Acta Aeronautica et Astronautica Sinica ›› 2026, Vol. 47 ›› Issue (8): 332786.doi: 10.7527/S1000-6893.2025.32786
• Electronics and Electrical Engineering and Control • Previous Articles
Yuheng LIU, Li YANG, Qilong HUANG( )
)
Received:2025-09-15
Revised:2025-09-27
Accepted:2025-10-21
Online:2025-10-31
Published:2025-10-30
Contact:
Qilong HUANG
E-mail:huangql@njust.edu.cn
Supported by:CLC Number:
Yuheng LIU, Li YANG, Qilong HUANG. Optimizing air and missile defense strategies with explainable hierarchical reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2026, 47(8): 332786.
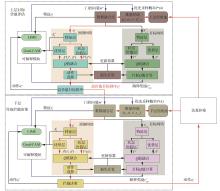
Fig.1
Overall architecture of algorithm
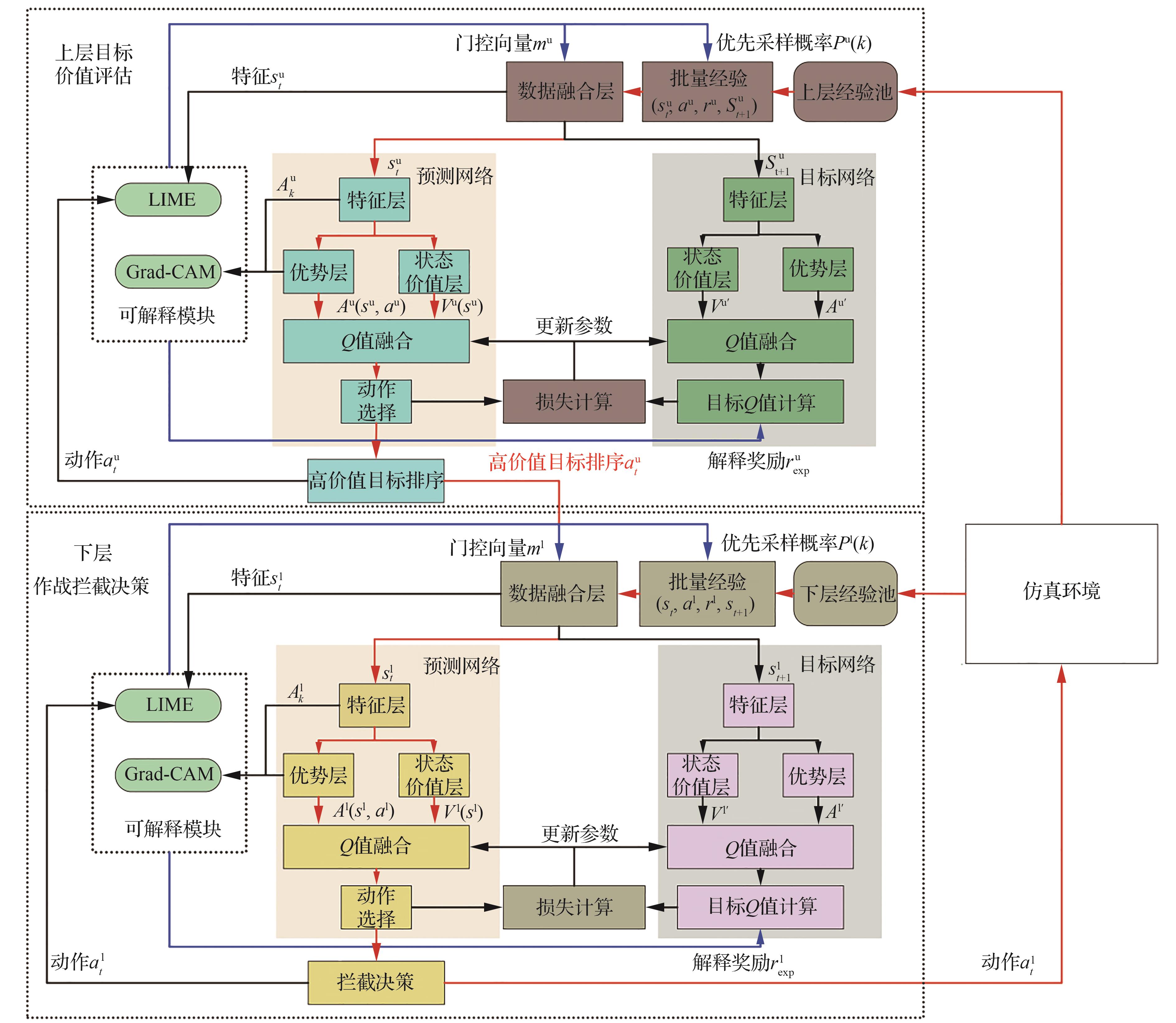
Table 1
Simulation parameter information of different fire units
| 类别 | 弹药数量 | 火力单元数量 | 弹药速度 |
|---|---|---|---|
| 远程火力单元 | 16 | 1 | 高 |
| 中程火力单元 | 20 | 2 | 中 |
| 近程火力单元 | 30 | 2 | 低 |
Table 2
Kinematic parameters of incoming platforms and interceptor
