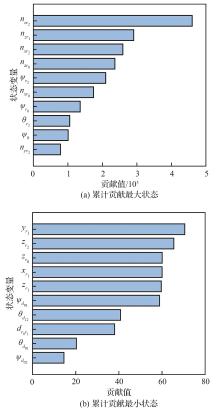
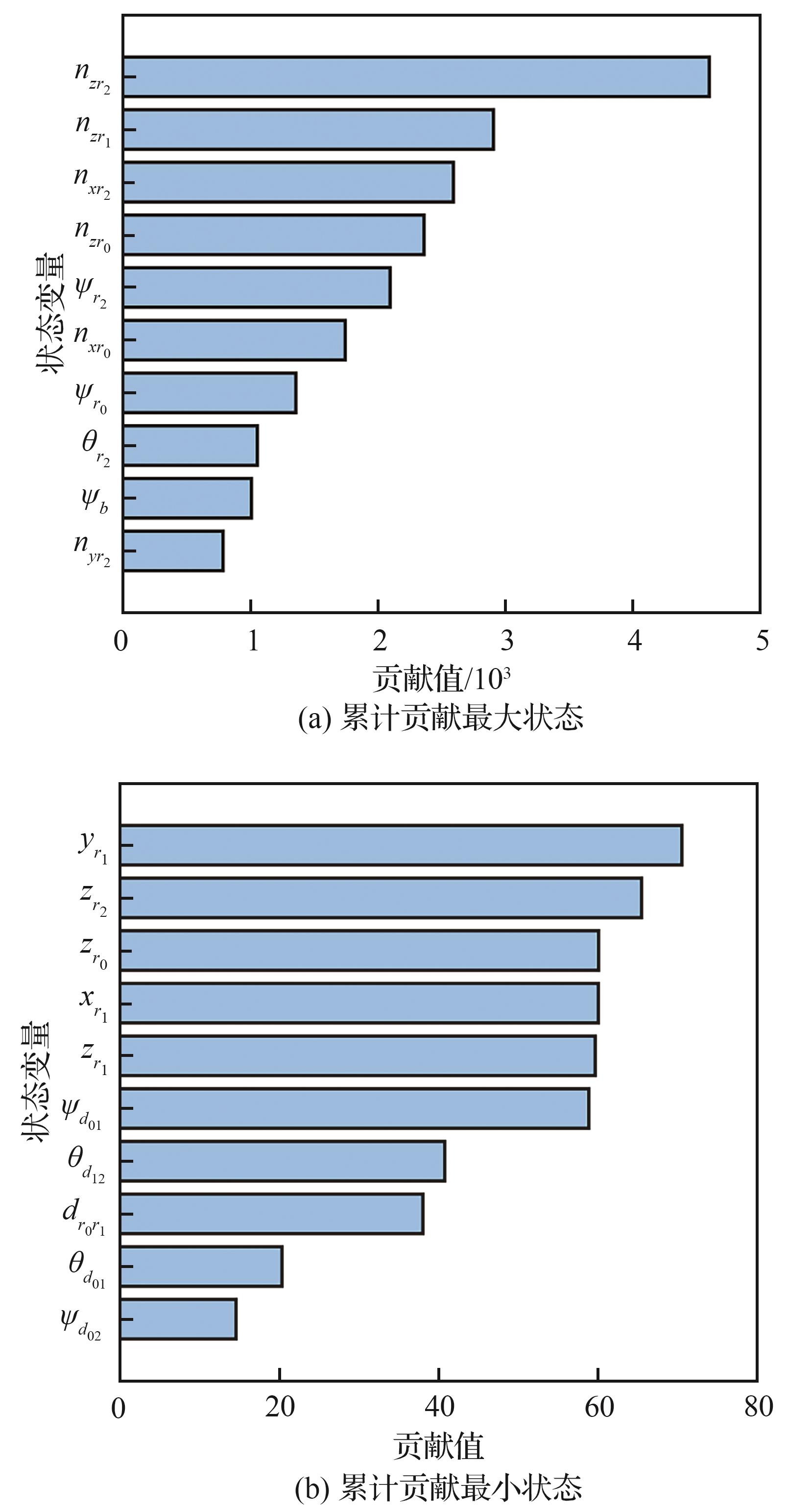
