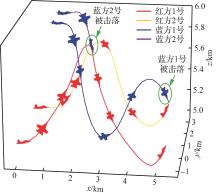
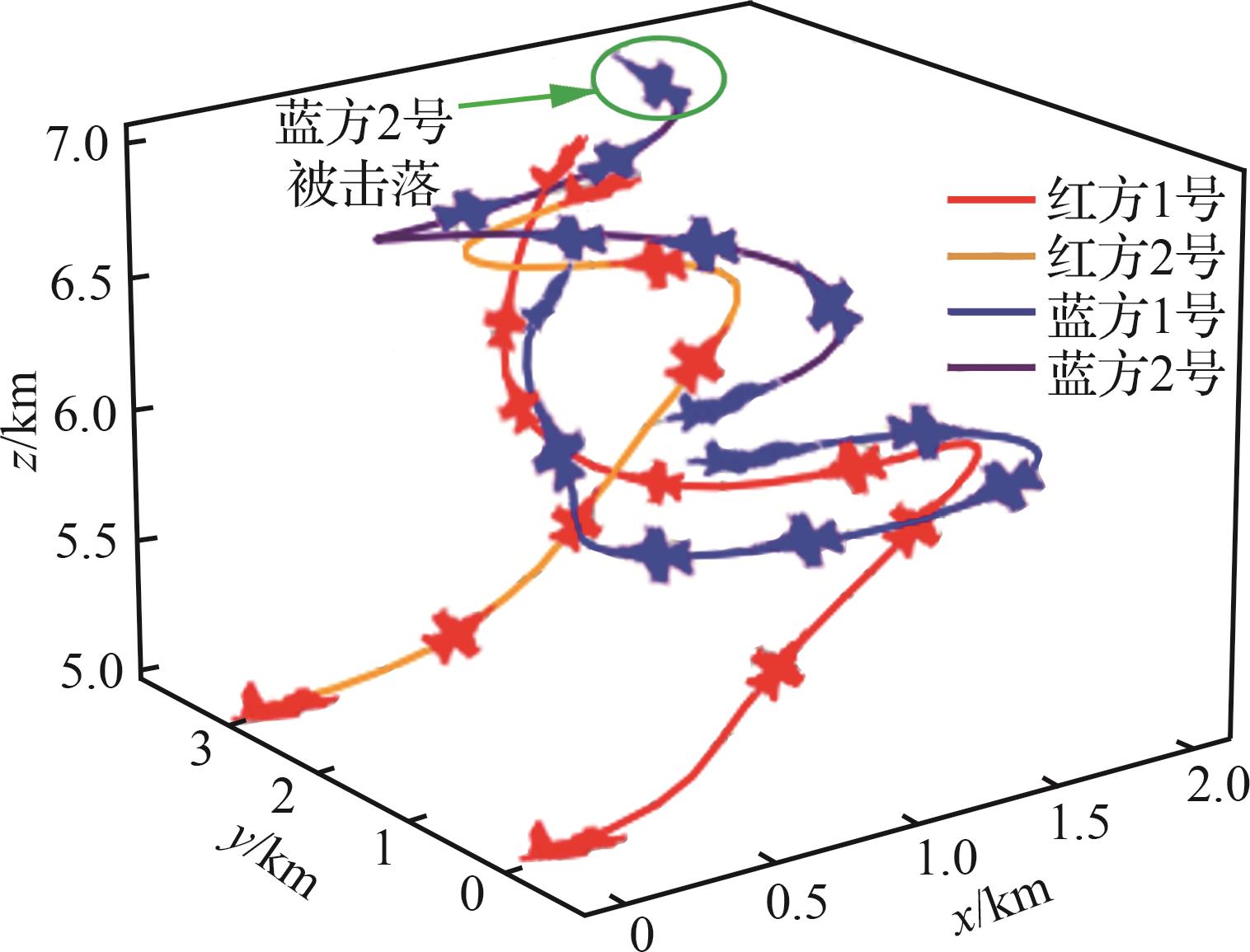
| 1 |
范晋祥, 陈晶华. 未来空战新概念及其实现挑战[J]. 航空兵器, 2020, 27(2): 15-24.
|
|
FAN J X, CHEN J H. New concepts of future air warfare and the challenges for its realization[J]. Aero Weaponry, 2020, 27(2): 15-24 (in Chinese).
|
| 2 |
孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 525799.
|
|
SUN Z X, YANG S Q, PIAO H Y, et al. A survey of air combat artificial intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 525799 (in Chinese).
|
| 3 |
徐光达, 吕超, 王光辉, 等. 基于双矩阵对策的UCAV空战自主机动决策研究[J]. 舰船电子工程, 2017, 37(11): 24-28, 39.
|
|
XU G D, LV C, WANG G H, et al. Research on UCAV autonomous air combat maneuvering decision-making based on Bi-matrix game[J]. Ship Electronic Engineering, 2017, 37(11): 24-28, 39 (in Chinese).
