李煜1, 徐新龙2, 李珂澄3, 溫志湧1, 李霓4, 刘小雄3( )
)
收稿日期:2025-05-12
修回日期:2025-07-29
接受日期:2025-09-05
出版日期:2025-09-19
发布日期:2025-09-18
通讯作者:
刘小雄
E-mail:liuxiaoxiong@nwpu.edu.cn
基金资助:
Yu LI1, Xinlong XU2, Kecheng LI3, Chi-yung WEN1, Ni LI4, Xiaoxiong LIU3()
Received:2025-05-12
Revised:2025-07-29
Accepted:2025-09-05
Online:2025-09-19
Published:2025-09-18
Contact:
Xiaoxiong LIU
E-mail:liuxiaoxiong@nwpu.edu.cn
Supported by:摘要:
针对V尾飞机的深失速改出问题,结合带惩罚的近端策略优化(P3O)学习和快速预定义时间的增量控制方法,提出了一种分层结构的深失速安全改出策略。首先,建立了V尾飞机的六自由度非线性运动方程,并将深失速安全改出问题转化为带有约束的马尔科夫决策过程;其次,改进了现有的预定义时间控制理论,提升了系统状态在预定义收敛时间内的响应速度,并基于改进后的理论和非线性增量动态逆控制方法设计了角速度控制器,确保角速度能够在预定义时间内快速跟踪上决策指令,并通过Lyapunov稳定理论证明了其预定义时间的稳定性;随后,结合深失速改出过程中飞机的安全需求,构建了基于惩罚近端策略优化的强化学习决策网络,将安全约束转化为惩罚项,从而实现深失速改出的安全决策;最后,通过一系列仿真和蒙特卡洛实验对所提出深失速安全改出策略进行了验证,结果表明该策略在快速性、鲁棒性、安全性以及策略合理性方面具有显著优势,并且展示出良好的应用潜力。
中图分类号:
李煜, 徐新龙, 李珂澄, 溫志湧, 李霓, 刘小雄. 基于安全约束强化学习的深失速改出控制[J]. 航空学报, 2026, 47(4): 332217.
Yu LI, Xinlong XU, Kecheng LI, Chi-yung WEN, Ni LI, Xiaoxiong LIU. Deep-stall recovery control based on safety-constrained reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2026, 47(4): 332217.