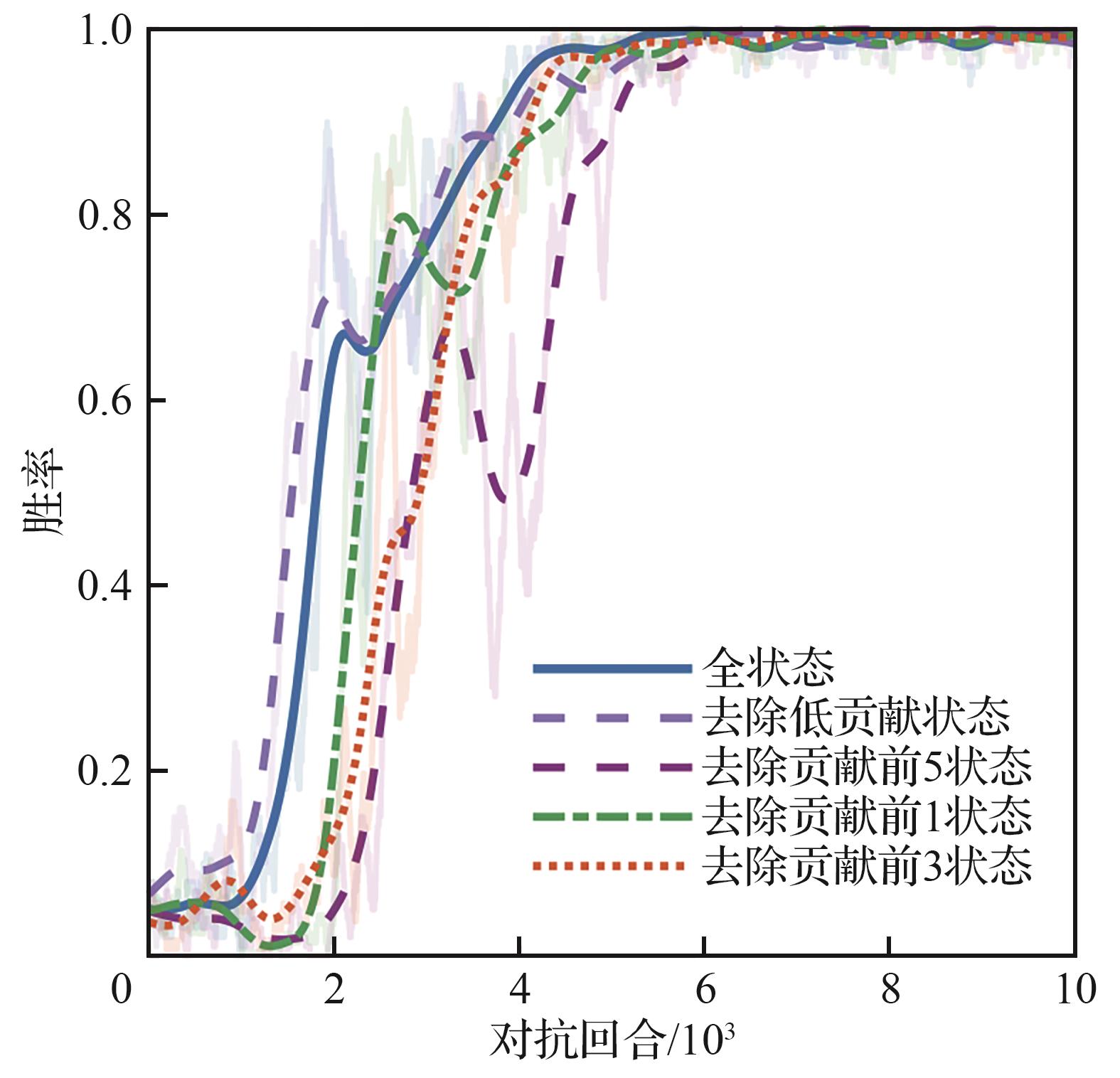
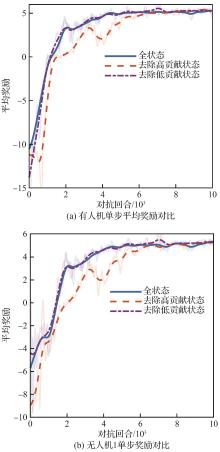
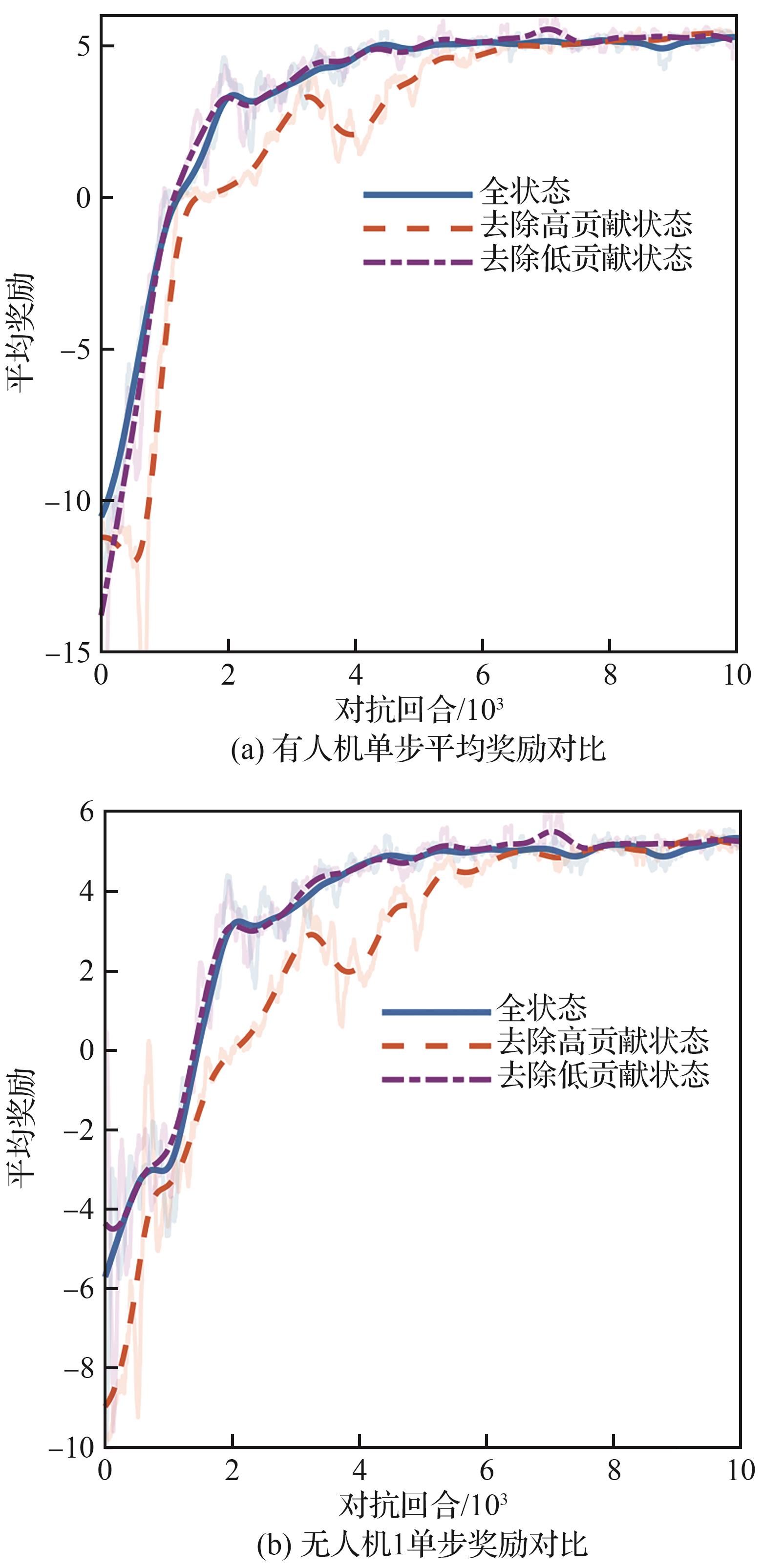
| [1] |
王童豪, 彭星光, 胡浩, 等. 海上有人/无人协同系统及其关键技术综述[J]. 兵工学报, 2024, 45(10): 3317-3340.