| 类别 | 速度/(km·s-1) | 最大转率/(rad·s-1) |
|---|---|---|
| 战斗机 | 0.25 | 0.10 |
| 巡航导弹 | 0.24 | 0.21 |
| 无人机 | 0.06 | 0.05 |
| 远/中/近程拦截弹 | 0.90/0.65/0.45 | 0.35/0.28/0.22 |
Table 3
Network and key hyperparameters
| 网络 | 隐藏 层数 | 每层 神经元 | 折扣 因子 | 学习率/ 10-4 | 初始 探索率 | 最小 探索率 | 探索率衰减轮次/103 | 经验回放 容量/10⁴ | 批量大小 | 训练回合 数/103 |
|---|---|---|---|---|---|---|---|---|---|---|
| 上层策略网络(U) | 2 | 256 256 | 0.99 | 1 | 1.00 | 0.05 | 1 | 5 | 64 | 4 |
| 下层策略网络(L) | 2 | 128 128 | 0.99 | 2 | 1.00 | 0.05 | 1 | 2 | 128 | 4 |
Fig.2
Algorithm comparison experimental results
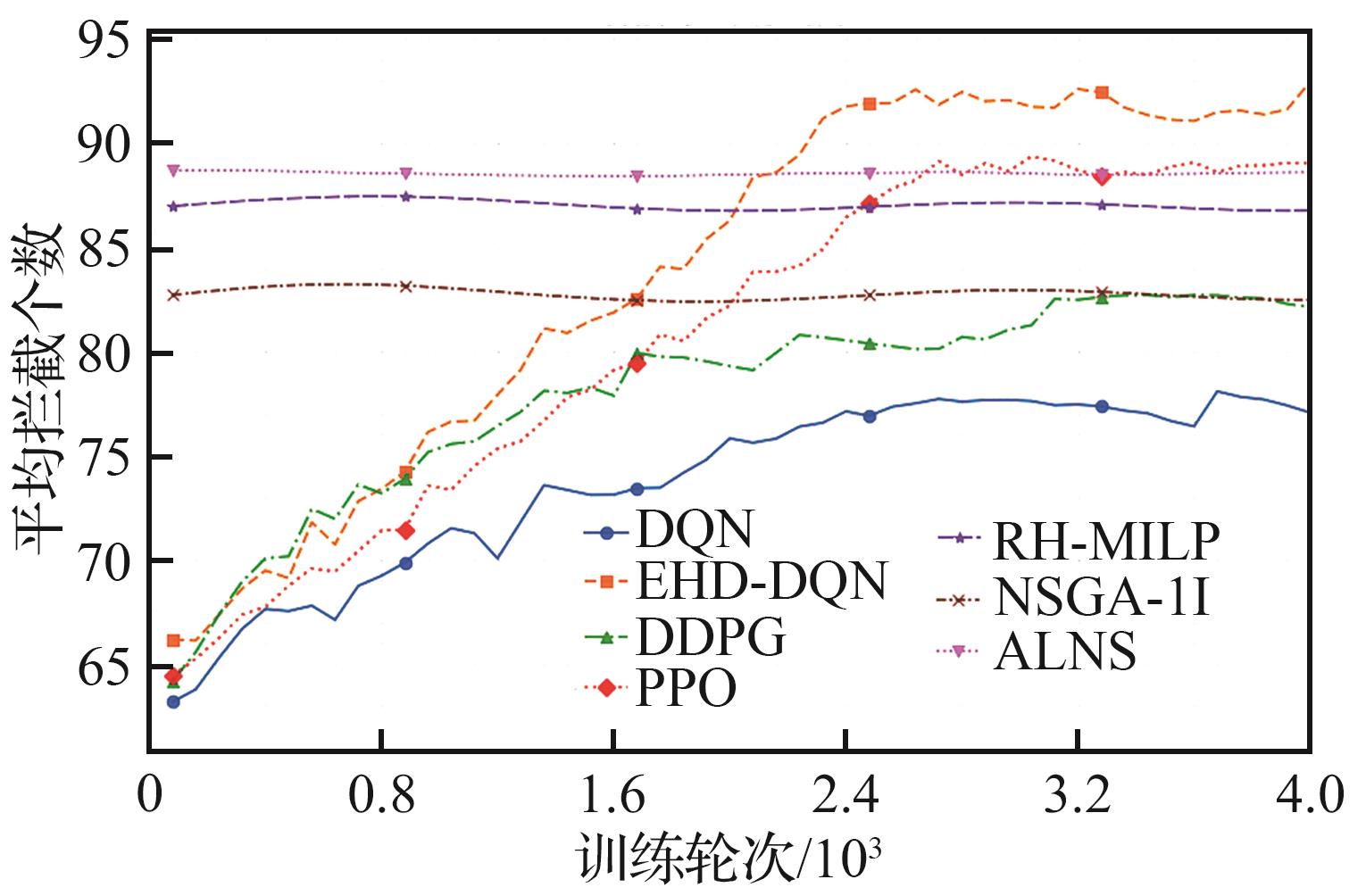

Fig.3
Target interception efficiency comparison
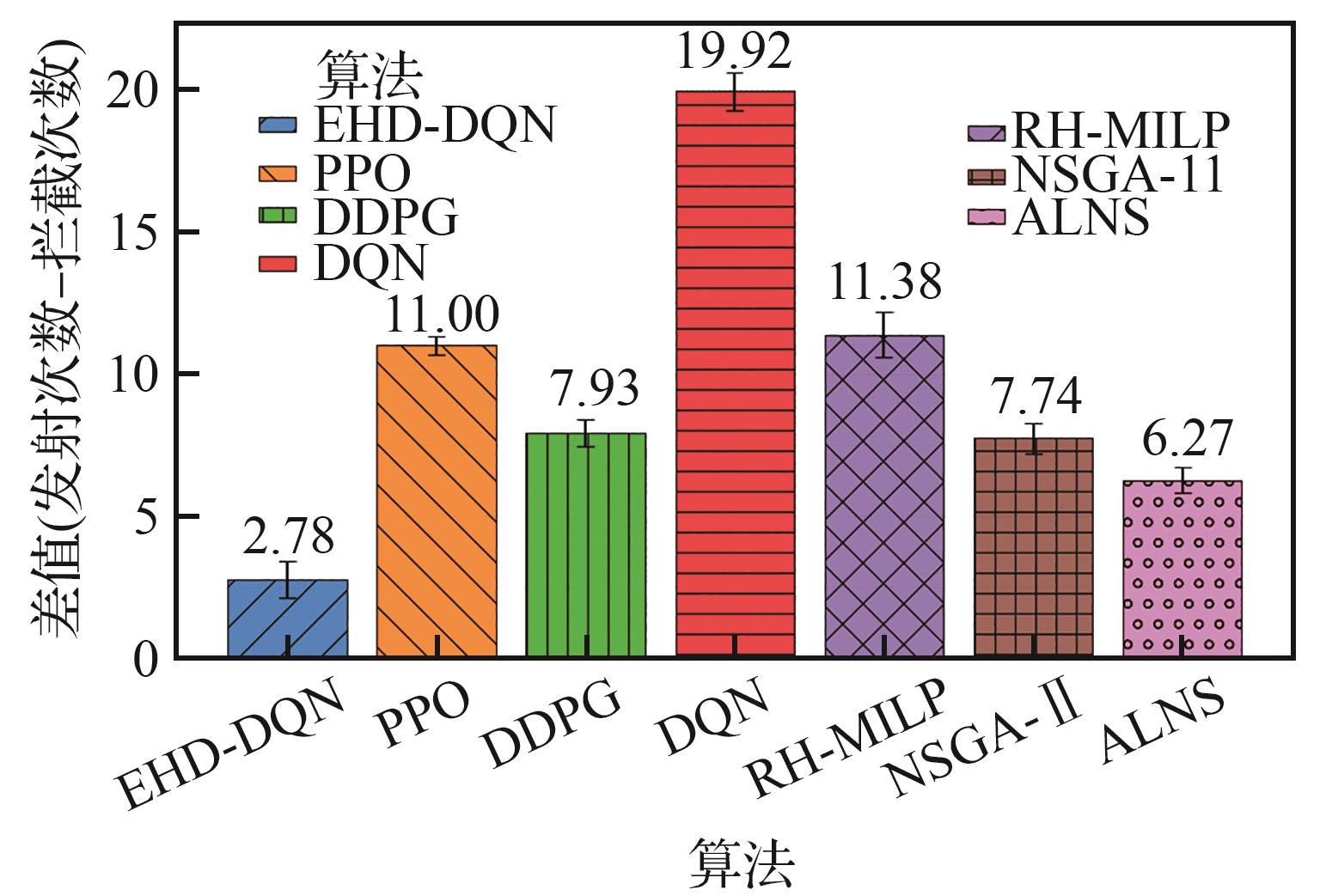
Fig.4
Comparison of high-value target interception efficiency
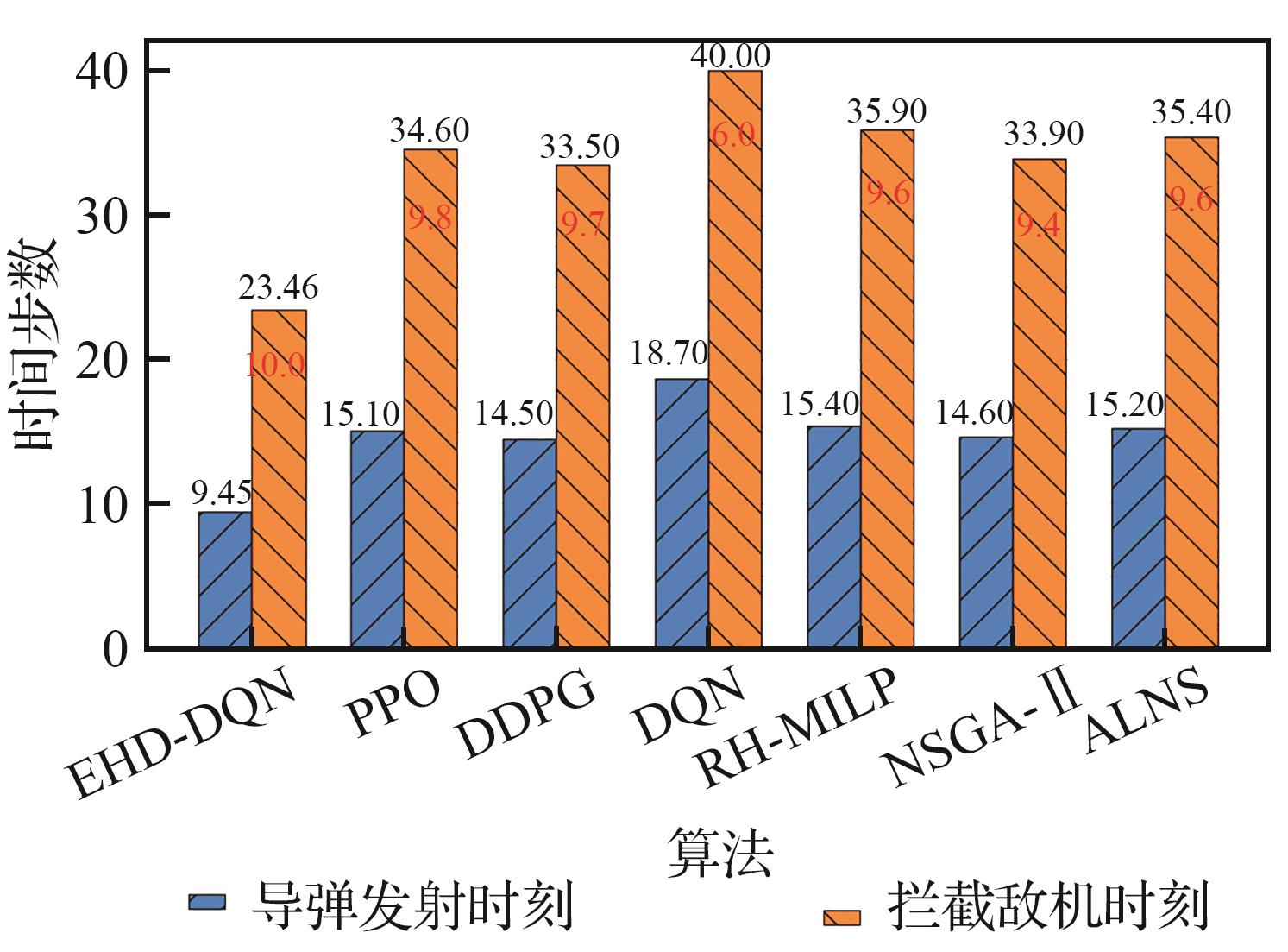
Table 4
Ranking and allocation of high-value targets at key stages
| 阶段 | 时刻 | 上层高价值目标(ID/类型/距目标) | 下层分配 |
|---|---|---|---|
| 前期 | 2 | T07/战斗机/120,T03/战斗机/128,T05/战斗机/132,T12/巡航弹/160,T21/巡航弹/168 | LR1→T07,MR1→T12,MR2→T21,SR1→T31,SR2→T33 |