图 1
V尾布局飞机的舵面布局


图 2
深失速改出控制结构
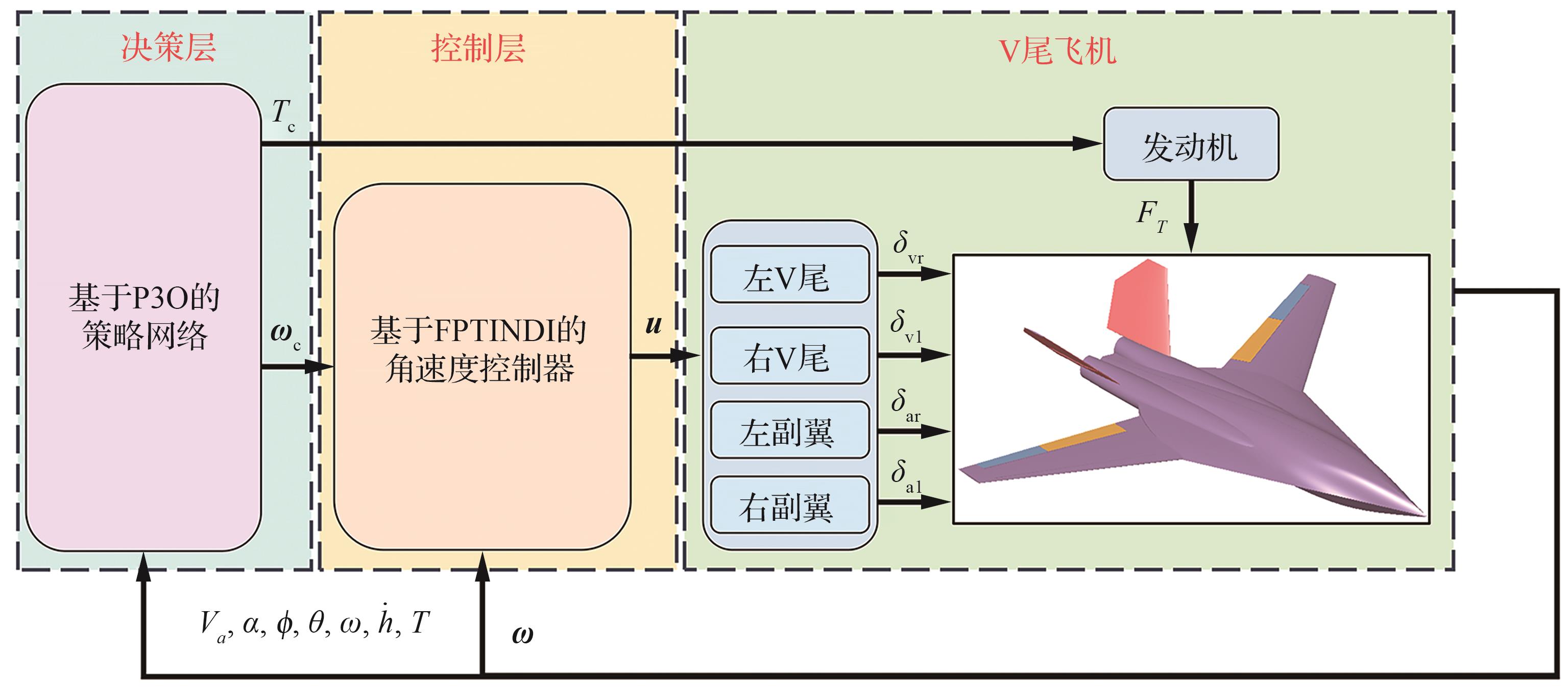

图 3
基于FPTINDI角速度控制器


图 4
自适应约束阈值调节
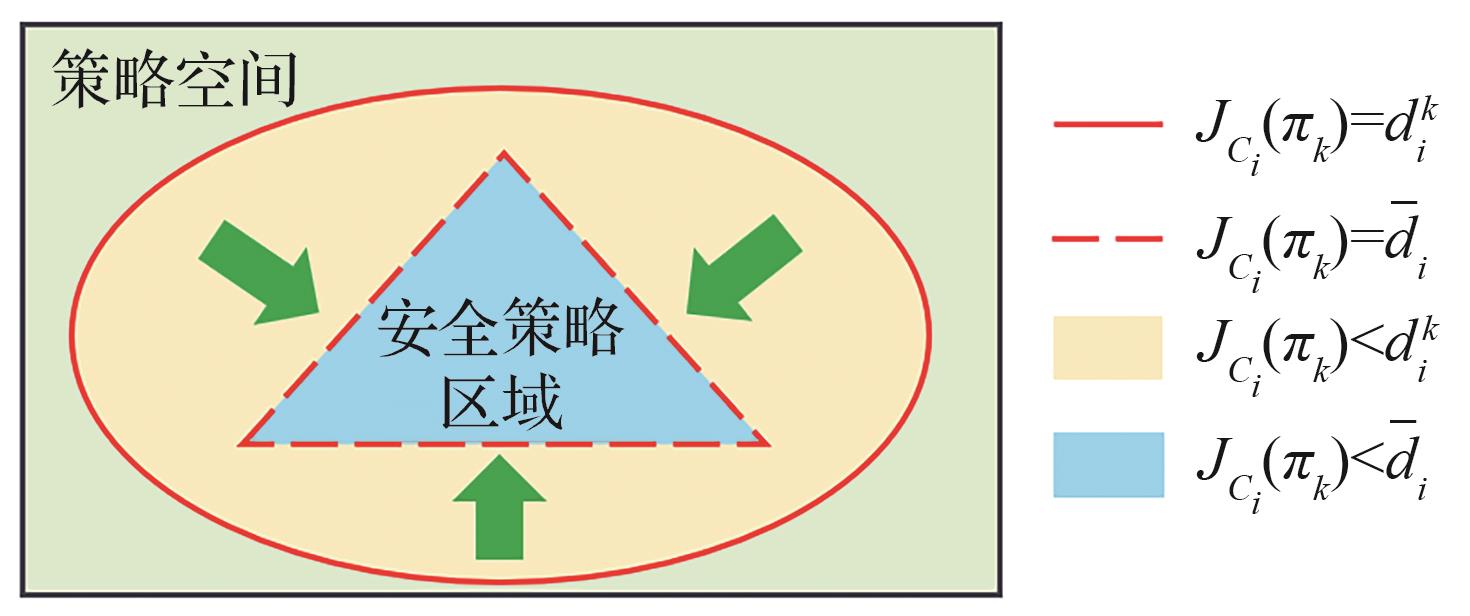
表 1
FPTINDI控制器参数
| 组成 | 参数 |
|---|---|
| NTD | |
| FPTNF | |
| FPTINDI |
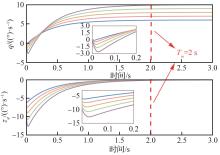
图 5
俯仰角速度响应和误差

