Acta Aeronautica et Astronautica Sinica ›› 2025, Vol. 46 ›› Issue (S1): 732184.doi: 10.7527/S1000-6893.2025.32184
• Excellent Papers of the 2nd Aerospace Frontiers Conference/the 27th Annual Meeting of the China Association for Science and Technology • Previous Articles
Tao ZHANG, Pan LI( ), Zixu WANG, Zhenhua ZHU
), Zixu WANG, Zhenhua ZHU
Received:2025-02-25
Revised:2025-03-08
Accepted:2025-05-06
Online:2025-05-29
Published:2025-05-27
Contact:
Pan LI
E-mail:lipan@nuaa.edu.cn
Supported by:CLC Number:
Tao ZHANG, Pan LI, Zixu WANG, Zhenhua ZHU. Design of reward functions for helicopter attitude control in reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(S1): 732184.
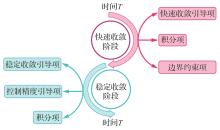
Fig.1
Reward function architecture of attitude control
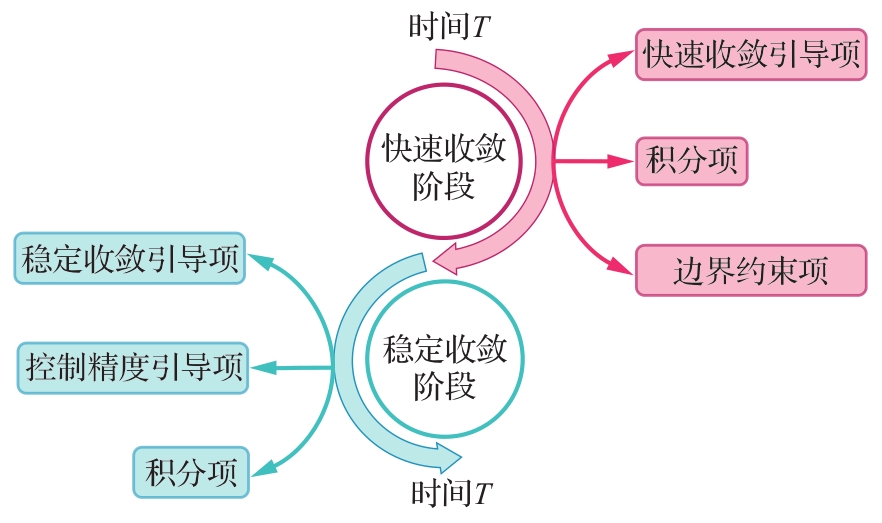
Fig.2
Overview of reinforcement learning training framework
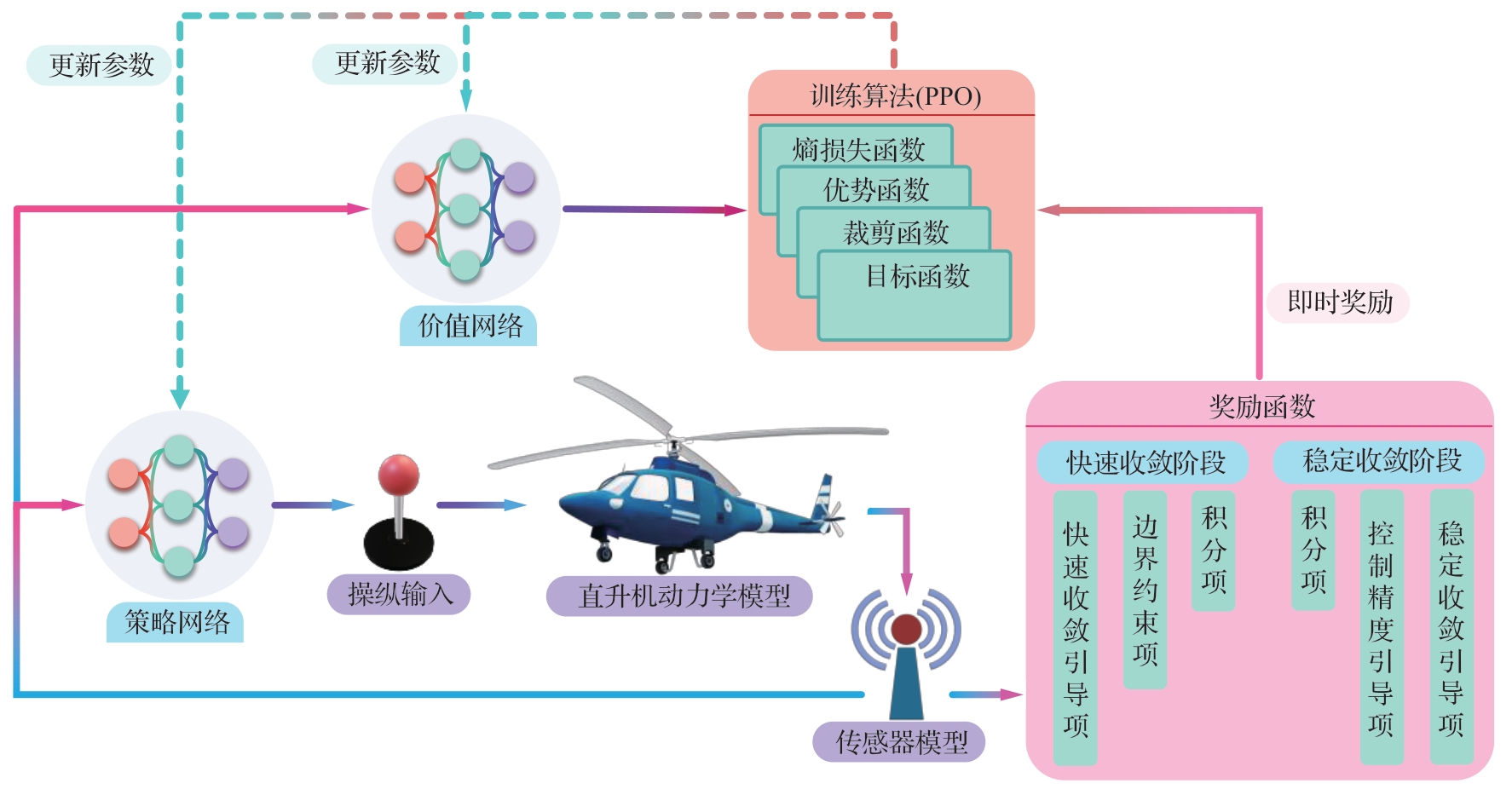
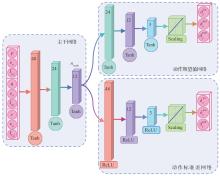
Fig.3
Topology of policy network
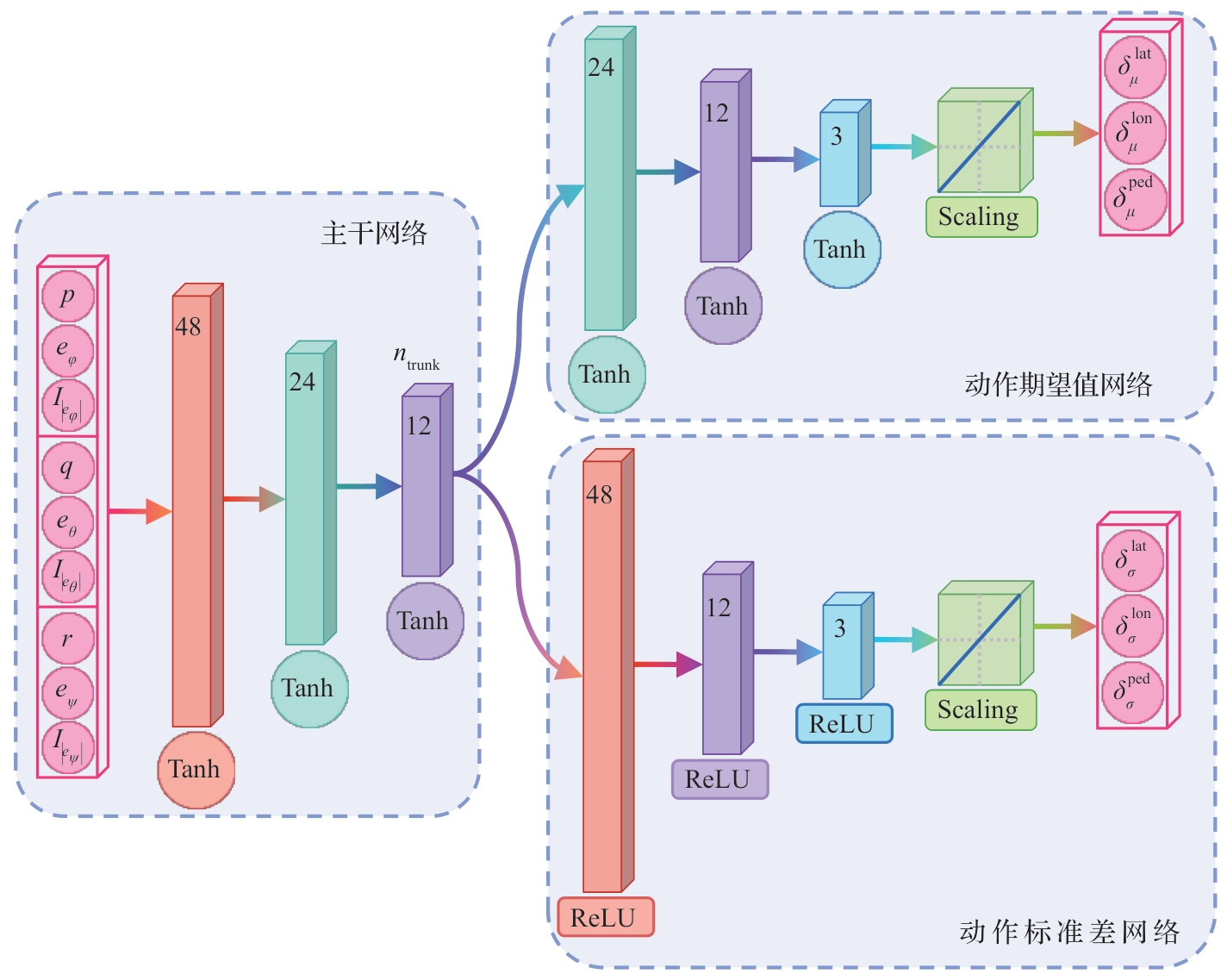
Fig.4
Topology of value network
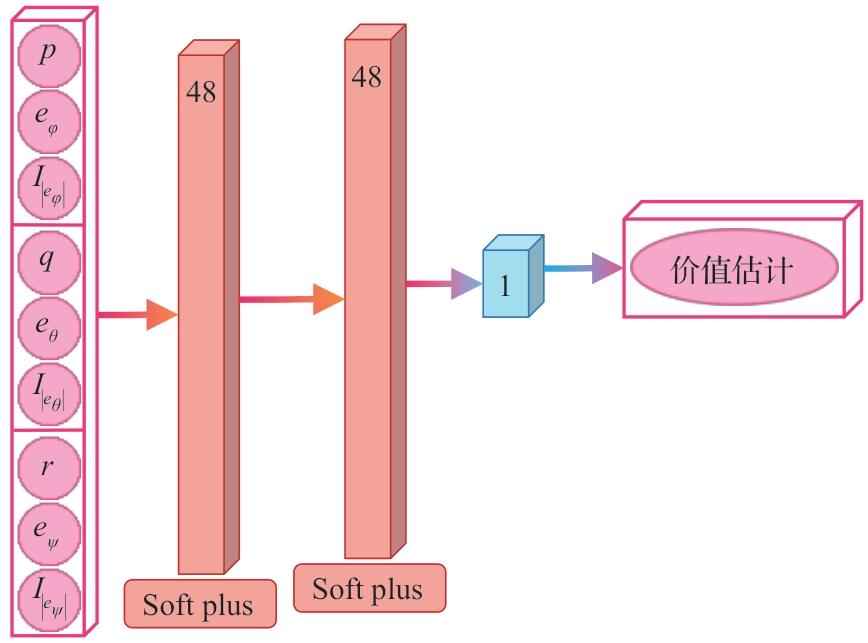

Fig.5
Comparison of trim results between the model and test flight data
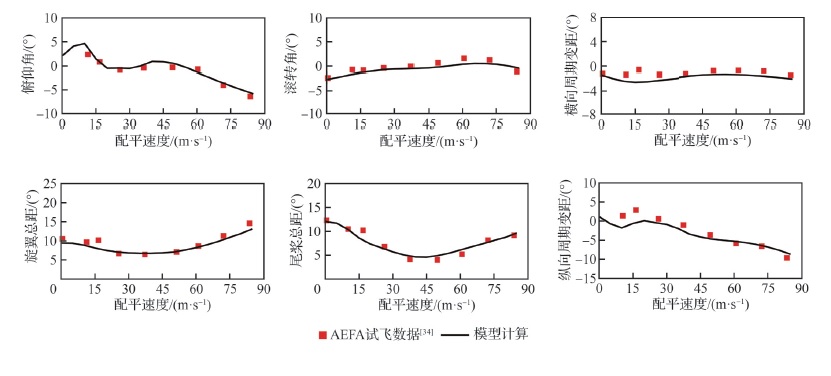

Fig.6
Comparison of maneuvering response results between model and test flight data
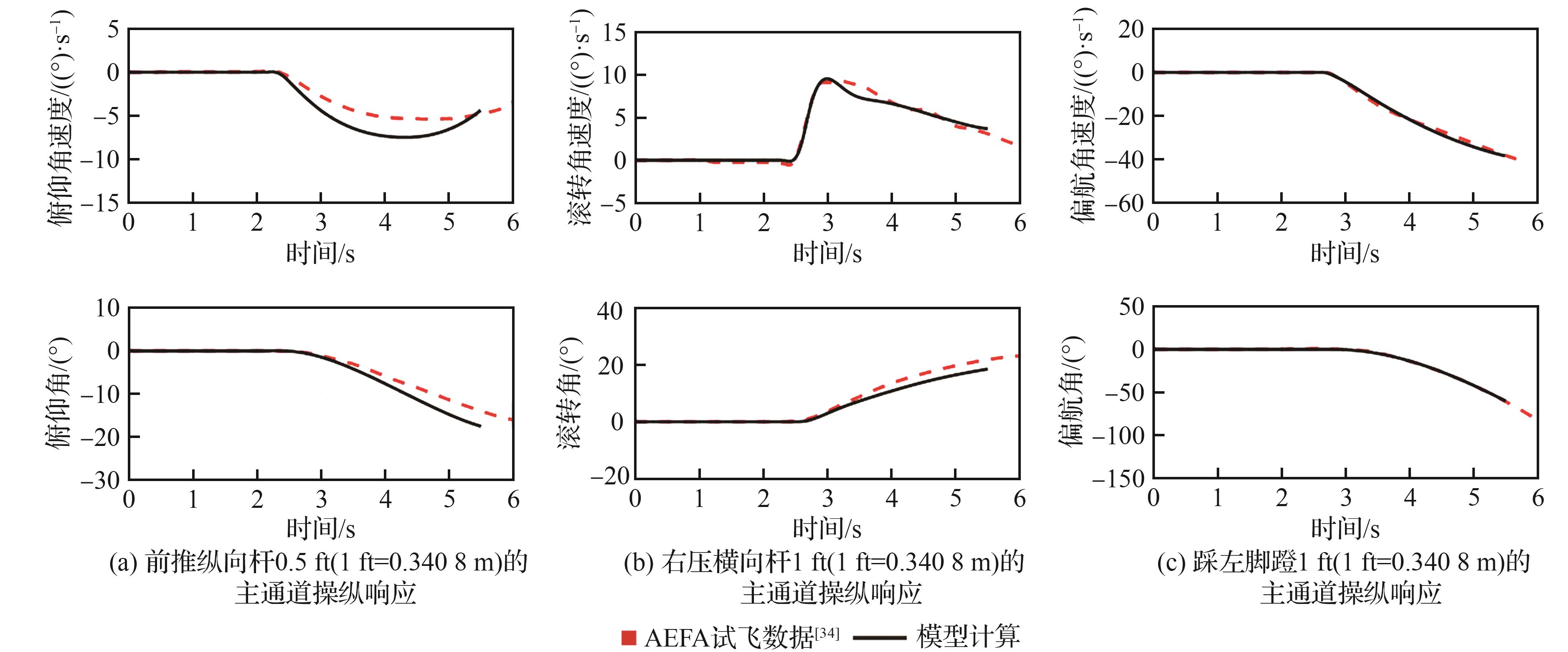
Table 1
Summary of reward function hyperparameters
| 阶段 | 参数名称 | 数值 |
|---|---|---|
| 全过程 | 0.5 | |
| 0.2 | ||
| 快速收敛 | 0.2 | |
| 10 | ||
| 0.7 | ||
| 0.2 | ||
| 0.2 | ||
| 稳定收敛 | 0.2 | |
| 2 | ||
| 0.2 | ||
| 0.2 |
Table 2
Hyperparameters of PPO algorithm
| 超参数 | 本文设置 | 基准研究[ |
|---|---|---|
| 折扣因子 | 0.99 | 0.99 |
| 裁剪系数 | 0.2 | 0.2~0.3 |
| 熵损失权重 | 0.02 | 无需熵正则化 |
| 策略网络动作标准差缩放系数 | 0.6 | 0.5 |