| 前期 | 4 | T07/战斗机/120,T03/战斗机/128,T05/战斗机/132,T12/巡航弹/160,T21/巡航弹/168 | LR1→T03,MR1→T09,MR2→T27,SR1→T36,SR2→T37 |
| 中期 | 12 | T27/巡航弹/68,T18/巡航弹/72,T24/巡航弹/80,T32/巡航弹/83,T05/战斗机/76 | LR1→T05,MR1→T18,MR2→T27,SR1→T35,SR2→T40 |
| 中期 | 14 | T18/巡航弹/66,T24/巡航弹/74,T38/巡航弹/82,T34/巡航弹/84,T41/无人机/96 | LR1→T11,MR1→T18,MR2→T24,SR1→T41,SR2→T38 |
| 后期 | 22 | T33/无人机/70,T40/无人机/74,T41/无人机/78,T24/巡航弹/63,T32/巡航弹/72 | LR1→T24,MR1→T32,MR2→T38,SR1→T33,SR2→T40 |
| 后期 | 24 | T40/无人机/68,T41/无人机/70,T42/无人机/72,T34/巡航弹/71,T29/巡航弹/73 | LR1→T34,MR1→T29,MR2→T32,SR1→T40,SR2→T41 |
Table 5
Statistics of single-round interception failure
发射时刻/ 时间步 | 火力单元 | 目标ID/类型 | 脱靶距离/km |
|---|---|---|---|
| 12 | MR1 | T18巡航导弹 | 71 |
| 14 | MR2 | T24巡航导弹 | 73.3 |
| 24 | SR2 | T41无人机 | 1.8 |
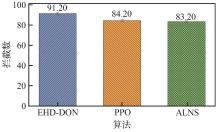
Fig.5
Algorithm comparison experimental results in new scenario
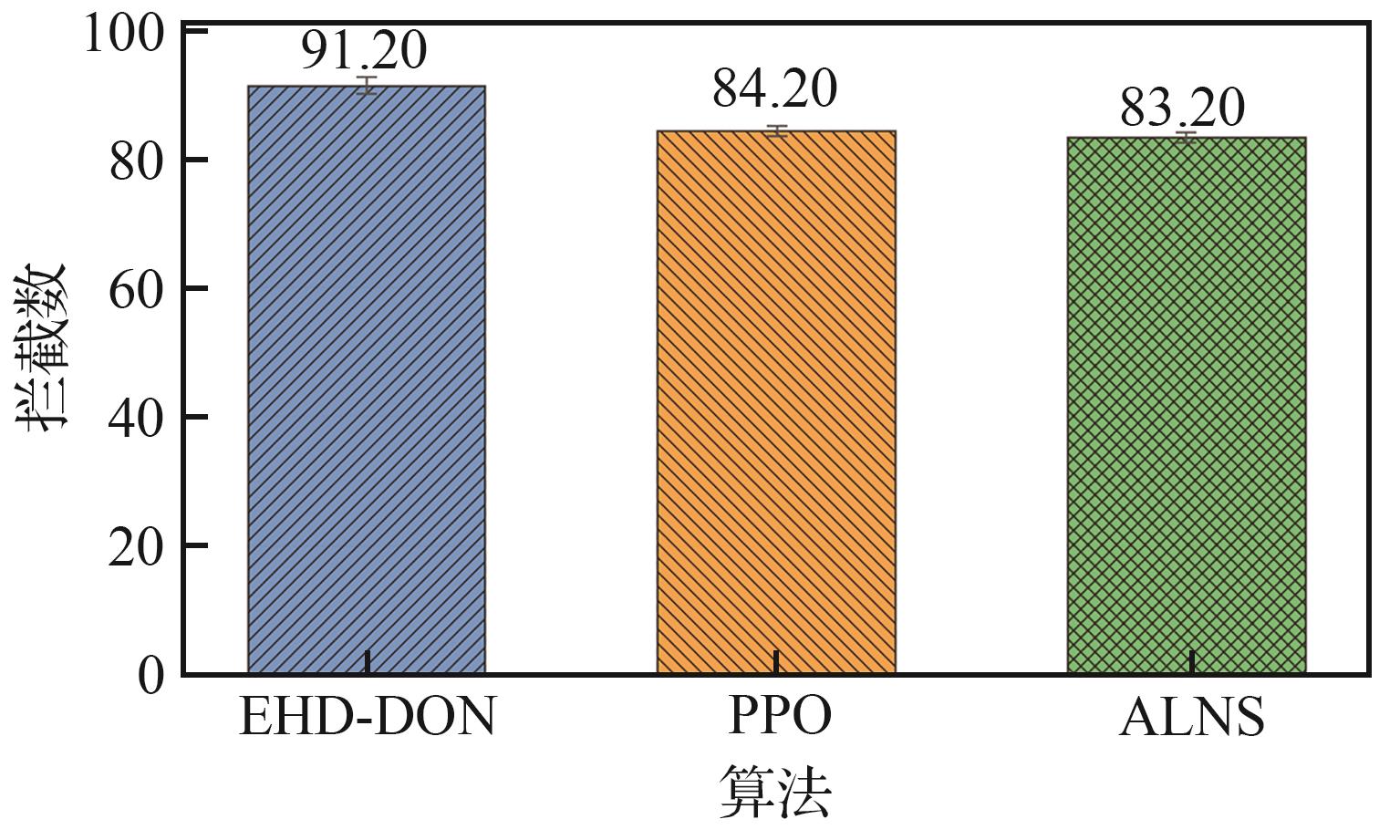
Fig.6