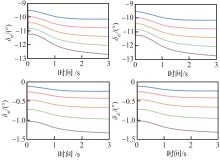
图 6
舵面偏转
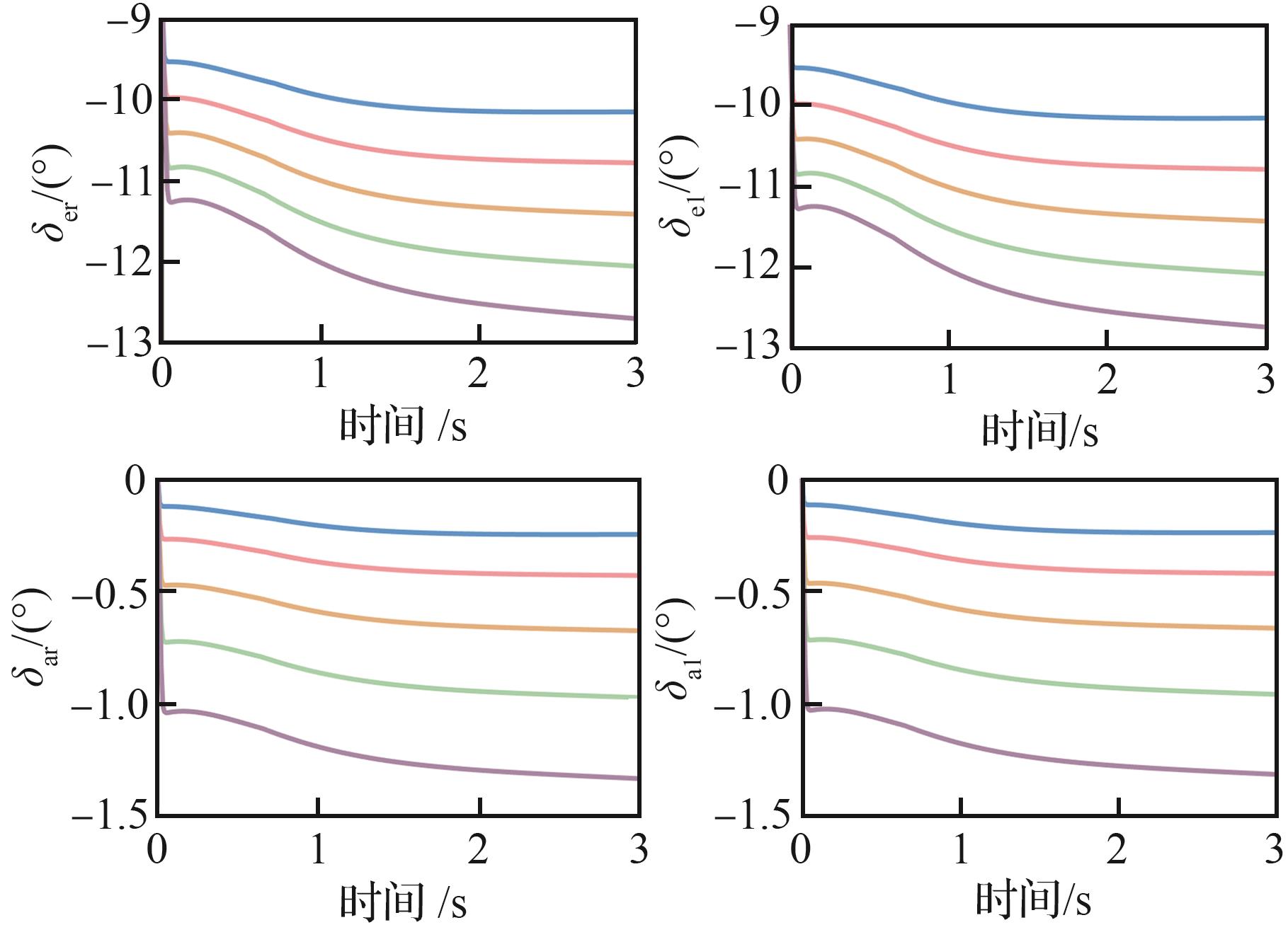

图 7
角速度对比


图 8
舵面对比

表 2
策略网络、奖励函数和成本函数参数
| 组成 | 参数 |
|---|---|
| 策略网络 | |
| 奖励函数和成本函数 |
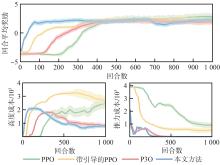
图 9
奖励和成本收敛对比