| 广义优势估计器平滑因子 | 0.9 | 0.9 |
| Actor网络学习率 | 6×10-4 | 3×10-4 |
| Critic网络学习率 | 6×10-3 | 3×10-4 |
| 优化器 | Adam优化器 | Adam优化器 |
Fig.7
Change curve of reward value with the number of training episodes
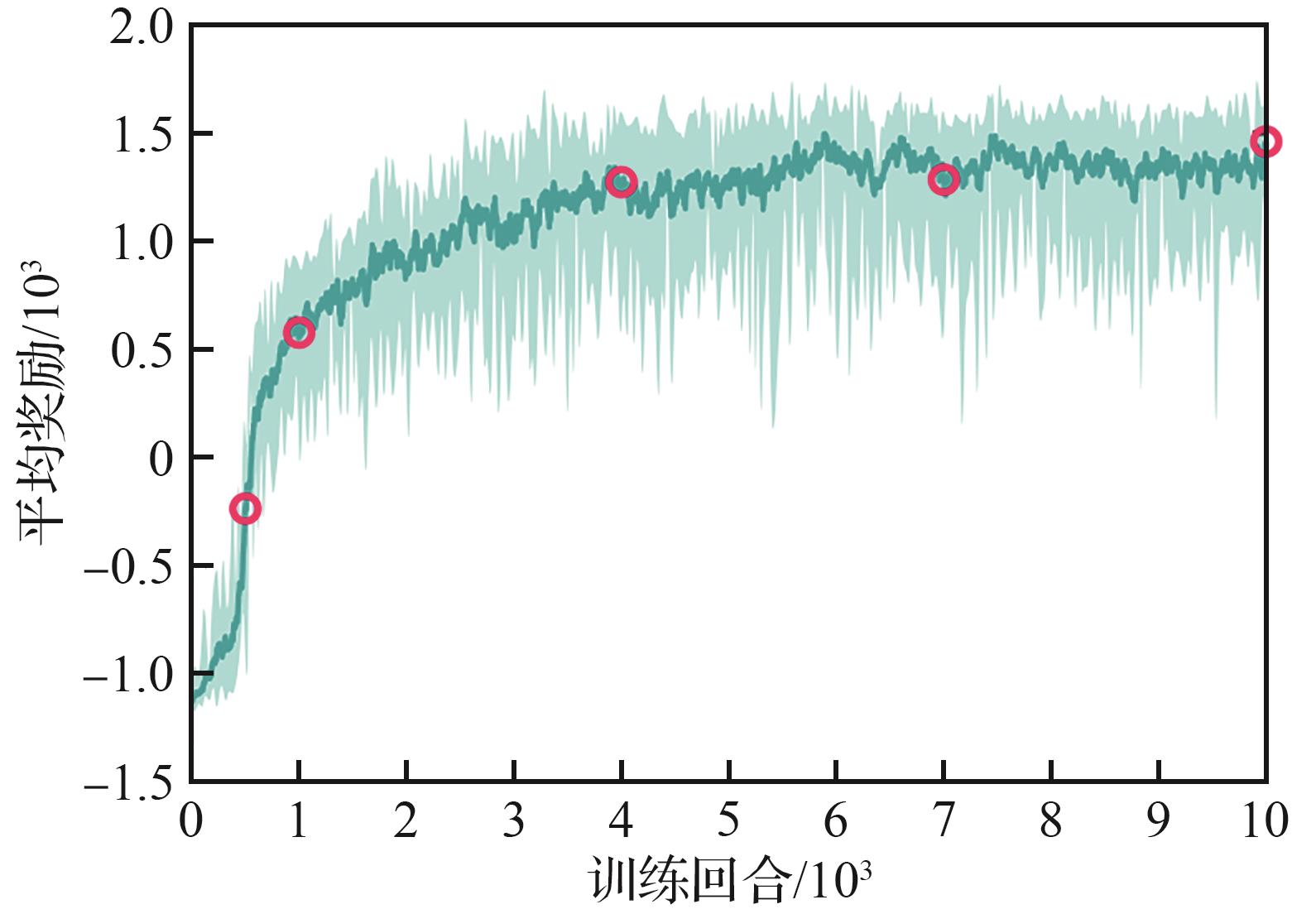
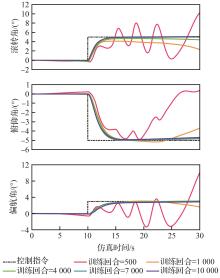
Fig.8
Performance comparison of agents in different training episodes
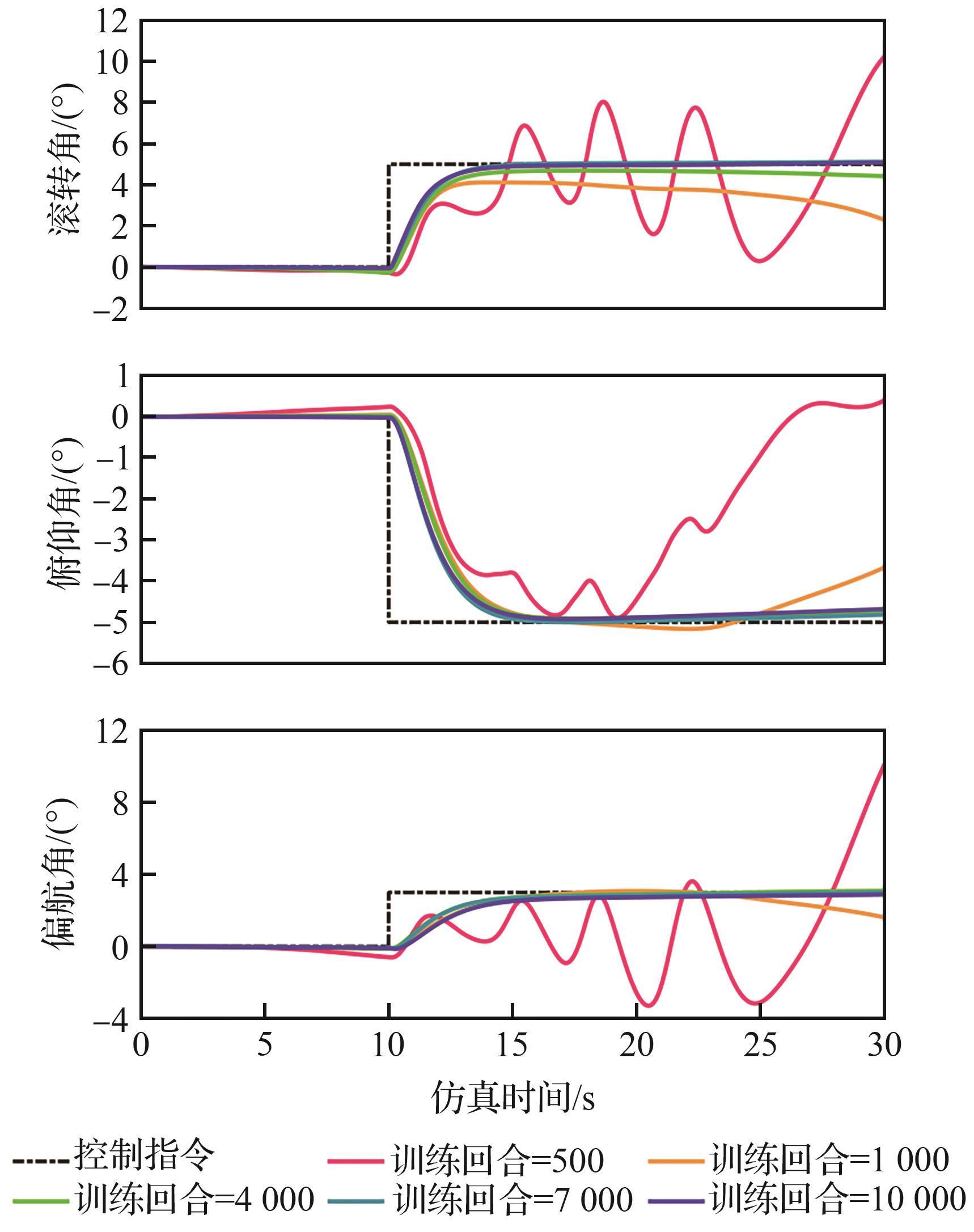
Fig.9
Step response of the system
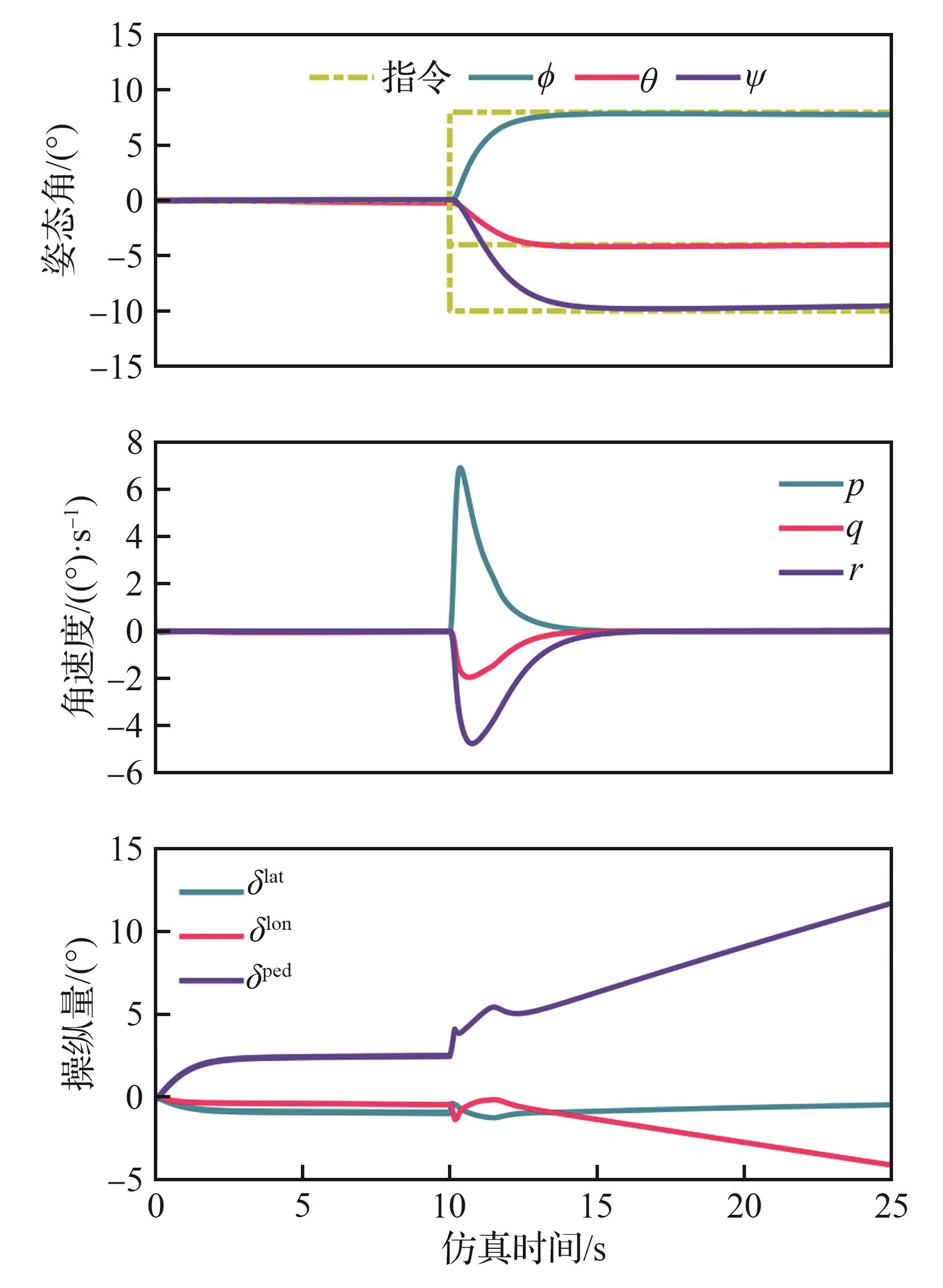
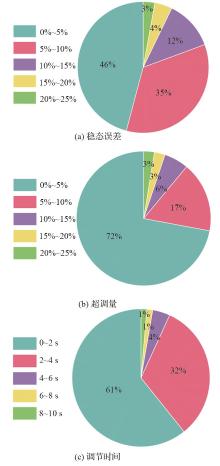
Fig.10
Statistics of system time-domain performance indices
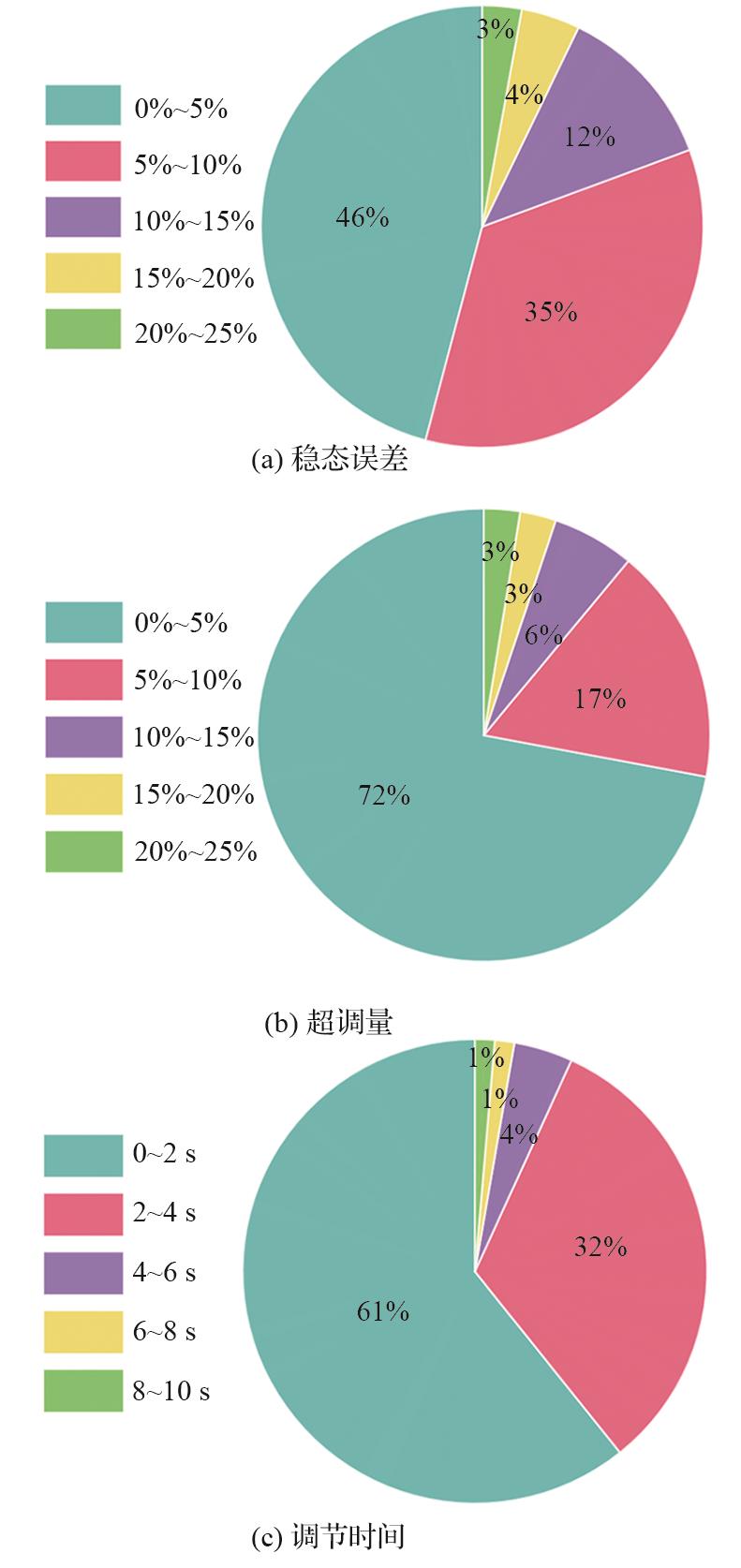
Table 3
Error value of angular velocity sensor
| 误差参数 | 误差值 |
|---|---|
| 0.2° | |
| 300 ×10-6 | |
| 30 (°)/h | |
| 1 (°)/ |
Fig.11
System step response considering sensor errors
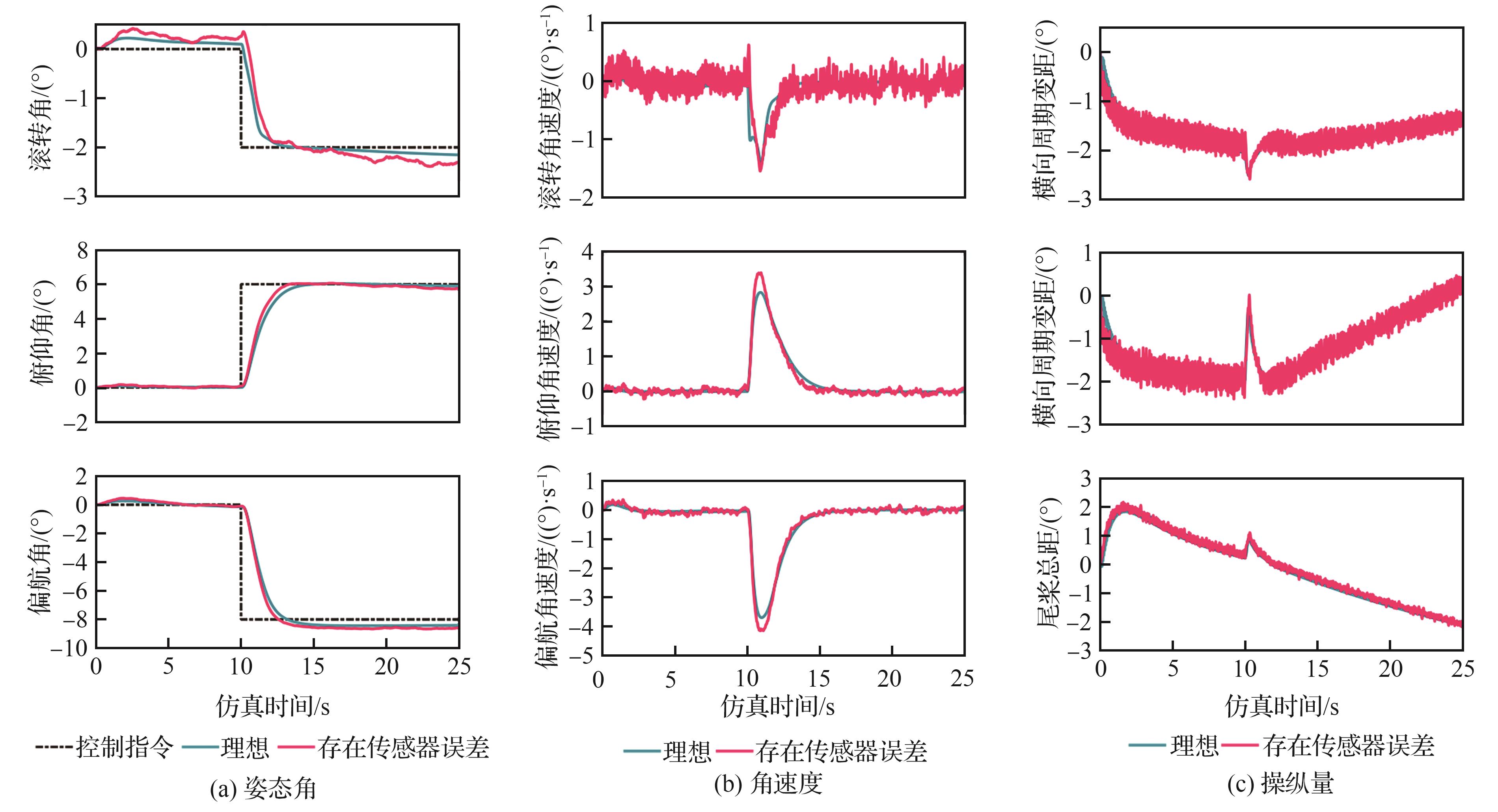
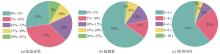
Fig.12
System time-domain performance index statistics considering sensor errors
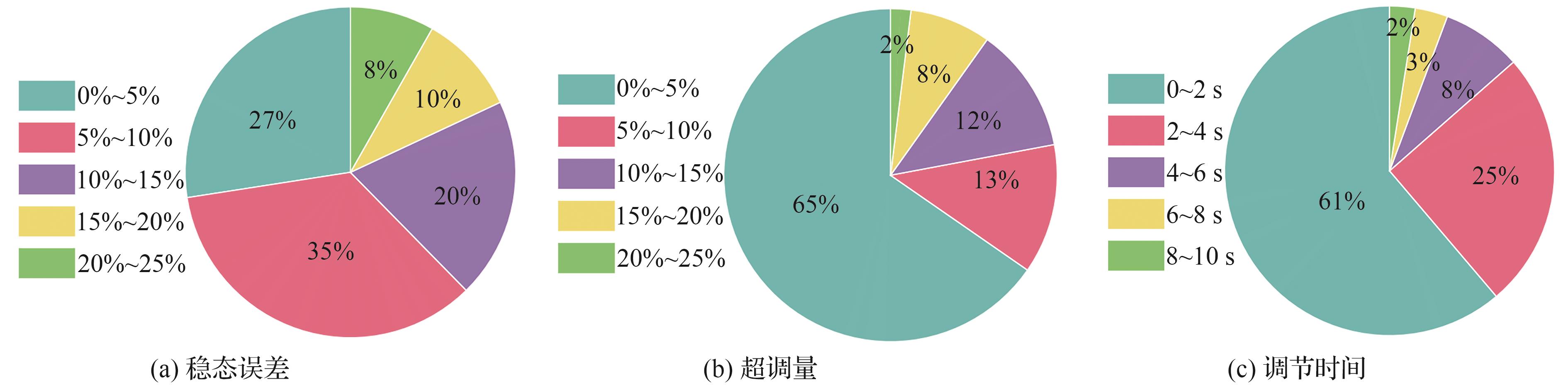
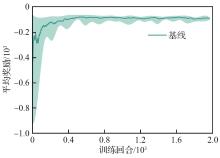
Fig.13
Training process curves under baseline reward function
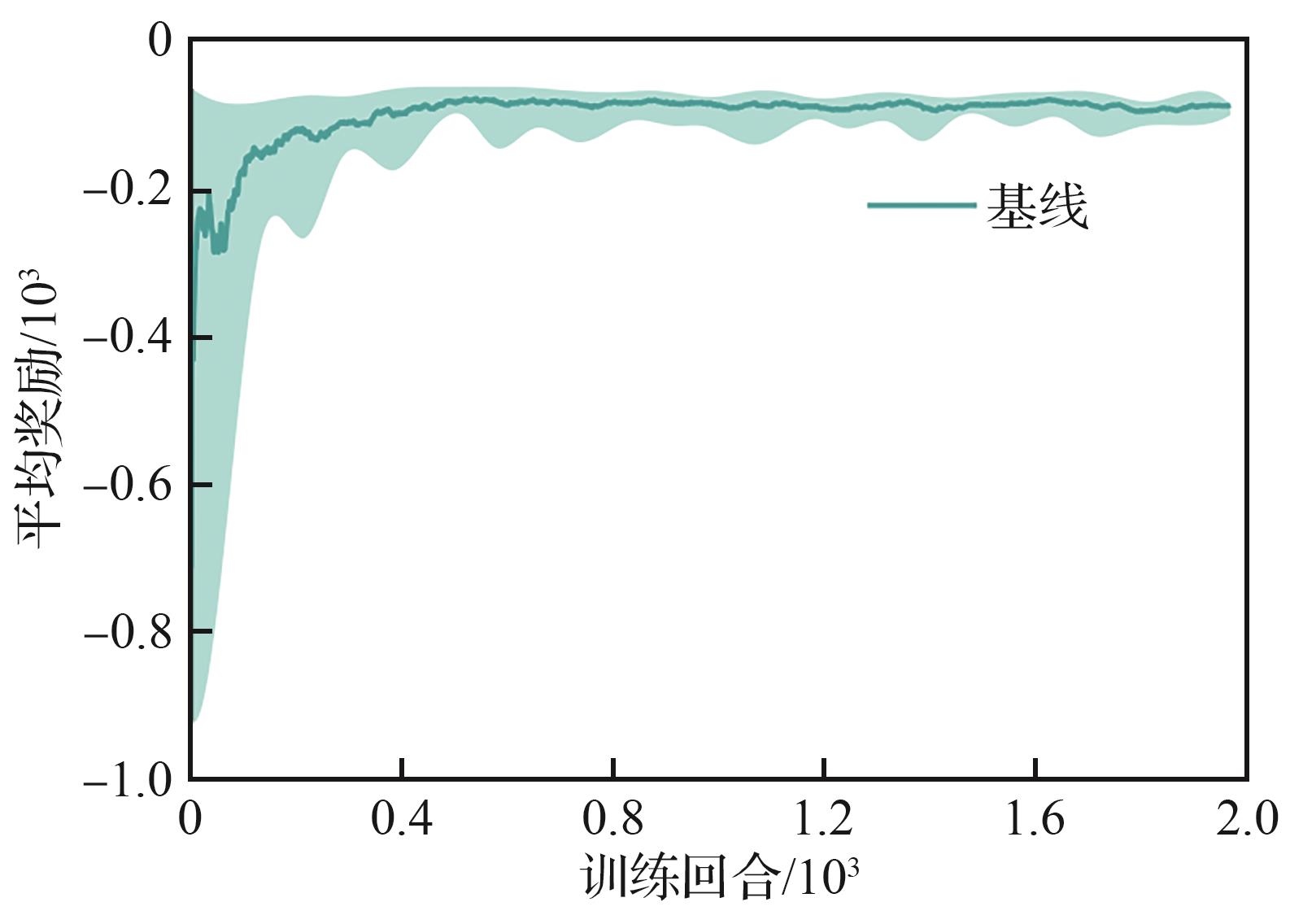
Fig.14
Step response test of agents under different reward functions
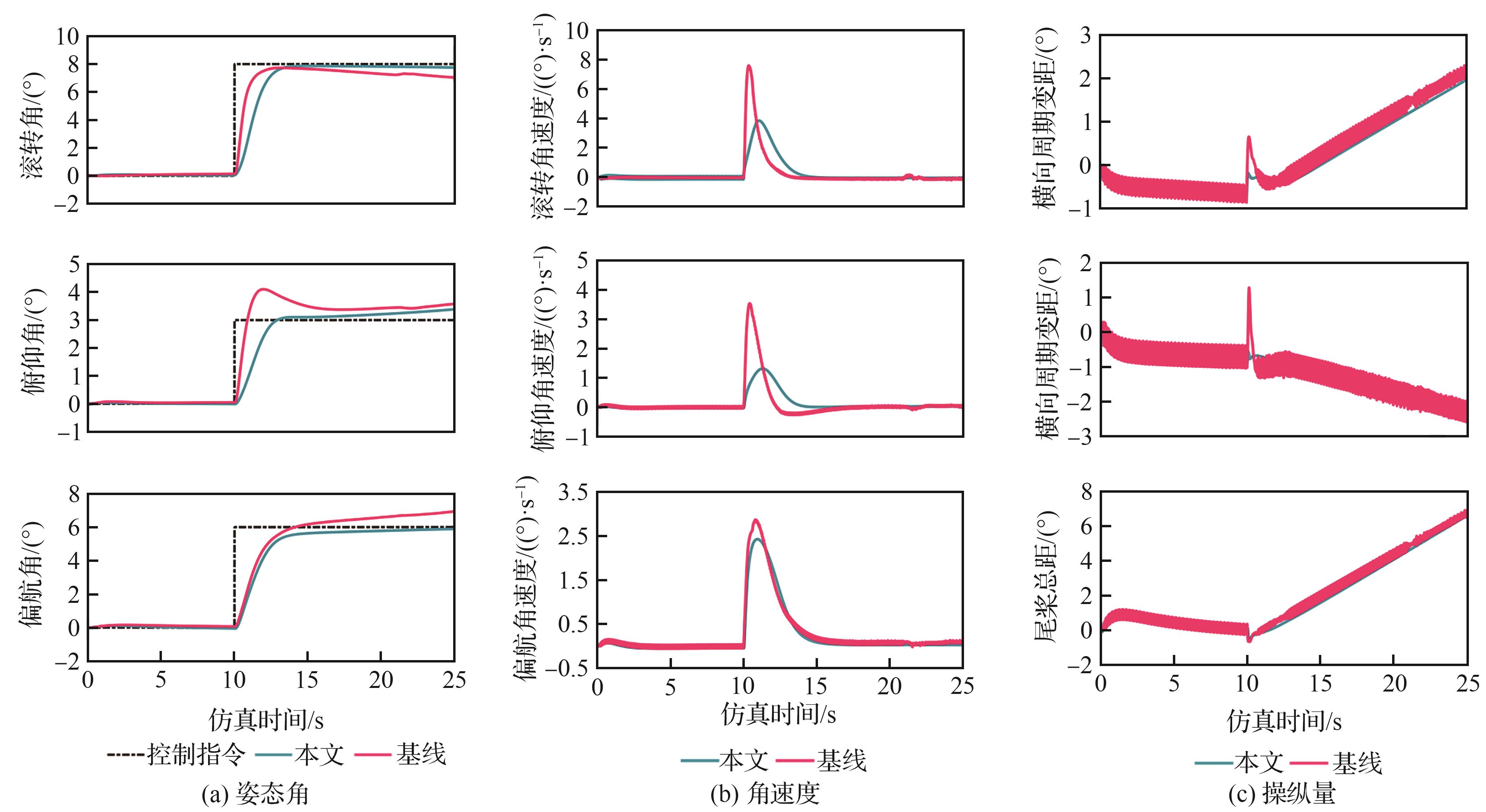
Table 4
Comparison of agent control performance under different reward functions
| 控制性能指标 | 本文方法 | 基线方法 |
|---|---|---|
| 稳态误差≤10% | 占比81% | 占比65% |
| 超调量≤10% | 占比89% | 占比80% |
| 调节时间≤4 s | 占比93% | 占比86% |
| 仿真发散 | 占比0% | 占比2% |
| [1] | 高正, 陈仁良. 直升机飞行动力学[M]. 北京: 科学出版社, 2003: 1-232. |
| GAO Z, CHEN R L. Helicopter flight dynamics[M]. Beijing: Science Press, 2003: 1-232 (in Chinese). | |
| [2] | 陈仁良, 李攀, 吴伟, 等. 直升机飞行动力学数学建模问题[J]. 航空学报, 2017, 38(7): 520915. |