Layered architecture ablation experiment
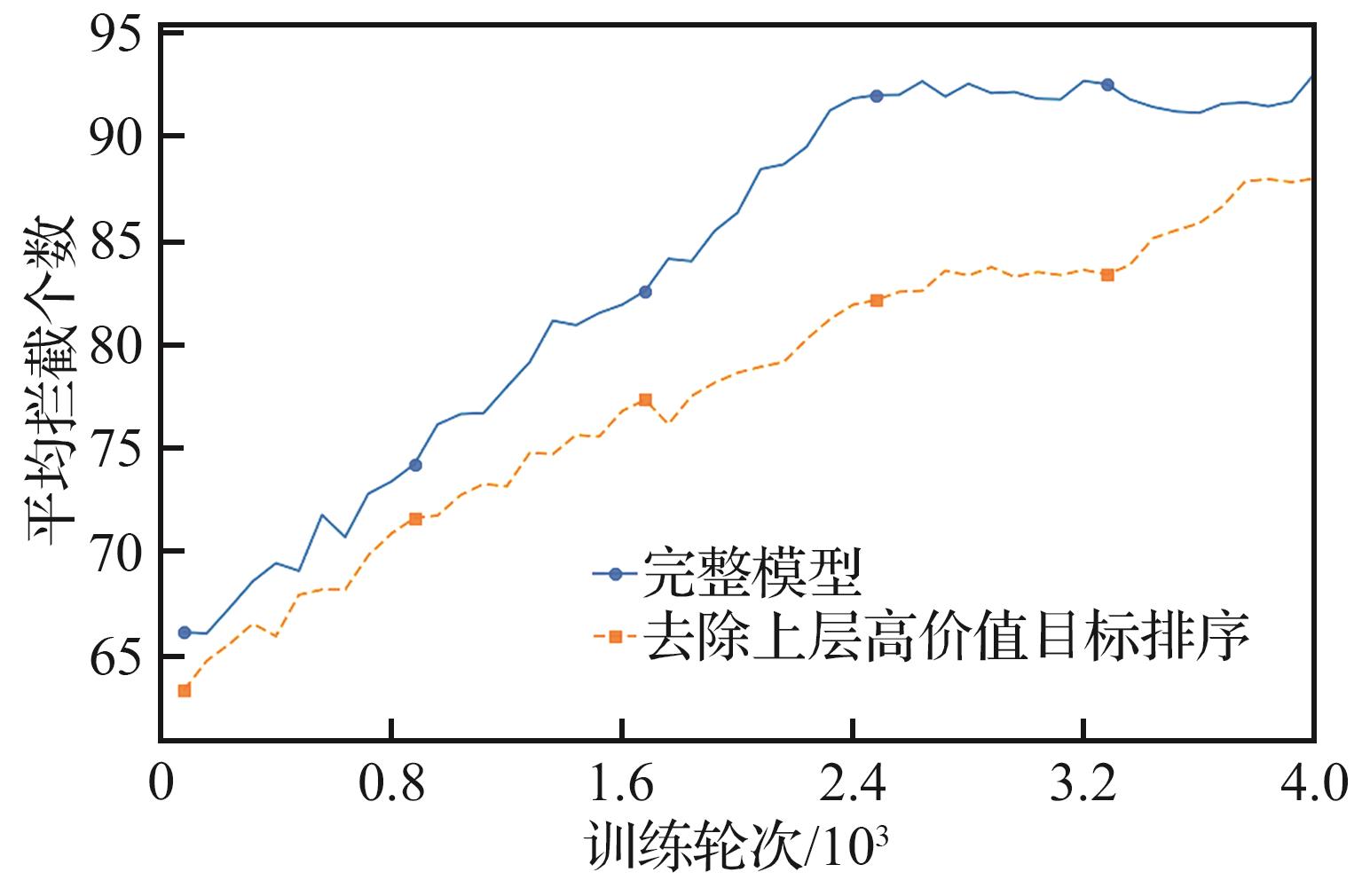
Fig.7
Multiple experience pool design ablation experiment
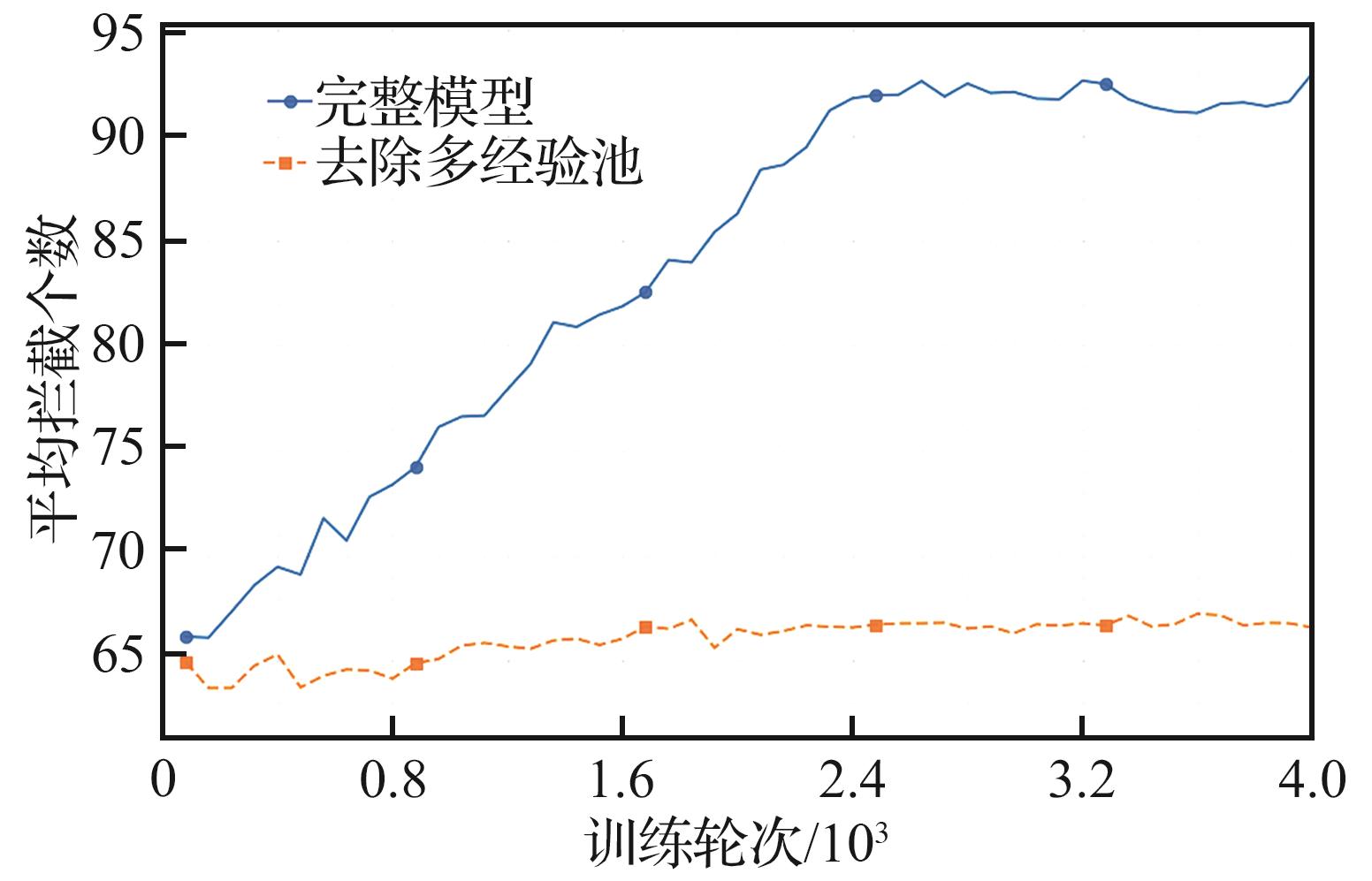
Fig.8
Time parameter ablation experiment
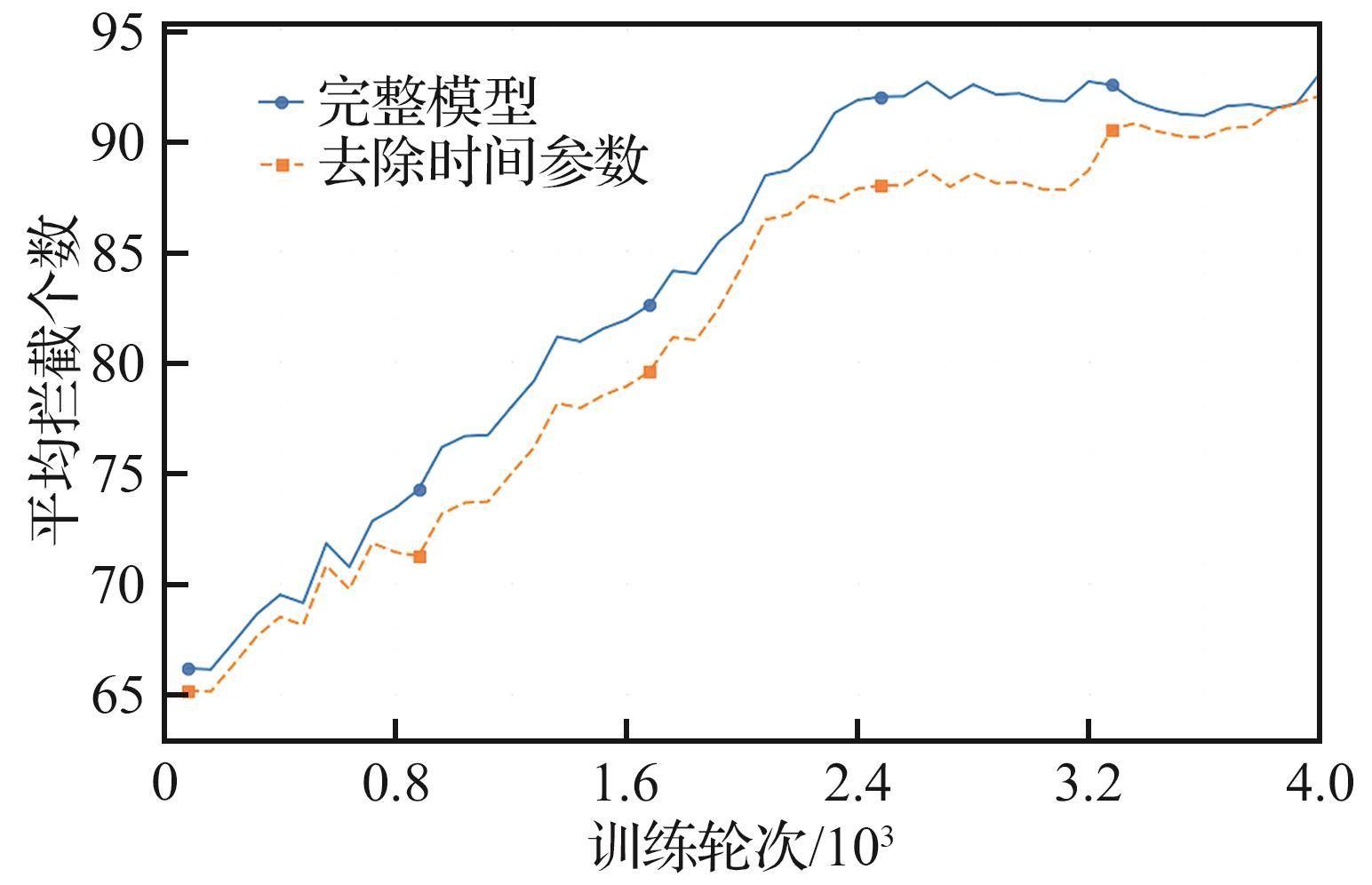
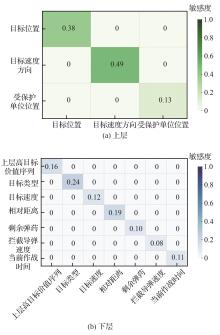
Fig.9
Feature sensitivity heatmap
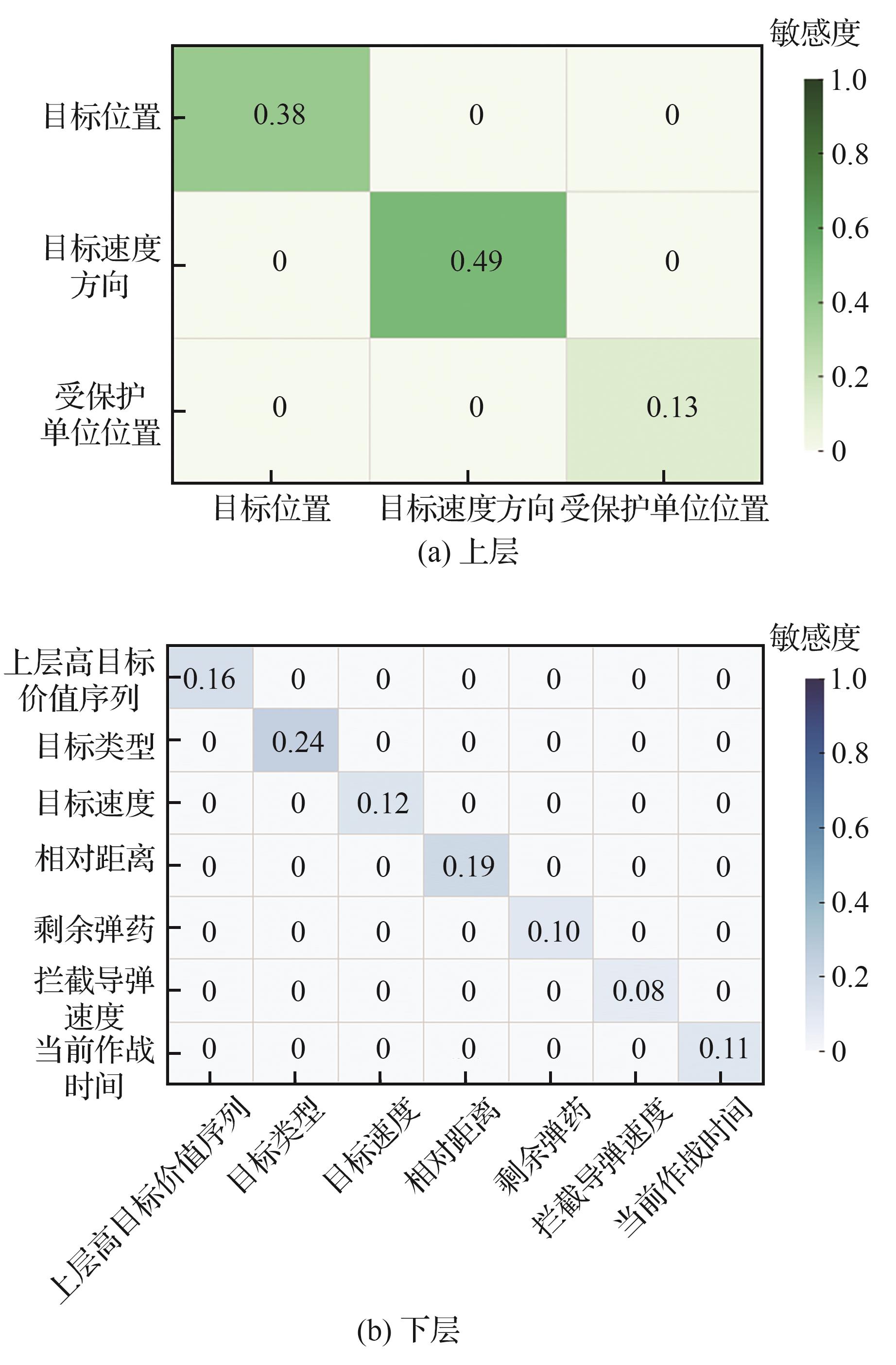
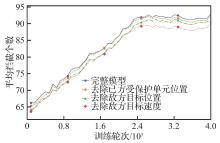
Fig.10
Upper layer feature ablation experiment
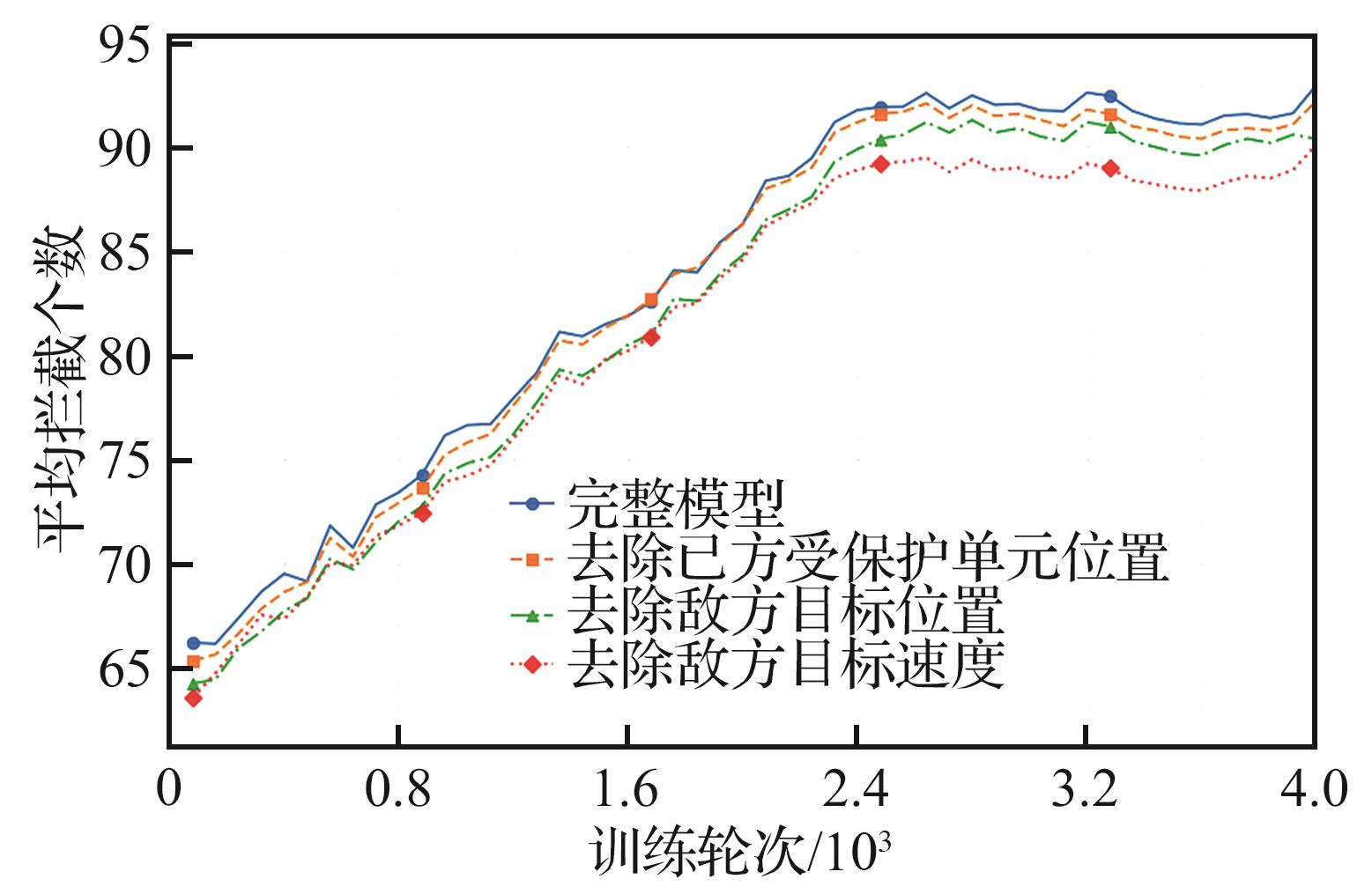