图 10
固定约束和自适应约束对比
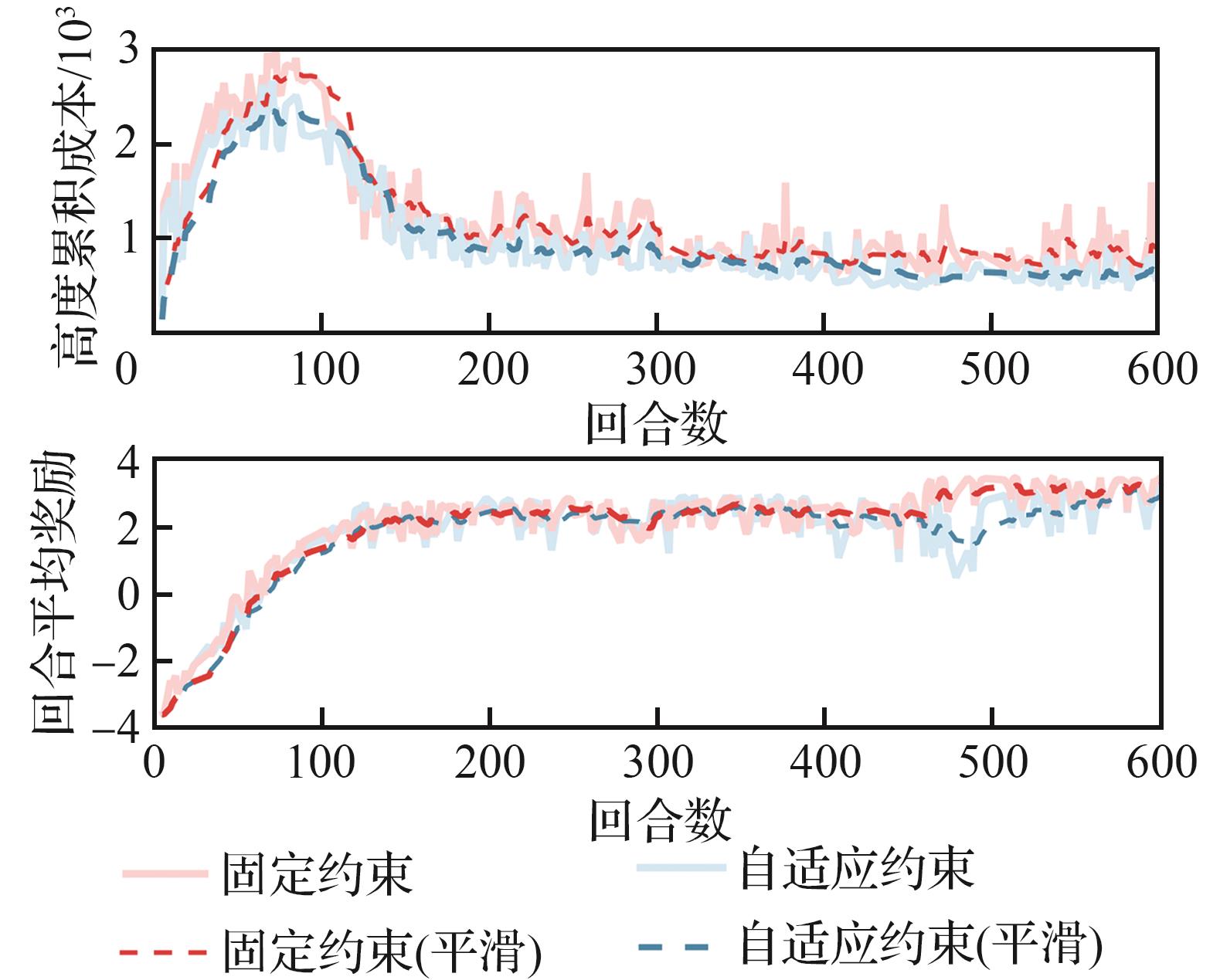

图 11
高度对比


图 12
迎角对比


图 13
迎角的相平面

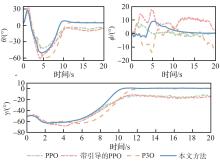
