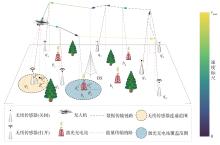
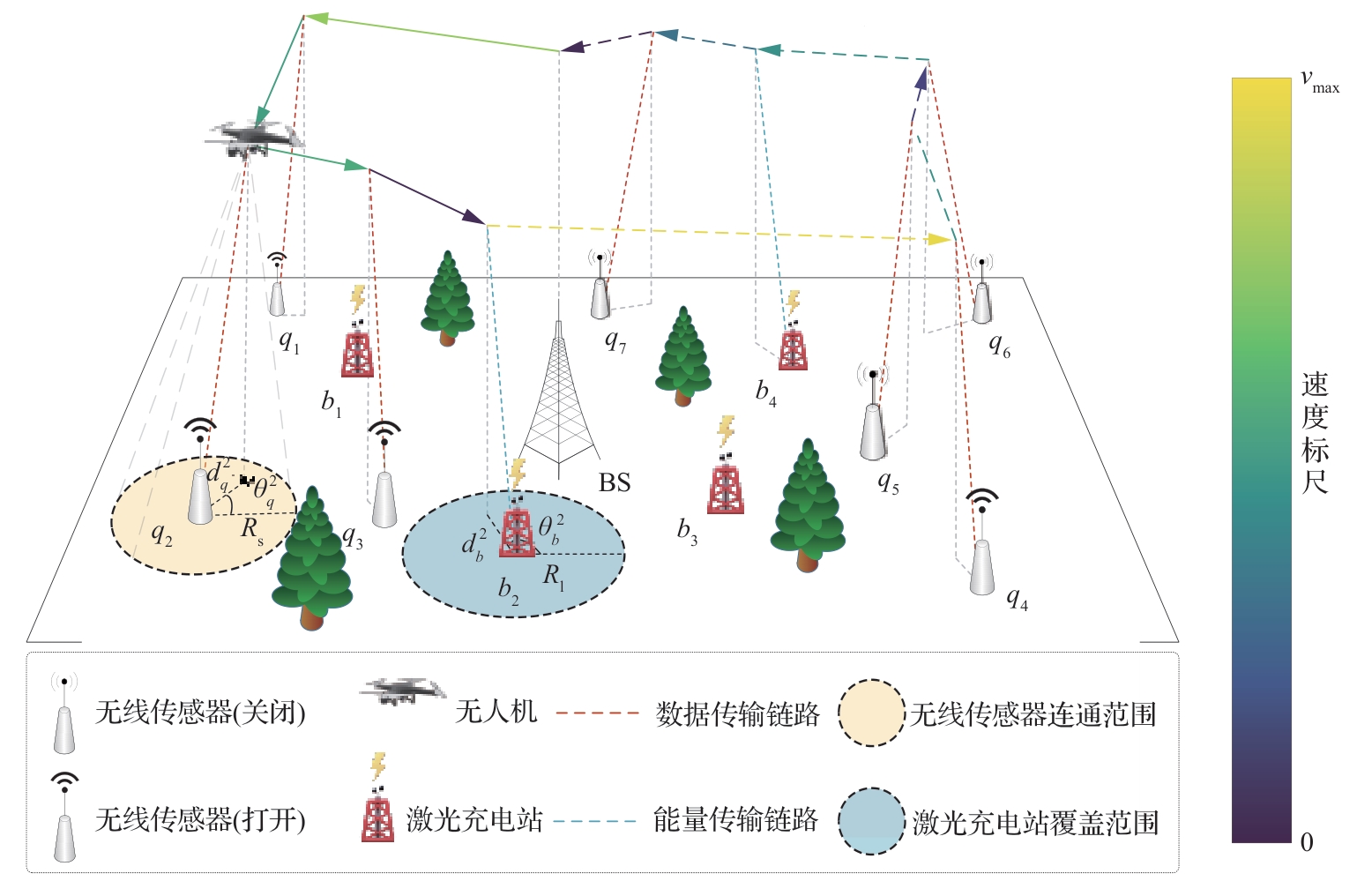
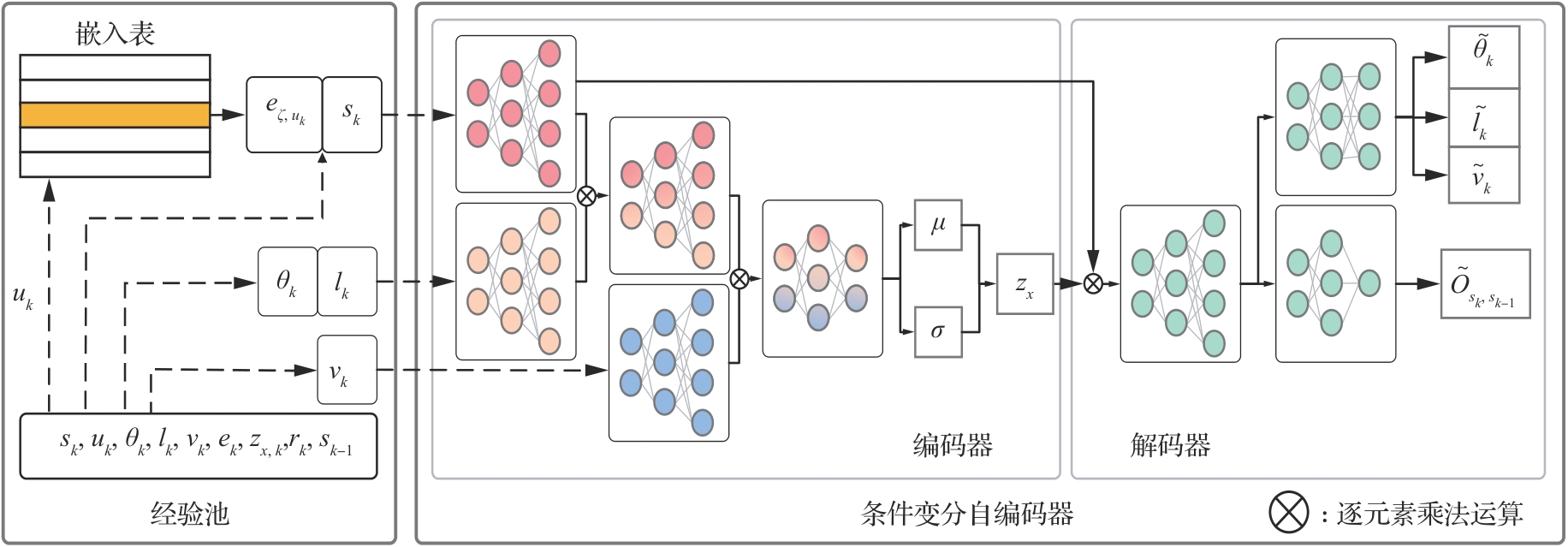
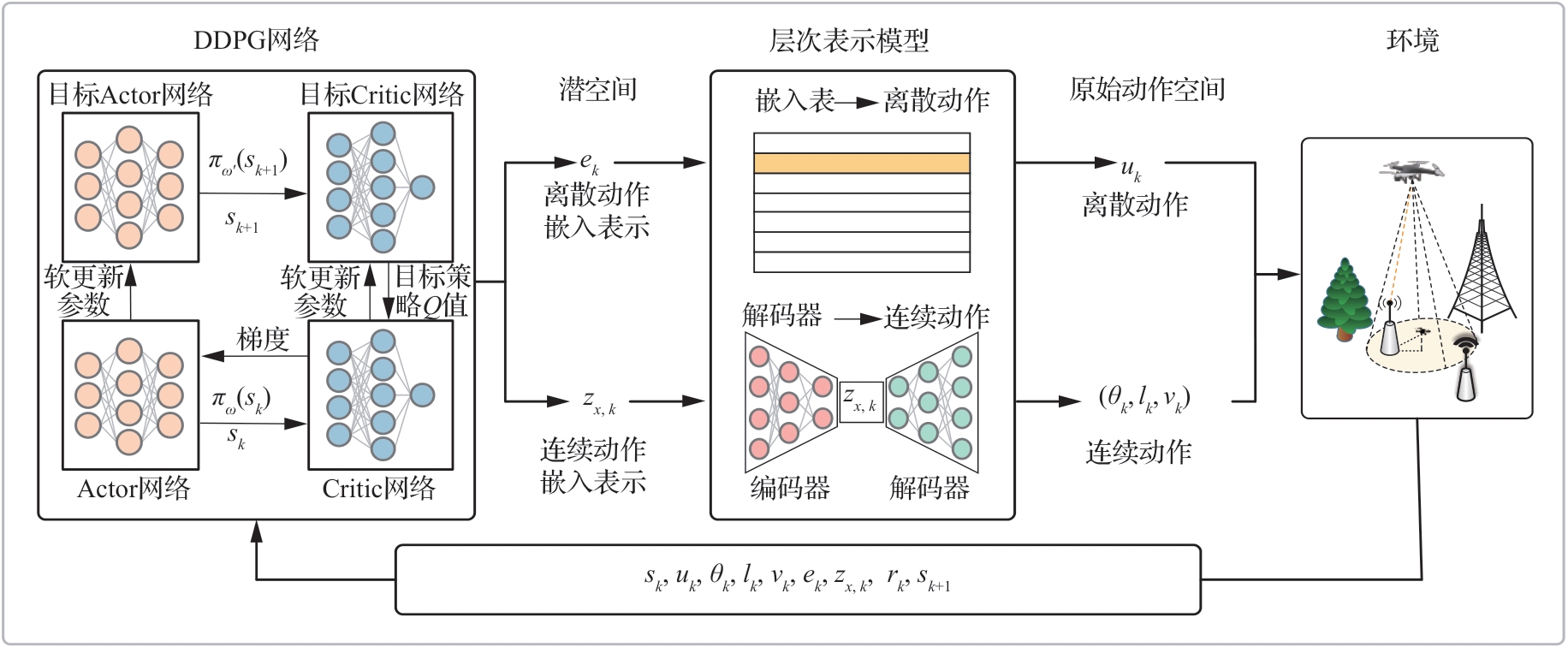
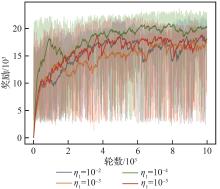
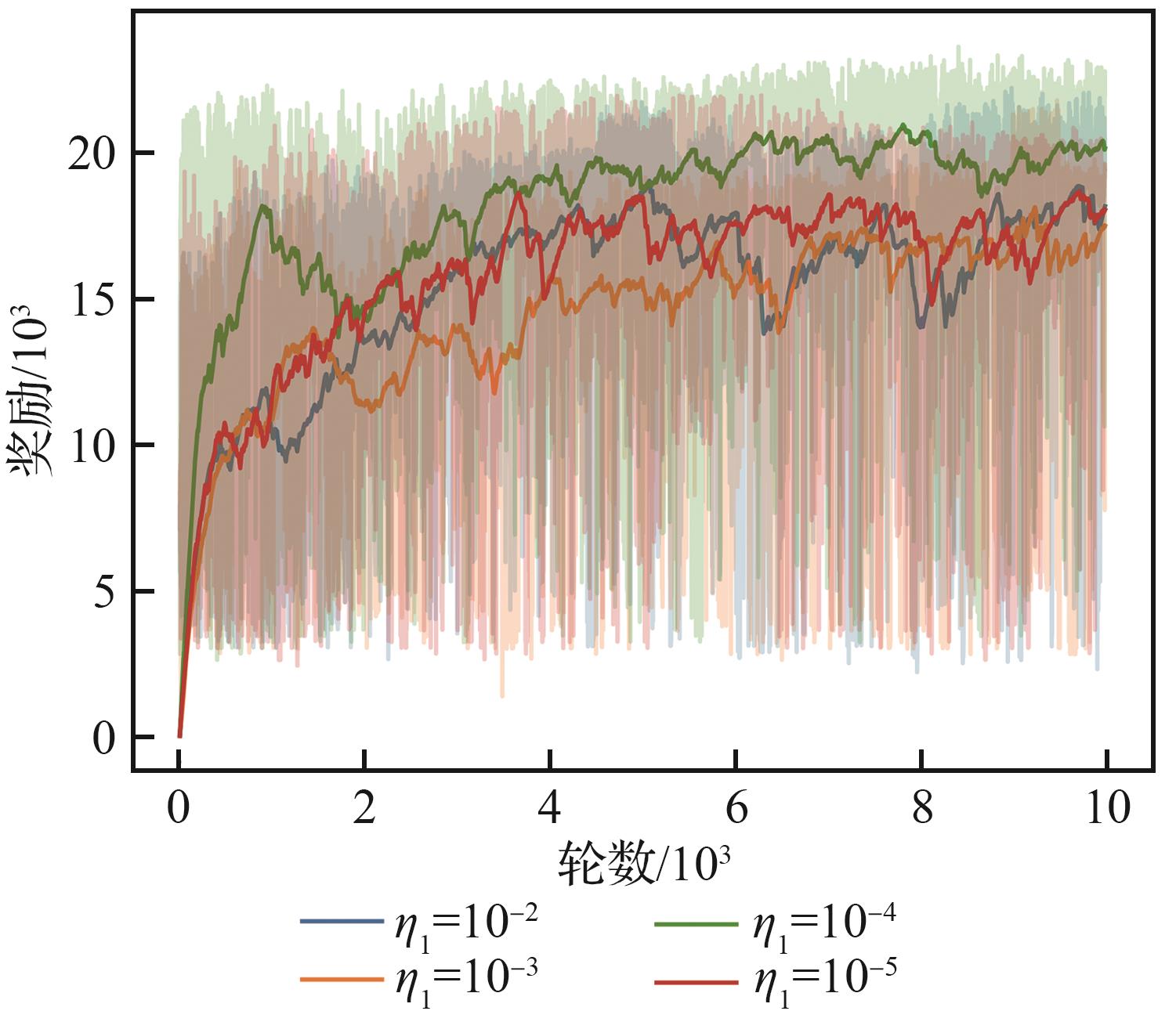
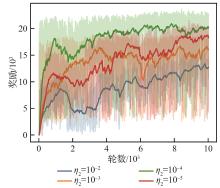
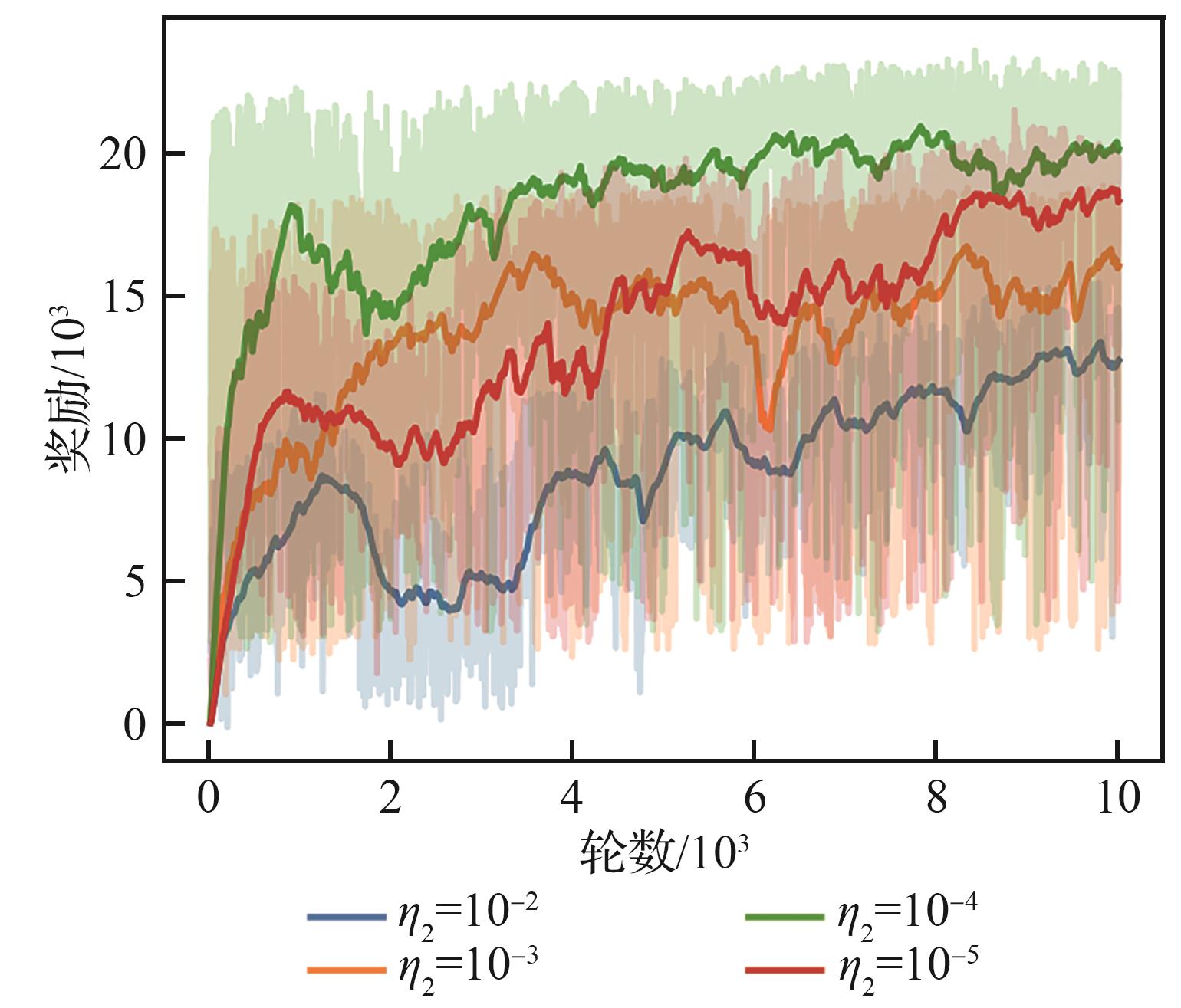
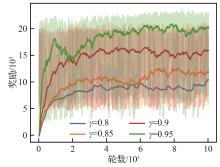
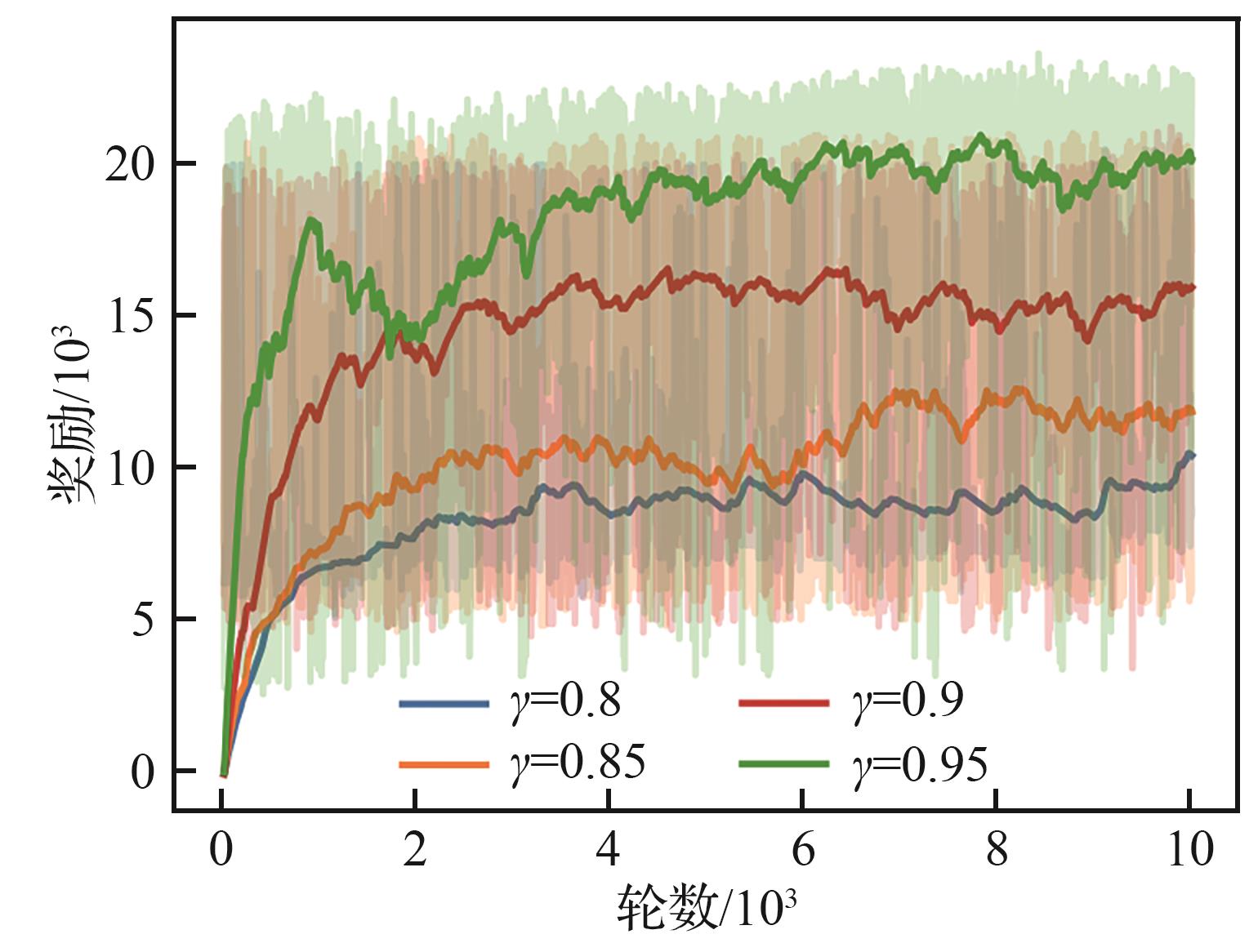