| CHEN R L, LI P, WU W, et al. A review of mathematical modeling of helicopter flight dynamics[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(7): 520915 (in Chinese). | |
| [3] | 李攀. 旋翼非定常自由尾迹及高置信度直升机飞行力学建模研究[D]. 南京: 南京航空航天大学, 2010: 1-169. |
| LI P. Research on unsteady free wake of rotor and high confidence helicopter flight mechanics modeling[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2010: 1-169 (in Chinese). | |
| [4] | BALAS G J, PACKARD A K, RENFROW J, et al. Control of the F-14 aircraft lateral-directional axis during powered approach[J]. Journal of Guidance, Control, and Dynamics, 1998, 21(6): 899-908. |
| [5] | 郑峰婴, 沈志敏, 李雅琴, 等. 共轴高速直升机增益自适应多模式切换控制[J]. 航空学报, 2024, 45(9): 529088. |
| ZHENG F Y, SHEN Z M, LI Y Q, et al. Gain adaptive multi-mode switching control for coaxial high-speed helicopter[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(9): 529088 (in Chinese). | |
| [6] | CATAK A, ALTUNKAYA E C, DEMIR M, et al. Enhanced flight envelope protection: A novel reinforcement learning approach[J]. IFAC-PapersOnLine, 2024, 58(30): 207-212. |
| [7] | WISE K A. Design parameter tuning in adaptive observer-based flight control architectures[C]∥2018 AIAA Information Systems-AIAA Infotech @ Aerospace. Reston: AIAA, 2018. |
| [8] | 仇钰清, 李俨, 郎金溪, 等. 高速直升机过渡模态鲁棒自适应姿态控制[J]. 航空学报, 2024, 45(9): 529927. |
| QIU Y Q, LI Y, LANG J X, et al. Robust adaptive attitude control of high-speed helicopters in transition mode[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(9): 529927 (in Chinese). | |
| [9] | LAKE B M, BARONI M. Human-like systematic generalization through a meta-learning neural network[J]. Nature, 2023, 623(7985): 115-121. |
| [10] | SUTTON R S, BARTO A G. Reinforcement learning: An introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5): 1054. |
