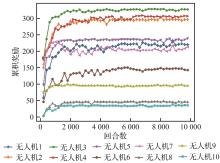
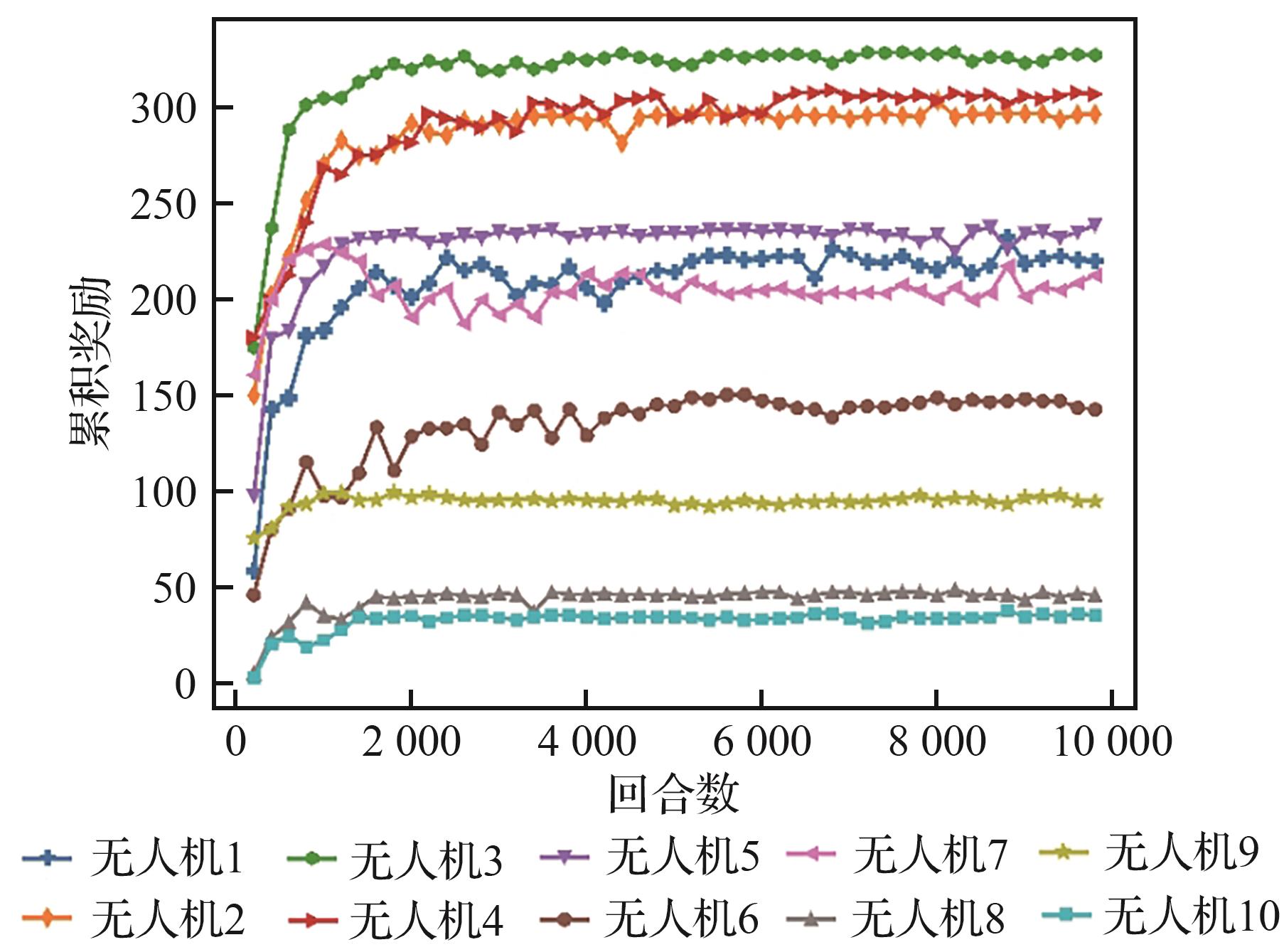
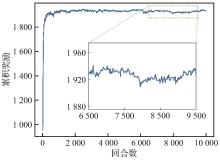
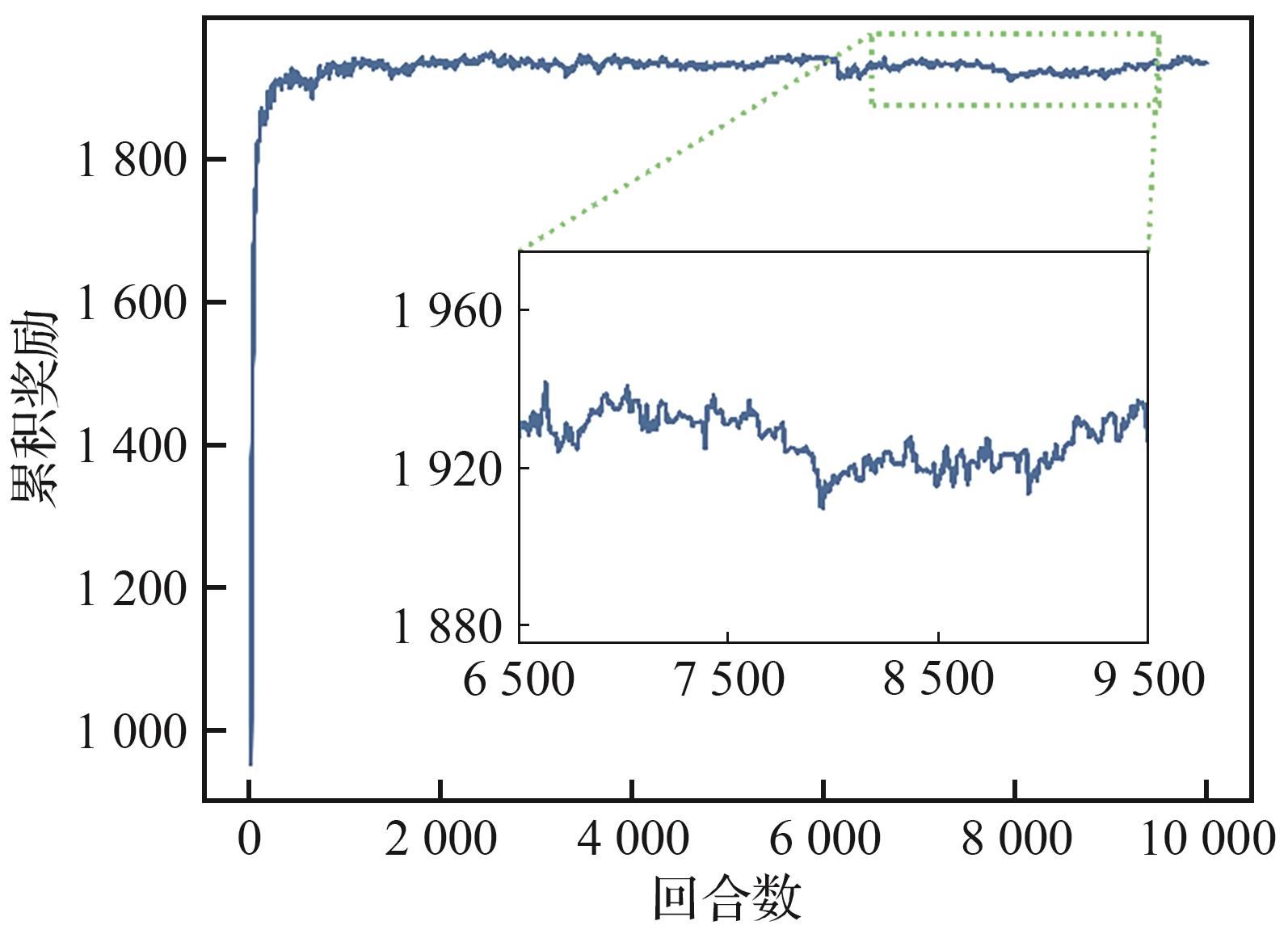
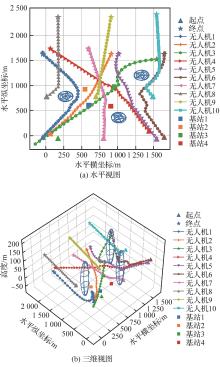
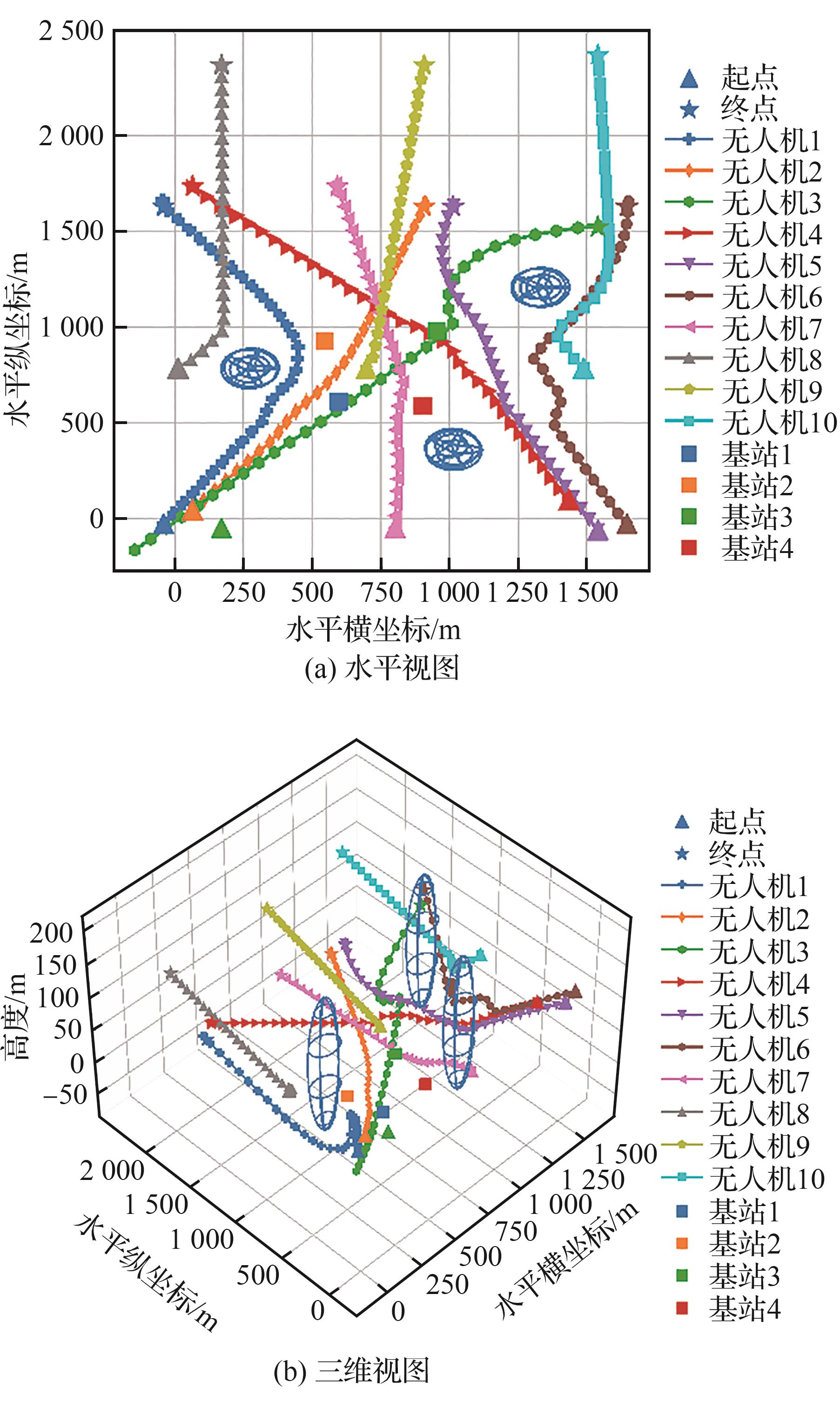
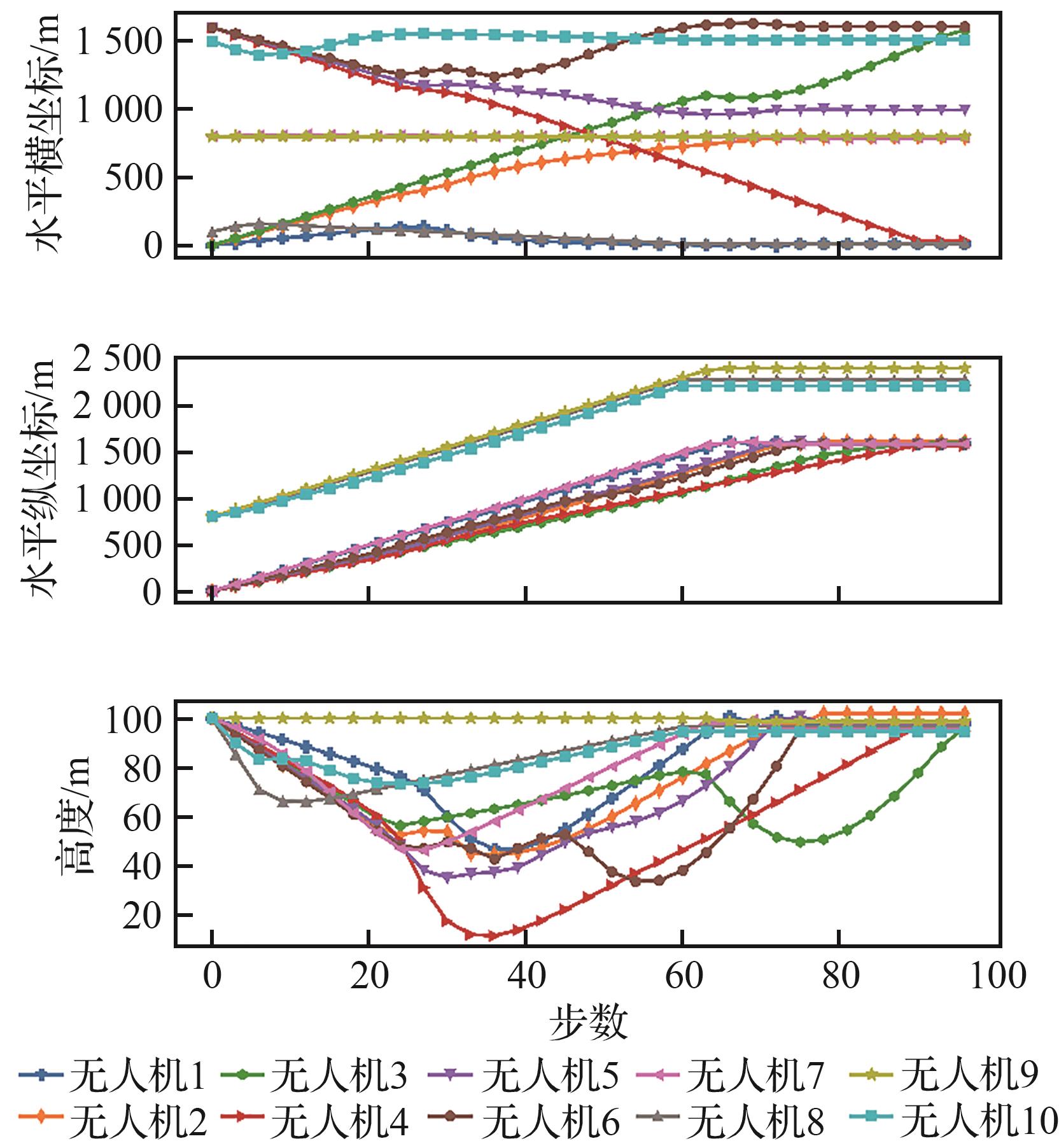
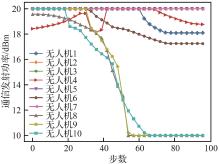
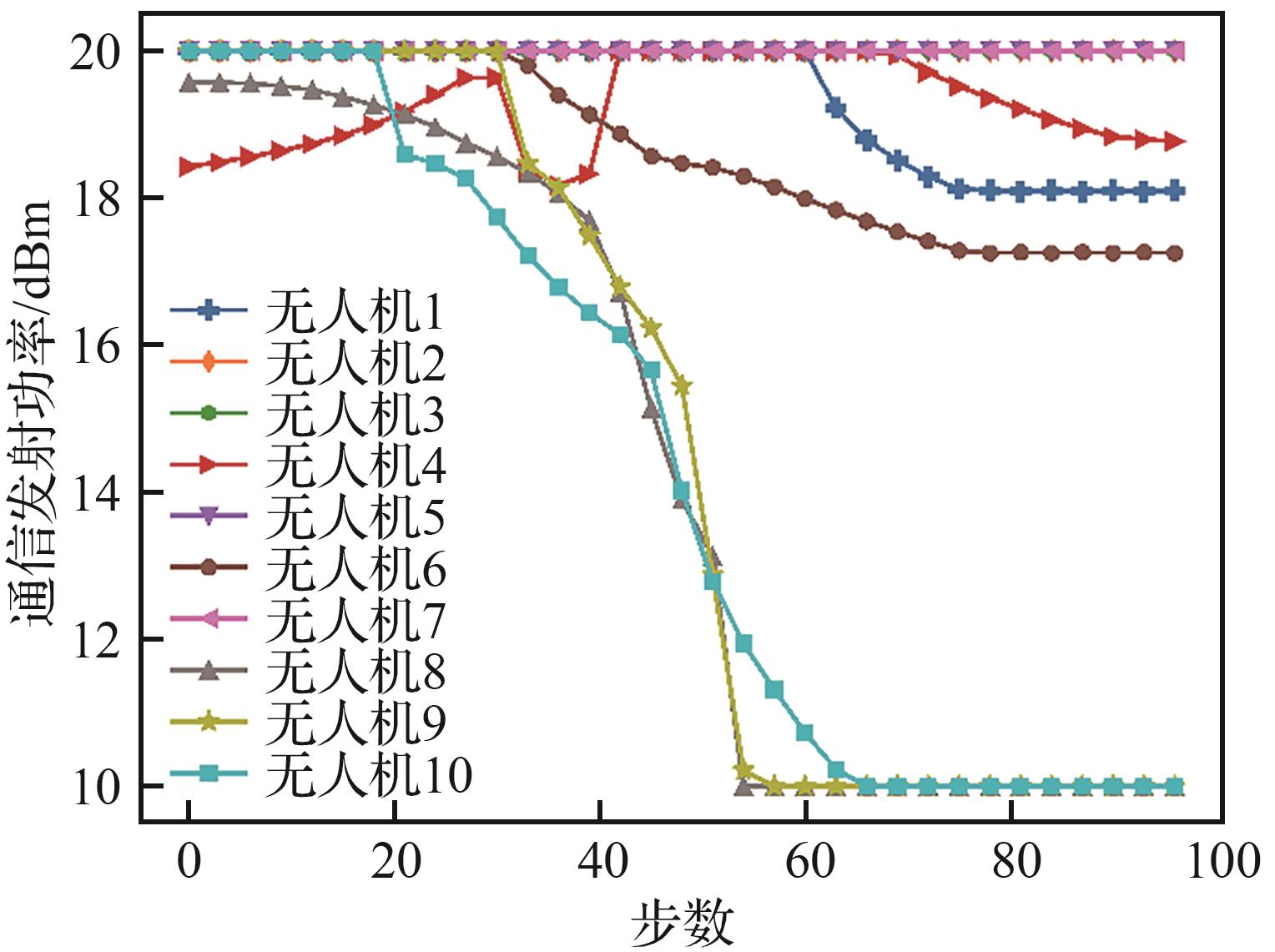
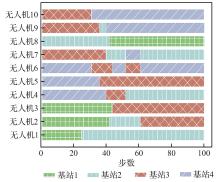
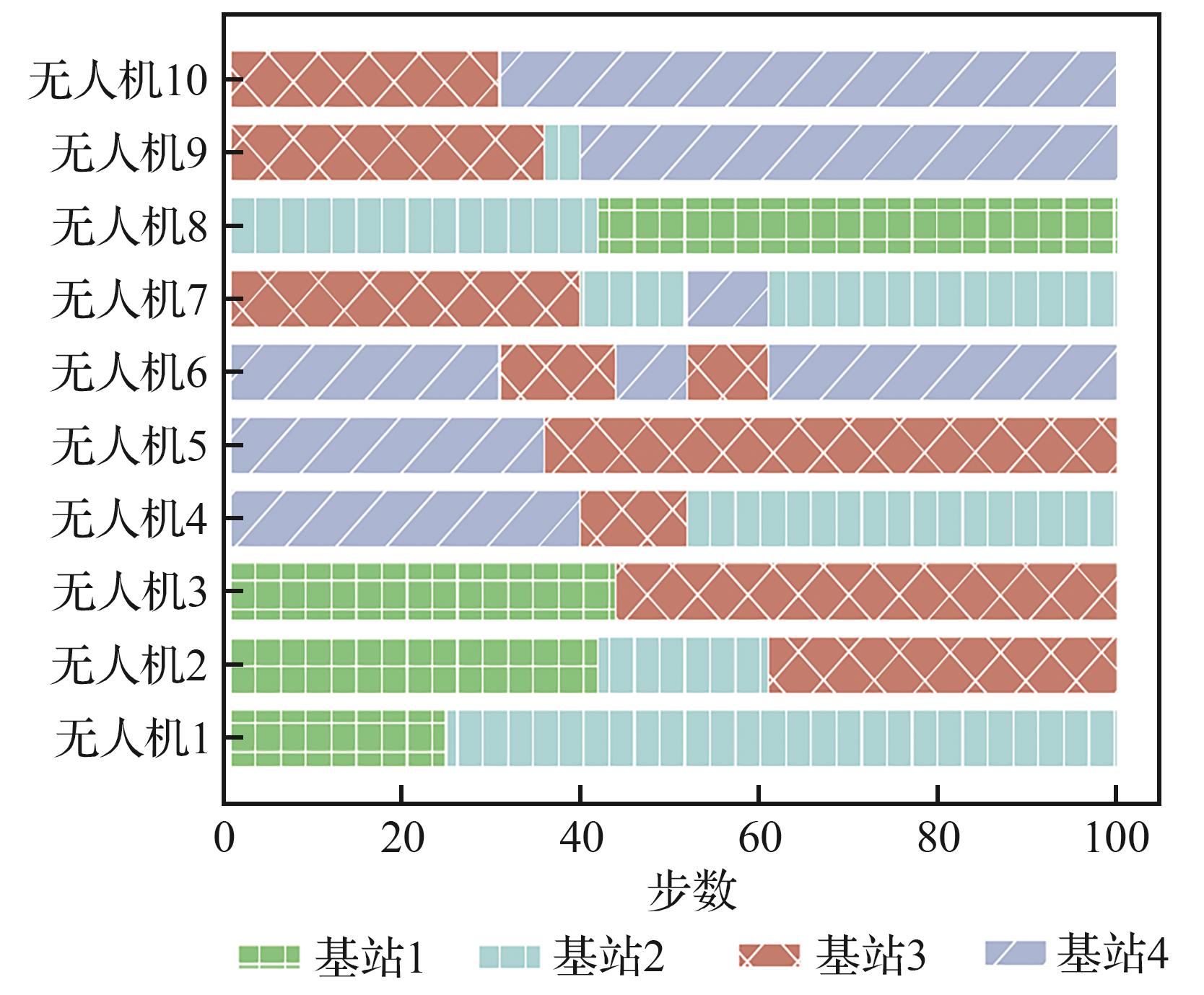
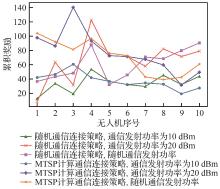
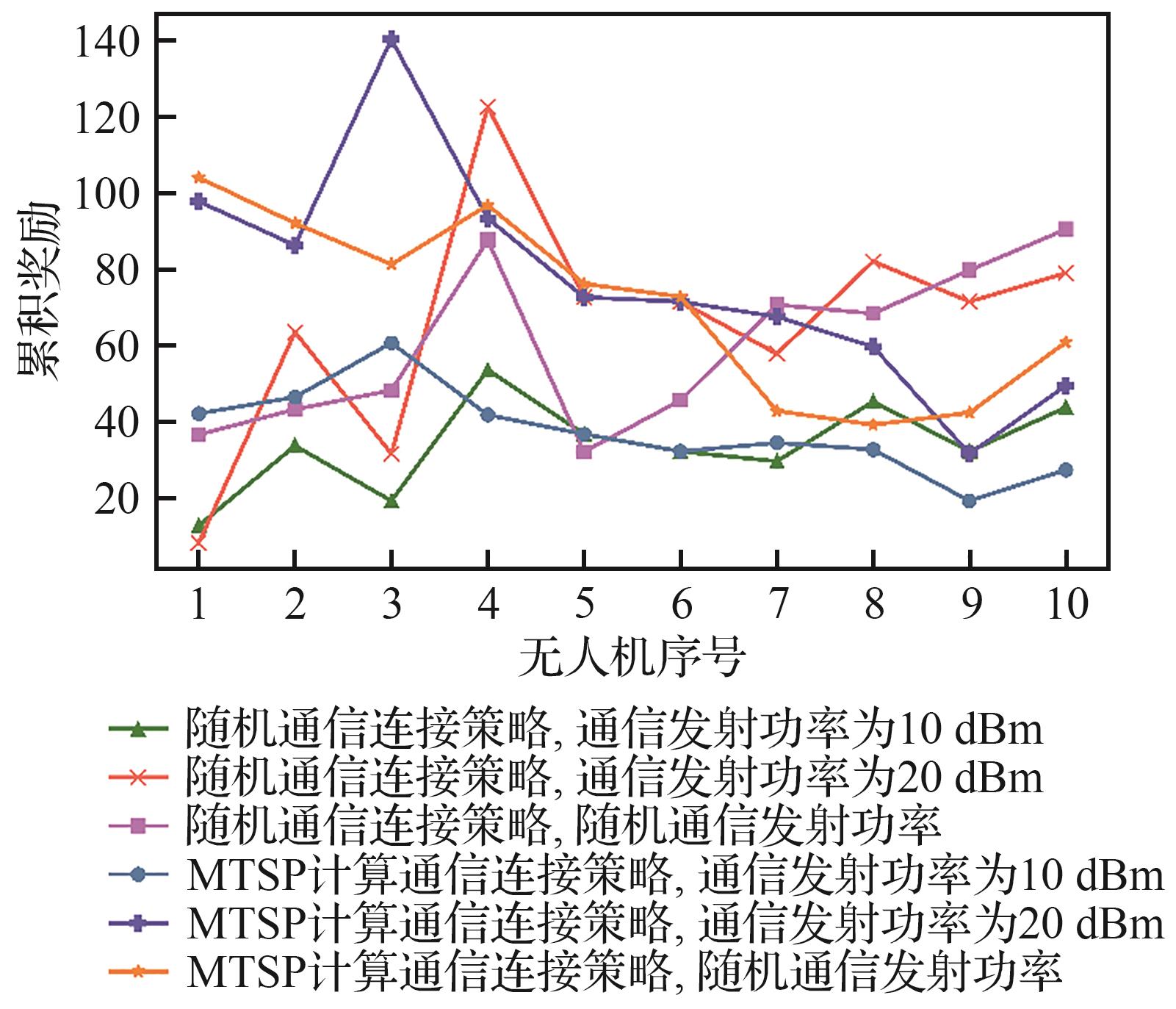