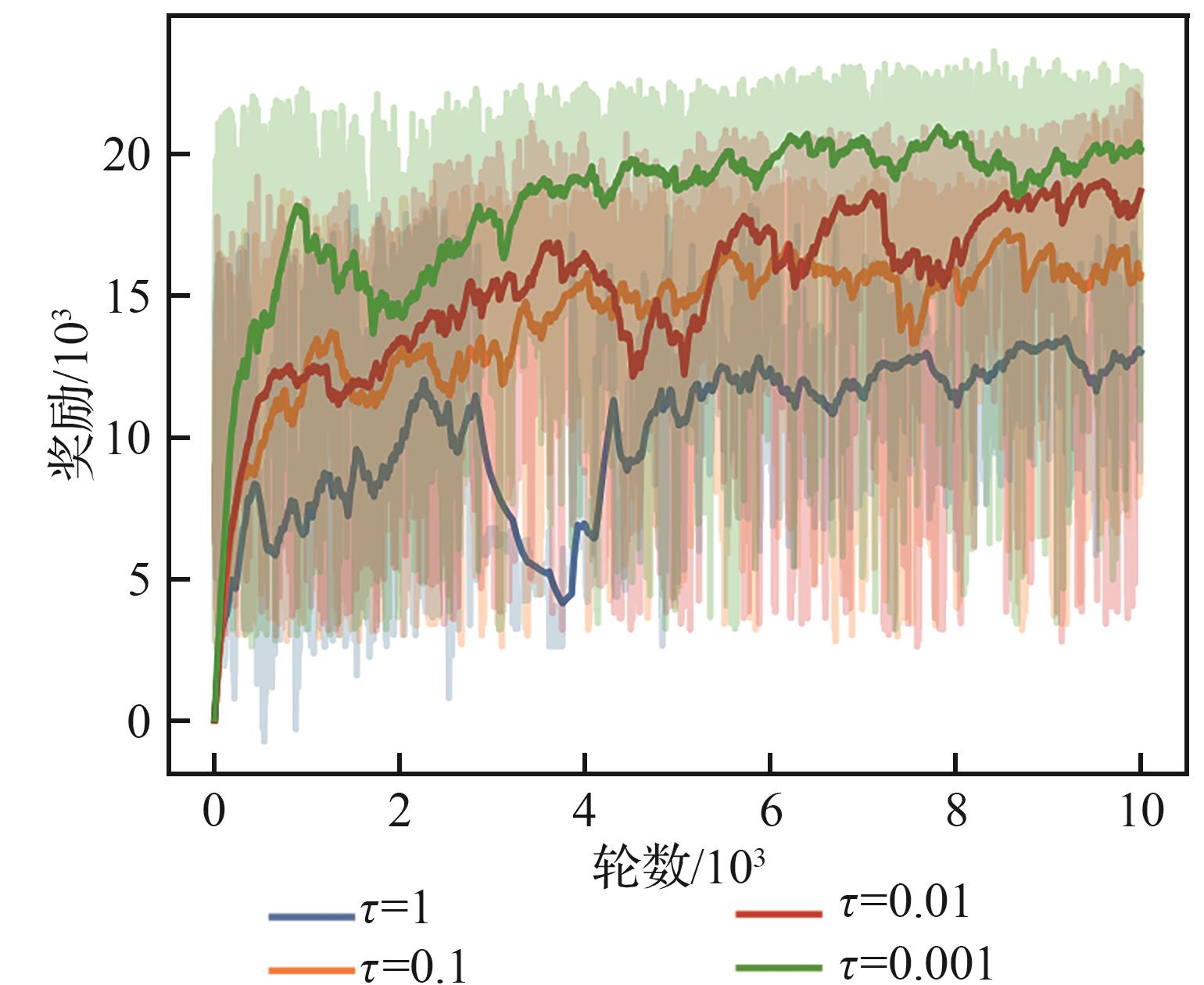
| [1] |
YANG M, BI W H, ZHANG A, et al. A distributed task reassignment method in dynamic environment for multi-UAV system[J]. Applied Intelligence, 2022, 52(2): 1582-1601.
|
| [2] |
SAMIR M, SHARAFEDDINE S, ASSI C M, et al. UAV trajectory planning for data collection from time-constrained IoT devices[J]. IEEE Transactions on Wireless Communications, 2020, 19(1): 34-46.