|
| 4 |
邵将, 徐扬, 罗德林. 无人机多机协同对抗决策研究[J]. 信息与控制, 2018, 47(3): 347-354.
|
|
SHAO J, XU Y, LUO D L. Cooperative combat decision-making research for multi UAVs[J]. Information and Control, 2018, 47(3): 347-354 (in Chinese).
|
| 5 |
黄长强, 赵克新, 韩邦杰, 等. 一种近似动态规划的无人机机动决策方法[J]. 电子与信息学报, 2018, 40(10): 2447-2452.
|
|
HUANG C Q, ZHAO K X, HAN B J, et al. Maneuvering decision-making method of UAV based on approximate dynamic programming[J]. Journal of Electronics & Information Technology, 2018, 40(10): 2447-2452 (in Chinese).
|
| 6 |
谢建峰, 杨啟明, 戴树岭, 等. 基于强化遗传算法的无人机空战机动决策研究[J]. 西北工业大学学报, 2020, 38(6): 1330-1338.
|
|
XIE J F, YANG Q M, DAI S L, et al. Air combat maneuver decision based on reinforcement genetic algorithm[J]. Journal of Northwestern Polytechnical University, 2020, 38(6): 1330-1338 (in Chinese).
|
| 7 |
李伟东, 黄振柱, 何精武, 等. 改进行为克隆与DDPG的无人驾驶决策模型[J/OL]. 计算机工程与应用, [2023-07-06] (2023-08-18). .
|
|
LI W D, HUANG Z Z, HE J W, et al. Improved behavioral cloning and DDPG’s driverless decision model[J/OL]. Computer Engineering and Applications, [2023-07-06] (2023-08-18). (in Chinese).
|
| 8 |
BOTVINICK M, WANG J X, DABNEY W, et al. Deep reinforcement learning and its neuroscientific implications[J]. Neuron, 2020, 107(4): 603-616.
|
| 9 |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529: 484-489.
|
| 10 |
THERESA H. DARPA’s AlphaDogfight tests AI pilot’s combat chops[EB/OL]. (2020-08) [2023-08-18]. , 2020.
|
| 11 |
马文, 李辉, 王壮, 等. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2): 443-451.
|
|
MA W, LI H, WANG Z, et al. Close air combat maneuver decision based on deep stochastic game[J]. Systems Engineering and Electronics, 2021, 43(2): 443-451 (in Chinese).
|
| 12 |
周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44(4): 126731.
|
|
ZHOU P, HUANG J T, ZHANG S, et al. Intelligent air combat decision making and simulation based on deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(4): 126731 (in Chinese).
|
| 13 |
左家亮, 杨任农, 张滢, 等. 基于启发式强化学习的空战机动智能决策[J]. 航空学报, 2017, 38(10): 321168.
|
|
ZUO J L, YANG R N, ZHANG Y, et al. Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(10): 321168 (in Chinese).
|
| 14 |
KONG W R, ZHOU D Y, YANG Z, et al. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning[J]. Electronics, 2020, 9(7): 1121.
|
| 15 |
高敬鹏, 王国轩, 高路. 基于异步合作更新的LSTM-MADDPG多智能体协同决策算法[J]. 吉林大学学报(工学版), 2024, 54(3): 797-806.
|
|
GAO J P, WANG G X, GAO L. LSTM-MADDPG multi-agent cooperative decision algorithm based on asynchronous collaborative update[J]. Journal of Jilin University (Engineering and Technology Edition), 2024, 54(3): 797-806 (in Chinese).
|
| 16 |
孔维仁, 周德云, 赵艺阳, 等. 基于深度强化学习与自学习的多无人机近距空战机动策略生成算法[J]. 控制理论与应用, 2022, 39(2): 352-362.
|
|
KONG W R, ZHOU D Y, ZHAO Y Y, et al. Maneuvering strategy generation algorithm for multi-UAV in close-range air combat based on deep reinforcement learning and self-play[J]. Control Theory & Applications, 2022, 39(2): 352-362 (in Chinese).
|
| 17 |
邓可, 彭宣淇, 周德云. 基于矩阵对策与遗传算法的无人机空战决策[J]. 火力与指挥控制, 2019, 44(12): 61-66, 71.
|
|
DENG K, PENG X Q, ZHOU D Y. Study on air combat decision method of UAV based on matrix game and genetic algorithm[J]. Fire Control & Command Control, 2019, 44(12): 61-66, 71 (in Chinese).
|
| 18 |
LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6382-6393.
|
| 19 |
施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623.
|
|
SHI W, FENG Y H, CHENG G Q, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610-1623 (in Chinese).
|
| 20 |
RASHID T, SAMVELYAN M, DE WITT C S, et al. Monotonic value function factorisation for deep multi-agent reinforcement learning[J]. The Journal of Machine Learning Research, 2020, 21(1): 7234-7284.
|
 ), 王振亚2, 朱奕超1, 彭冬亮1
), 王振亚2, 朱奕超1, 彭冬亮1