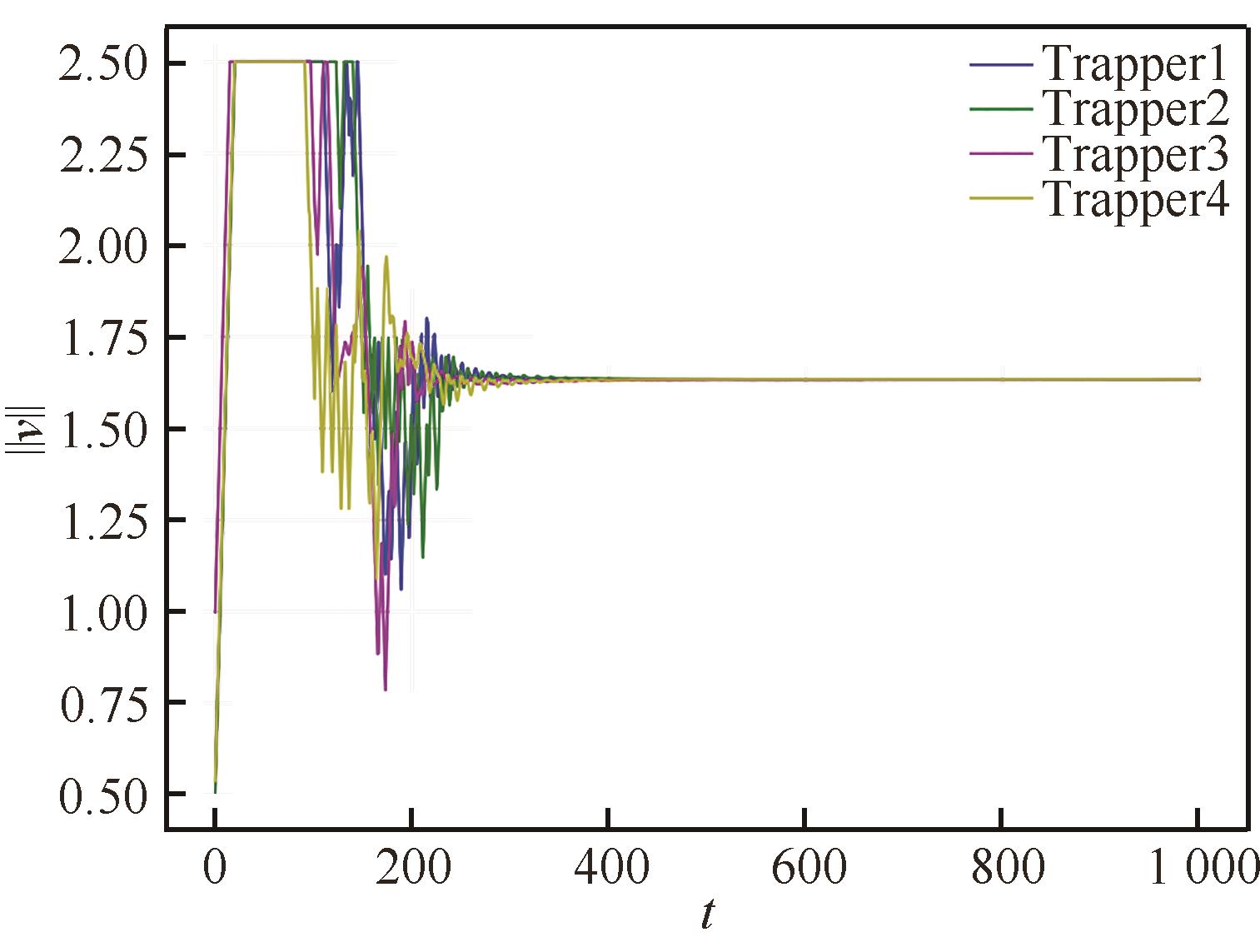
| [1] |
万开方, 吴志林, 武韫晖, 强皓植, 吴艺博, 李波. 拒止环境下基于深度强化学习的多无人机协同定位[J]. 航空学报, 2025, 46(8): 331024-331024. |
| [2] |
姜凌峰, 李新凯, 张海, 李涵玮, 张宏立. 基于改进TD3算法的无人机动态环境无地图导航[J]. 航空学报, 2025, 46(8): 331035-331035. |
| [3] |
杨敏, 刘关俊, 周子渊. 基于安全强化学习的月球着陆器控制[J]. 航空学报, 2025, 46(3): 630553-630553. |
| [4] |
王辰, 魏才盛, 殷泽阳, 靳锴, 李星辰. 考虑信道资源约束的多无人机航迹与通信策略协同规划[J]. 航空学报, 2025, 46(18): 331837-331837. |
| [5] |
罗祎喆, 张辉, 余新得, 金钊, 冯朔, 石育澄, 徐明亮. 面向舰载机多波次弹药保障任务的分层动态调度[J]. 航空学报, 2025, 46(18): 331945-331945. |
| [6] |
黄湘松, 王梦宇, 潘大鹏. 基于对抗强化学习的无人机逃离路径规划方法[J]. 航空学报, 2025, 46(17): 331637-331637. |
| [7] |
王昱, 谢志鹏, 田永健, 孟光磊. 虚拟结构引领强化学习分布式无人机编队控制[J]. 航空学报, 2025, 46(15): 331354-331354. |
| [8] |
陈伟, 李璐璐, 陈董, 张少辉, 李亚飞, 王可, 靳远远, 徐明亮. 差异化保障需求驱动的舰载机多机协同决策方法[J]. 航空学报, 2025, 46(13): 531274-531274. |
| [9] |
陈旭东, 陈琦琦, 罗祎喆, 王佳宝, 徐明亮. 异构舰载机舰面保障作业动态并行调度[J]. 航空学报, 2025, 46(13): 531329-531329. |
| [10] |
王政, 王华, 崔可可, 李超超, 刘俊楠, 徐明亮. 局部引导强化学习的舰载机自主调运方法[J]. 航空学报, 2025, 46(13): 531333-531333. |
| [11] |
凌文辉, 牟春晖, 聂聆聪, 杜宪, 孙希明. 基于改进DDPG的宽速域几何可调燃烧室压力分布控制[J]. 航空学报, 2025, 46(12): 131092-131092. |
| [12] |
余子杰, 郑征, 李清东, 郭林, 任素萍, 郭健. 基于深度强化学习的太阳能无人机航迹规划[J]. 航空学报, 2025, 46(12): 331420-331420. |
| [13] |
赵长啸, 孙亦轩. 面向适航要求的eVTOL航电系统安全调度模型[J]. 航空学报, 2025, 46(11): 531252-531252. |
| [14] |
高树一, 林德福, 郑多, 徐骋. 考虑拦截器探测能力限制的飞行器智能机动突防制导策略[J]. 航空学报, 2025, 46(10): 331304-331304. |
| [15] |
薛震, 盛汉霖, 陈欣, 魏鹏轩, 李嘉诚, 陈芊. 基于剪枝可视性地图的无人机全局规划方法[J]. 航空学报, 2025, 46(10): 331279-331279. |
 ), 韩艺琳
), 韩艺琳