| [11] | SÖNMEZ S, RUTHERFORD M J, VALAVANIS K P. A survey of offline-and online-learning-based algorithms for multirotor UAVs [J]. Drones, 2024, 8(4): 116. |
| [12] | RICHTER D J, CALIX R A, KIM K. A review of reinforcement learning for fixed-wing aircraft control tasks[J]. IEEE Access, 2024, 12: 103026-103048. |
| [13] | SHADEED O, HASANZADE M, KOYUNCU E. Deep reinforcement learning based aggressive flight trajectory tracker[C]∥AIAA Scitech 2021 Forum. Reston: AIAA, 2021. |
| [14] | MANUKYAN A, OLIVARES-MENDEZ M A, GEIST M, et al. Deep reinforcement learning-based continuous control for multicopter systems[C]∥2019 6th International Conference on Control, Decision and Information Technologies (CoDIT). Piscataway: IEEE Press, 2019: 1876-1881. |
| [15] | HWANGBO J, SA I, SIEGWART R, et al. Control of a quadrotor with reinforcement learning[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 2096-2103. |
| [16] | KOCH W, MANCUSO R, WEST R, et al. Reinforcement learning for UAV attitude control[J]. ACM Transactions on Cyber-Physical Systems, 2019, 3(2): 1-21. |
| [17] | XU J, DU T, FOSHEY M, et al. Learning to fly: Computational controller design for hybrid UAVs with reinforcement learning[J]. ACM Transactions on Graphics, 2019, 38(4): 1-12. |
| [18] | CANO LOPES G, FERREIRA M, SILVA SIMÕES A DA, et al. Intelligent control of a quadrotor with proximal policy optimization reinforcement learning[C]∥2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE). Piscataway: IEEE Press, 2018: 503-508. |
| [19] | MOLCHANOV A, CHEN T, HÖNIG W, et al. Sim-to-(multi)-real: Transfer of low-level robust control policies to multiple quadrotors[C]∥2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2019: 59-66. |