图 14
飞机状态对比
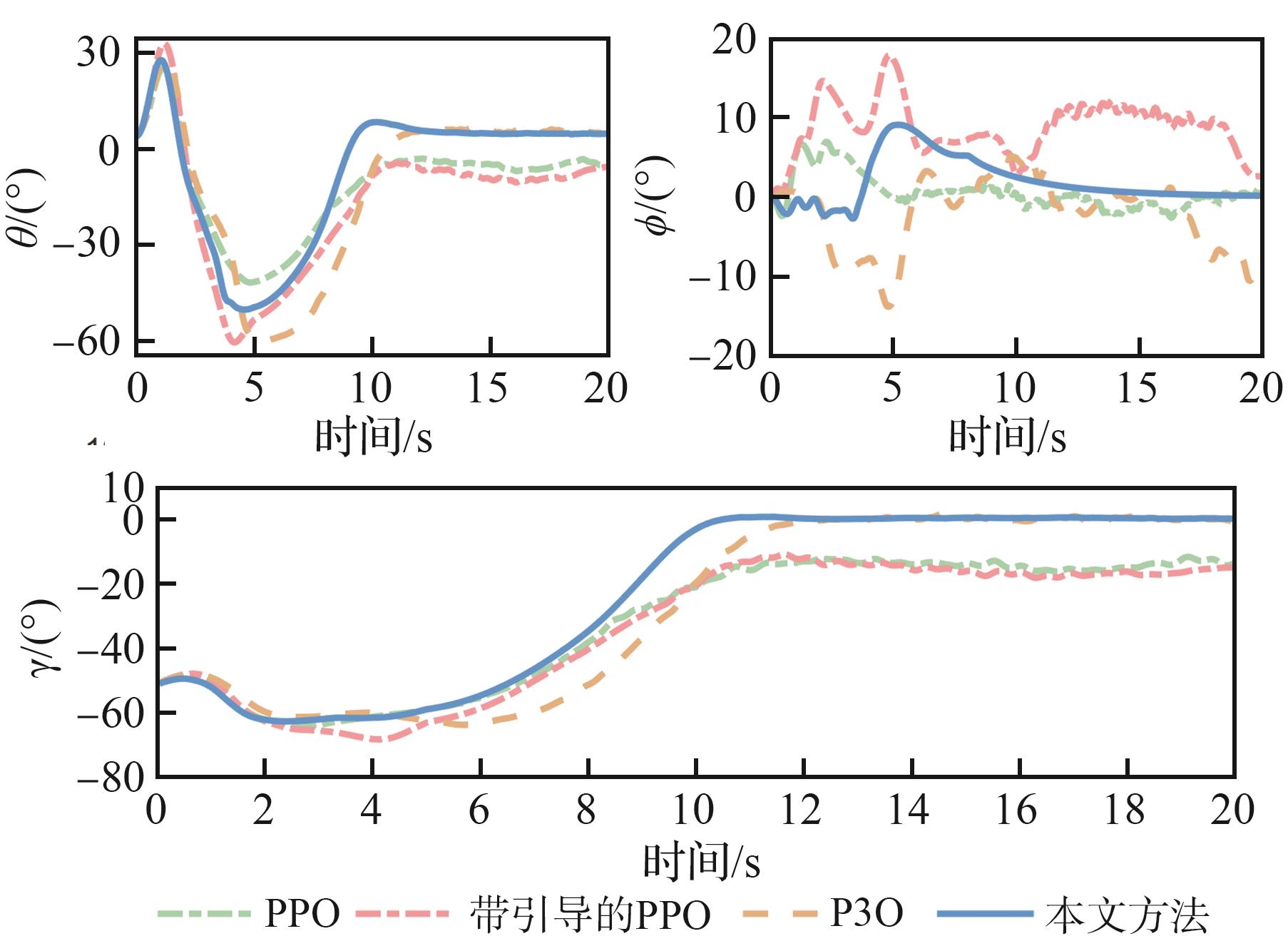
图 15
控制输入对比
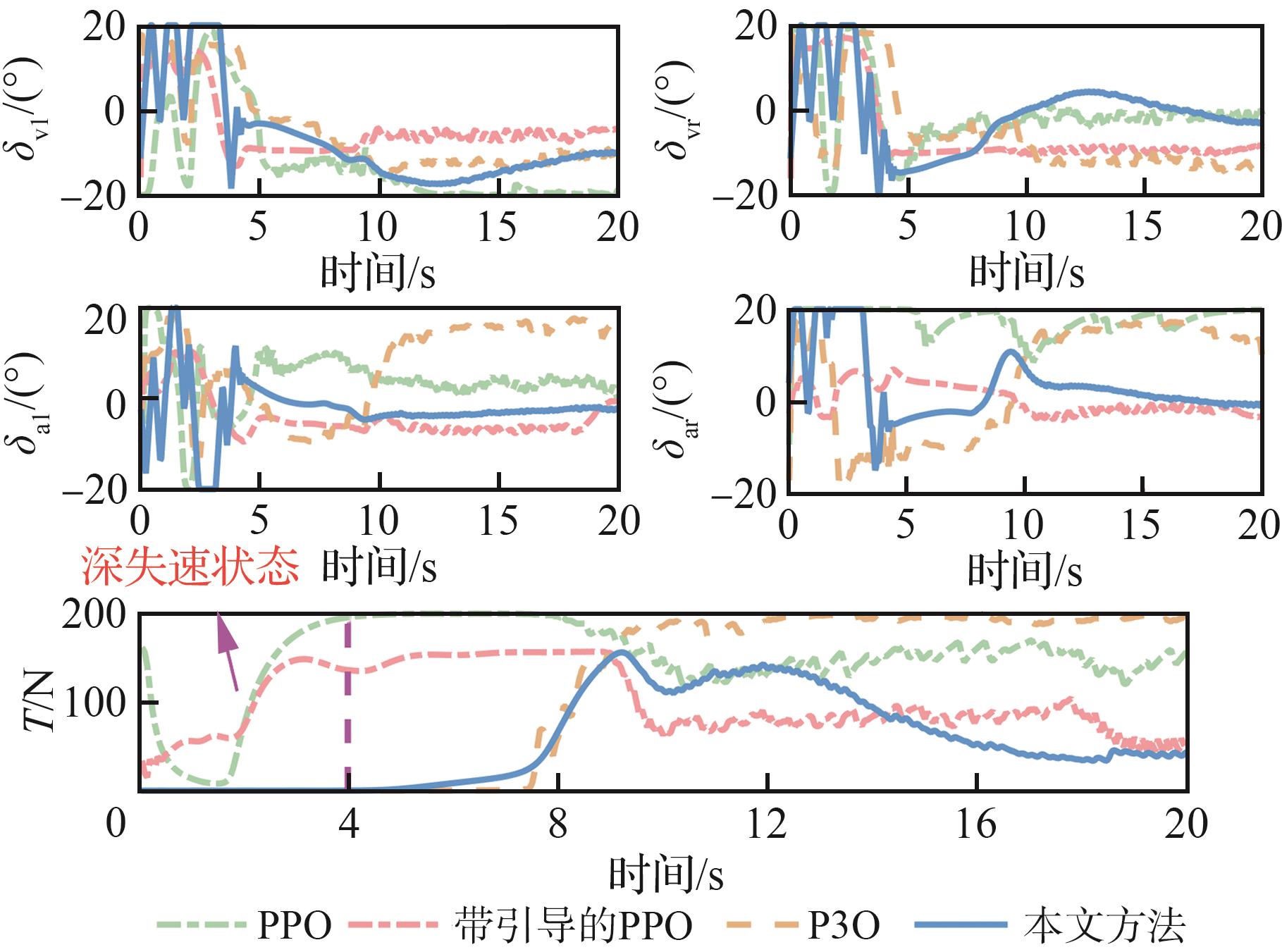

