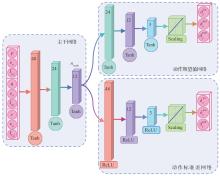
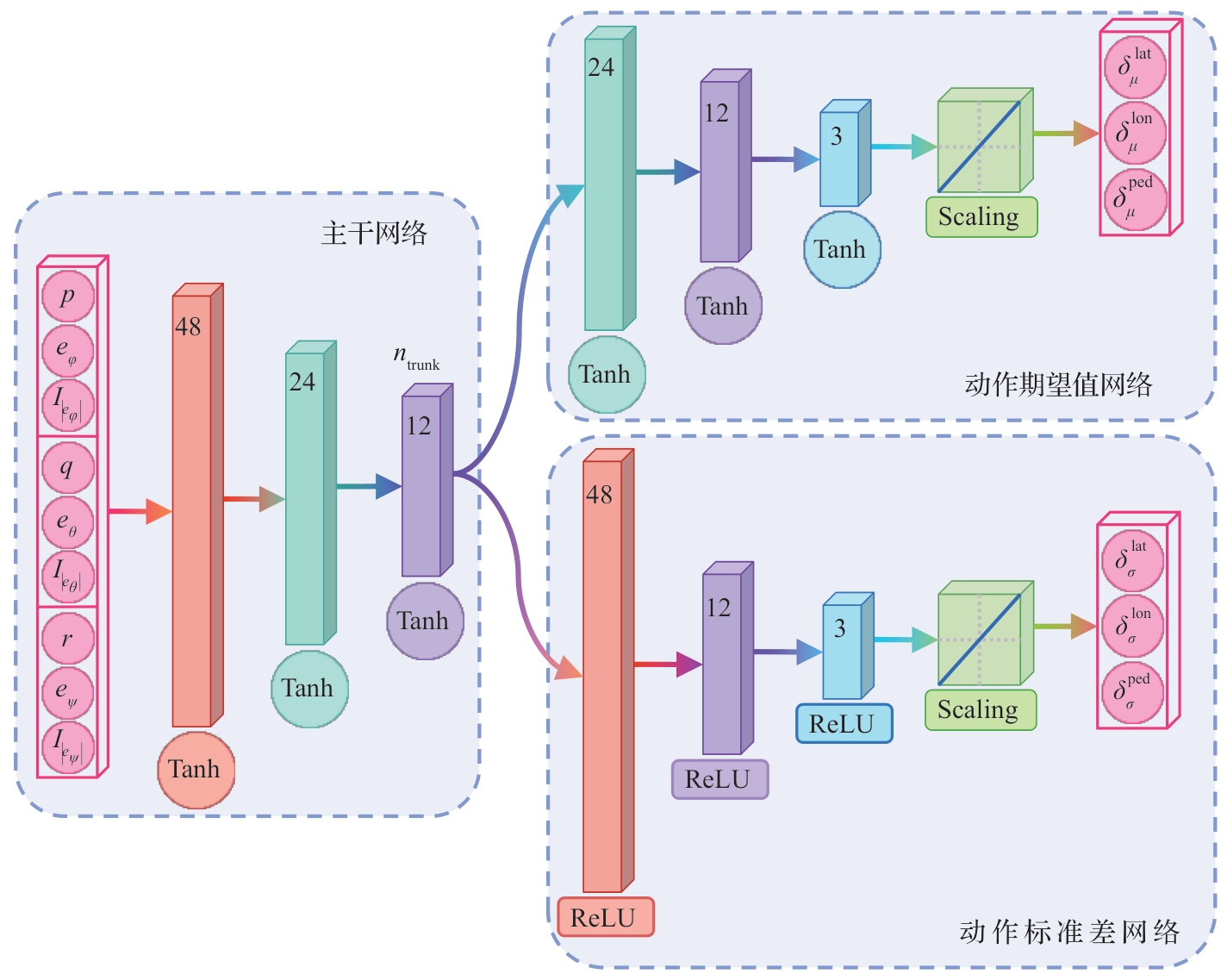
