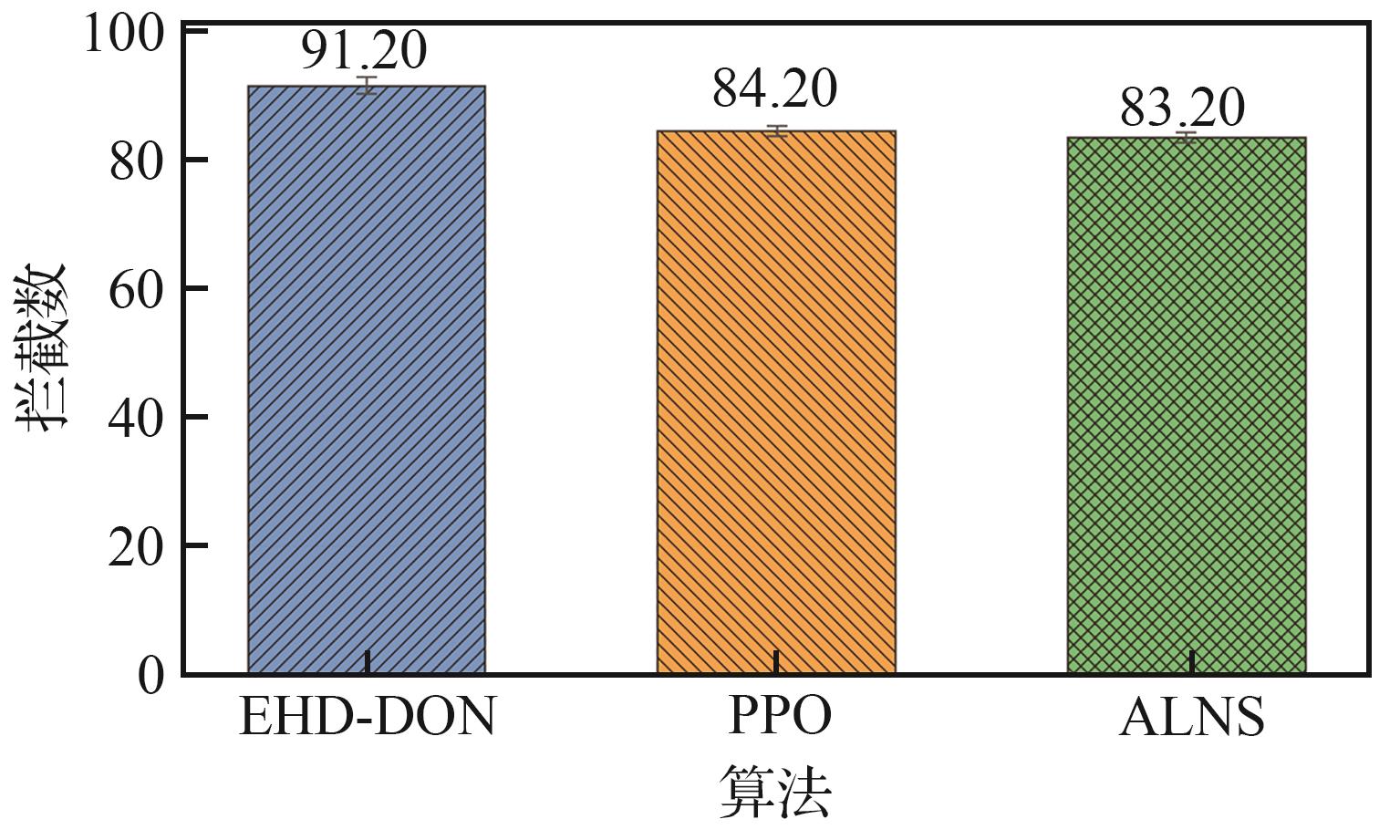
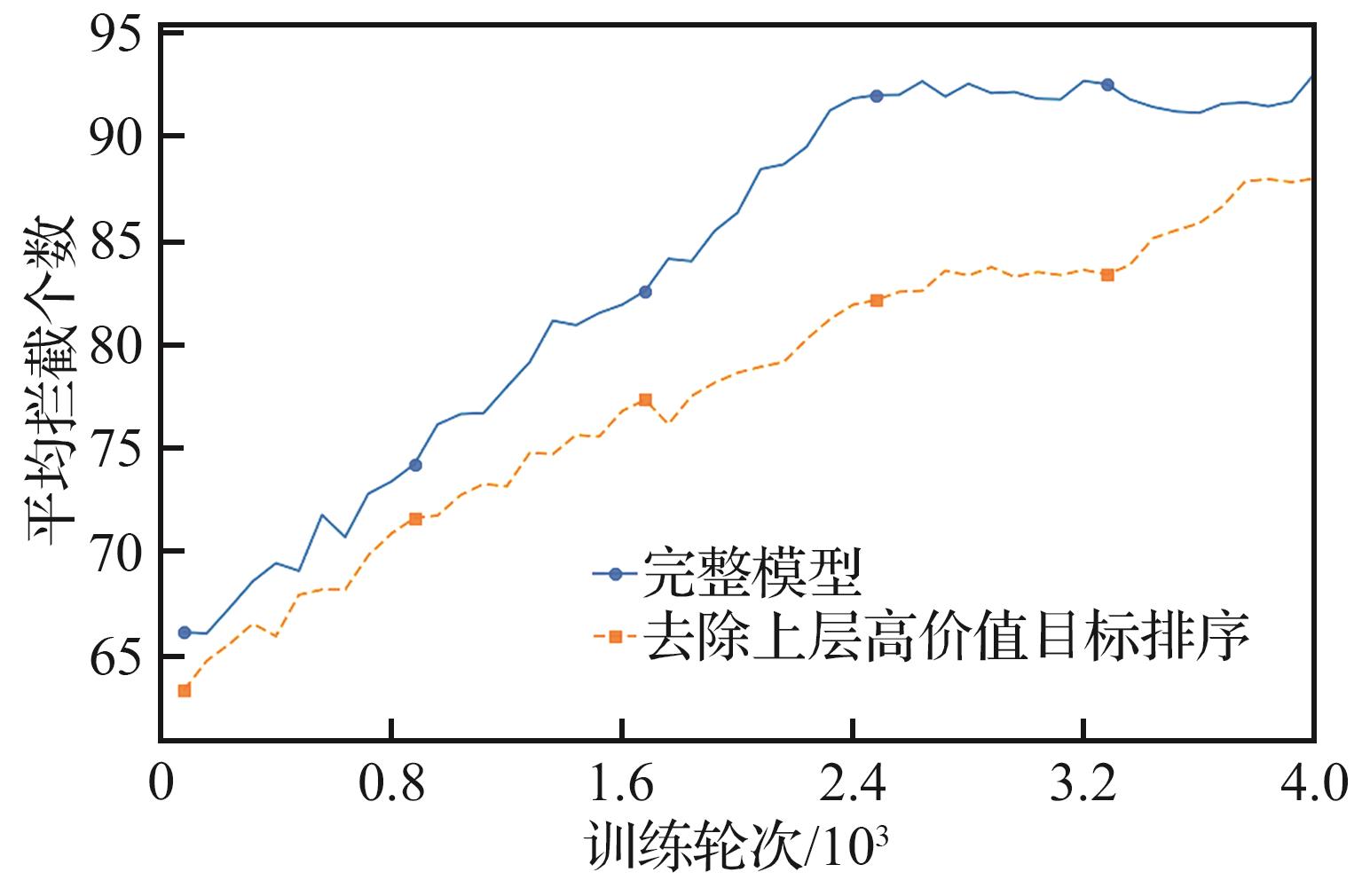
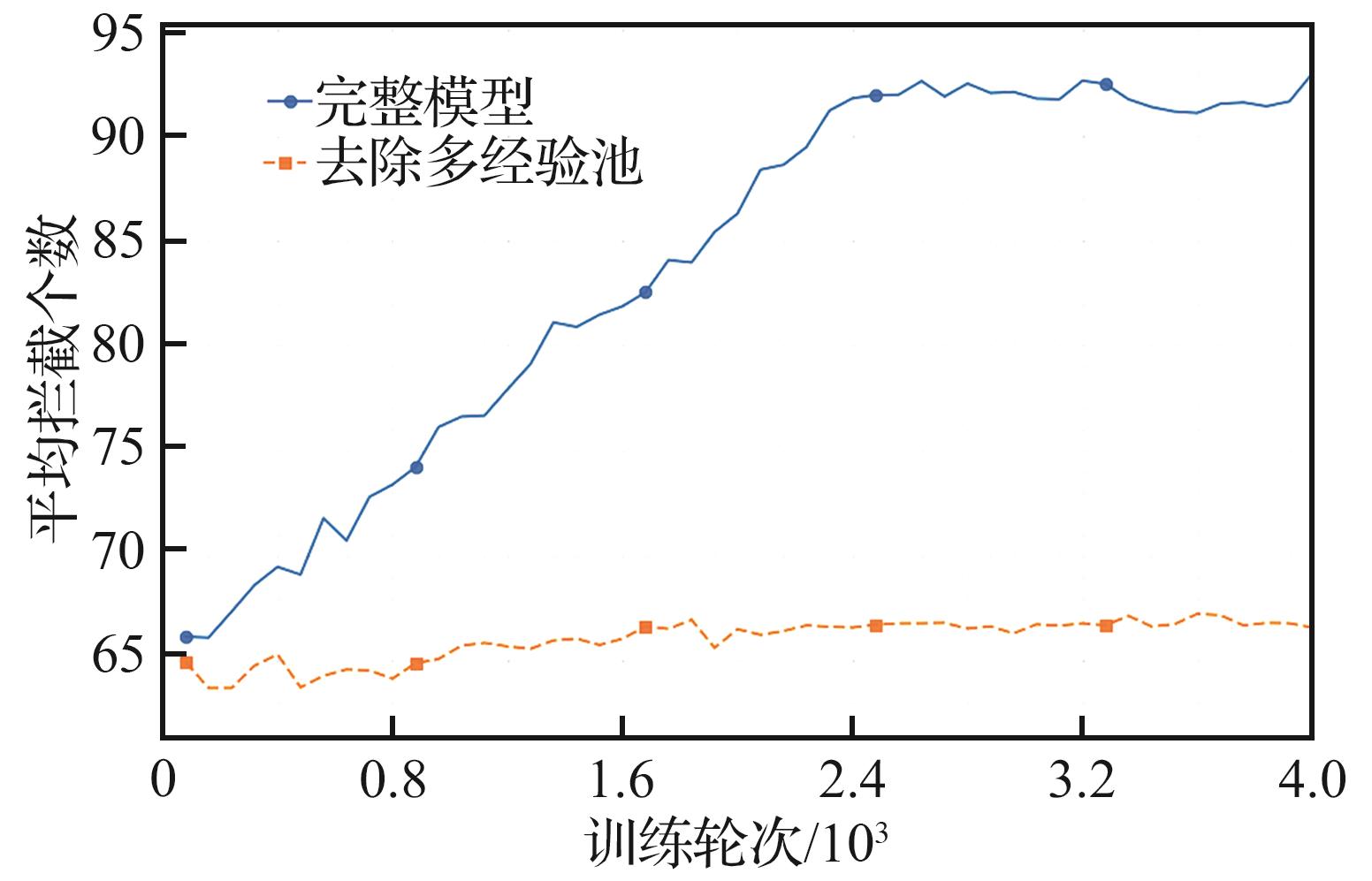
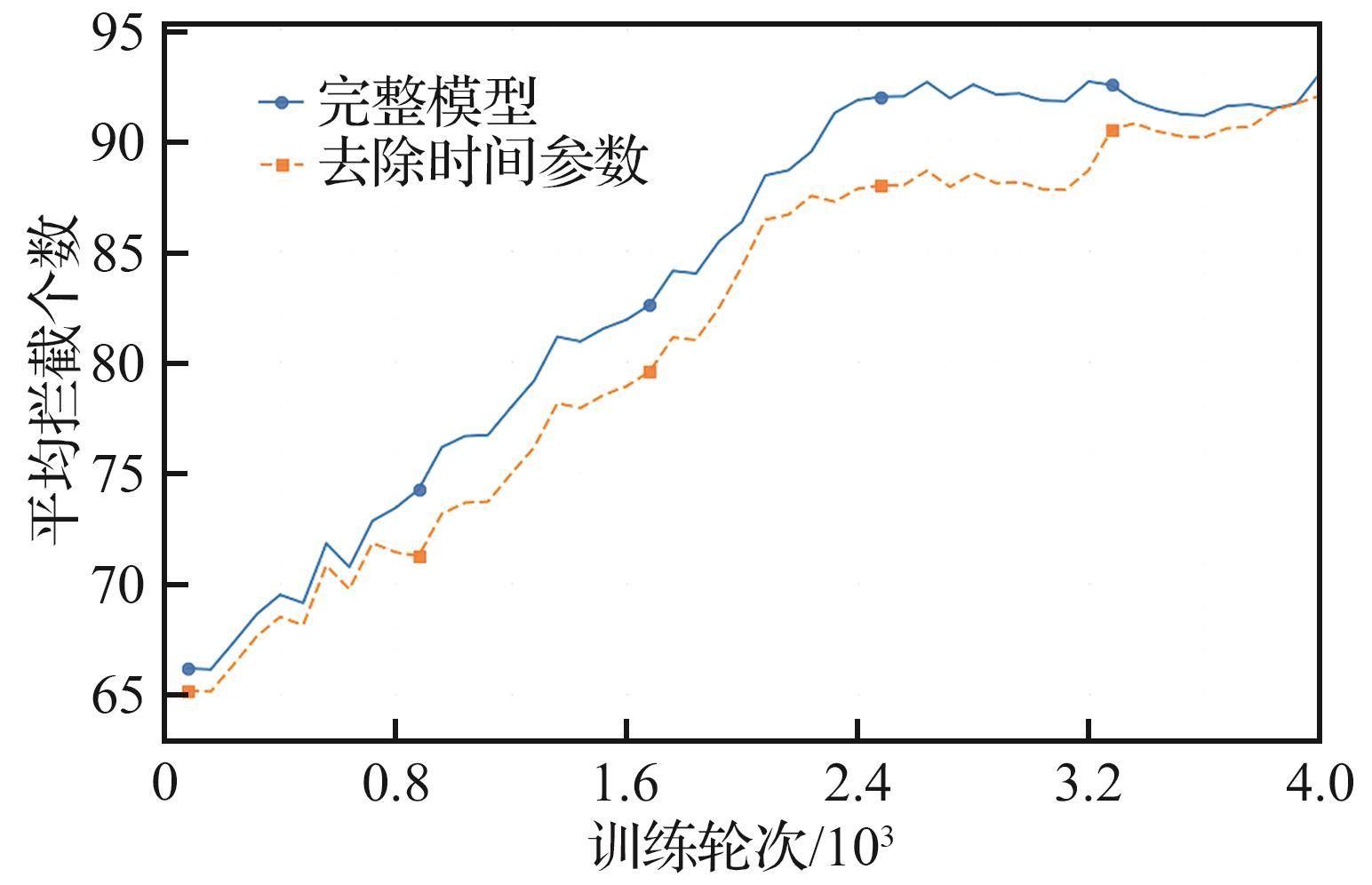
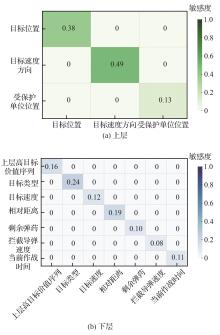
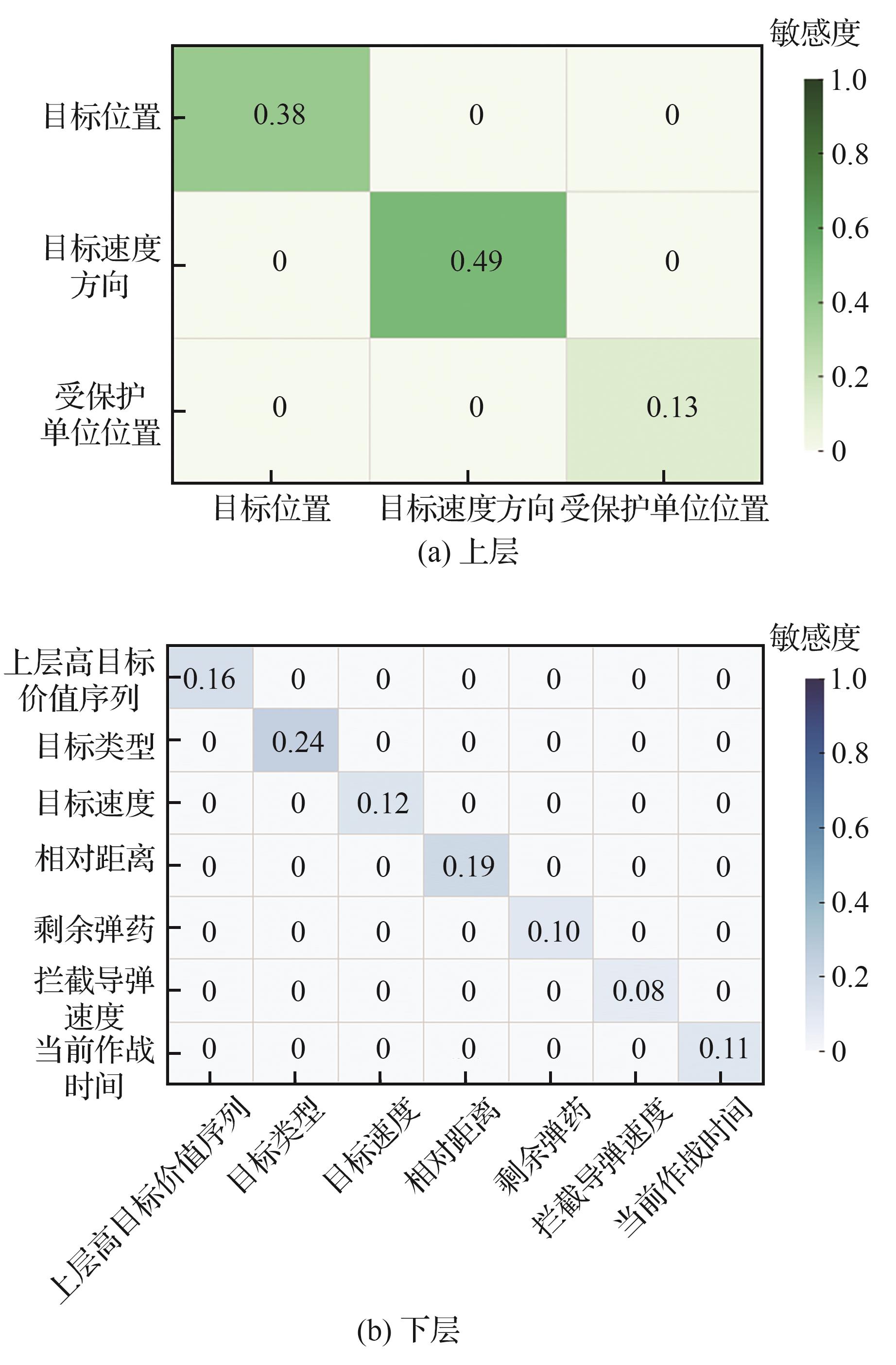
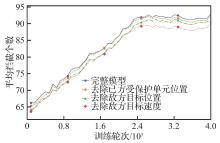
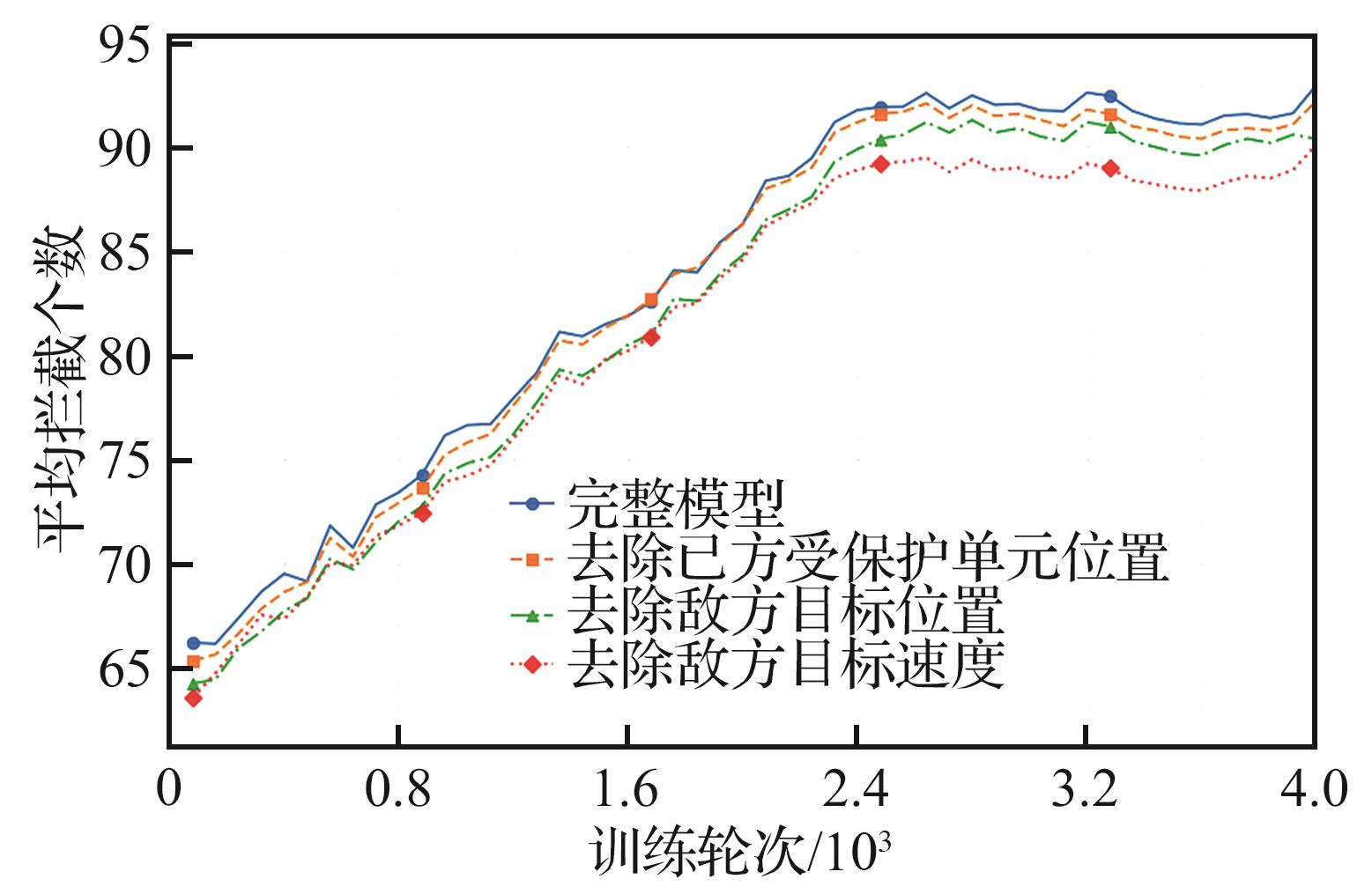
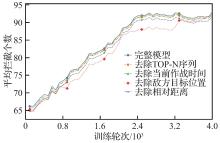