| [20] | LI Z, XUE S R, LIN W Y, et al. Training a robust reinforcement learning controller for the uncertain system based on policy gradient method[J]. Neurocomputing, 2018, 316: 313-321. |
| [21] | ZHEN Y, HAO M R, SUN W D. Deep reinforcement learning attitude control of fixed-wing UAVs[C]∥2020 3rd International Conference on Unmanned Systems (ICUS). Piscataway: IEEE Press, 2020: 239-244. |
| [22] | BEKAR C, YUKSEK B, INALHAN G. High fidelity progressive reinforcement learning for agile maneuvering UAVs[C]∥AIAA Scitech 2020 Forum. Reston: AIAA, 2020. |
| [23] | KIM J, JUNG S. Enhancing UAV stability: A deep reinforcement learning strategy[C]∥2024 International Conference on Electronics, Information, and Communication (ICEIC). Piscataway: IEEE Press, 2024: 1-4. |
| [24] | AOUN C, MONCAYO H. Disturbance observer-based reinforcement learning control and the application to a nonlinear dynamic system[C]∥AIAA Scitech 2020 Forum. Reston: AIAA, 2022. |
| [25] | WANG Y D, SUN J, HE H B, et al. Deterministic policy gradient with integral compensator for robust quadrotor control[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(10): 3713-3725. |
| [26] | AKHTAR M, MAQSOOD A. Comparative analysis of deep reinforcement learning algorithms for hover-to-cruise transition maneuvers of a tilt-rotor unmanned aerial vehicle[J]. Aerospace, 2024, 11(12): 1040-1042. |
| [27] | PUTERMAN M L. Markov decision processes[M]∥Handbooks in Operations Research and Management Science. New York: Springer Science+Business Media, 1990, 2: 331-434. |
| [28] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. ArXiv preprint: 1707. 06347, 2017. |
| [29] | SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation[DB/OL]. ArXiv preprint: 1506. 02438, 2015. |
