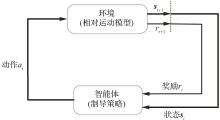
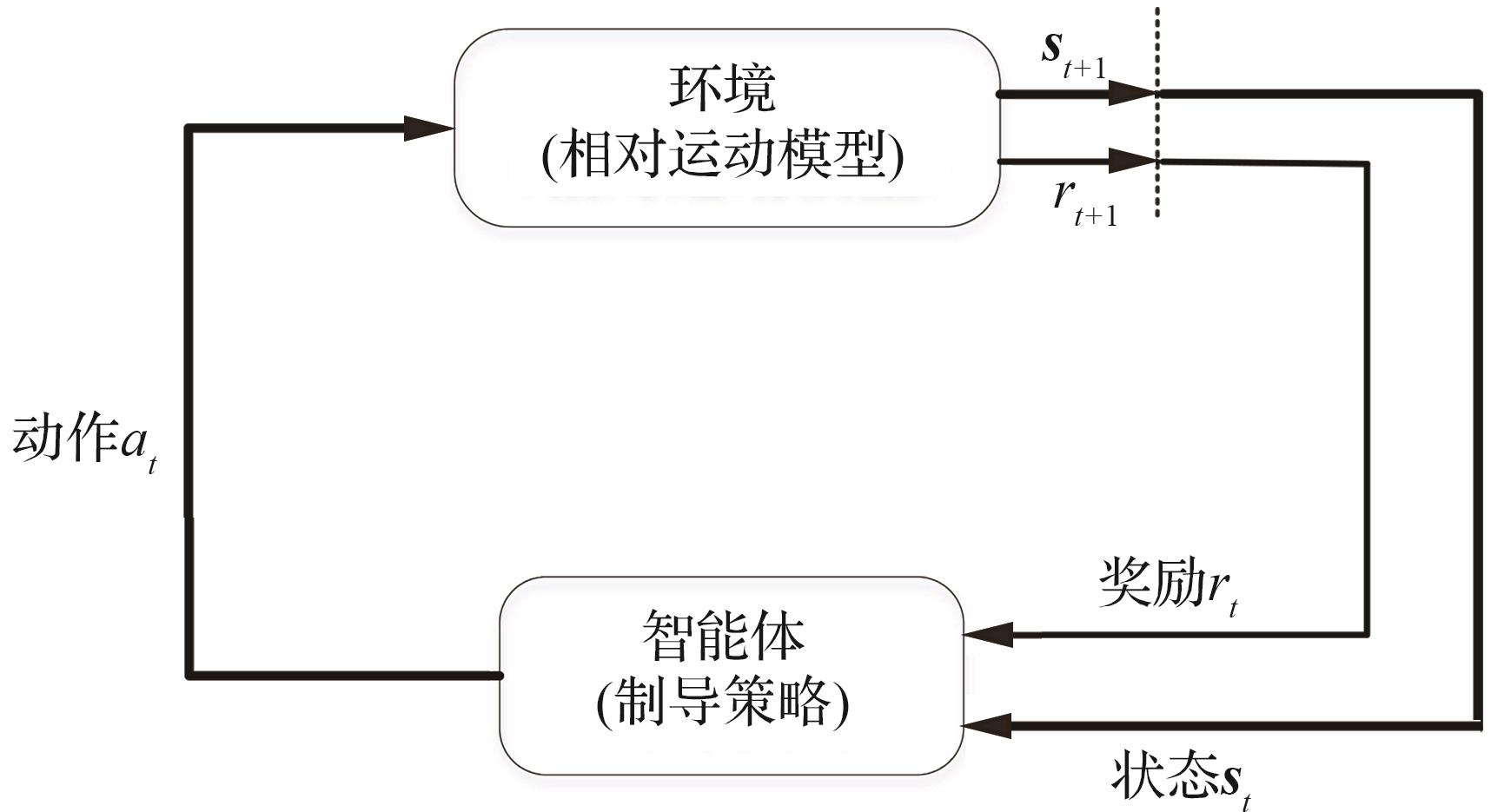
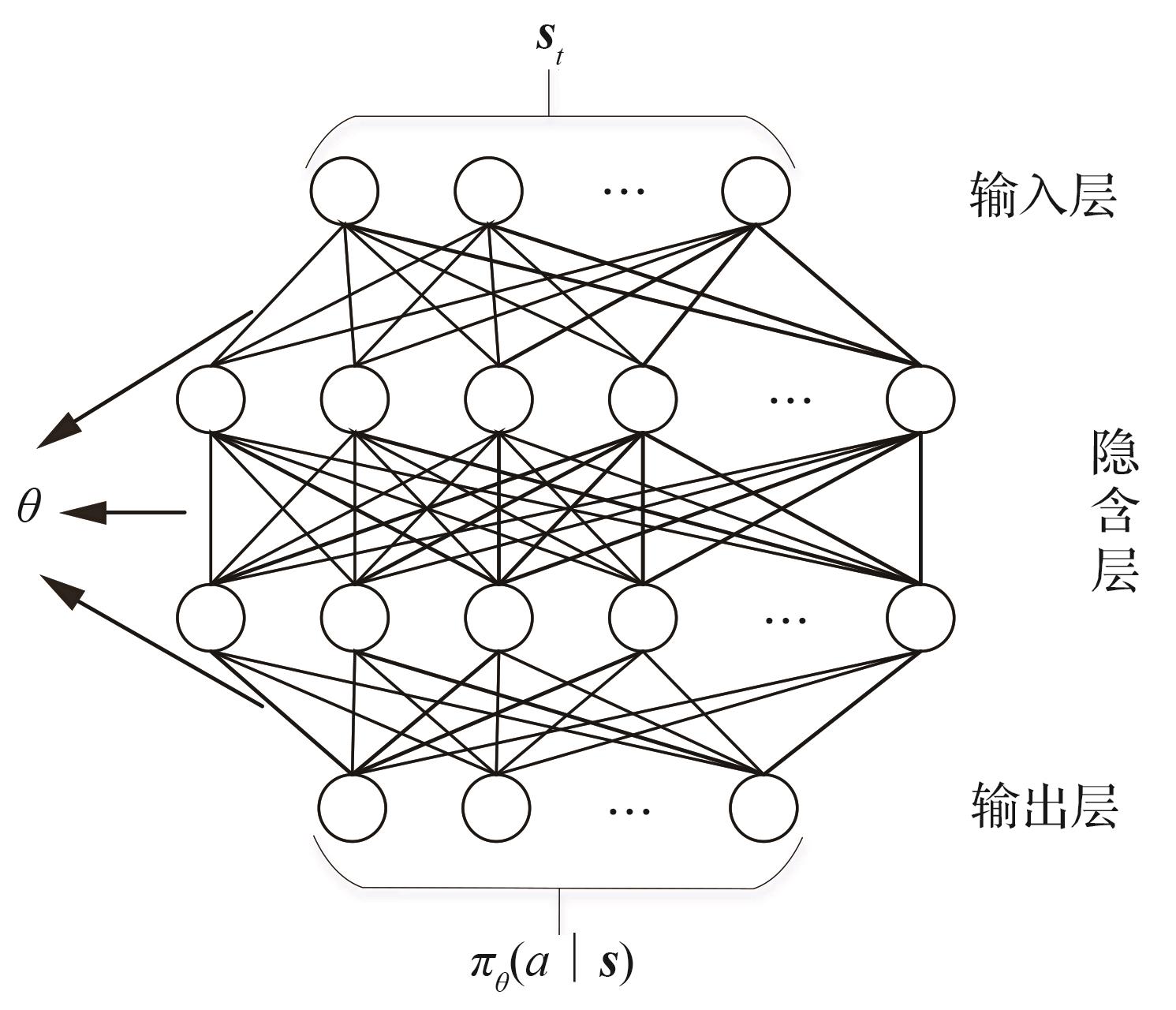
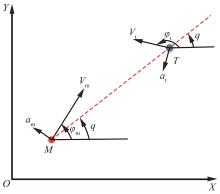
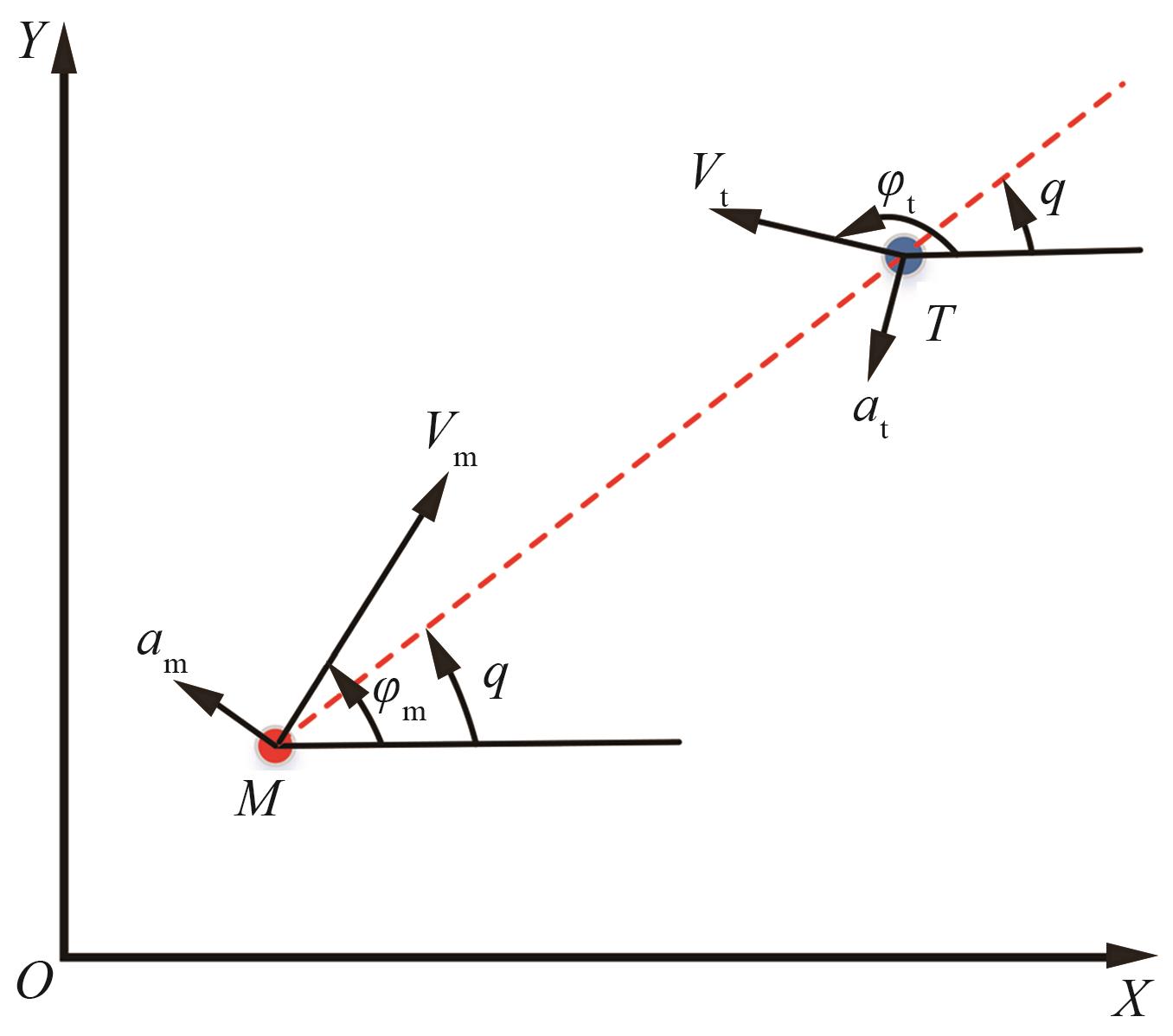