|
|
WANG T H, PENG X G, HU H, et al. Maritime manned/unmanned collaborative systems and key technologies: A survey[J]. Acta Armamentarii, 2024, 45(10): 3317-3340 (in Chinese).
|
| [2] |
UNITED STATES DEPARTMENT OF DEFENSE. Unmanned systems integrated roadmap: FY2013-2038[R]. Washington, D.C.: United States Department of Defense, 2013.
|
| [3] |
LI S Y, CHEN M, WANG Y H, et al. A fast algorithm to solve large-scale matrix games based on dimensionality reduction and its application in multiple unmanned combat air vehicles attack-defense decision-making[J]. Information Sciences, 2022, 594: 305-321.
|
| [4] |
RUAN W Y, DUAN H B, DENG Y M. Autonomous maneuver decisions via transfer learning pigeon-inspired optimization for UCAVs in dogfight engagements[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9(9): 1639-1657.
|
| [5] |
ASLAN S, ERKIN T. A multi-population immune plasma algorithm for path planning of unmanned combat aerial vehicle[J]. Advanced Engineering Informatics, 2023, 55: 101829.
|
| [6] |
FU Y F, LIU D, CHEN J D, et al. Secretary bird optimization algorithm: A new metaheuristic for solving global optimization problems[J]. Artificial Intelligence Review, 2024, 57(5): 123.
|
| [7] |
PIAO H Y, HAN Y, CHEN H C, et al. Complex relationship graph abstraction for autonomous air combat collaboration: A learning and expert knowledge hybrid approach[J]. Expert Systems with Applications, 2023, 215: 119285.
|
| [8] |
LI B, HUANG J Y, BAI S X, et al. Autonomous air combat decision-making of UAV based on parallel self-play reinforcement learning[J]. CAAI Transactions on Intelligence Technology, 2023, 8(1): 64-81.
|
| [9] |
KAUFMANN E, BAUERSFELD L, LOQUERCIO A, et al. Champion-level drone racing using deep reinforcement learning[J]. Nature, 2023, 620(7976): 982-987.
|
| [10] |
CHAI J J, CHEN W Z, ZHU Y H, et al. A hierarchical deep reinforcement learning framework for 6-DOF UCAV air-to-air combat[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2023, 53(9): 5417-5429.
|
| [11] |
LI B, BAI S X, LIANG S Y, et al. Manoeuvre decision-making of unmanned aerial vehicles in air combat based on an expert actor-based soft actor critic algorithm[J]. CAAI Transactions on Intelligence Technology, 2023, 8(4): 1608-1619.
|
| [12] |
李佐龙, 朱纪洪, 匡敏驰, 等. 基于混合动作的空战分层强化学习决策算法[J]. 航空学报, 2024, 45(17): 530053.
|
|
LI Z L, ZHU J H, KUANG M C, et al. Hierarchical decision algorithm for air combat with hybrid action based on deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(17): 530053 (in Chinese).
|
| [13] |
WANG E S, LIU F, HONG C, et al. MADRL-based UAV swarm non-cooperative game under incomplete information[J]. Chinese Journal of Aeronautics, 2024, 37(6): 293-306.
|
| [14] |
李樾, 韩维, 陈清阳, 等. 凸优化算法在有人/无人机协同系统航迹规划中的应用[J]. 宇航学报, 2020, 41(3): 276-286.
