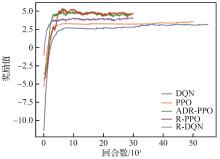
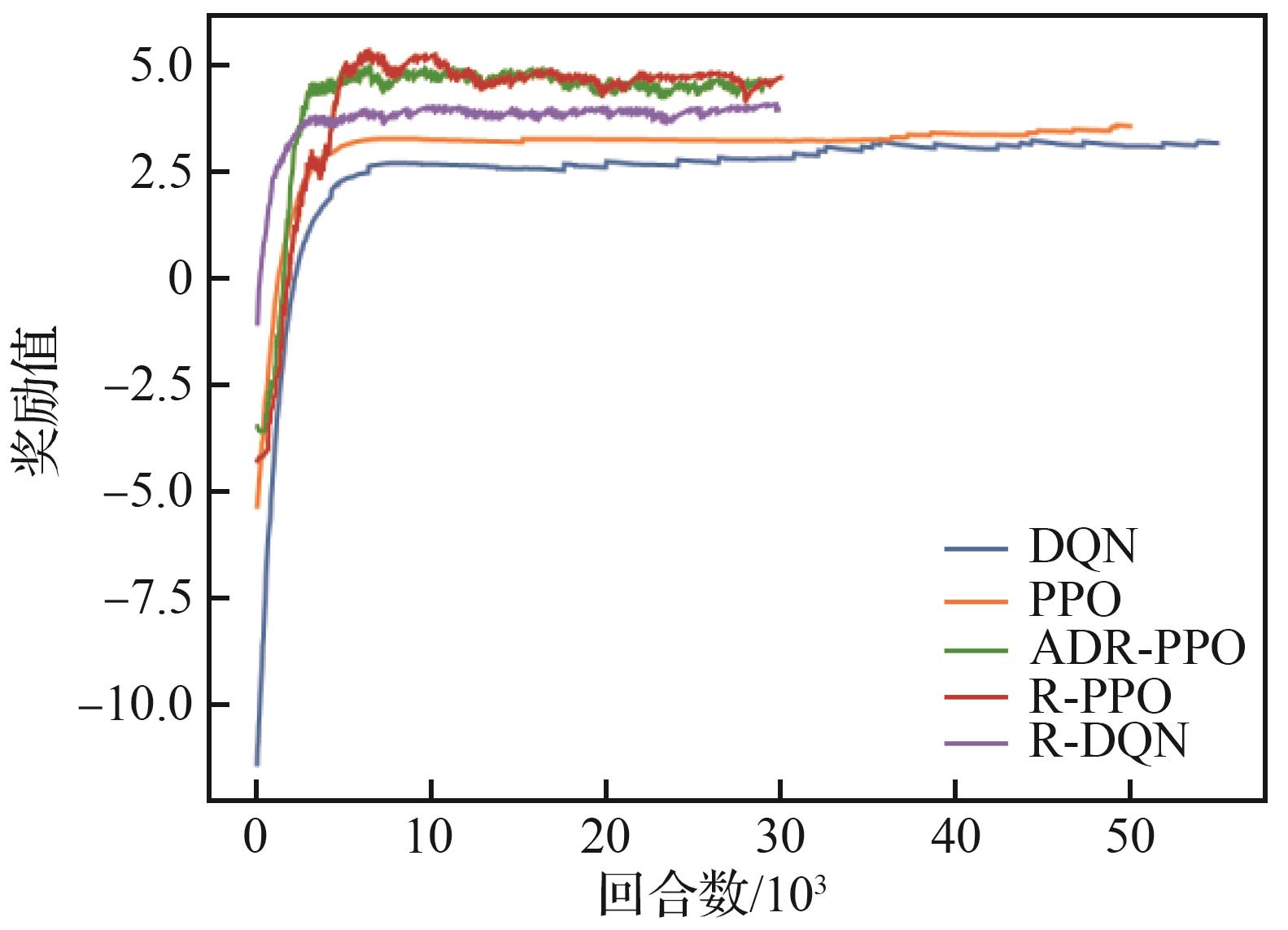
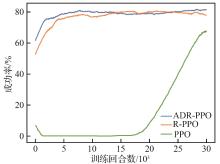
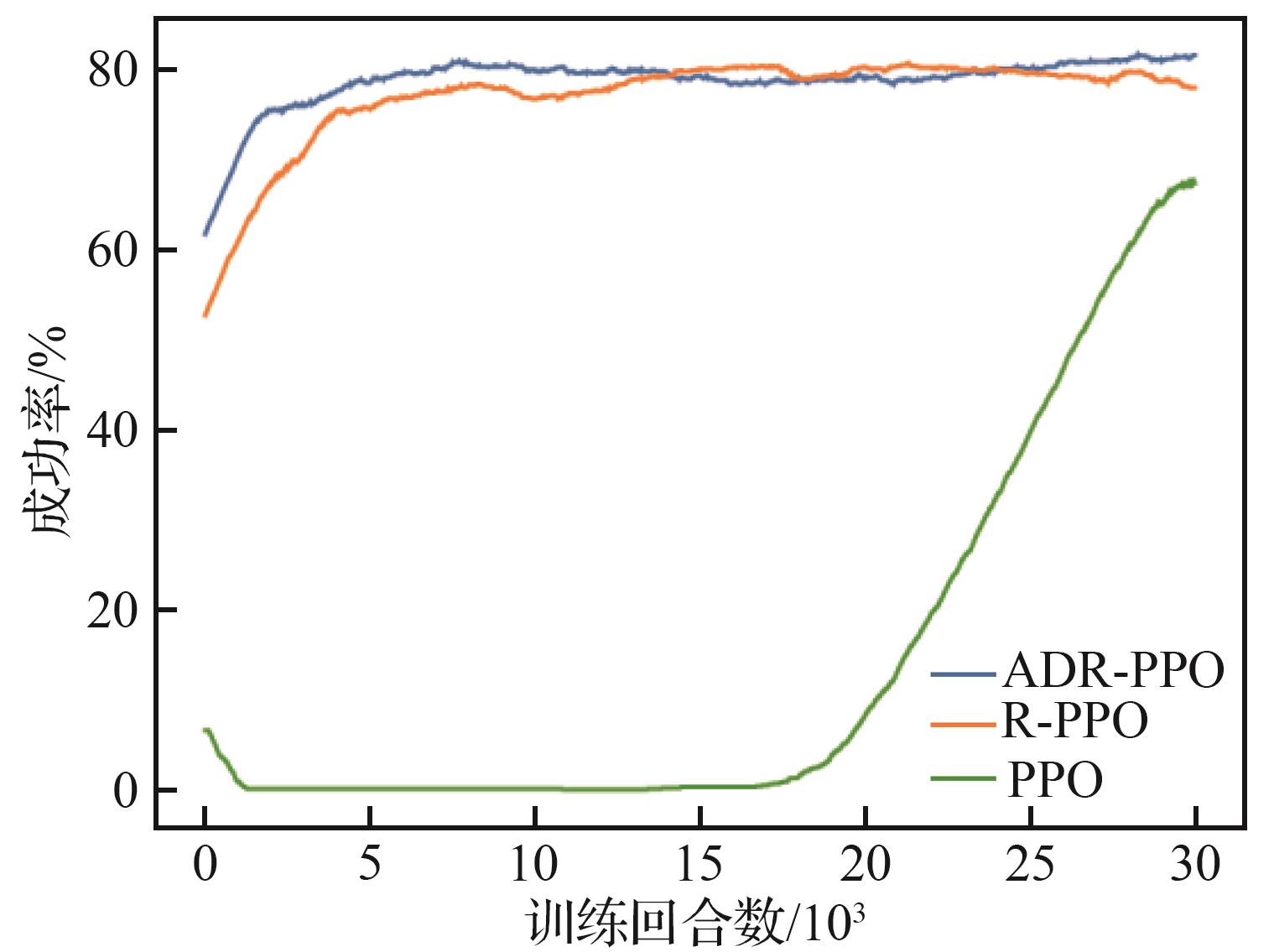
| [1] |
CHEN B X. Research on AI application in the field of quadcopter UAVs[C]∥2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology. Piscataway: IEEE, 2020: 569-571.
|
| [2] |
LI B, GAN Z G, CHEN D Q, et al. UAV maneuvering target tracking in uncertain environments based on deep reinforcement learning and meta-learning[J]. Remote Sensing, 2020, 12(22): 3789.
|
| [3] |
LI B, SONG C, BAI S X, et al. Multi-UAV trajectory planning during cooperative tracking based on a fusion algorithm integrating MPC and standoff[J]. Drones, 2023, 7(3): 196.
|
| [4] |
范之琳, 杨洪勇, 韩艺琳. 基于强化学习的多智能体系统目标围捕控制[J]. 航空学报, 2023, 44(S1): 727487.
|
|
FAN Z L, YANG H Y, HAN Y L. Target hunting control of multi-agent system based on reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S1): 727487 (in Chinese).
|
| [5] |
郭华, 郭小和. 改进速度障碍法的无人机局部路径规划算法[J]. 航空学报, 2023, 44(11): 327586.
|
|
GUO H, GUO X H. Local path planning algorithm for UAV based on improved velocity obstacle method[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(11): 327586 (in Chinese).
|
| [6] |
赵江, 张璇, 池沛, 等. 空地无人集群自调节控制与动态路径规划方法[J]. 航空学报, 2024, 45(16): 329809.