图 16
不同策略下的高度对比


图 17
不同策略下的迎角对比
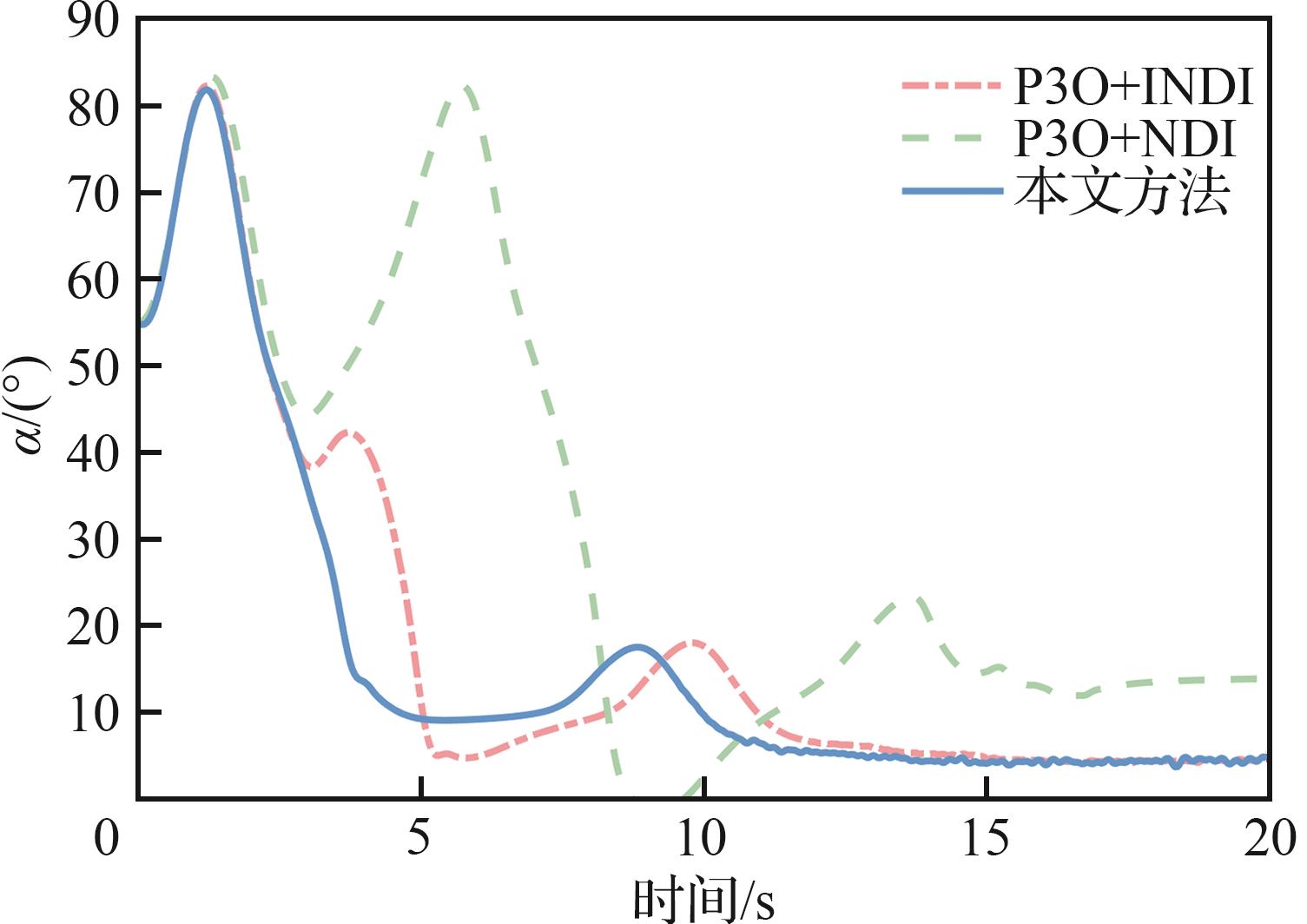
图 18
不同策略下的迎角相平面特性对比
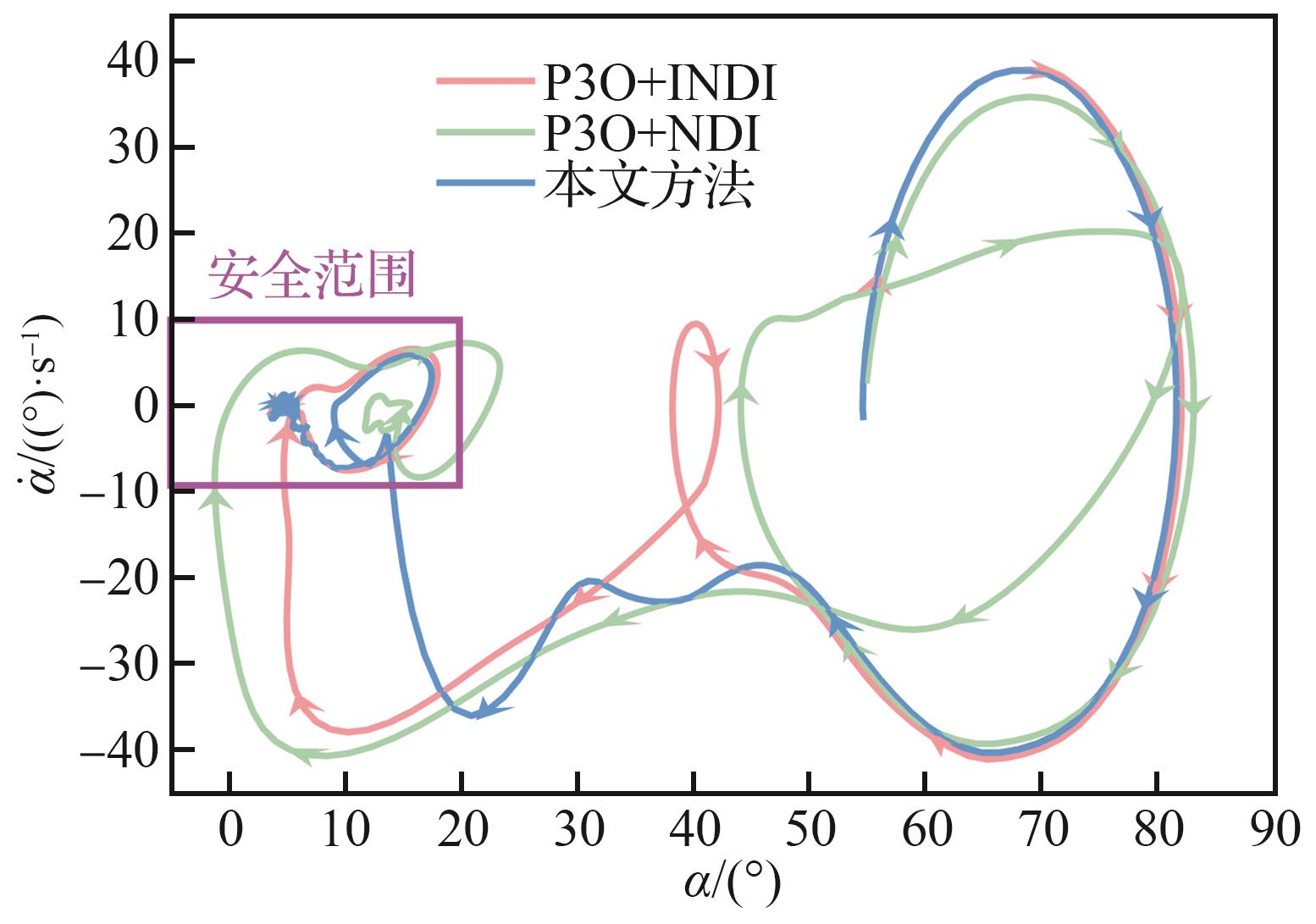
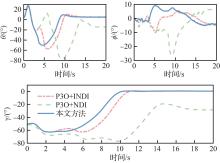
图 19
不同策略下的飞机状态对比