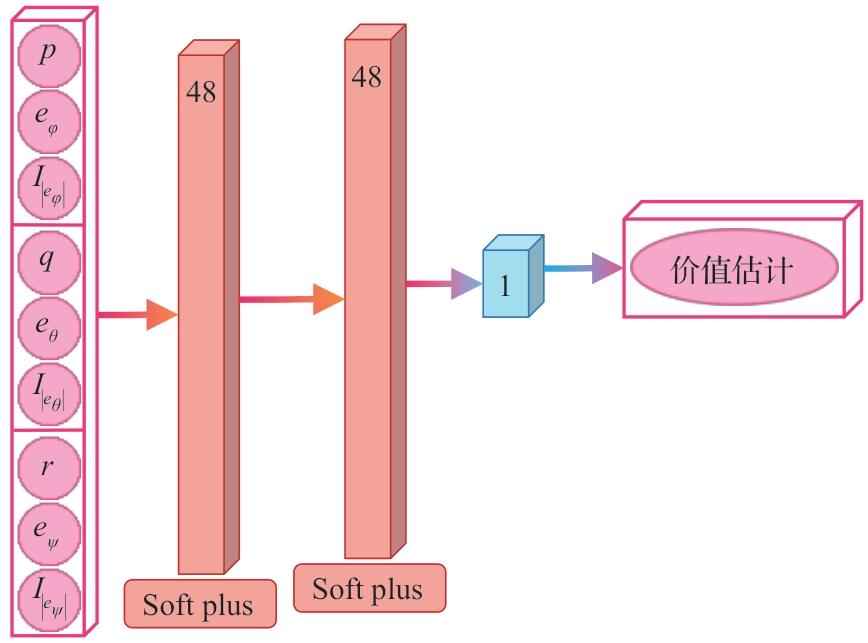
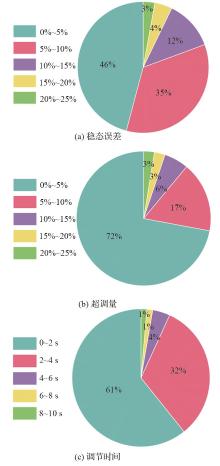
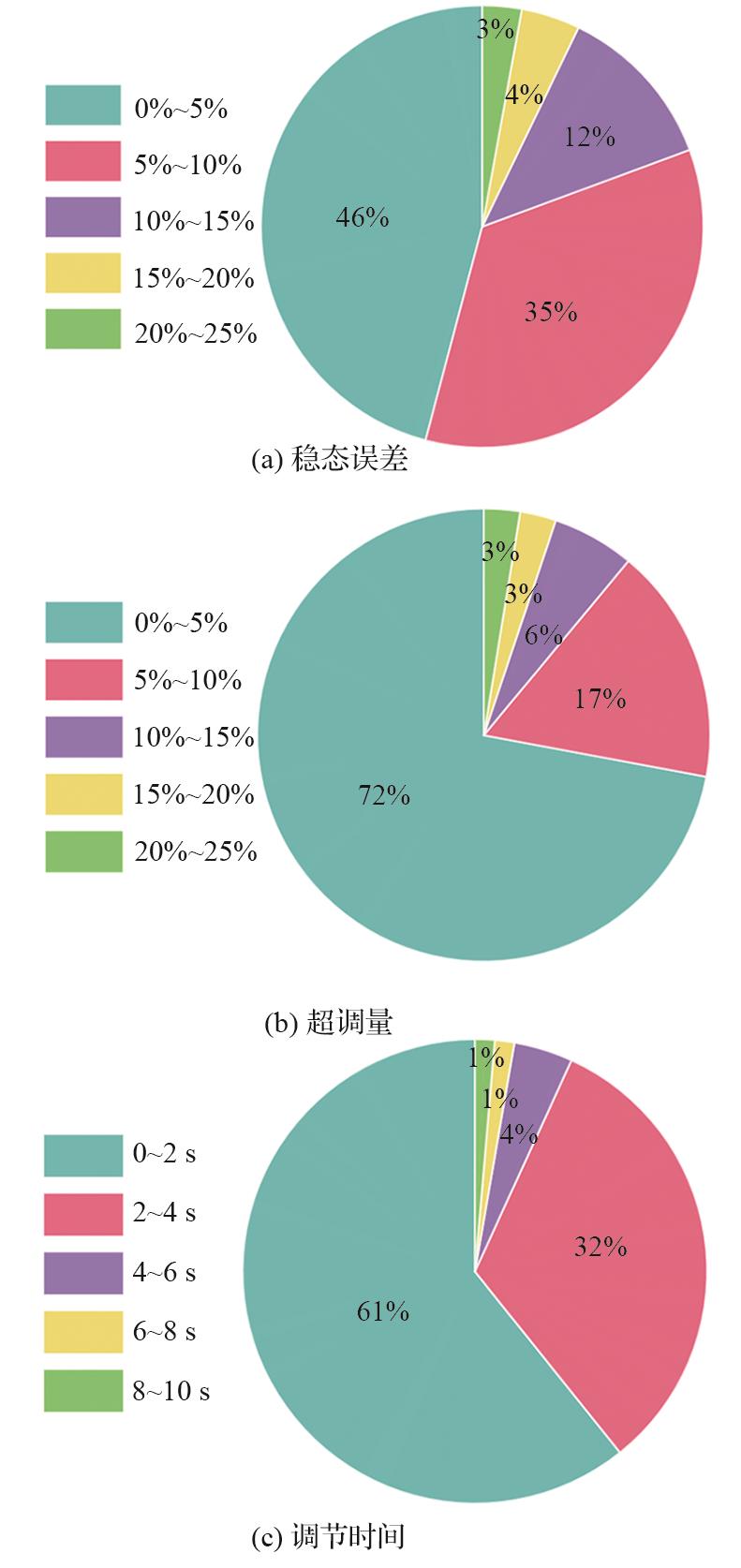