|
| [3] |
CUI W, LI R L, FENG Y X, et al. Distributed task allocation for a multi-UAV system with time window constraints[J]. Drones, 2022, 6(9): 226.
|
| [4] |
WAN P F, WANG S K, XU G Y, et al. Hybrid heuristic-based multi-UAV route planning for time-dependent data collection[J]. IEEE Internet of Things Journal, 2024, 11(13): 24134-24147.
|
| [5] |
CHAPNEVIS A, BULUT E. Time-efficient approximate trajectory planning for AoI-centered multi-UAV IoT networks[J]. Internet of Things, 2025, 29: 101461.
|
| [6] |
张薇, 何若俊. 面向物联网数据收集的无人机自主路径规划[J]. 航空学报, 2024, 45(8): 329054.
|
|
ZHANG W, HE R J. Autonomous trajectory design for IoT data collection by UAV[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329054 (in Chinese).
|
| [7] |
KUO H A, SHEU J P, VAN CUONG N. Profit maximization for UAV trajectory planning in time-constrained data collection[C]∥ICC 2023-IEEE International Conference on Communications. Piscataway: IEEE Press, 2023: 5413-5418.
|
| [8] |
LIU K, ZHENG J. UAV trajectory planning with interference awareness in UAV-enabled time-constrained data collection systems[J]. IEEE Transactions on Vehicular Technology, 2024, 73(2): 2799-2815.
|
| [9] |
LIAU Y S, HONG Y W P, SHEU J P. Laser-powered UAV trajectory and charging optimization for sustainable data-gathering in the Internet of Things[J]. IEEE Transactions on Mobile Computing, 2025, 24(5): 4278-4295.
|
| [10] |
LUO C W, LIU N, HOU Y N, et al. Trajectory optimization of laser-charged UAV to minimize the average age of information for wireless rechargeable sensor network[J]. Theoretical Computer Science, 2023, 945: 113680.
|
| [11] |
乌兰, 刘全, 黄志刚, 等. 离线强化学习研究综述[J]. 计算机学报, 2025, 48(1): 156-187.
|
|
WU L, LIU Q, HUANG Z G, et al. A review of research on offline reinforcement learning[J]. Chinese Journal of Computers, 2025, 48(1): 156-187 (in Chinese).
|
| [12] |
WAN P F, XU G Y, CHEN J W, et al. Deep reinforcement learning enabled multi-UAV scheduling for disaster data collection with time-varying value[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(7): 6691-6702.