| [30] | GRONDMAN I, BUSONIU L, LOPES G A D, et al. A survey of actor-critic reinforcement learning: Standard and natural policy gradients[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2012, 42(6): 1291-1307. |
| [31] | BORISOV A, MAMAEV I S. Rigid body dynamics[M]. New York: Springer Science+Business Media, 2018: 1-271. |
| [32] | LI P, CHEN R L. A mathematical model for helicopter comprehensive analysis[J]. Chinese Journal of Aeronautics, 2010, 23(3): 320-326. |
| [33] | PITT D M, PETERS D A. Theoretical prediction of dynamic inflow derivatives[J]. Vertica, 1981, 5(1): 21-34. |
| [34] | BALLIN M G. Validation of a real-time engineering simulation of the UH-60A helicopter: NASA-TM-88360 [R]. Washington, D.C.: NASA, 1987. |
| [35] | ANDRYCHOWICZ M, RAICHUK A, STAŃCZYK P, et al. What matters for on-policy deep actor-critic methods? A large-scale study[C]∥International Conference on Learning Representations: OpenReview. 2021: 1-10. |
| [36] | WU Y F, ZHANG W, XU P, et al. A finite-time analysis of two time-scale actor-critic methods[J]. Advances in Neural Information Processing Systems, 2020, 33: 17617-17628. |
| [37] | WELCER M, SZCZEPAŃSKI C, KRAWCZYK M. The impact of sensor errors on flight stability[J]. Aerospace, 2022, 9(3): 169. |
| [38] | TRIPATHI S, WAGH P, CHAUDHARY A B. Modelling, simulation & sensitivity analysis of various types of sensor errors and its impact on tactical flight vehicle navigation[C]∥2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT). Piscataway: IEEE Press, 2016: 938-942. |
| [39] | ZHENG T, XU A G, XU X C, et al. Modeling and compensation of inertial sensor errors in measurement systems[J]. Electronics, 2023, 12(11): 2458. |