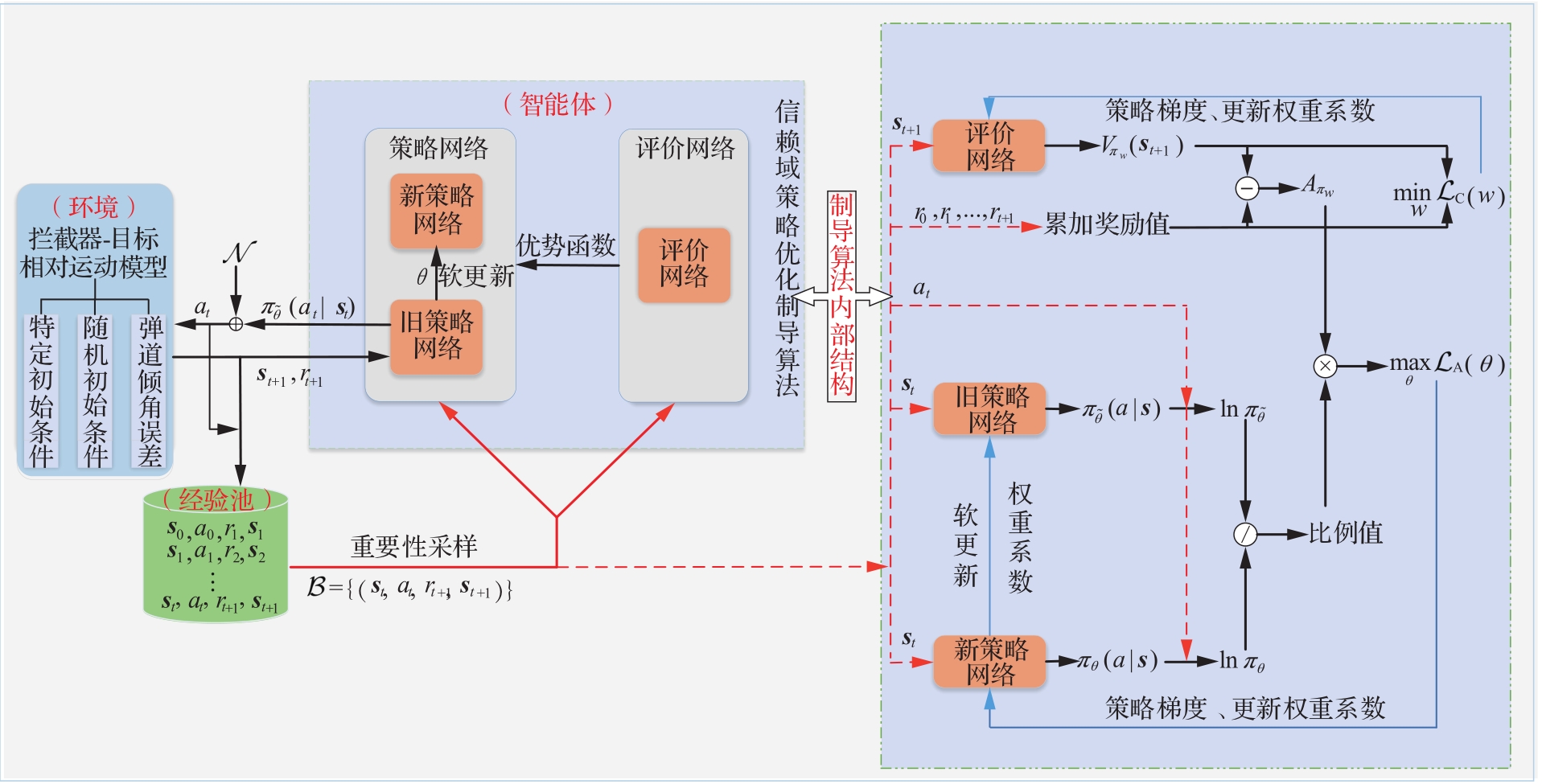
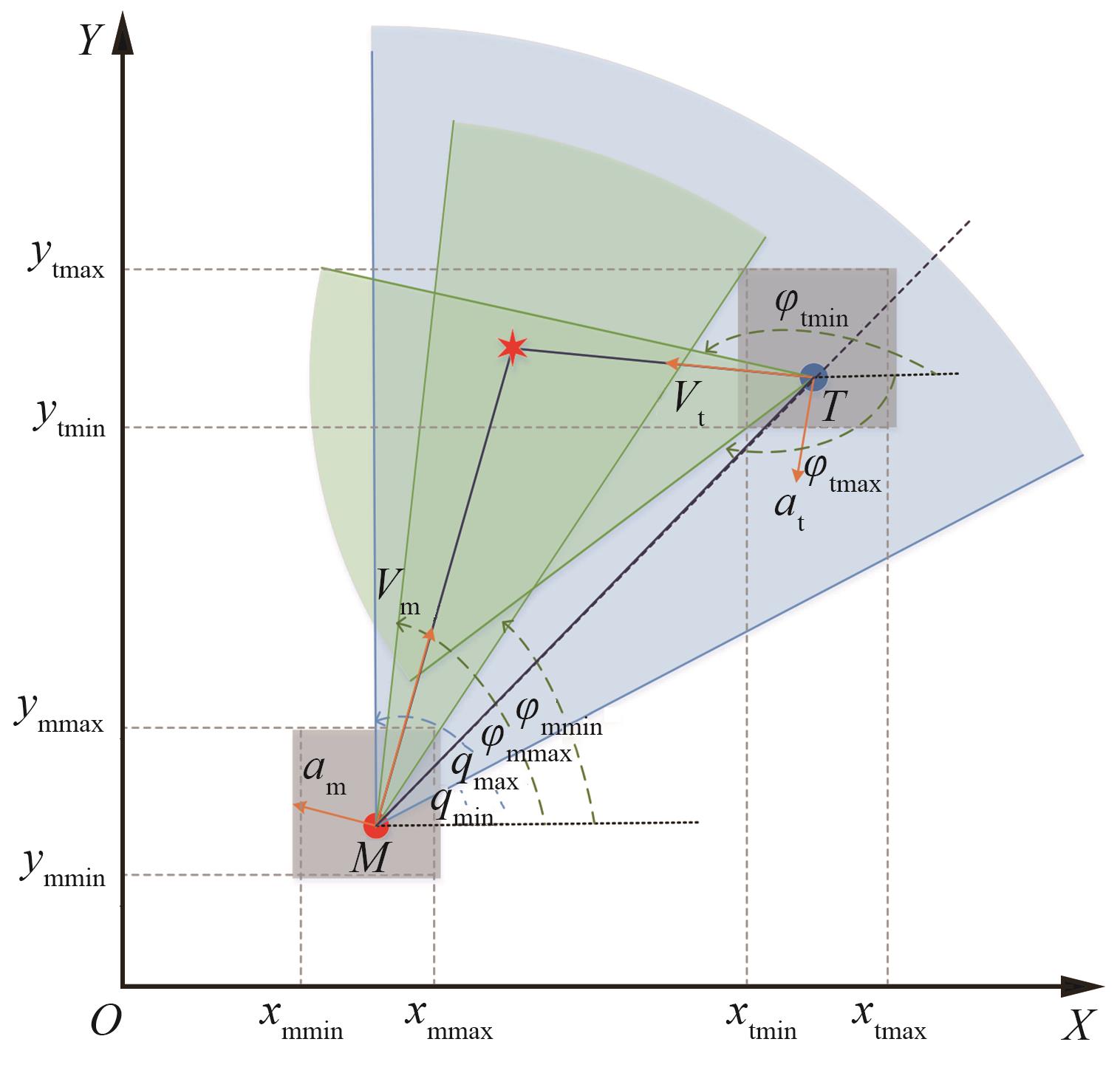
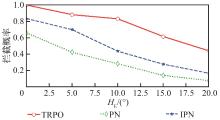
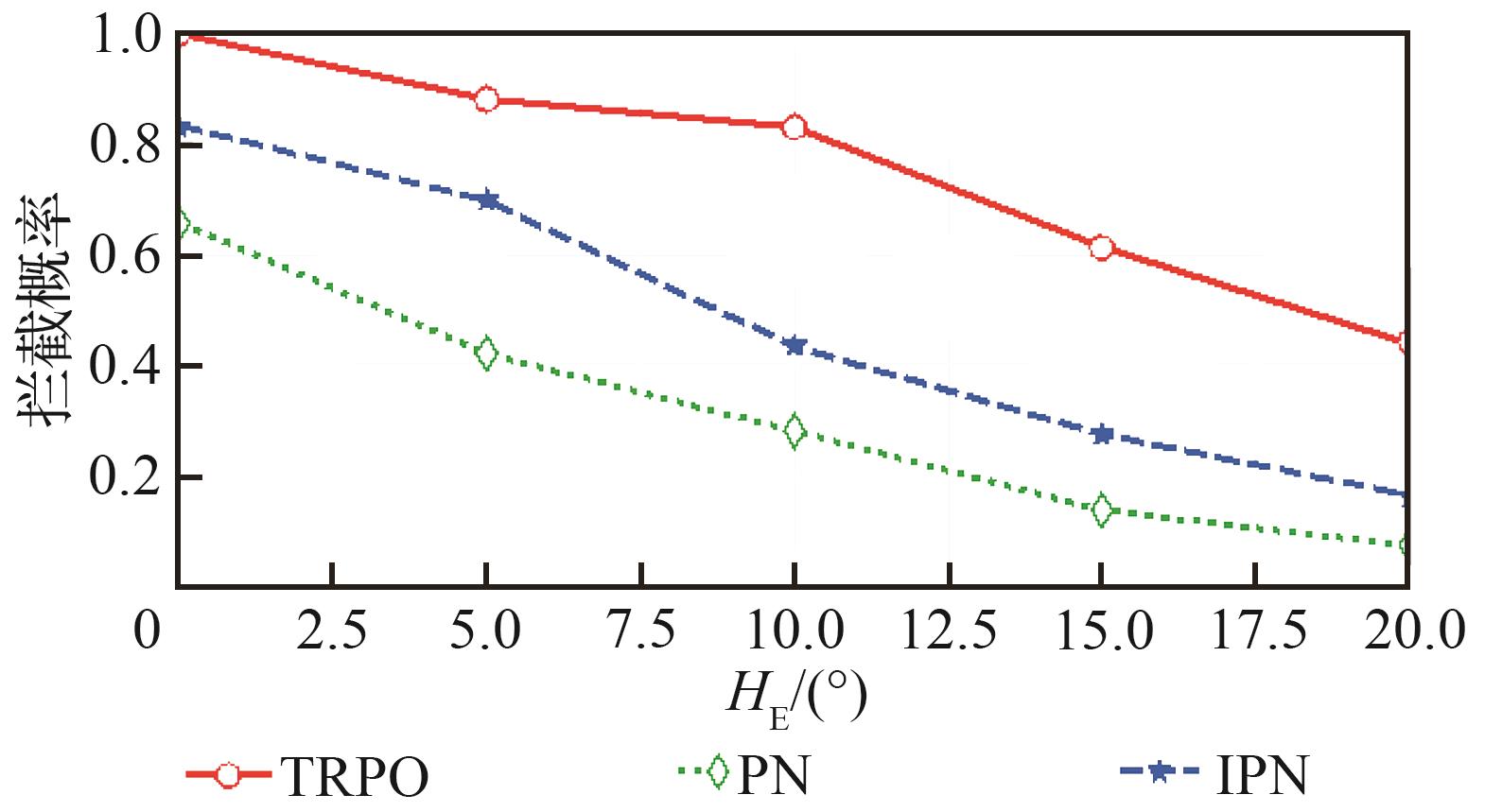