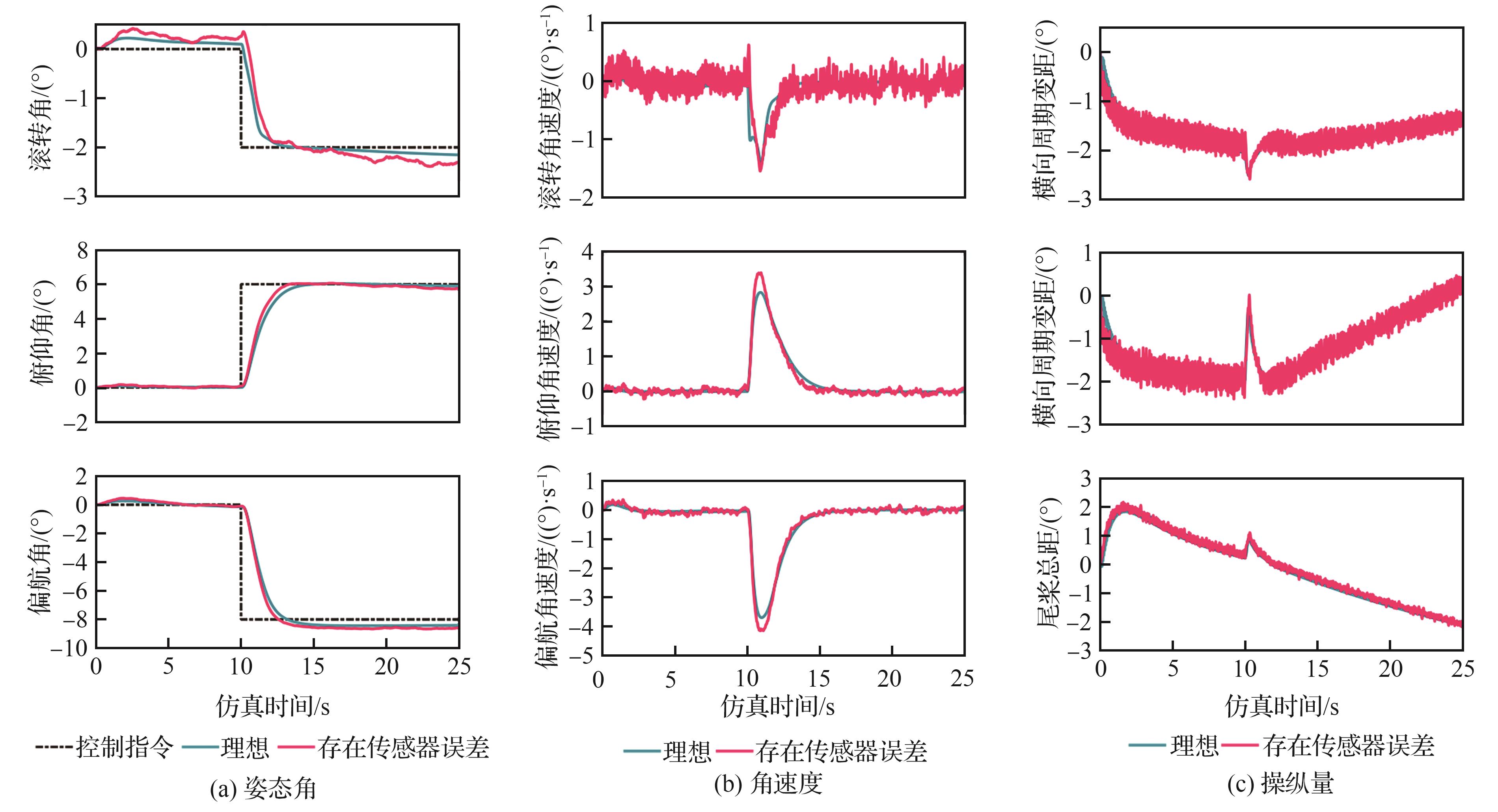
| [1] |
高正, 陈仁良. 直升机飞行动力学[M]. 北京: 科学出版社, 2003: 1-232.