| [1] | Kaifang WAN, Zhilin WU, Yunhui WU, Haozhi QIANG, Yibo WU, Bo LI. Cooperative location of multiple UAVs with deep reinforcement learning in GPS-denied environment [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331024-331024. |
| [2] | Lingfeng JIANG, Xinkai LI, Hai ZHANG, Hanwei LI, Hongli ZHANG. Mapless navigation of UAVs in dynamic environments based on an improved TD3 algorithm [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(8): 331035-331035. |
| [3] | Mou CHEN, Zhengguo HUANG, Yaohua SHEN, Fan LIU. Overview of composite anti-disturbance control technology of advanced vehicles [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(6): 531303-531303. |
| [4] | Min YANG, Guanjun LIU, Ziyuan ZHOU. Control of lunar landers based on secure reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(3): 630553-630553. |
| [5] | Jiakun FAN, Junqiang AI, Ningjuan DONG, Jiakuan XU, Lei QIAO, Junqiang BAI. Stationary crossflow induced transition prediction method for supersonic swept-wing based on convolutional neural networks [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(20): 532012-532012. |
| [6] | Yugang ZHANG, Zhe YANG, Senpeng HE, Wenqing YANG. Aircraft attitude prediction model based on physical information neural networks [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(19): 531850-531850. |
| [7] | Chen WANG, Caisheng WEI, Zeyang YIN, Kai JIN, Xingchen LI. Collaborative planning of multi-UAV trajectories and communication strategies considering channel resource constraints [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(18): 331837-331837. |
| [8] | Yizhe LUO, Hui ZHANG, Xinde YU, Zhao JIN, Shuo FENG, Yucheng SHI, Mingling XU. Hierarchical dynamic scheduling for multi-wave carrier-based aircraft ammunition support missions [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(18): 331945-331945. |
