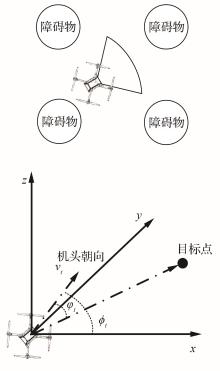
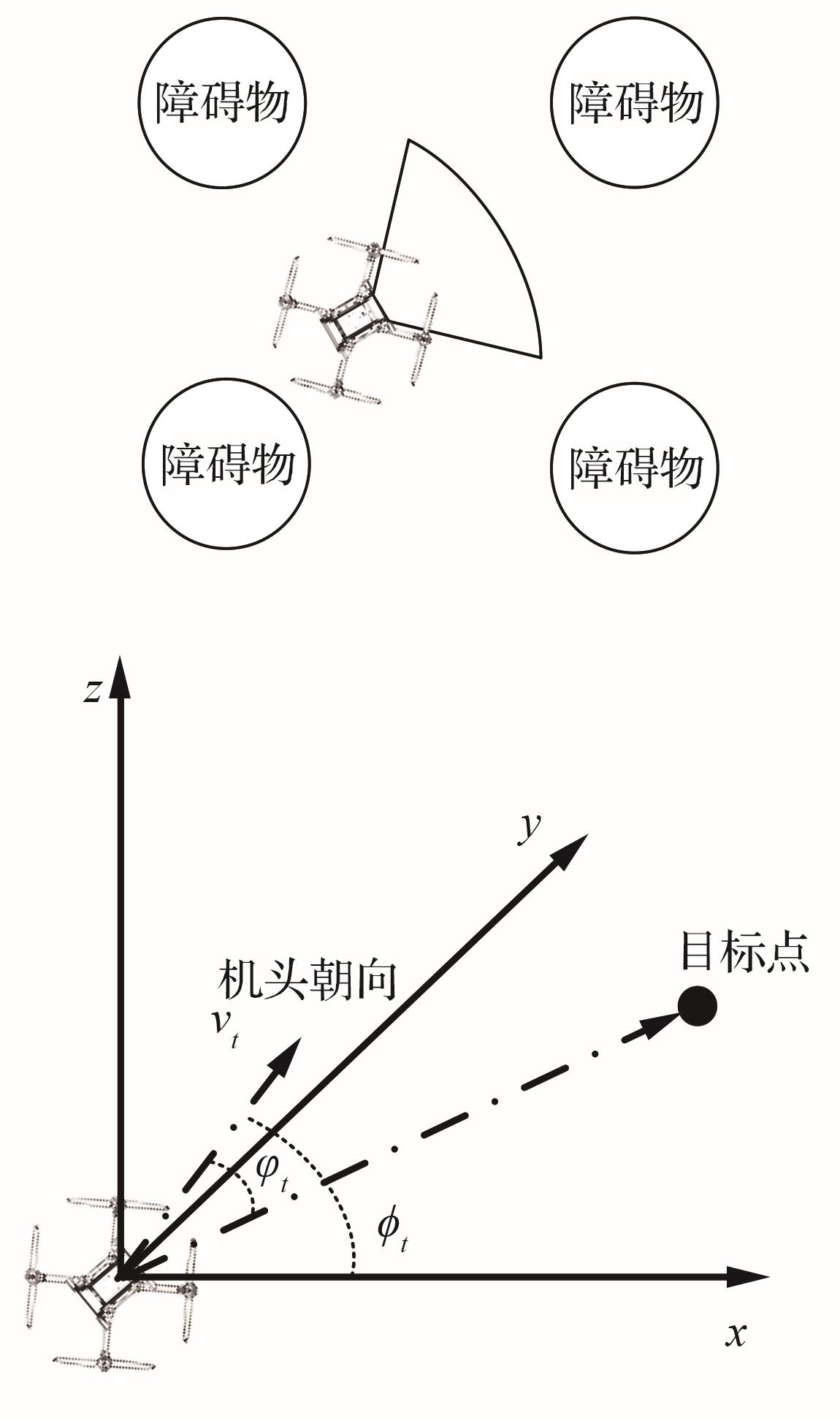
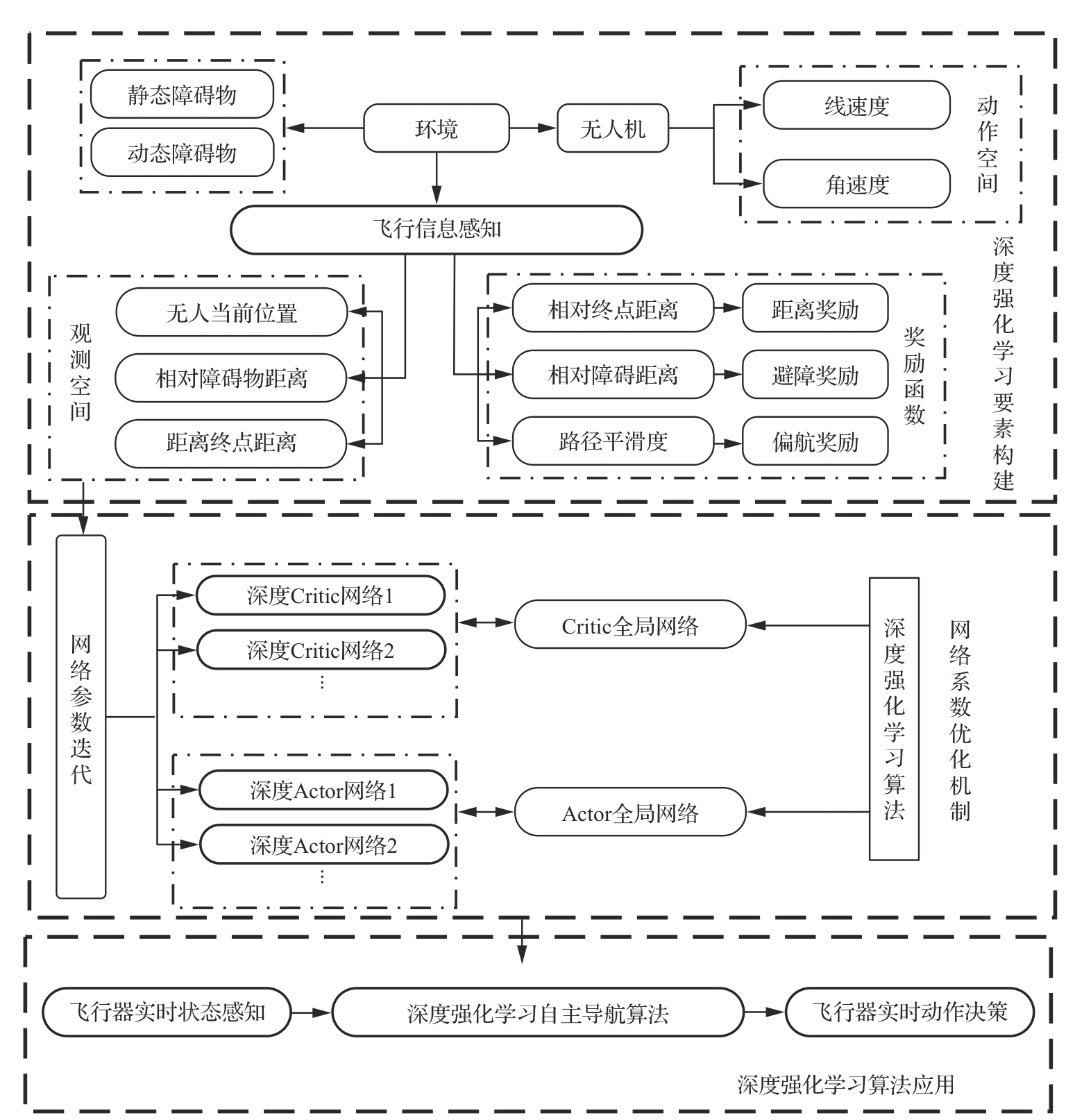
| 1 |
HUANG Z Y, WU J D, LV C. Efficient deep reinforcement learning with imitative expert priors for autonomous driving[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(10): 7391-7403.
|
| 2 |
ADIL M, SONG H B, AHMAD JAN M, et al. UAV-assisted IoT applications, QoS requirements and challenges with future research directions[J]. ACM Computing Surveys, 2024, 56(10): 1-35.
|
| 3 |
XUE Z H, GONSALVES T. Vision based drone obstacle avoidance by deep reinforcement learning[J]. AI, 2021, 2(3): 366-380.
|
| 4 |
LI J, QIN H, WANG J Z, et al. OpenStreetMap-based autonomous navigation for the four wheel-legged robot via 3D-lidar and CCD camera[J]. IEEE Transactions on Industrial Electronics, 2022, 69(3): 2708-2717.
|
| 5 |
CAI D P, LI R Q, HU Z H, et al. A comprehensive overview of core modules in visual SLAM framework[J]. Neurocomputing, 2024, 590: 127760.
|
| 6 |
YANG C G, CHEN C Z, HE W, et al. Robot learning system based on adaptive neural control and dynamic movement primitives[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(3): 777-787.
|
| 7 |
ALMAZROUEI K, KAMEL I, RABIE T. Dynamic obstacle avoidance and path planning through reinforcement learning[J]. Applied Sciences, 2023, 13(14): 8174.
|
| 8 |
SATHYAMOORTHY A J, PATEL U, GUAN T R, et al. Frozone: Freezing-free, pedestrian-friendly navigation in human crowds[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 4352-4359.