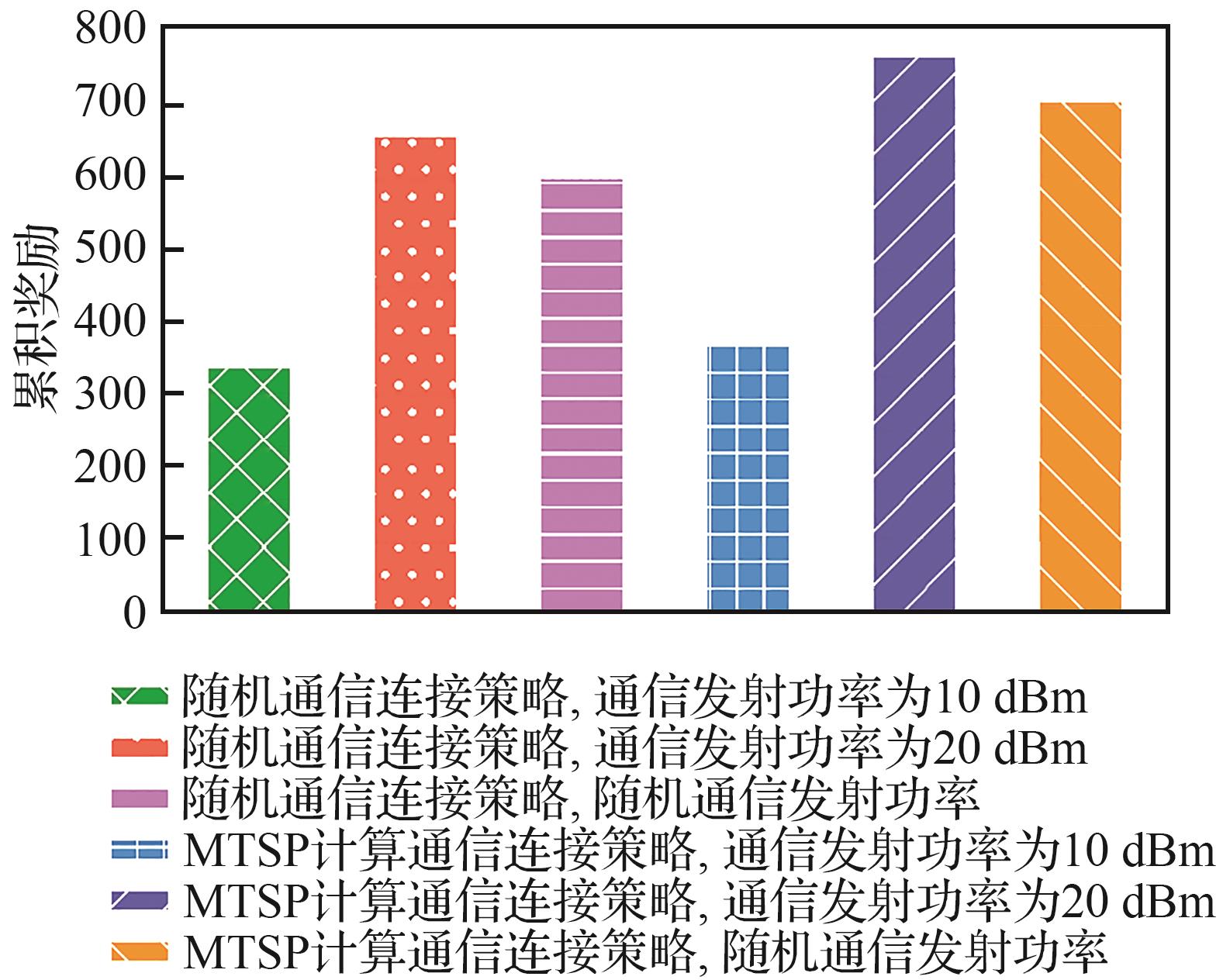
| [1] |
PENG G Z, XIA Y X, ZHANG X J, et al. UAV-aided networks for emergency communications in areas with unevenly distributed users[C]∥2018 IEEE International Conference on Communication Systems (ICCS). Piscataway: IEEE Press, 2018: 25-29.
|
| [2] |
SAADI A AIT, SOUKANE A, MERAIHI Y, et al. UAV path planning using optimization approaches: A survey[J]. Archives of Computational Methods in Engineering, 2022, 29(6): 4233-4284.
|
| [3] |
庞磊, 曹志强, 喻俊志. 基于A*和TEB融合的行人感知无碰跟随方法[J]. 航空学报, 2021, 42(4): 524909.