| [9] | Xiangsong HUANG, Mengyu WANG, Dapeng PAN. Adversarial reinforcement learning-based UAV escape path planning method [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(17): 331637-331637. |
| [10] | Yu WANG, Zhipeng XIE, Yongjian TIAN, Guanglei MENG. Distributed UAV formation control with virtual structure guided reinforcement learning [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(15): 331354-331354. |
| [11] | Wei CHEN, Lulu LI, Dong CHEN, Shaohui ZHANG, Yafei LI, Ke WANG, Yuanyuan JIN, Mingliang XU. Multi-aircraft cooperative decision-making methods driven by differentiated support demands for carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531274-531274. |
| [12] | Xudong CHEN, Qiqi CHEN, Yizhe LUO, Jiabao WANG, Mingliang XU. Dynamic parallel scheduling of heterogeneous carrier-based aircraft deck support operations [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531329-531329. |
| [13] | Ming YAN, Jiaxing WANG, Heqi LI, Kai LIU. Active disturbance rejection control of carrier-based aircraft based on offline network/online identification [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531317-531317. |
| [14] | Zheng WANG, Hua WANG, Keke CUI, Chaochao LI, Junnan LIU, Mingliang XU. Locally guided reinforcement learning for autonomous dispatching of carrier-based aircraft [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531333-531333. |
| [15] | Wenhui LING, Chunhui MU, Lingcong NIE, Xian DU, Ximing SUN. Improved DDPG-based multipoint pressure distribution control of variable geometry scramjet combustor at wide range velocities [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(12): 131092-131092. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341