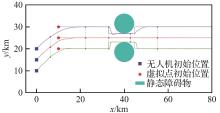
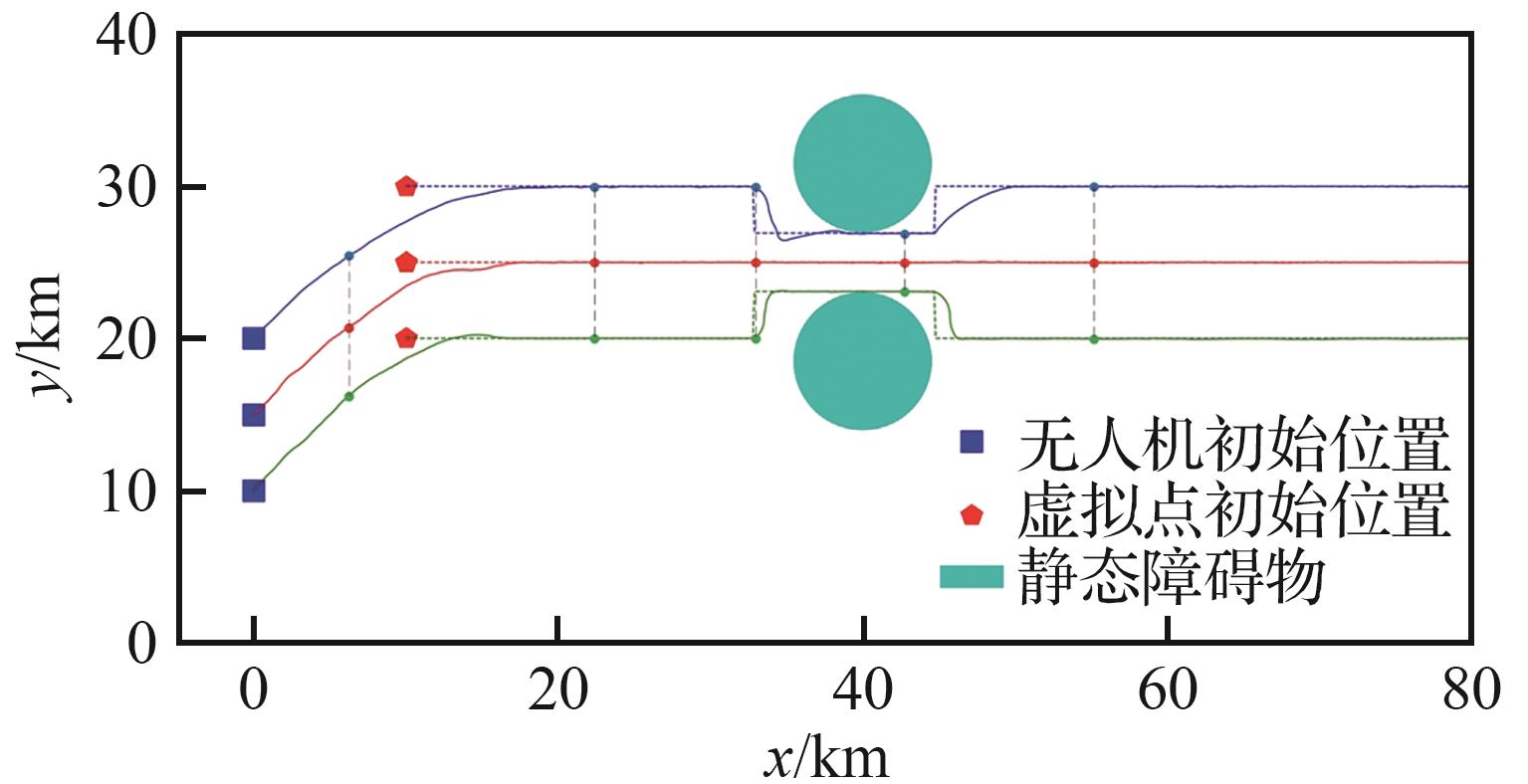
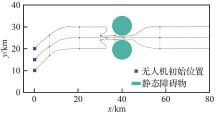
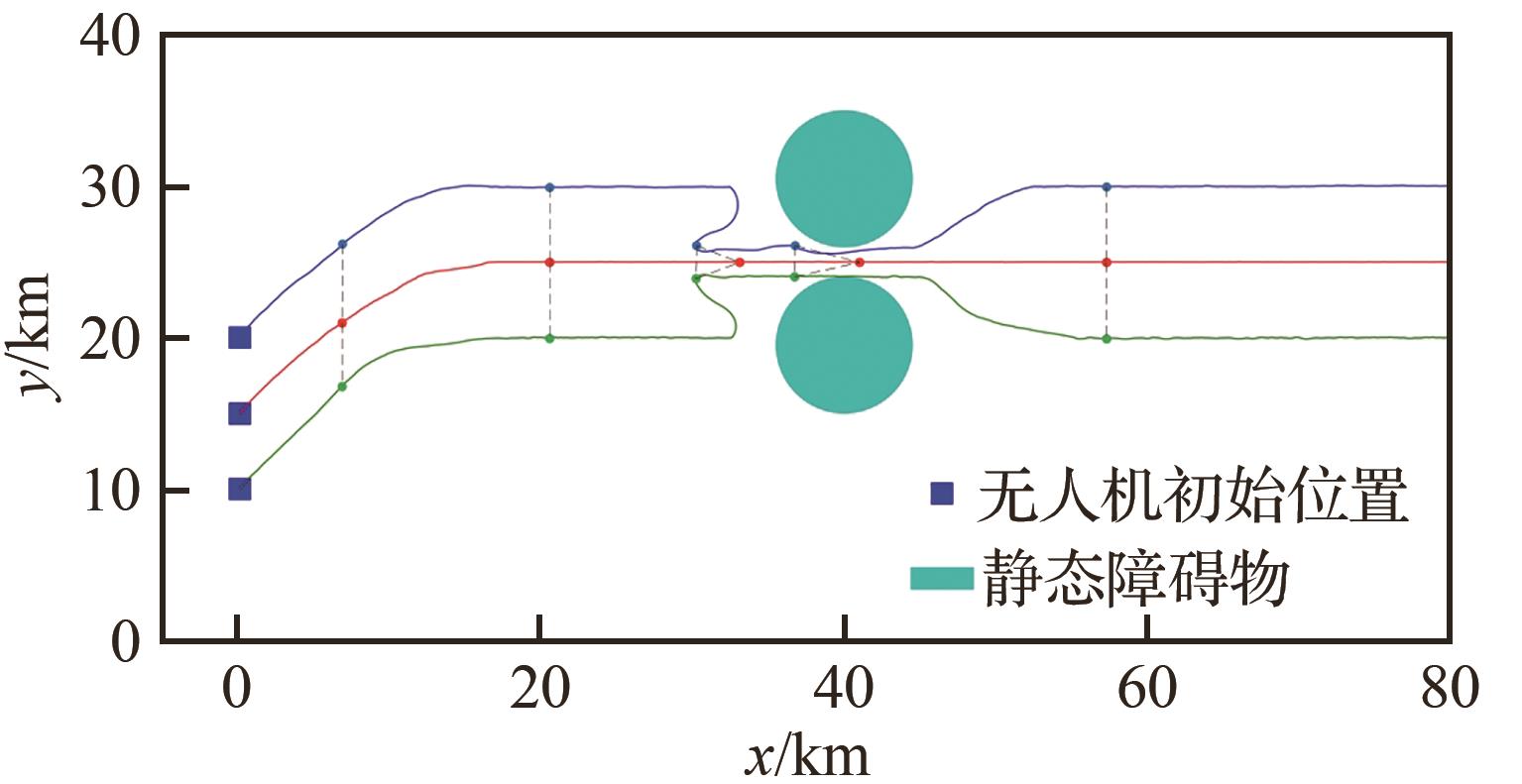
| [1] |
王琳, 张庆杰, 陈宏伟. 基于领航者跟随者的群系统保性能编队控制[J]. 北京航空航天大学学报, 2024, 50(3): 1037-1046.
|
|
WANG L, ZHANG Q J, CHEN H W. Guaranteed-performance formation control of swarm systems based on leader-follower strategy[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(3): 1037-1046 (in Chinese).
|
| [2] |
彭建帅, 付兴建. 仿雁群行为的领航-跟随无人机编队控制[J]. 控制工程, 2023, 30(1): 113-118.
|
|
PENG J S, FU X J. Formation control of leader-follower UAV based on the behavior of geese swarm[J]. Control Engineering of China, 2023, 30(1): 113-118 (in Chinese).
|
| [3] |
吴立尧, 韩维, 张勇, 等. 基于领航-跟随的有人/无人机编队队形保持控制[J]. 控制与决策, 2021, 36(10): 2435-2441.
|
|
WU L Y, HAN W, ZHANG Y, et al. Formation keeping control for manned/unmanned aerial vehicle formation based on leader-follower strategy[J]. Control and Decision, 2021, 36(10): 2435-2441 (in Chinese).
|
| [4] |
李正平, 鲜斌. 基于虚拟结构法的分布式多无人机鲁棒编队控制[J]. 控制理论与应用, 2020, 37(11): 2423-2431.
|
|
LI Z P, XIAN B. Robust distributed formation control of multiple unmanned aerial vehicles based on virtual structure[J]. Control Theory & Applications, 2020, 37(11): 2423-2431 (in Chinese).
|
| [5] |
黄勇, 李小将, 杨业伟, 等. 应用虚拟结构的卫星编队飞行自适应协同控制[J]. 中国空间科学技术, 2015, 35(3): 75-83.
|
|
HUANG Y, LI X J, YANG Y W, et al. Adaptive cooperative control for satellites formation flying using virtual structure[J]. Chinese Space Science and Technology, 2015, 35(3): 75-83 (in Chinese).
|
| [6] |
GUO J D, LIU Z G, SONG Y G, et al. Research on multi-UAV formation and semi-physical simulation with virtual structure[J]. IEEE Access, 2023, 11: 126027-126039.