|
|
PANG L, CAO Z Q, YU J Z. A pedestrian-aware collision-free following approach for mobile robots based on A* and TEB[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): 524909 (in Chinese).
|
| [4] |
REN Z Q, RATHINAM S, LIKHACHEV M, et al. Multi-objective path-based D* lite[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 3318-3325.
|
| [5] |
HUANG H X, SHANG Y X, LIU X F, et al. An improved Bi-RRT*-based path planning algorithm with adaptive search strategy assignment mechanism for ultra-low-altitude penetration of fixed-wing aircraft[J]. Aerospace Science and Technology, 2024, 152: 109363.
|
| [6] |
符歆国, 关成启, 杨婷, 等. 基于改进RRT*的RLV在线再入轨迹规划算法[J]. 飞控与探测, 2025, 8(1): 57-66.
|
|
FU X G, GUAN C Q, YANG T, et al. Online re-entry trajectory planning algorithm for reusable launch vehicle based on improved RRT* [J]. Flight Control & Detection, 2025, 8(1): 57-66 (in Chinese).
|
| [7] |
YANG H X, XU X M, HONG J C. Automatic parking path planning of tracked vehicle based on improved A* and DWA algorithms[J]. IEEE Transactions on Transportation Electrification, 2023, 9(1): 283-292.