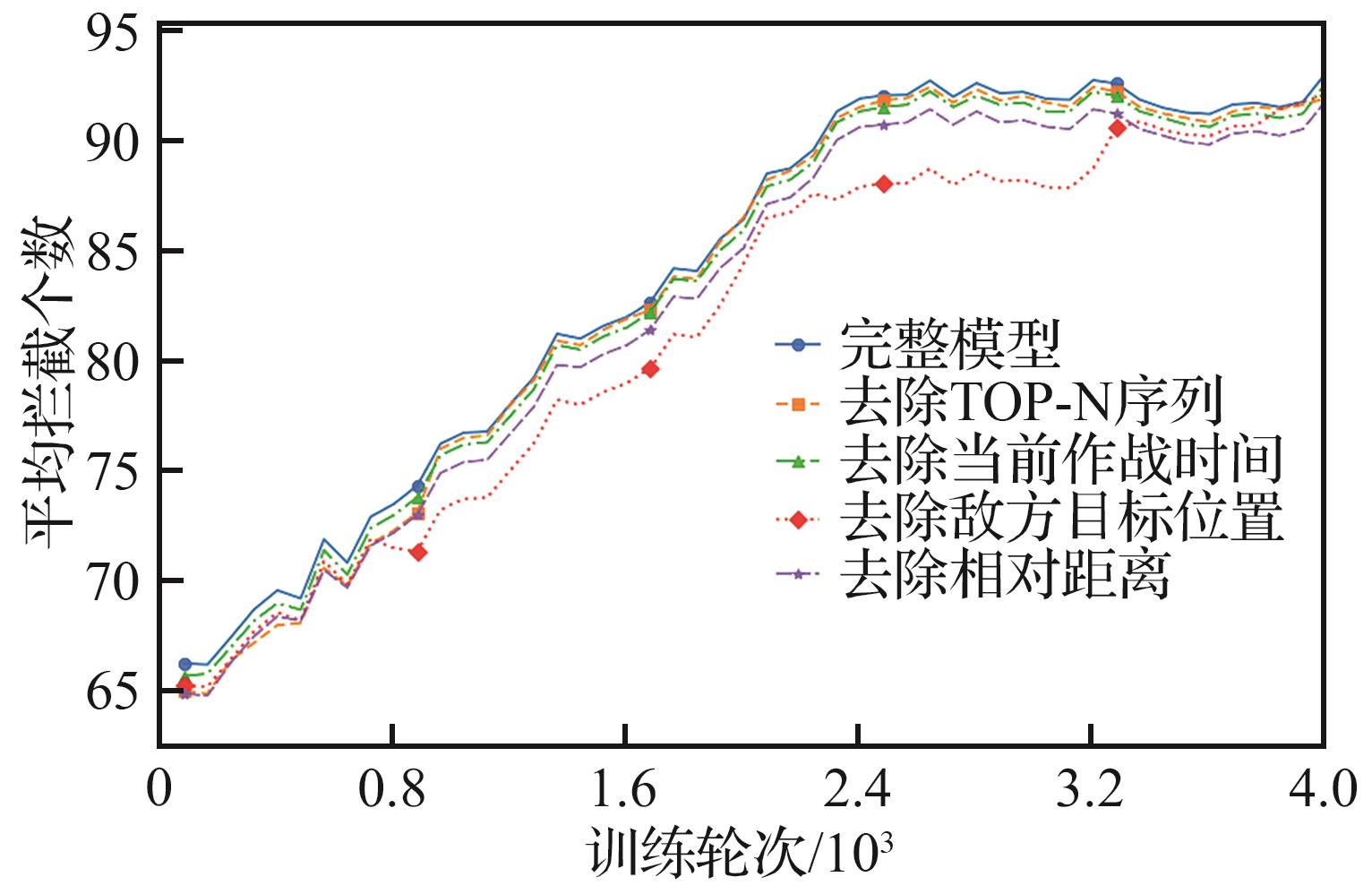
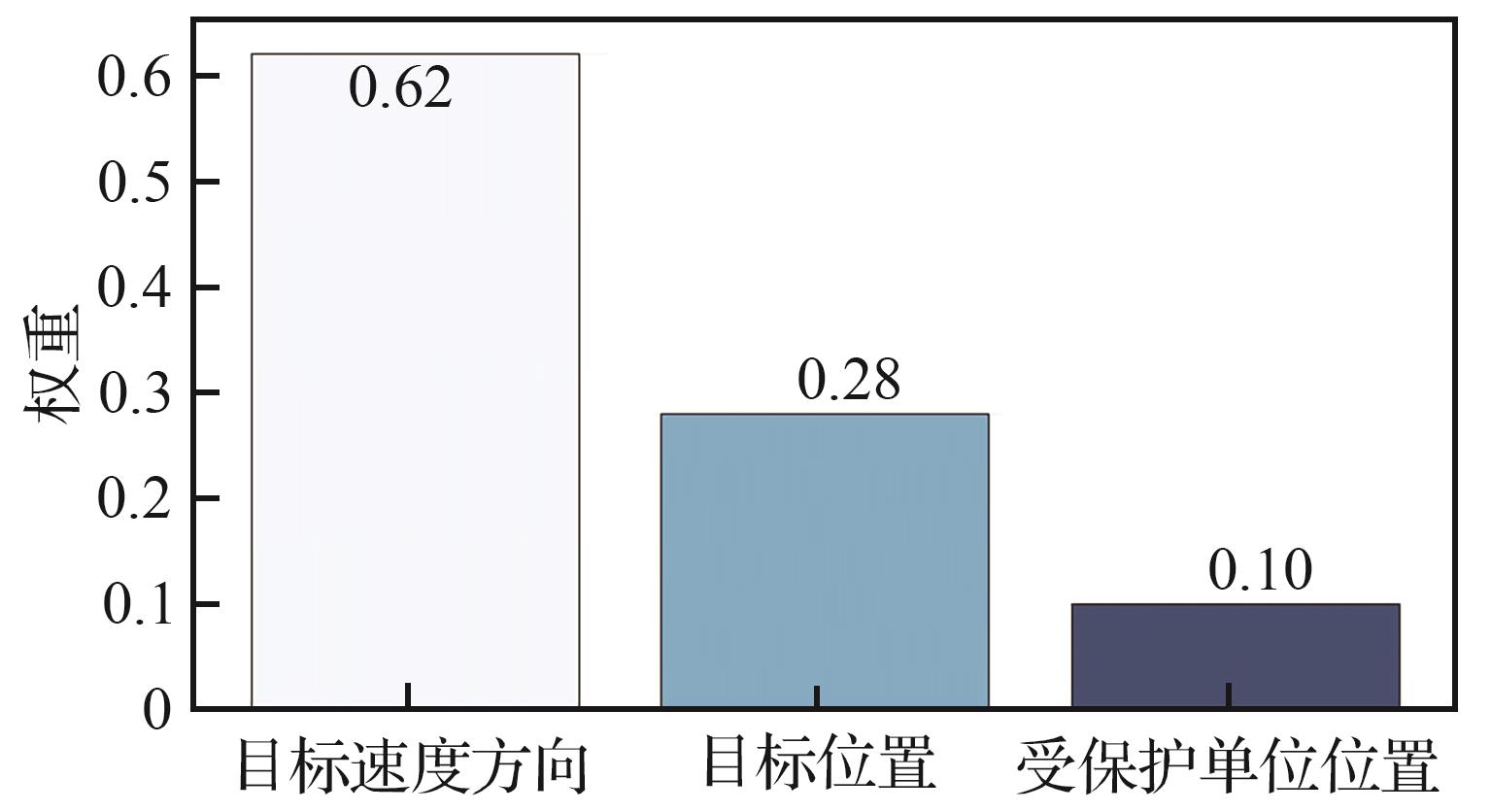
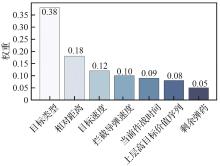
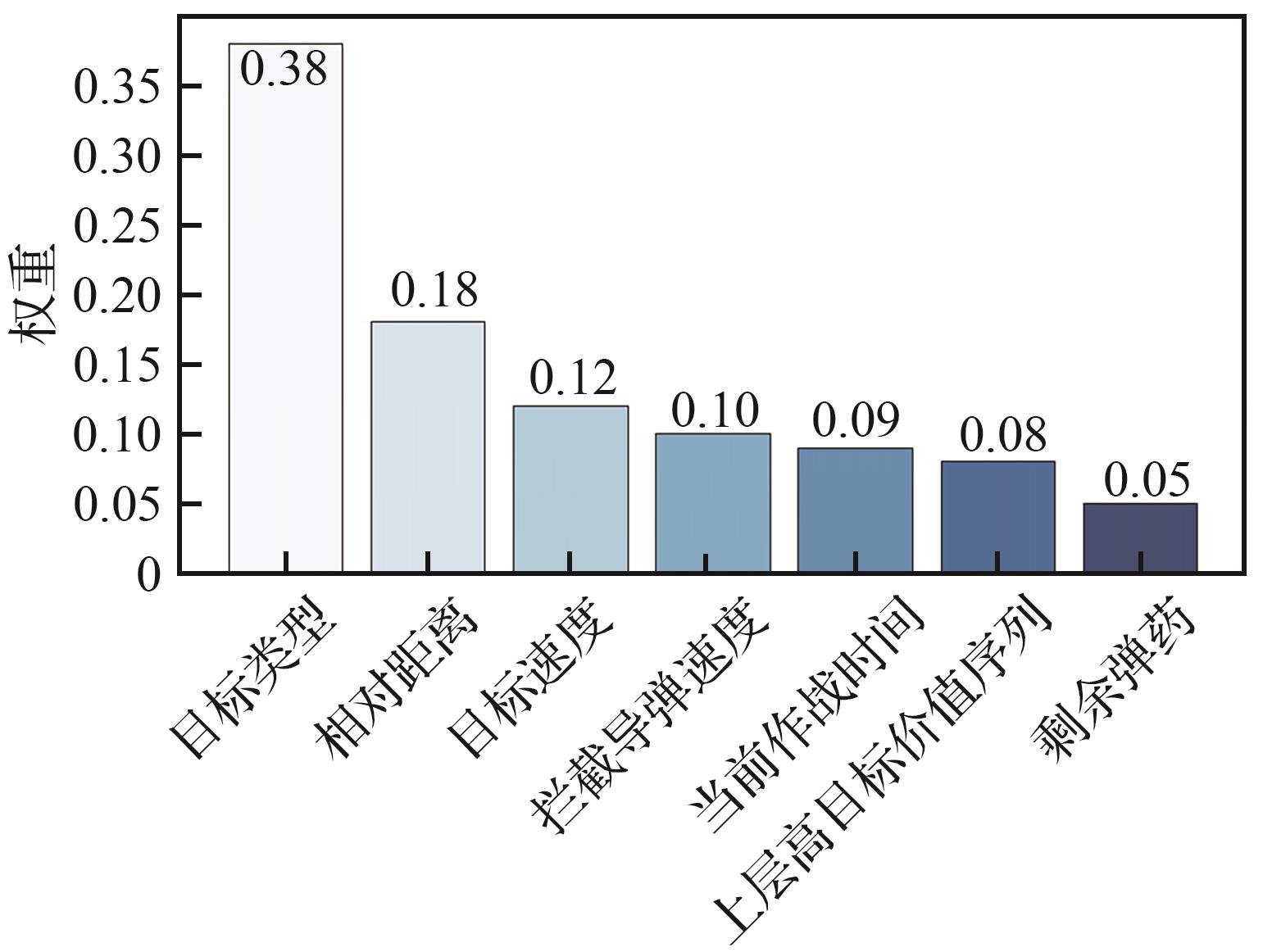
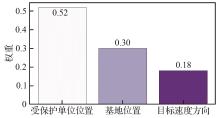
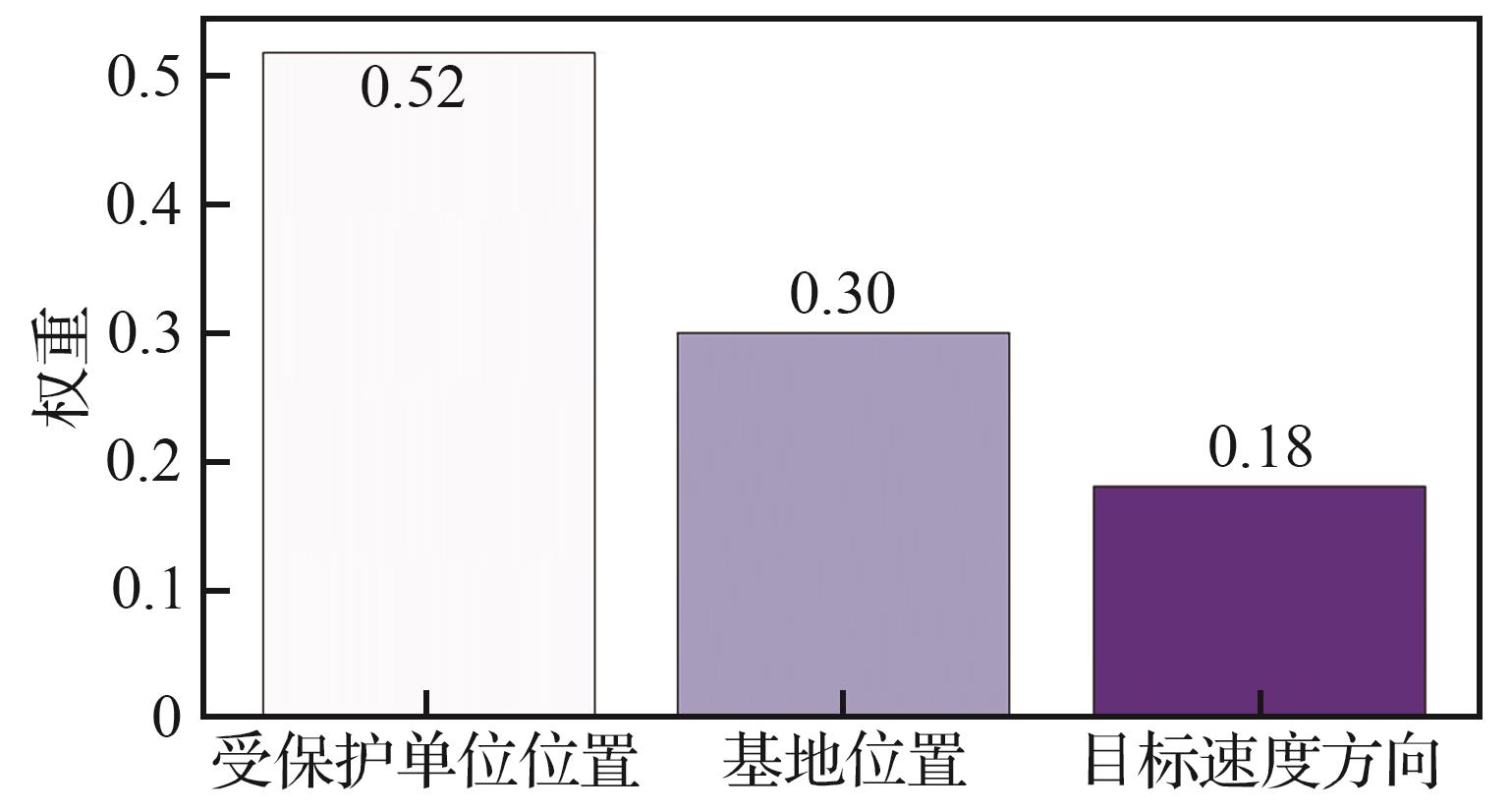
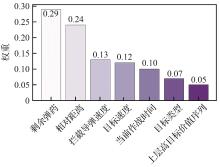
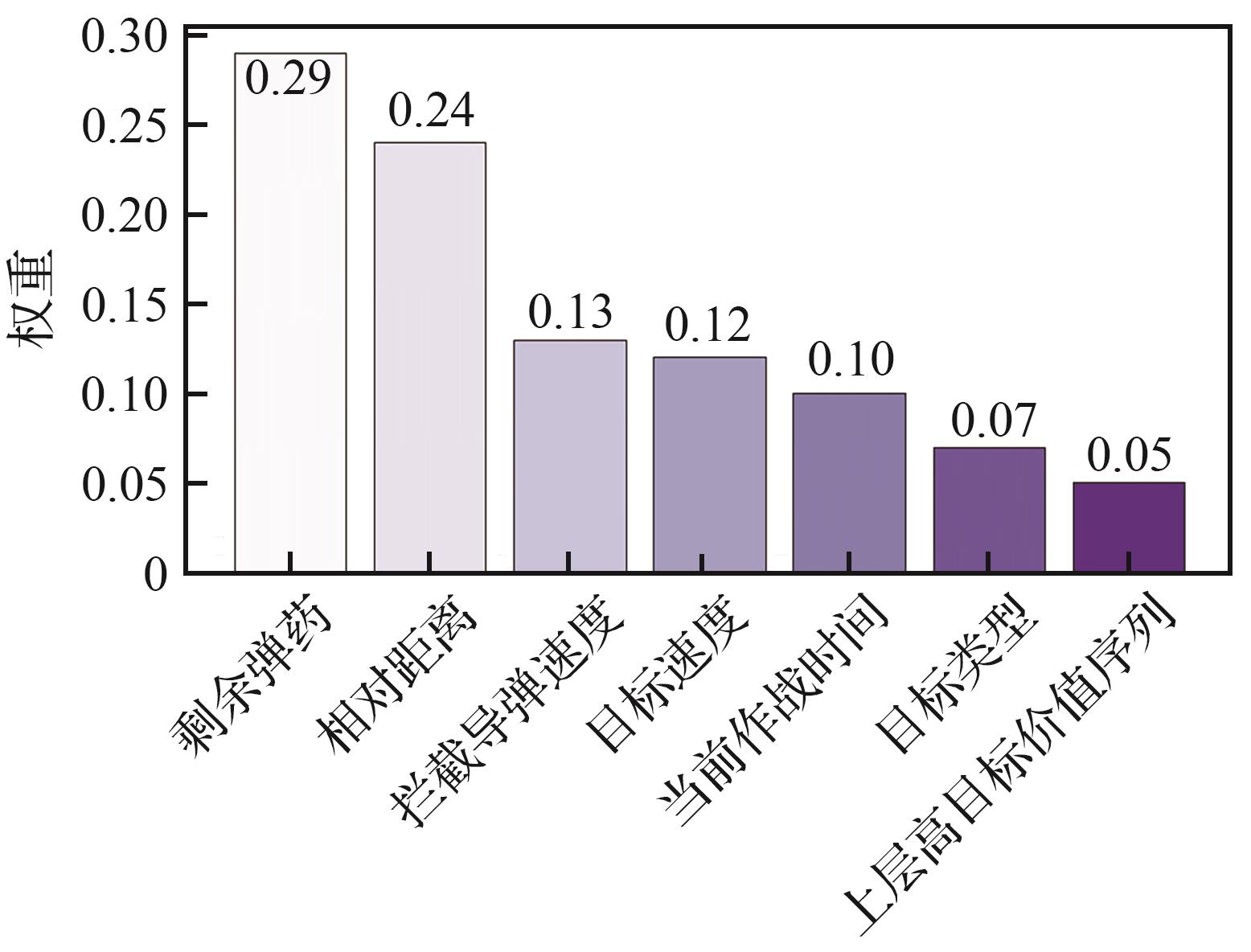
| [1] |