图 20
不同策略下的舵面和推力对比


图 21
Monte Carlo仿真结果

表 3
舵面偏转统计
| 舵面 | 改出过程平均出舵量/( | 标准差/( |
|---|---|---|
| 14.85 | 2.78 | |
| 15.35 | 3.53 | |
| 13.86 | 2.56 | |
| 11.95 | 1.89 |
| [1] | TAYLOR R T, RAY E J. Deep-stall aerodynamic characteristics of T-tail aircraft[R]. Washington, D.C.: NASA, 1965. |
| [2] | NGUYEN D H, LOWENBERG M H, NEILD S A. Analysing dynamic deep stall recovery using a nonlinear frequency approach[J]. Nonlinear Dynamics, 2022, 108(2): 1179-1196. |
| [3] | 陈永亮, 沈宏良, 刘昶. 飞机深失速改出特性分析与控制[J]. 南京航空航天大学学报, 2007, 39(4): 435-439. |
| CHEN Y L, SHEN H L, LIU C. Analysis and control of aircraft deep stall recovery characteristics[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2007, 39(4): 435-439 (in Chinese). | |
| [4] | 艾文磊. 歼击机深失速特性分析及改出控制研究[D]. 南京: 南京航空航天大学, 2015. |
| AI W L. Characteristics analysis and recovery control for deep-stall of fighters[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2015 (in Chinese). | |
| [5] | TRUBSHAW E B. Low speed handling with special reference to the super stall[J]. Journal of the Royal Aeronautical Society, 1966, 70(667): 695-704. |
| [6] | ILOPUTAIFE O I. Design of deep stall protection for the C-17A[J]. Journal of Guidance, Control, and Dynamics, 1997, 20(4): 760-767. |
| [7] | DEFAZIO P A, LARSEN R. Final committee report on the design, development, and certification of the boeing 737 max [EB/OL]. (2020-09-16)[2025-05-12]. . |
| [8] | JIANG H T, XIONG H, ZENG W F, et al. Safely learn to fly aircraft from human: An offline-online reinforcement learning strategy and its application to aircraft stall recovery[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(6): 8194-8207. |
| [9] | SINGH TOMAR D, GAUCI J, DINGLI A, et al. Automated aircraft stall recovery using reinforcement learning and supervised learning techniques[C]∥2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC). Piscataway: IEEE Press, 2021. |
| [10] | KOOPMAN C, ZAMMIT-MANGION D. Using reinforcement learning for AI systems in the mitigation of automation failures and stall recovery in complex aircraft[C]∥ AIAA SciTech 2024 Forum. Reston: AIAA, 2024. |
| [11] | GRILLO A, TORRE G, BUNGE R. Optimal stall recovery via deep reinforcement learning for a general aviation aircraft[C]∥ AIAA SciTech 2024 Forum. Reston: AIAA, 2024. |
| [12] | 李煜, 陈通文, 王志刚, 等. 基于预定义时间的直接升力着舰增量控制[J]. 航空学报, 2025, 46(13): 531163. |
| LI Y, CHEN T W, WANG Z G, et al. Incremental control of direct lift landing based on predefined-time theory[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531163 (in Chinese). | |
| [13] | 罗飞, 张军红, 王博, 等. 基于直接升力与动态逆的舰尾流抑制方法[J]. 航空学报, 2021, 42(12): 124770. |
| LUO F, ZHANG J H, WANG B, et al. Air wake suppression method based on direct lift and nonlinear dynamic inversion control[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(12): 124770 (in Chinese). | |
| [14] | KOLB S, HÉTRU L, FAURE T M, et al. Nonlinear analysis and control of an aircraft in the neighbourhood of deep stall[J]. AIP Conference Proceedings, 2017, 1798: 020080. |
| [15] | LI Y, WEN C Y, LIU X X, et al. Prescribed-time fault-tolerant flight control for aircraft subject to structural damage[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 1848-1859. |