|
| [7] |
LIU Y P, CHEN C, WANG Y, et al. A fast formation obstacle avoidance algorithm for clustered UAVs based on artificial potential field[J]. Aerospace Science and Technology, 2024, 147: 108974.
|
| [8] |
高运克, 唐宏伟, 高方坤, 等. 无线紫外光通信下基于改进人工势场法的无人机编队控制研究[J]. 电气传动自动化, 2023, 45(6): 6-12, 5.
|
|
GAO Y K, TANG H W, GAO F K, et al. Research on UAV formation control based on improved artificial potential field method[J]. Electric Drive Automation, 2023, 45(6): 6-12, 5 (in Chinese).
|
| [9] |
陈博琛, 唐文兵, 黄鸿云, 等. 基于改进人工势场的未知障碍物无人机编队避障[J]. 计算机科学, 2022, 49(S1): 686-693.
|
|
CHEN B C, TANG W B, HUANG H Y, et al. Pop-up obstacles avoidance for UAV formation based on improved artificial potential field[J]. Computer Science, 2022, 49(S1): 686-693 (in Chinese).
|
| [10] |
葛宇, 廖煜雷, 王博, 等. 基于零空间行为融合的多智能体编队控制综述[J]. 哈尔滨工程大学学报, 2024, 45(8): 1442-1450.
|
|
GE Y, LIAO Y L, WANG B, et al. A review of multiagent formation control based on the null-space-based behavioral fusion algorithm[J]. Journal of Harbin Engineering University, 2024, 45(8): 1442-1450 (in Chinese).
|
| [11] |
TAN G G, ZHUANG J Y, ZOU J, et al. Coordination control for multiple unmanned surface vehicles using hybrid behavior-based method[J]. Ocean Engineering, 2021, 232: 109147.
|
| [12] |
HACENE N, MENDIL B. Behavior-based autonomous navigation and formation control of mobile robots in unknown cluttered dynamic environments with dynamic target tracking[J]. International Journal of Automation and Computing, 2021, 18(5): 766-786.
|
| [13] |
GUO M, JAYAWARDHANA B, LEE J, et al. Maintaining and steering a formation in an unknown dynamic environment via a consistent distributed dynamic map[J]. International Journal of Robust and Nonlinear Control, 2024, 34(13): 8785-8801.
|
| [14] |
PEI H Q, LAN Z Y. Multi-agent consistent formation control operation optimization for high-speed trains[J]. IEEE Access, 2023, 11: 139201-139210.
|
| [15] |
LIU W J, LYU S K, LIU T, et al. Multi-target optimization strategy for unmanned aerial vehicle formation in forest fire monitoring based on deep Q-network algorithm[J]. Drones, 2024, 8(5): 201.
|
| [16] |
赵启, 甄子洋, 龚华军, 等. 基于D3QN的无人机编队控制技术[J]. 北京航空航天大学学报, 2023, 49(8): 2137-2146.
|
|
ZHAO Q, ZHEN Z Y, GONG H J, et al. UAV formation control based on dueling double DQN[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(8): 2137-2146 (in Chinese).
|
| [17] |
黄号, 马文卉, 李家诚, 等. 未知环境下无人机编队智能避障控制方法[J]. 清华大学学报(自然科学版), 2024, 64(2): 358-369.
|
|
HUANG H, MA W H, LI J C, et al. Intelligent obstacle avoidance control method for unmanned aerial vehicle formations in unknown environments[J]. Journal of Tsinghua University (Science and Technology), 2024, 64(2): 358-369 (in Chinese).
|
| [18] |
XU D, GUO Y X, YU Z Y, et al. PPO-exp: Keeping fixed-wing UAV formation with deep reinforcement learning[J]. Drones, 2023, 7(1): 28.
|
| [19] |
LI Y D, YUAN Y L, CHENG Y, et al. Predictive air combat decision model with segmented reward allocation[J]. Complex & Intelligent Systems, 2024, 10(6): 7513-7530.
|
| [20] |
ZHOU Y X, SHU J S, HAO H, et al. UAV 3D online track planning based on improved SAC algorithm[J]. Journal of the Brazilian Society of Mechanical Sciences and Engineering, 2023, 46(1): 12.
|
| [21] |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[DB/OL]. arXiv preprint: 1801.01290; 2018.
|
| [22] |
HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[DB/OL]. arXiv preprint, 1812.05905; 2018.
|
| [23] |
LEVINE S, KUMAR A, TUCKER G, et al. Offline reinforcement learning: Tutorial, review, and perspectives on open problems[DB/OL]. arXiv preprint: 2005.01643; 2020.
|
| [24] |
ZHANG L J, PENG J B, YI W G, et al. A state-decomposition DDPG algorithm for UAV autonomous navigation in 3-D complex environments[J]. IEEE Internet of Things Journal, 2024, 11(6): 10778-10790.
|
 ), 谢志鹏, 田永健, 孟光磊
), 谢志鹏, 田永健, 孟光磊