刘伟, 张琳, 王代强, 等. 激光武器反无人机集群作战运用及关键技术[J]. 航空学报, 2024, 45(12): 329457.
|
|
LIU W, ZHANG L, WANG D Q, et al. Application and key technologies of laser weapons in anti-UAV swarm operations[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(12): 329457 (in Chinese).
|
| [2] |
SUN Z Y, YANG J Y. Multi-missile interception for multi-targets: Dynamic situation assessment, target allocation and cooperative interception in groups[J]. Journal of the Franklin Institute, 2022, 359(12): 5991-6022.
|
| [3] |
LI J R, WU G H, WANG L. A comprehensive survey of weapon target assignment problem: Model, algorithm, and application[J]. Engineering Applications of Artificial Intelligence, 2024, 137: 109212.
|
| [4] |
OH S H, BYUEON G W, CHO Y I, et al. Artificial intelligence in combat decision-making: Weapon target assignment via reinforcement learning and graph neural networks[J]. IEEE Transactions on Cybernetics, 2025, pp(99):1-13.
|
| [5] |
TUNCER O, CIRPAN H A. Adaptive fuzzy based threat evaluation method for air and missile defense systems[J]. Information Sciences, 2023, 643: 119191.
|
| [6] |
CHEN L, YANG J, ZHOU Y Z, et al. A rule-based agent for unmanned systems with TDGG and VGD for online air target intention recognition[J]. Drones, 2024, 8(12): 765.
|
| [7] |
COSKUN M, TASDEMIR S. Fuzzy logic-based threat assessment application in air defense systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(3): 2245-2251.
|
| [8] |
PIRES H B, GUIMARÃES L N F. Dynamic multi-target three-way threat assessment in the context of air defense[J]. IEEE Access, 2024, 12: 141397-141413.
|
| [9] |
PIRES H B, GUIMARÃES L N F, REBOUÇAS S. A multi-target threat assessment method based on objective three-way decision[J]. IEEE Access, 2025, 13: 681-694.
|
| [10] |
刘富樯, 周伦, 刘中阳, 等. 基于三支决策和遗传算法的动态武器目标分配[J]. 兵工学报, 2025, 46(3): 240281.