| [16] | 吴慈航, 闫建国, 钱先云, 等. 受油机指定时间姿态稳定控制[J]. 航空学报, 2022, 43(2): 324996. |
| WU C H, YAN J G, QIAN X Y, et al. Predefined-time attitude stabilization control of receiver aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(2): 324996 (in Chinese). | |
| [17] | YE D, ZOU A M, SUN Z W. Predefined-time predefined-bounded attitude tracking control for rigid spacecraft[J]. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(1): 464-472. |
| [18] | LI Y, WANG T Q, LIU X X, et al. Predefined-time active fault-tolerant control of transport aircraft subject to control surface failures[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(3): 5731-5744. |
| [19] | TIAN D P, SHEN H H, DAI M. Improving the rapidity of nonlinear tracking differentiator via feedforward[J]. IEEE Transactions on Industrial Electronics, 2014, 61(7): 3736-3743. |
| [20] | KHALIL H K. Nonlinear system[M]. 3rd ed. Englewood Cliffs: Prentice-Hall, 2002:5-10. |
| [21] | YU X, WU Z J. Stochastic barbalat’s lemma and its applications[J]. IEEE Transactions on Automatic Control, 2012, 57(6): 1537-1543. |
| [22] | ZHANG L R, SHEN L, YANG L, et al. Penalized proximal policy optimization for safe reinforcement learning [EB/OL]. arXiv preprint: 2205.11814, 2022. |
| [23] | JOHN S, PHILIPP M, SERGEY L, et al. High-dimensional continuous control using generalized advantage estimation [EB/OL]. arXiv preprint: 1506.02438, 2016. |
| [24] | KINGMA D P, JIMMY B. Adam: A method for stochastic optimization [EB/OL]. arXiv preprint: 1412.6980, 2017. |
| [25] | SCHULAMN J, MORITZ P, LEVINE S, et, al. High-dimensional continuous control using generalized advantage estimation[C]∥ International Conference on Learning Representations. New York: ACM, 2016. |
| [1] | 周大鹏 甄冲 曲晓雷 罗斐. 考虑舵面效能损失的着舰主被动复合容错控制研究[J]. 航空学报, 0, (): 1-0. |
| [2] | 罗飞 蒋彪 胡志勇 刘海良 高怡宁 张军红 苏子康. 硬杆加油装置空中对接先进控制器设计与风洞试验[J]. 航空学报, 0, (): 1-0. |
| [3] | 谭高澎 王晓芳 林海. 考虑视场角约束的突防打击一体化智能决策算法[J]. 航空学报, 0, (): 1-0. |
| [4] | 刘洋 李妮 于泽熙 贾尚杰. 融合大语言模型技术的飞机编队行为智能建模[J]. 航空学报, 0, (): 1-0. |
| [5] | 卢园 张柯 姜斌. 基于全驱系统方法的直升机分层容错编队控制(飞行器安全控制专栏)[J]. 航空学报, 0, (): 1-0. |
| [6] | 杨彬 卞俊 章健淳 郭克信 杨懿. 多源风险因素下多无人机分布式安全协同控制(2026增刊1,集群会议增刊,会议投稿号:20250370)[J]. 航空学报, 0, (): 1-0. |
| [7] | 荣尔超, 张钰迎, 梁峻宁, 吕熙敏. 基于神经网络气动NMPC的尾座式VTOL无人机轨迹跟踪控制[J]. 航空学报, 2025, 46(24): 331995-331995. |
| [8] | 严国乘, 王宏伦, 王延祥, 伦岳斌, 朱俊帆. 无人机拖曳式空中回收机翼折叠过程预设性能抗摆动控制[J]. 航空学报, 2025, 46(24): 331840-331840. |
| [9] | 贺炅, 任斌武, 杜思亮, 徐尤松, 王博. 基于ADRC-RBF倾转四旋翼无人机姿态自适应控制[J]. 航空学报, 2025, 46(S1): 732189-732189. |
| [10] | 周攀, 李霓, 黄江涛, 杨青林, 廉云霄. 非完备信息下无人机近距博弈自主决策[J]. 航空学报, 2025, 46(S1): 732215-732215. |
| [11] | 贺之豪, 寇鹏, 梁博华, 梁得亮. 考虑滑流效应的分布式电推进飞机动力偏航预测控制[J]. 航空学报, 2025, 46(S1): 732305-732305. |
| [12] | 李钊星 杨林 王霞 许斌. 基于强迫振荡的战斗机有限时间深失速改出控制(飞行器安全控制专栏)[J]. 航空学报, 0, (): 1-0. |
| [13] | 徐体超 蒙文跃 张健. 基于多目标强化学习的太阳能无人机航迹规划[J]. 航空学报, 0, (): 1-0. |
| [14] | 李文博 周志杰 王兆强 冯志超 孙一杰 张心怡. 融合多源信息的电液伺服机构健康评估[J]. 航空学报, 0, (): 1-0. |
| [15] | 宋怡成, 齐瑞云, 姜斌. 通信故障下无人机编队网络分布式拓扑重构[J]. 航空学报, 2025, 46(22): 331914-331914. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 航空学报编辑部
版权所有 © 2011航空学报杂志社
主管单位:中国科学技术协会 主办单位:中国航空学会 北京航空航天大学