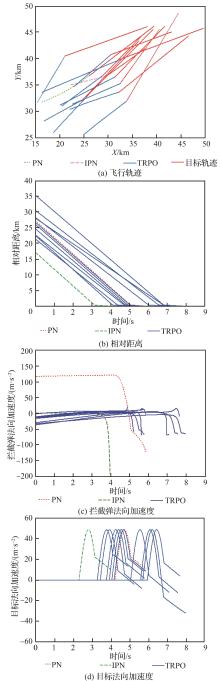
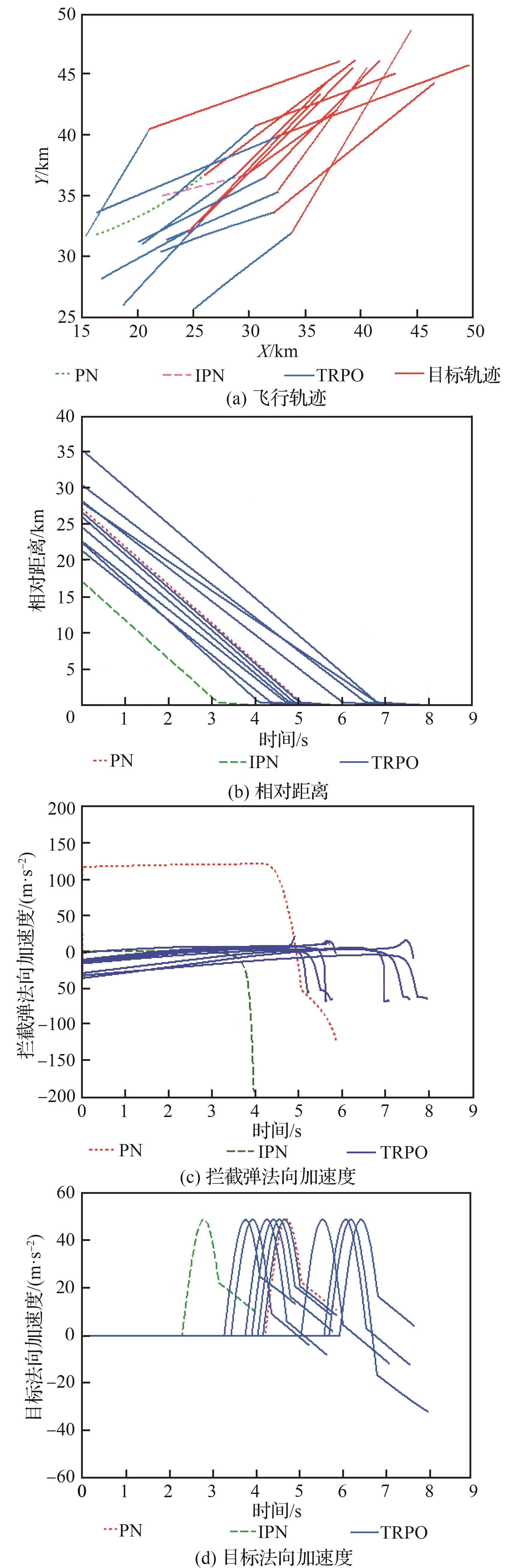
| 1 |
GOLESTANI M, MOHAMMADZAMAN I, VALI A R. Finite-time convergent guidance law based on integral backstepping control[J]. Aerospace Science and Technology, 2014, 39: 370-376.
|
| 2 |
ZARCHAN P. Tactical and strategic missile guidance[M]. 7th ed. Reston: AIAA, 2019.
|
| 3 |
GUELMAN M. A qualitative study of proportional navigation[J]. IEEE Transactions on Aerospace and Electronic Systems, 1971, AES-7(4): 637-643.
|
| 4 |
GHAWGHAWE S N, GHOSE D. Pure proportional navigation against time-varying target manoeuvres[J]. IEEE Transactions on Aerospace and Electronic Systems, 1996, 32(4): 1336-1347.
|
| 5 |
黎克波, 廖选平, 梁彦刚, 等. 基于纯比例导引的拦截碰撞角约束制导策略[J]. 航空学报, 2020, 41(S2): 724277.