|
|
LIU F Q, ZHOU L, LIU Z Y, et al. Dynamic weapon-target assignment based on three-way decision and genetic algorithm[J]. Acta Armamentarii, 2025, 46(3): 240281 (in Chinese).
|
| [11] |
唐明南, 张承龙, 赵强, 等. 任务场景驱动的防空资源部署方案智能生成与优化方法[J]. 现代防御技术, 2023, 51(3): 1-9.
|
|
TANG M N, ZHANG C L, ZHAO Q, et al. Scenario-driven and intelligent optimization of disposition scheme for air defense[J]. Modern Defense Technology, 2023, 51(3): 1-9 (in Chinese).
|
| [12] |
毕文豪, 周久力, 段晓波, 等. 基于多要素改进NSGA-Ⅱ的小直径制导炸弹空面打击最优火力分配方法[J]. 航空学报, 2023, 44(17): 328116.
|
|
BI W H, ZHOU J L, DUAN X B, et al. Optimal fire distribution method of small diameter guided bomb in air-to-surface strike based on multi-factor modified NSGA-Ⅱ[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(17): 328116 (in Chinese).
|
| [13] |
SONG J M, CHENG T, WANG Y M, et al. LPI-based resource allocation strategy for multiple targets tracking in CMIMO radar system with array division[J]. Signal Processing, 2024, 225: 109625.
|
| [14] |
BERTSIMAS D, PASKOV A. Solving large-scale weapon target assignment problems in seconds using branch-price-and-cut[J]. Naval Research Logistics (NRL), 2025, 72(5): 735-749.
|
| [15] |
隆雨佟, 陈爱国, 史红权, 等. 基于改进差分进化算法的跨平台武器目标分配方法[J]. 系统工程与电子技术, 2024, 46(3): 953-962.
|
|
LONG Y T, CHEN A G, SHI H Q, et al. Cross-platform weapon target allocation method based on improved differential evolution algorithm[J]. Systems Engineering and Electronics, 2024, 46(3): 953-962 (in Chinese).
|
| [16] |
YI X J, YU H Y, XU T. Solving multi-objective weapon-target assignment considering reliability by improved MOEA/D-AM2M[J]. Neurocomputing, 2024, 563: 126906.
|
| [17] |
Lu Y, Chen D Z, Gao T. An exact algorithm for the dynamic two-stage weapon-target assignment problem: abstract=4485993[R]. SSRN, 2023.
|
| [18] |
孙昕, 邢立宁, 王锐, 等. 基于多目标进化算法的防空导弹武器目标分配[J]. 系统仿真学报, 2024, 36(6): 1298-1308.
|
|
SUN X, XING L N, WANG R, et al. Air defense missile weapon target assignment based on multi-objective evolutionary algorithm[J]. Journal of System Simulation, 2024, 36(6): 1298-1308 (in Chinese).
|
| [19] |
ZHAO J, LV Y F. Output-feedback robust control of systems with uncertain dynamics via data-driven policy learning[J]. International Journal of Robust and Nonlinear Control, 2022, 32(18): 9791-9807.
|
| [20] |
高树一, 林德福, 郑多,等. 考虑拦截器探测能力限制的飞行器智能机动突防制导策略[J]. 航空学报, 2025, 46(10): 331304.
|
|
GAO S Y, LIN D F, ZHENG D, et al. Intelligent maneuvering penetration guidance strategies for aerial vehicles considering interceptor detection capability limitations[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(10): 331304 (in Chinese).
|
| [21] |
ZHAO M R, WANG G, FU Q, et al. Intelligent decision‐making system of air defense resource allocation via hierarchical reinforcement learning[J]. International Journal of Intelligent Systems, 2024, 2024(1): 7777050.
|
| [22] |
LI T, WANG G, FU Q, et al. An intelligent algorithm for solving weapon-target assignment problem: DDPG-DNPE algorithm[J]. Computers, Materials & Continua, 2023, 76(3): 3499-3522.
|
| [23] |
NA H, AHN J, MOON I C. Weapon-target assignment by reinforcement learning with pointer network[J]. Journal of Aerospace Information Systems, 2023, 20(1): 53-59.
|
| [24] |
闫世祥, 刘海军. 基于深度强化学习的传感器-武器-目标分配方法[J]. 现代防御技术, 2025, 53(4): 10-17.
|
|
YAN S X, LIU H J. Sensor-weapon-target assignment method based on deep reinforcement learning[J]. Modern Defense Technology, 2025, 53(4): 10-17 (in Chinese).
|
| [25] |
QIN P, ZHAO T. Knowledge guided fuzzy deep reinforcement learning[J]. Expert Systems with Applications, 2025, 264: 125823.
|
| [26] |
VOUROS G A. Explainable deep reinforcement learning: state of the art and challenges[J]. ACM Computing Surveys, 2022, 55(5): 1-39.
|
| [27] |
张晨浩, 周焰, 蔡益朝, 等. 空中目标作战意图识别研究综述[J]. 现代防御技术, 2024, 52(4): 1-15.
|
|
ZHANG C H, ZHOU Y, CAI Y C, et al. A review of air target operational intention recognition research[J]. Modern Defense Technology, 2024, 52(4): 1-15 (in Chinese).
|
| [28] |
KIM J E, LEE C H, YI M Y. A study on the weapon–target assignment problem considering heading error[J]. International Journal of Aeronautical and Space Sciences, 2024, 25(3): 1105-1120.
|
| [29] |
ZHAO K, SONG J, YU J W, et al. Integrated assignment and guidance with multi-objective function in a three-dimensional scenario[J]. Engineering Optimization, 2025: 1-16.
|
| [30] |
WONG A, BÄCK T, KONONOVA A V, et al. Deep multiagent reinforcement learning: Challenges and directions[J]. Artificial Intelligence Review, 2023, 56(6): 5023-5056.
|
| [31] |
MINH D, WANG H X, LI Y F, et al. Explainable artificial intelligence: A comprehensive review[J]. Artificial Intelligence Review, 2022, 55: 3503-3568.
|
| [32] |
GAJCIN J, DUSPARIC I. Redefining counterfactual explanations for reinforcement learning: Overview, challenges and opportunities[J]. ACM Computing Surveys, 2024, 56(9): 1-33.
|
| [33] |
RIBEIRO M, SINGH S, GUESTRIN C. “Why should I trust you?” Explaining the predictions of any classifier[C]∥2016 Conference of the north American chapter of the association for computational linguistics: Demonstrations. San Diego: NAACL, 2016: 97-101.
|
| [34] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128: 336-359.
|
 )
)