|
|
ZHAO J, ZHANG X, CHI P, et al. Self-adaptive formation control and dynamic path planning for air-ground heterogeneous swarm[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(16): 329809 (in Chinese).
|
| [7] |
黄湘松, 于日龙, 潘大鹏. 面向目标定位精度的主从式无人机编队航迹规划方法[J]. 电子学报, 2023, 51(9): 2289-2300.
|
|
HUANG X S, YU R L, PAN D P. Route planning method of master-slave UAV formation for target positioning accuracy[J]. Acta Electronica Sinica, 2023, 51(9): 2289-2300 (in Chinese).
|
| [8] |
FAN X Y, LI H, CHEN Y, et al. A path-planning method for UAV swarm under multiple environmental threats[J]. Drones, 2024, 8(5): 171.
|
| [9] |
DONG Q X. Reinforcement learning based anti-UAV three-dimensional pursuit-evasion game for substation security[C]∥2024 5th International Conference on Mechatronics Technology and Intelligent Manufacturing (ICMTIM). Piscataway: IEEE Press, 2024: 224-227.
|
| [10] |
MA X H. Application of artificial intelligence in computer network technology[C]∥2023 2nd International Conference on Artificial Intelligence and Autonomous Robot Systems (AIARS). Piscataway: IEEE Press, 2023: 182-186.
|
| [11] |
YU F, ZHANG X, LI Q. Determination of the barrier in the qualitatively pursuit-evasion differential game[C]∥ 2018 IEEE CSAA Guidance, Navigation and Control Conference (CGNCC). Piscataway: IEEE Press, 2018: 1-6.
|
| [12] |
PAN Q, ZHOU D Y, HUANG J C, et al. Maneuver decision for cooperative close-range air combat based on state predicted influence diagram[C]∥2017 IEEE International Conference on Information and Automation (ICIA). Piscataway: IEEE Press, 2017: 726-731.
|
| [13] |
傅莉, 谢福怀, 孟光磊, 等. 基于滚动时域的无人机空战决策专家系统[J]. 北京航空航天大学学报, 2015, 41(11): 1994-1999.
|
|
FU L, XIE F H, MENG G L, et al. An UAV air-combat decision expert system based on receding horizon control[J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(11): 1994-1999 (in Chinese).
|
| [14] |
张耀中, 许佳林, 姚康佳, 等. 基于DDPG算法的无人机集群追击任务[J]. 航空学报, 2020, 41(10): 324000.
|
|
ZHANG Y, XU J, YAO K, et al. Pursuit missions for UAV swarms based on DDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(10): 324000 (in Chinese).
|
| [15] |
KOUZEGHAR M, SONG Y, MEGHJANI M, et al. Multi-target pursuit by a decentralized heterogeneous UAV swarm using deep multi-agent reinforcement learning[C]∥2023 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE Press, 2023: 3289-3295.
|
| [16] |
符小卫, 徐哲, 朱金冬, 等. 基于PER-MATD3的多无人机攻防对抗机动决策[J]. 航空学报, 2023, 44(7): 327083.
|
|
FU X W, XU Z, ZHU J D, et al. Maneuvering decision-making of multi-UAV attack-defence confrontation based on PER-MATD3[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(7): 327083 (in Chinese).
|
| [17] |
XIONG H, ZHANG Y. Reinforcement learning-based formation-surrounding control for multiple quadrotor UAVs pursuit-evasion games[J]. ISA Transactions, 2024, 145: 205-224.
|
| [18] |
GUO Y, ZHANG N Z, JIANG H R, et al. Layered reinforcement learning design for safe flight control of UAV in urban environments[C]∥2023 International Annual Conference on Complex Systems and Intelligent Science (CSIS-IAC). Piscataway: IEEE Press, 2023: 673-678.
|
| [19] |
WANG J, XIAO Y, LI T S, et al. A jamming aware artificial potential field method to counter GPS jamming for unmanned surface ship path planning[J]. IEEE Systems Journal, 2023, 17(3): 4555-4566.
|
| [20] |
SHRIVASTAVA A, PFISTER T, TUZEL O, et al. Learning from simulated and unsupervised images through adversarial training[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2017: 2242-2251.
|
| [21] |
杨振, 李琳, 柴仕元, 等. 面向多战术需求的无人机空战自主规避机动方法[J]. 航空学报, 2024, 45(20): 630629.
|
|
YANG Z, LI L, CHAI S Y, et al. Autonomous evasive maneuver method for unmanned combat aerial vehicle in air combat with multiple tactical requirements[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(20): 630629 (in Chinese).
|
| [22] |
CESA-BIANCHI N, CONCONI A, GENTILE C. On the generalization ability of on-line learning algorithms[J]. IEEE Transactions on Information Theory, 2004, 50(9): 2050-2057.
|
 )
)