|
|
GAO Z, CHEN R L. Helicopter flight dynamics[M]. Beijing: Science Press, 2003: 1-232 (in Chinese).
|
| [2] |
陈仁良, 李攀, 吴伟, 等. 直升机飞行动力学数学建模问题[J]. 航空学报, 2017, 38(7): 520915.
|
|
CHEN R L, LI P, WU W, et al. A review of mathematical modeling of helicopter flight dynamics[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(7): 520915 (in Chinese).
|
| [3] |
李攀. 旋翼非定常自由尾迹及高置信度直升机飞行力学建模研究[D]. 南京: 南京航空航天大学, 2010: 1-169.
|
|
LI P. Research on unsteady free wake of rotor and high confidence helicopter flight mechanics modeling[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2010: 1-169 (in Chinese).
|
| [4] |
BALAS G J, PACKARD A K, RENFROW J, et al. Control of the F-14 aircraft lateral-directional axis during powered approach[J]. Journal of Guidance, Control, and Dynamics, 1998, 21(6): 899-908.
|
| [5] |
郑峰婴, 沈志敏, 李雅琴, 等. 共轴高速直升机增益自适应多模式切换控制[J]. 航空学报, 2024, 45(9): 529088.
|
|
ZHENG F Y, SHEN Z M, LI Y Q, et al. Gain adaptive multi-mode switching control for coaxial high-speed helicopter[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(9): 529088 (in Chinese).
|
| [6] |
CATAK A, ALTUNKAYA E C, DEMIR M, et al. Enhanced flight envelope protection: A novel reinforcement learning approach[J]. IFAC-PapersOnLine, 2024, 58(30): 207-212.
|
| [7] |
WISE K A. Design parameter tuning in adaptive observer-based flight control architectures[C]∥2018 AIAA Information Systems-AIAA Infotech @ Aerospace. Reston: AIAA, 2018.
|
| [8] |
仇钰清, 李俨, 郎金溪, 等. 高速直升机过渡模态鲁棒自适应姿态控制[J]. 航空学报, 2024, 45(9): 529927.
|
|
QIU Y Q, LI Y, LANG J X, et al. Robust adaptive attitude control of high-speed helicopters in transition mode[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(9): 529927 (in Chinese).
|
| [9] |
LAKE B M, BARONI M. Human-like systematic generalization through a meta-learning neural network[J]. Nature, 2023, 623(7985): 115-121.
|
| [10] |
SUTTON R S, BARTO A G. Reinforcement learning: An introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5): 1054.
|
| [11] |
SÖNMEZ S, RUTHERFORD M J, VALAVANIS K P. A survey of offline-and online-learning-based algorithms for multirotor UAVs [J]. Drones, 2024, 8(4): 116.
|
| [12] |
RICHTER D J, CALIX R A, KIM K. A review of reinforcement learning for fixed-wing aircraft control tasks[J]. IEEE Access, 2024, 12: 103026-103048.
|
| [13] |
SHADEED O, HASANZADE M, KOYUNCU E. Deep reinforcement learning based aggressive flight trajectory tracker[C]∥AIAA Scitech 2021 Forum. Reston: AIAA, 2021.
|
| [14] |
MANUKYAN A, OLIVARES-MENDEZ M A, GEIST M, et al. Deep reinforcement learning-based continuous control for multicopter systems[C]∥2019 6th International Conference on Control, Decision and Information Technologies (CoDIT). Piscataway: IEEE Press, 2019: 1876-1881.
|
| [15] |
HWANGBO J, SA I, SIEGWART R, et al. Control of a quadrotor with reinforcement learning[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 2096-2103.
|
| [16] |
KOCH W, MANCUSO R, WEST R, et al. Reinforcement learning for UAV attitude control[J]. ACM Transactions on Cyber-Physical Systems, 2019, 3(2): 1-21.
|
| [17] |
XU J, DU T, FOSHEY M, et al. Learning to fly: Computational controller design for hybrid UAVs with reinforcement learning[J]. ACM Transactions on Graphics, 2019, 38(4): 1-12.