|
| 9 |
周彬, 郭艳, 李宁, 等. 基于导向强化Q学习的无人机路径规划[J]. 航空学报, 2021, 42(9): 325109.
|
|
ZHOU B, GUO Y, LI N, et al. Path planning of UAV using guided enhancement Q-learning algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(9): 325109 (in Chinese).
|
| 10 |
CHAI R Q, NIU H L, CARRASCO J, et al. Design and experimental validation of deep reinforcement learning-based fast trajectory planning and control for mobile robot in unknown environment[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5778-5792.
|
| 11 |
XIE Z T, DAMES P. DRL-VO: Learning to navigate through crowded dynamic scenes using velocity obstacles[J]. IEEE Transactions on Robotics, 2023, 39(4): 2700-2719.
|
| 12 |
CAO X, REN L, SUN C Y. Research on obstacle detection and avoidance of autonomous underwater vehicle based on forward-looking sonar[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(11): 9198-9208.
|
| 13 |
WANG W Y, MA F, LIU J L. Course tracking control for smart ships based on A deep deterministic policy gradient-based algorithm[C]∥2019 5th International Conference on Transportation Information and Safety (ICTIS). Piscataway: IEEE Press, 2019.
|
| 14 |
LILLICRAP T P, HUNT J, PRITZEL A, et al. Continuous control with deep reinforcement learning[DB/OL]. arXiv preprint: 1509.02971,2019.
|
| 15 |
SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]∥Proceedings of the 31st International Conference on International Conference on Machine Learning. New York: ACM, 2014.
|
| 16 |
FUJIMOTO S, HOOF H V, MEGER D. Addressing function approximation error in actor-critic methods[C]∥Proceedings of the 35th International Conference on Machine Learning. New York: ACM, 2018
|
| 17 |
寇凯, 杨刚, 张文启, 等. 基于SAC的无人机自主导航方法研究[J]. 西北工业大学学报, 2024, 42(2): 310-318.
|
|
KOU K, YANG G, ZHANG W Q, et al. Exploring UAV autonomous navigation algorithm based on soft actor-critic[J]. Journal of Northwestern Polytechnical University, 2024, 42(2): 310-318 (in Chinese).
|
| 18 |
SINGLA A, PADAKANDLA S, BHATNAGAR S. Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(1): 107-118.
|
| 19 |
CUI Z Y, WANG Y. UAV path planning based on multi-layer reinforcement learning technique[J]. IEEE Access, 2021, 9: 59486-59497.
|
| 20 |
XUE Y T, CHEN W S. A UAV navigation approach based on deep reinforcement learning in large cluttered 3D environments[J]. IEEE Transactions on Vehicular Technology, 2023, 72(3): 3001-3014.
|
| 21 |
EVERETT M, CHEN Y F, HOW J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning[C]∥2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2018.
|
| 22 |
KAELBLING L P, LITTMAN M L, CASSANDRA A R. Planning and acting in partially observable stochastic domains[J]. Artificial Intelligence, 1998, 101(1): 99-134.
|
| 23 |
XIAO C X, LU P, HE Q Z. Flying through a narrow gap using end-to-end deep reinforcement learning augmented with curriculum learning and Sim2Real[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(5): 2701-2708.
|
| 24 |
JIA J Y, XING X W, CHANG D E. GRU-attention based TD3 network for mobile robot navigation[C]∥2022 22nd International Conference on Control, Automation and Systems (ICCAS). Piscataway: IEEE Press, 2022.
|
| 25 |
DEY R, SALEM F M. Gate-variants of gated recurrent unit (GRU) neural networks[C]∥2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS). Piscataway: IEEE Press, 2017.
|
| 26 |
KALIDAS A P, JOSHUA C J, MD A Q, et al. Deep reinforcement learning for vision-based navigation of UAVs in avoiding stationary and mobile obstacles[J]. Drones, 2023, 7(4): 245.
|
| 27 |
杨卫平. 新一代飞行器导航制导与控制技术发展趋势[J]. 航空学报, 2024, 45(5): 529720.
|
|
YANG W P. Development trend of navigation guidance and control technology for new generation aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(5): 529720 (in Chinese).
|
| 28 |
ZHANG F J, LI J, LI Z. A TD3-based multi-agent deep reinforcement learning method in mixed cooperation-competition environment[J]. Neurocomputing, 2020, 411: 206-215.
|
| 29 |
PAN L, CAI Q P, HUANG L B. Softmax deep double deterministic policy gradients[DB/OL]. arXiv preprint: 2010. 09177, 2020.
|
| 30 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[DB/OL]. arXiv preprint: 1707. 06347, 2017.
|
| 31 |
HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[DB/OL]. arXiv preprint: 1801. 01290, 2018.
|
 ), 张海2, 李涵玮1, 张宏立3
), 张海2, 李涵玮1, 张宏立3