|
|
LI K B, LIAO X P, LIANG Y G, et al. Guidance strategy with impact angle constraints based on pure proportional navigation[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S2): 724277 (in Chinese).
|
| 6 |
YUAN P, CHEN M G. Extended true proportional navigation[C]∥ SPIE Defense + Commercial Sensing. San Francisco: SPIE, 2001: 214-224.
|
| 7 |
袁泉, 赵秀娜, 马宏绪, 等. 一种改进的比例导引规律的设计与仿真[J]. 计算机仿真, 2007, 24(7): 65-68.
|
|
YUAN Q, ZHAO X N, MA H X, et al. Design and simulation of an advanced proportional guidance law[J]. Computer Simulation, 2007, 24(7): 65-68 (in Chinese).
|
| 8 |
ZHANG Z X, MAN C Y, LI S H, et al. Finite-time guidance laws for three-dimensional missile-target interception[J]. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2016, 230(2): 392-403.
|
| 9 |
ZHANG B L, ZHOU D. Optimal predictive sliding-mode guidance law for intercepting near-space hypersonic maneuvering target[J]. Chinese Journal of Aeronautics, 2022, 35(4): 320-331.
|
| 10 |
司玉洁, 熊华, 宋勋, 等. 三维自适应终端滑模协同制导律[J]. 航空学报, 2020, 41(S1): 723759.
|
|
SI Y J, XIONG H, SONG X, et al. Three dimensional guidance law for cooperative operation based on adaptive terminal sliding mode[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(S1): 723759 (in Chinese).
|
| 11 |
孙胜, 张华明, 周荻. 考虑自动驾驶仪动特性的终端角度约束滑模导引律[J]. 宇航学报, 2013, 34(1): 69-78.
|
|
SUN S, ZHANG H M, ZHOU D. Sliding mode guidance law with autopilot lag for terminal angle constrained trajectories[J]. Journal of Astronautics, 2013, 34(1): 69-78 (in Chinese).
|
| 12 |
张宽桥, 杨锁昌, 李宝晨, 等. 考虑驾驶仪动态特性的固定时间收敛制导律[J]. 航空学报, 2019, 40(11): 323227.
|
|
ZHANG K Q, YANG S C, LI B C, et al. Fixed-time convergent guidance law considering autopilot dynamics[J]. Acta Aeronautica et Astronautica Sinica, 2019, 40(11): 323227 (in Chinese).
|
| 13 |
EBRAHIMI B, BAHRAMI M, ROSHANIAN J. Optimal sliding-mode guidance with terminal velocity constraint for fixed-interval propulsive maneuvers[J]. Acta Astronautica, 2008, 62(10-11): 556-562.
|
| 14 |
王亚宁, 王辉, 林德福, 等. 基于虚拟视角约束的机动目标拦截制导方法[J]. 航空学报, 2022, 43(1): 324799.
|
|
WANG Y N, WANG H, LIN D F, et al. Guidance method for maneuvering target interception based on virtual look angle constraint[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(1): 324799 (in Chinese).
|
| 15 |
RYU M Y, LEE C H, TAHK M J. New trajectory shaping guidance laws for anti-tank guided missile[J]. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2015, 229(7): 1360-1368.
|
| 16 |
周聪, 闫晓东, 唐硕, 等. 大气层内模型预测静态规划拦截中制导[J]. 航空学报, 2021, 42(11): 524912.
|
|
ZHOU C, YAN X D, TANG S, et al. Midcourse guidance for endo-atmospheric interception based on model predictive static programming[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(11): 524912 (in Chinese).
|
| 17 |
YAMASAKI T, BALAKRISHNAN S N, TAKANO H. Geometrical approach-based defense-missile intercept guidance for aircraft protection against missile attack[J]. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2012, 226(8): 1014-1028.
|
| 18 |
张友安, 胡云安, 林涛. 导弹制导的鲁棒几何方法[J]. 控制理论与应用, 2003, 20(1): 13-16, 20.
|
|
ZHANG Y A, HU Y A, LIN T. Robust geometric approach to missile guidance[J]. Control Theory & Applications, 2003, 20(1): 13-16, 20 (in Chinese).
|
| 19 |
ZHANG P, FANG Y W, ZHANG F M, et al. An adaptive weighted differential game guidance law[J]. Chinese Journal of Aeronautics, 2012, 25(5): 739-746.
|
| 20 |
SURKOV P G. On the problem of package guidance for nonlinear control system via fuzzy approach[J]. IFAC-PapersOnLine, 2018, 51(32): 733-738.
|
| 21 |
RAJASEKHAR V, SREENATHA A G. Fuzzy logic implementation of proportional navigation guidance[J]. Acta Astronautica, 2000, 46(1): 17-24.