|
| [13] |
CAI M, FAN S, XIAO G, et al. Deep reinforcement learning-based UAV path planning algorithm in agricultural time-constrained data collection[J]. Advances in Electrical and Computer Engineering, 2023, 23(2): 101-108.
|
| [14] |
WANG J Y, LI S Y, CHEN D Z, et al. Flight trajectory control with network-oriented hierarchical reinforcement learning for UAVs-assisted data time-sensitive IoT[J]. IEEE Transactions on Intelligent Transportation Systems, 2025, 26(5): 6332-6345.
|
| [15] |
HU Y M, LIU Y, KAUSHIK A, et al. Timely data collection for UAV-based IoT networks: A deep reinforcement learning approach[J]. IEEE Sensors Journal, 2023, 23(11): 12295-12308.
|
| [16] |
BOUHAMED O, GHAZZAI H, BESBES H, et al. A UAV-assisted data collection for wireless sensor networks: Autonomous navigation and scheduling[J]. IEEE Access, 2020, 8: 110446-110460.
|
| [17] |
高思华, 李军辉, 李建伏, 等. 面向公平性数据采集和能量补充的无人机路径规划算法研究[J]. 电子学报, 2024, 52(11): 3699-3710.
|
|
GAO S H, LI J H, LI J F, et al. Research on UAV path planning algorithm for fairness data collection and energy supplement[J]. Acta Electronica Sinica, 2024, 52(11): 3699-3710 (in Chinese).
|
| [18] |
高思华, 刘宝煜, 惠康华, 等. 信息年龄约束下的无人机数据采集能耗优化路径规划算法[J]. 电子与信息学报, 2024, 46(10): 4024-4034.
|
|
GAO S H, LIU B Y, HUI K H, et al. Energy-efficient UAV trajectory planning algorithm for AoI-constrained data collection[J]. Journal of Electronics & Information Technology, 2024, 46(10): 4024-4034 (in Chinese).
|
| [19] |
LI B, TANG H, ZHENG Y, et al. HyAR: Addressing discrete-continuous action reinforcement learning via hybrid action representation[DB/OL]. arXiv preprint: 2109.05490, 2021.
|
| [20] |
YU Y, TANG J, HUANG J Y, et al. Multi-objective optimization for UAV-assisted wireless powered IoT networks based on extended DDPG algorithm[J]. IEEE Transactions on Communications, 2021, 69(9): 6361-6374.
|
| [21] |
WEI Z Q, ZHU M Y, ZHANG N, et al. UAV-assisted data collection for Internet of Things: A survey[J]. IEEE Internet of Things Journal, 2022, 9(17): 15460-15483.
|
| [22] |
FU Q Y, JIA R H, LYU F, et al. Collection point matters in time-energy tradeoff for UAV-enabled data collection of IoT devices[J]. IEEE Internet of Things Journal, 2024, 11(19): 31492-31506.
|
| [23] |
GONG H, HUANG B Q, JIA B, et al. Modeling power consumptions for multirotor UAVs[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(6): 7409-7422.
|
| [24] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arXiv preprint: 1707.06347, 2017.
|
| [25] |
LAHMERI M A, KISHK M A, ALOUINI M S. Charging techniques for UAV-assisted data collection: Is laser power beaming the answer?[J]. IEEE Communications Magazine, 2022, 60(5): 50-56.
|
| [26] |
HU H M, XIONG K, QU G, et al. AoI-minimal trajectory planning and data collection in UAV-assisted wireless powered IoT networks[J]. IEEE Internet of Things Journal, 2021, 8(2): 1211-1223.
|
| [27] |
WU M P, SU L J, CHEN J X, et al. Development and prospect of wireless power transfer technology used to power unmanned aerial vehicle[J]. Electronics, 2022, 11(15): 2297.
|
| [28] |
ZHANG Q Q, FANG W, LIU Q W, et al. Distributed laser charging: A wireless power transfer approach[J]. IEEE Internet of Things Journal, 2018, 5(5): 3853-3864.
|
| [29] |
ZENG Y, XU J, ZHANG R. Energy minimization for wireless communication with rotary-wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329-2345.
|
 )
)