|
|
LI Y, HAN W, CHEN Q Y, et al. Application of convex optimization algorithm in trajectory planning of manned/unmanned cooperative system[J]. Journal of Astronautics, 2020, 41(3): 276-286 (in Chinese).
|
| [15] |
HUO M Z, DUAN H B. Three-dimension cluster space formation control of manned/unmanned aerial team subject to input constraint[J]. IEEE Transactions on Industrial Informatics, 2024, 20(6): 8596-8604.
|
| [16] |
HE H X, DUAN H B, YUAN W M, et al. A potential game approach to target assignment in heterogeneous manned/unmanned aerial team with incomplete information[J]. IEEE Transactions on Circuits and Systems Ⅱ: Express Briefs, 2024, 71(12): 4894-4898.
|
| [17] |
熊威, 张栋, 任智, 等. 面向有人/无人机协同打击的智能决策方法研究[J]. 系统工程与电子技术, 2025, 47(4): 1285-1299.
|
|
XIONG W, ZHANG D, REN Z, et al. Research on intelligent decision-making methods for coordinated attack by manned aerial vehicles and unmanned aerial vehicles[J]. Systems Engineering and Electronics, 2025, 47(4): 1285-1299 (in Chinese).
|
| [18] |
VOUROS G A. Explainable deep reinforcement learning: state of the art and challenges[J]. ACM Computing Surveys, 2023, 55(5): 1-39.
|
| [19] |
杨书恒, 张栋, 熊威, 等. 基于可解释性强化学习的空战机动决策方法[J]. 航空学报, 2024, 45(18): 329922.
|
|
YANG S H, ZHANG D, XIONG W, et al. Decision-making method for air combat maneuver based on explainable reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(18): 329922 (in Chinese).
|
| [20] |
AKROUR R, TATEO D, PETERS J. Continuous action reinforcement learning from a mixture of interpretable experts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(10): 6795-6806.
|
| [21] |
WANG C, WU L Z, YAN C, et al. Coactive design of explainable agent-based task planning and deep reinforcement learning for human-UAVs teamwork[J]. Chinese Journal of Aeronautics, 2020, 33(11): 2930-2945.
|
| [22] |
SOARES E, ANGELOV P P, COSTA B, et al. Explaining deep learning models through rule-based approximation and visualization[J]. IEEE Transactions on Fuzzy Systems, 2021, 29(8): 2399-2407.
|
| [23] |
ÇETIN E, BARRADO C, SALAMÍ E, et al. Analyzing deep reinforcement learning model decisions with Shapley additive explanations for counter drone operations[J]. Applied Intelligence, 2024, 54(23): 12095-12111.
|
| [24] |
HE L, AOUF N, SONG B F. Explainable Deep Reinforcement Learning for UAV autonomous path planning[J]. Aerospace Science and Technology, 2021, 118: 107052.
|
| [25] |
HICKLING T, ZENATI A, AOUF N, et al. Explainability in deep reinforcement learning: A review into current methods and applications[J]. ACM Computing Surveys, 2023, 56(5): 1-35.
|
| [26] |
ZHOU Y T, KONG X R, LIN K P, et al. Novel task decomposed multi-agent twin delayed deep deterministic policy gradient algorithm for multi-UAV autonomous path planning[J]. Knowledge-Based Systems, 2024, 287: 111462.
|
| [27] |
AUSTIN F, CARBONE G, FALCO M, et al. Automated maneuvering decisions for air-to-air combat:AIAA-1987-2393[R]. Reston: AIAA, 1987.
|
| [28] |
ŠTRUMBELJ E, KONONENKO I. Explaining prediction models and individual predictions with feature contributions[J]. Knowledge and Information Systems, 2014, 41(3): 647-665.
|
| [29] |
HEUILLET A, COUTHOUIS F, DÍAZ-RODRÍGUEZ N. Collective Explainable AI: Explaining cooperative strategies and agent contribution in multiagent reinforcement learning with shapley values[J]. IEEE Computational Intelligence Magazine, 2022, 17(1): 59-71.
|
 ), 杨书恒1, 任智1, 刘文逸2
), 杨书恒1, 任智1, 刘文逸2