|
| 22 |
KIM M, HONG D, PARK S. Deep neural network-based guidance law using supervised learning[J]. Applied Sciences, 2020, 10(21): 7865.
|
| 23 |
SUTTON R S, BARTO A G. Reinforcement learning: An introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5): 1054.
|
| 24 |
BELLMAN R. Dynamic programming[J]. Science, 1966, 153(3731): 34-37.
|
| 25 |
SCHULMAN J. Optimizing expectations: From deep reinforcement learning to stochastic computation graphs[D]. Berkeley: University of California, Berkeley, 2016.
|
| 26 |
HE X J, CHEN Z H, JIA F, et al. Guidance law based on zero effort miss and Q-learning algorithm[C]∥ Seventh Symposium on Novel Photoelectronic Detection Technology and Applications. San Francisco: SPIE, 2021: 708-716.
|
| 27 |
陈治湘, 曹国辉. 基于微分对策的导弹神经网络制导律研究[J]. 地面防空武器, 2007(4): 13-17.
|
|
CHEN Z X, CAO G H. Research on neural network guidance law of missile based on differential game[J]. Land-Based Air Defence Weapons, 2007(4): 13-17 (in Chinese).
|
| 28 |
THEODORIDIS S. Machine learning [M]. Salt Lake City: Academic Press, 2020: 901-1038.
|
| 29 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[DB/OL]. arXiv preprint: 1312.5602, 2013.
|
| 30 |
LEI S, LEI Y L, ZHU Z. Research on missile intelligent penetration based on deep reinforcement learning[J]. Journal of Physics: Conference Series, 2020, 1616(1): 012107.
|
| 31 |
梁晨, 王卫红, 赖超. 带攻击角度约束的深度强化元学习制导律[J]. 宇航学报, 2021, 42(5): 611-620.
|
|
LIANG C, WANG W H, LAI C. Deep reinforcement meta-learning guidance with impact angle constraint[J]. Journal of Astronautics, 2021, 42(5): 611-620 (in Chinese).
|
| 32 |
GAUDET B, FURFARO R, LINARES R. Reinforcement learning for angle-only intercept guidance of maneuvering targets[J]. Aerospace Science and Technology, 2020, 99: 105746.
|
| 33 |
HUANG L W, FU M S, QU H, et al. A deep reinforcement learning-based method applied for solving multi-agent defense and attack problems[J]. Expert Systems With Applications, 2021, 176: 114896.
|
| 34 |
HE S M, SHIN H S, TSOURDOS A. Computational missile guidance: A deep reinforcement learning approach[J]. Journal of Aerospace Information Systems, 2021, 18(8): 571-582.
|
| 35 |
邱潇颀, 高长生, 荆武兴. 拦截大气层内机动目标的深度强化学习制导律[J]. 宇航学报, 2022, 43(5): 685-695.
|
|
QIU X Q, GAO C S, JING W X. Deep reinforcement learning guidance law for intercepting endo-atmospheric maneuvering targets[J]. Journal of Astronautics, 2022, 43(5): 685-695 (in Chinese).
|
| 36 |
SUTTON R S, BARTO A G. Reinforcement learning: An introduction[M]. Cambridge: MIT Press, 1998
|
| 37 |
SUTTON R S, MCALLESTER D, SINGH S, et al. Policy gradient methods for reinforcement learning with function approximation[C]∥ Proceedings of the 12th International Conference on Neural Information Processing Systems. New York: ACM, 1999: 1057–1063.
|
| 38 |
SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization[DB/OL]. arXiv preprint: 1502.05477, 2015.
|
| 39 |
BENGIO Y, SENECAL J S. Adaptive importance sampling to accelerate training of a neural probabilistic language model[J]. IEEE Transactions on Neural Networks, 2008, 19(4): 713-722.
|
| 40 |
KAKADE S, LANGFORD J. Approximately optimal approximate reinforcement learning[C]∥ International Conference on Machine Learning. New York: ACM, 2002: 267–274.
|
| 41 |
郭志强, 周绍磊, 于运治. 拦截机动目标的范数型协同微分对策制导律[J]. 计算机仿真, 2020, 37(3): 23-26.
|
|
GUO Z Q, ZHOU S L, YU Y Z. Research of cooperative norm differential games guidance law for intercepting a maneuvering target[J]. Computer Simulation, 2020, 37(3): 23-26 (in Chinese).
|
| 42 |
钱杏芳, 林瑞雄, 赵亚男. 导弹飞行力学[M]. 北京: 北京理工大学出版社, 2000.
|
|
QIAN X F, LIN R X, ZHAO Y N. Missile flight dynamics[M]. Beijing: Beijing Insititute of Technology Press, 2000 (in Chinese).
|
 ), 荆武兴
), 荆武兴