|
| [8] |
SHENG H L, ZHANG J, YAN Z Y, et al. New multi-UAV formation keeping method based on improved artificial potential field[J]. Chinese Journal of Aeronautics, 2023, 36(11): 249-270.
|
| [9] |
王羿, 叶辉, 杨晓飞. 基于无源性与势场法的四旋翼避障与位置控制[J]. 航空学报, 2023, 44(S1): 727492.
|
|
WANG Y, YE H, YANG X F. A position control and obstacle avoidance method for quadrotor via approach based on passivity and artificial potential filed[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(S1): 727492.
|
| [10] |
SHIN Y, KIM E. Hybrid path planning using positioning risk and artificial potential fields[J]. Aerospace Science and Technology, 2021, 112: 106640.
|
| [11] |
于全友, 徐止政, 段纳, 等. 基于改进ACO的带续航约束无人机全覆盖作业路径规划[J]. 航空学报, 2023, 44(12): 327856.
|
|
YU Q Y, XU Z Z, DUAN N, et al. Coverage operation path planning of UAV with endurance constraints based on improved ACO[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(12): 327856 (in Chinese).
|
| [12] |
LI Y P, ZHANG L X, CAI B, et al. Unified path planning for composite UAVs via Fermat point-based grouping particle swarm optimization[J]. Aerospace Science and Technology, 2024, 148: 109088.
|
| [13] |
JIANG W, LYU Y X, LI Y F, et al. UAV path planning and collision avoidance in 3D environments based on POMPD and improved grey wolf optimizer[J]. Aerospace Science and Technology, 2022, 121: 107314.
|
| [14] |
周彬, 郭艳, 李宁, 等. 基于导向强化Q学习的无人机路径规划[J]. 航空学报, 2021, 42(9): 325109.
|
|
ZHOU B, GUO Y, LI N, et al. Path planning of UAV using guided enhancement Q-learning algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(9): 325109 (in Chinese).