|
| [18] |
CANO LOPES G, FERREIRA M, SILVA SIMÕES A DA, et al. Intelligent control of a quadrotor with proximal policy optimization reinforcement learning[C]∥2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE). Piscataway: IEEE Press, 2018: 503-508.
|
| [19] |
MOLCHANOV A, CHEN T, HÖNIG W, et al. Sim-to-(multi)-real: Transfer of low-level robust control policies to multiple quadrotors[C]∥2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2019: 59-66.
|
| [20] |
LI Z, XUE S R, LIN W Y, et al. Training a robust reinforcement learning controller for the uncertain system based on policy gradient method[J]. Neurocomputing, 2018, 316: 313-321.
|
| [21] |
ZHEN Y, HAO M R, SUN W D. Deep reinforcement learning attitude control of fixed-wing UAVs[C]∥2020 3rd International Conference on Unmanned Systems (ICUS). Piscataway: IEEE Press, 2020: 239-244.
|
| [22] |
BEKAR C, YUKSEK B, INALHAN G. High fidelity progressive reinforcement learning for agile maneuvering UAVs[C]∥AIAA Scitech 2020 Forum. Reston: AIAA, 2020.
|
| [23] |
KIM J, JUNG S. Enhancing UAV stability: A deep reinforcement learning strategy[C]∥2024 International Conference on Electronics, Information, and Communication (ICEIC). Piscataway: IEEE Press, 2024: 1-4.
|
| [24] |
AOUN C, MONCAYO H. Disturbance observer-based reinforcement learning control and the application to a nonlinear dynamic system[C]∥AIAA Scitech 2020 Forum. Reston: AIAA, 2022.
|
| [25] |
WANG Y D, SUN J, HE H B, et al. Deterministic policy gradient with integral compensator for robust quadrotor control[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 50(10): 3713-3725.
|
| [26] |
AKHTAR M, MAQSOOD A. Comparative analysis of deep reinforcement learning algorithms for hover-to-cruise transition maneuvers of a tilt-rotor unmanned aerial vehicle[J]. Aerospace, 2024, 11(12): 1040-1042.
|
| [27] |
PUTERMAN M L. Markov decision processes[M]∥Handbooks in Operations Research and Management Science. New York: Springer Science+Business Media, 1990, 2: 331-434.
|
| [28] |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. ArXiv preprint: 1707. 06347, 2017.
|
| [29] |
SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation[DB/OL]. ArXiv preprint: 1506. 02438, 2015.
|
| [30] |
GRONDMAN I, BUSONIU L, LOPES G A D, et al. A survey of actor-critic reinforcement learning: Standard and natural policy gradients[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2012, 42(6): 1291-1307.
|
| [31] |
BORISOV A, MAMAEV I S. Rigid body dynamics[M]. New York: Springer Science+Business Media, 2018: 1-271.
|
| [32] |
LI P, CHEN R L. A mathematical model for helicopter comprehensive analysis[J]. Chinese Journal of Aeronautics, 2010, 23(3): 320-326.
|
| [33] |
PITT D M, PETERS D A. Theoretical prediction of dynamic inflow derivatives[J]. Vertica, 1981, 5(1): 21-34.
|
| [34] |
BALLIN M G. Validation of a real-time engineering simulation of the UH-60A helicopter: NASA-TM-88360 [R]. Washington, D.C.: NASA, 1987.
|
| [35] |
ANDRYCHOWICZ M, RAICHUK A, STAŃCZYK P, et al. What matters for on-policy deep actor-critic methods? A large-scale study[C]∥International Conference on Learning Representations: OpenReview. 2021: 1-10.
|
| [36] |
WU Y F, ZHANG W, XU P, et al. A finite-time analysis of two time-scale actor-critic methods[J]. Advances in Neural Information Processing Systems, 2020, 33: 17617-17628.
|
| [37] |
WELCER M, SZCZEPAŃSKI C, KRAWCZYK M. The impact of sensor errors on flight stability[J]. Aerospace, 2022, 9(3): 169.
|
| [38] |
TRIPATHI S, WAGH P, CHAUDHARY A B. Modelling, simulation & sensitivity analysis of various types of sensor errors and its impact on tactical flight vehicle navigation[C]∥2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT). Piscataway: IEEE Press, 2016: 938-942.
|
| [39] |
ZHENG T, XU A G, XU X C, et al. Modeling and compensation of inertial sensor errors in measurement systems[J]. Electronics, 2023, 12(11): 2458.
|
 ), 王梓旭, 朱振华
), 王梓旭, 朱振华