|
| [15] |
SCHLICHTING M R, NOTTER S, FICHTER W. Long short-term memory for spatial encoding in multi-agent path planning[J]. Journal of Guidance, Control, and Dynamics, 2022, 45(5): 952-961.
|
| [16] |
魏瑶, 刘小毛, 张晗, 等. 基于DDPG的单目无人机避障算法[J]. 飞控与探测, 2023, 6(3): 52-62.
|
|
WEI Y, LIU X M, ZHANG H, et al. Obstacle avoidance algorithm for monocular UAV based on DDPG[J]. Flight Control & Detection, 2023, 6(3): 52-62 (in Chinese).
|
| [17] |
谭富威, 何永宁, 孙晓晖, 等. 基于深度强化学习的飞行器过载和姿态智能控制研究[J]. 飞控与探测, 2025, 8(1): 25-31.
|
|
TAN F W, HE Y N, SUN X H, et al. Intelligent control of aircraft overload and attitude based on deep reinforcement learning[J]. Flight Control & Detection, 2025, 8(1): 25-31 (in Chinese).
|
| [18] |
ZHANG S W, ZENG Y, ZHANG R. Cellular-enabled UAV communication: A connectivity-constrained trajectory optimization perspective[J]. IEEE Transactions on Communications, 2019, 67(3): 2580-2604.
|
| [19] |
FONTANESI G, ZHU A D, ARVANEH M, et al. A transfer learning approach for UAV path design with connectivity outage constraint[J]. IEEE Internet of Things Journal, 2022, 10(6): 4998-5012.
|
| [20] |
WANG X Y, GURSOY M C. Learning-based UAV trajectory optimization with collision avoidance and connectivity constraints[J]. IEEE Transactions on Wireless Communications, 2021, 21(6): 4350-4363.
|
| [21] |
NGUYEN K K, DUONG T Q, DO-DUY T, et al. 3D UAV trajectory and data collection optimisation via deep reinforcement learning[J]. IEEE Transactions on Communications, 2022, 70(4): 2358-2371.
|
| [22] |
WANG X J, YI M J, LIU J, et al. Cooperative data collection with multiple UAVs for information freshness in the internet of things[J]. IEEE Transactions on Communications, 2023, 71(5): 2740-2755.
|
| [23] |
张薇, 何若俊. 面向物联网数据收集的无人机自主路径规划[J]. 航空学报, 2024, 45(8): 329054.
|
|
ZHANG W, HE R J. Autonomous trajectory design for IoT data collection by UAV[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(8): 329054 (in Chinese).
|
| [24] |
WANG L, WANG K Z, PAN C H, et al. Deep reinforcement learning based dynamic trajectory control for UAV-assisted mobile edge computing[J]. IEEE Transactions on Mobile Computing, 2022, 21(10): 3536-3550.
|
| [25] |
ZHANG Y, MOU Z Y, GAO F F, et al. UAV-enabled secure communications by multi-agent deep reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2020, 69(10): 11599-11611.
|
| [26] |
雷耀麟, 丁文锐, 罗祎喆, 等. 无人机数据采集任务中的航迹与资源优化[J/OL]. 北京航空航天大学学报, (2023-10-19)[2025-01-15]. .
|
|
LEI Y L, DING W R, LUO Y Z, et al. Trajectory planning and resource allocation methods in UAV data collection missions[J/OL]. Journal of Beijing University of Aeronautics and Astronautics, (2023-10-19)[2025-01-15]. (in Chinese).
|
| [27] |
胥彪, 赵琛钰, 李爽, 等. 基于深度强化学习的高超声速飞行器动态面控制方法[J]. 飞控与探测, 2023, 6(1): 15-23.
|
|
XU B, ZHAO C Y, LI S, et al. Dynamic surface control method for hypersonic vehicle based on deep reinforcement learning[J]. Flight Control & Detection, 2023, 6(1): 15-23 (in Chinese).
|
| [28] |
BANACIA A S, BRIOSO J G, SAWADA H, et al. Experimental verification of ITU-R P.1411 as path loss prediction model for IEEE 802.11af[C]∥21st International Symposium on Wireless Personal Multimedia Communications (WPMC), 2018.
|
| [29] |
王雪松, 王荣荣, 程玉虎. 基于表征学习的离线强化学习方法研究综述[J]. 自动化学报, 2024, 50(6): 1104-1128.
|
|
WANG X S, WANG R R, CHENG Y H. A review of offline reinforcement learning based on representation learning[J]. Acta Automatica Sinica, 2024, 50(6): 1104-1128 (in Chinese).
|
| [30] |
YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of PPO in cooperative, multi-agent games[C]∥36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks,2022.
|
| [31] |
WU W, WANG Q, WU X L, et al. Joint offloading and resource allocation for scalable vehicular edge computing[C]∥2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall). Piscataway: IEEE Press, 2020.
|
| [32] |
SCHULMAN J, MORTIZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation[DB/OL]. arXiv preprint:1506.02438,2021.
|
 ), 殷泽阳1, 靳锴2, 李星辰3
), 殷泽阳1, 靳锴2, 李星辰3