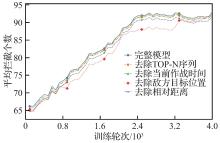
Fig.11
Lower layer feature ablation experiment
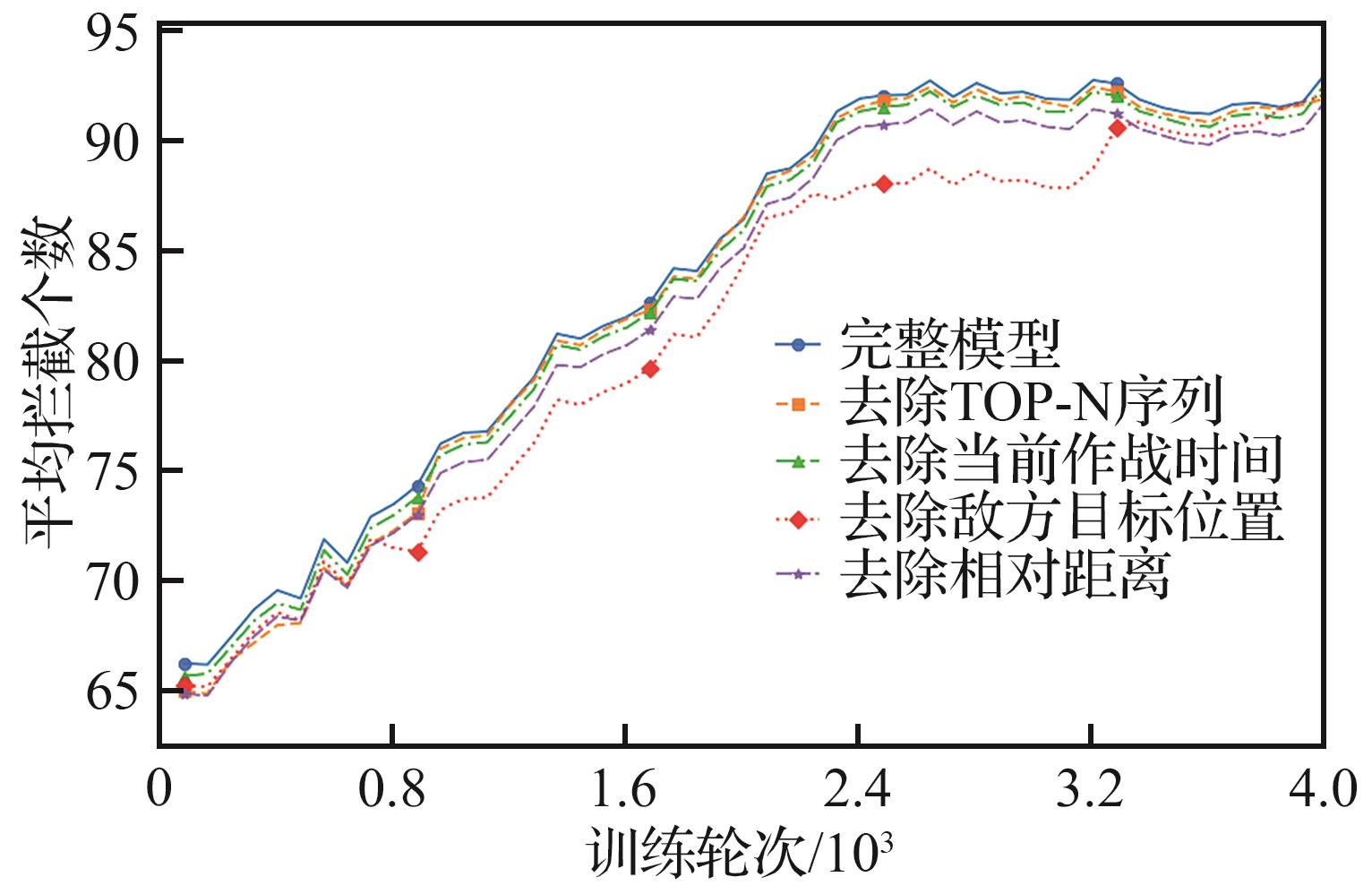

Fig.12
LIME weight of upper-level decision-making in early stage of combat
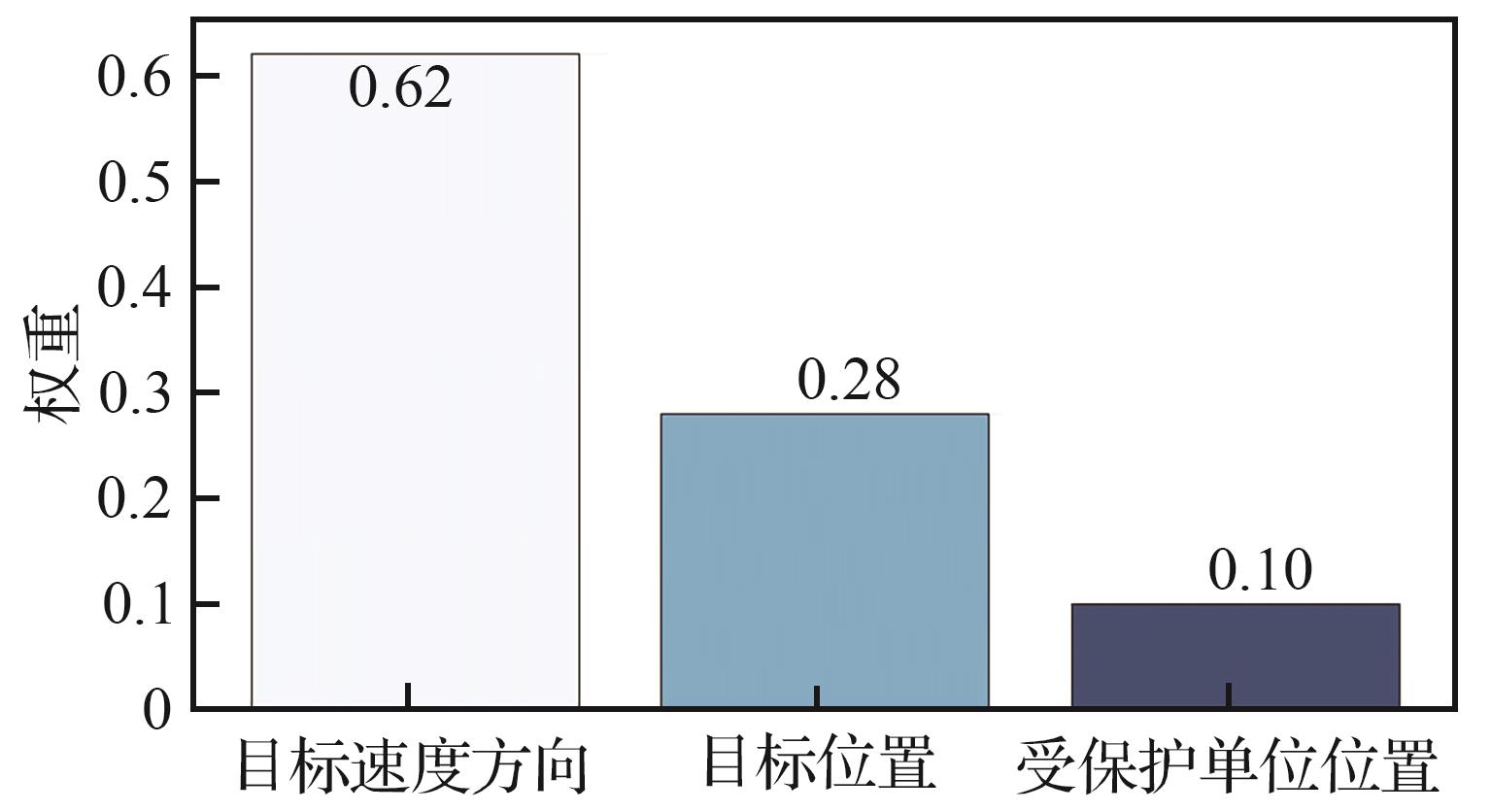
Fig.13
LIME weights of lower-level decisions in early stages of operations
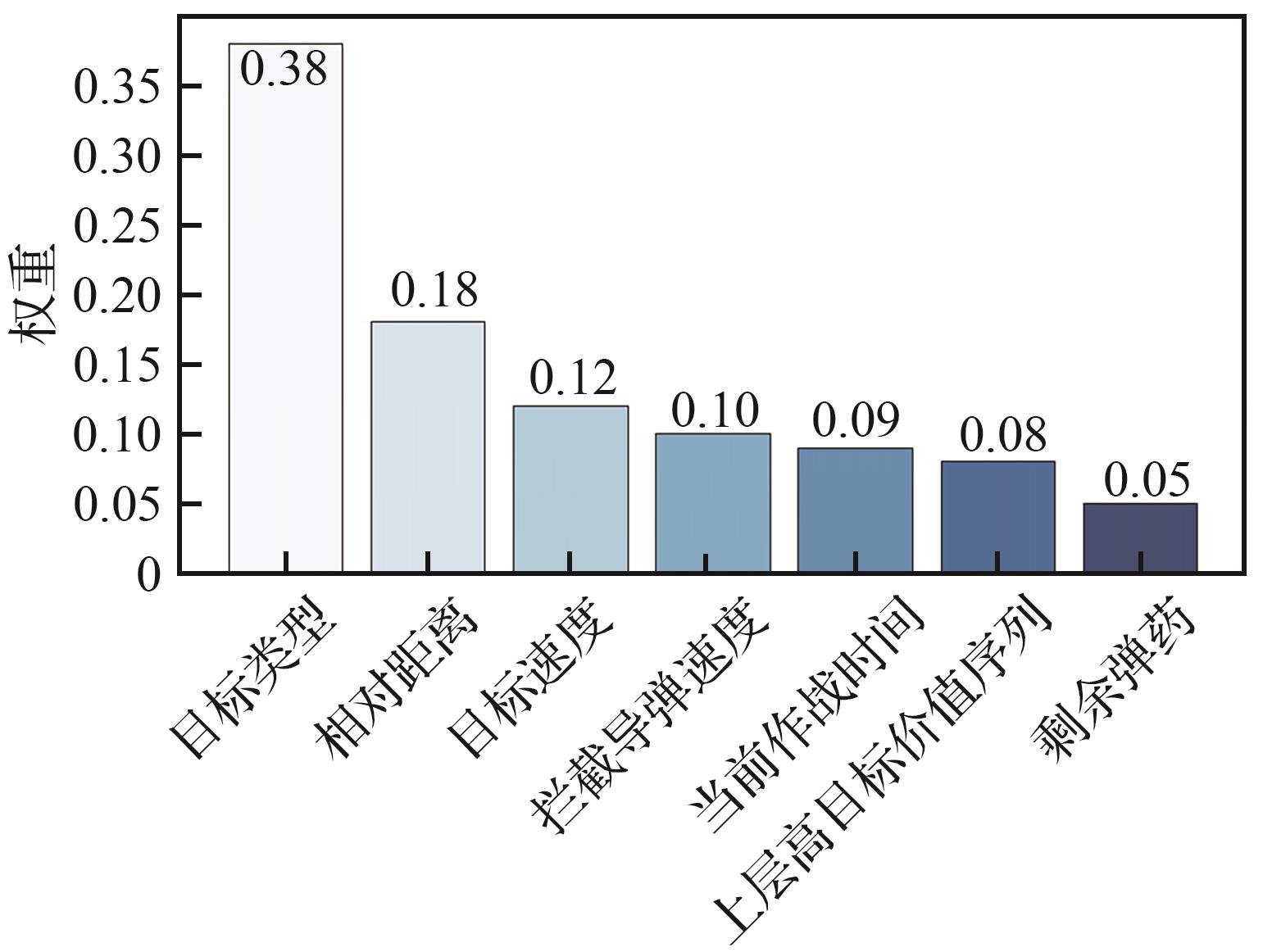
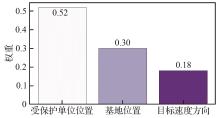
Fig.14
LIME weight of upper-level decision-making in late stage of combat
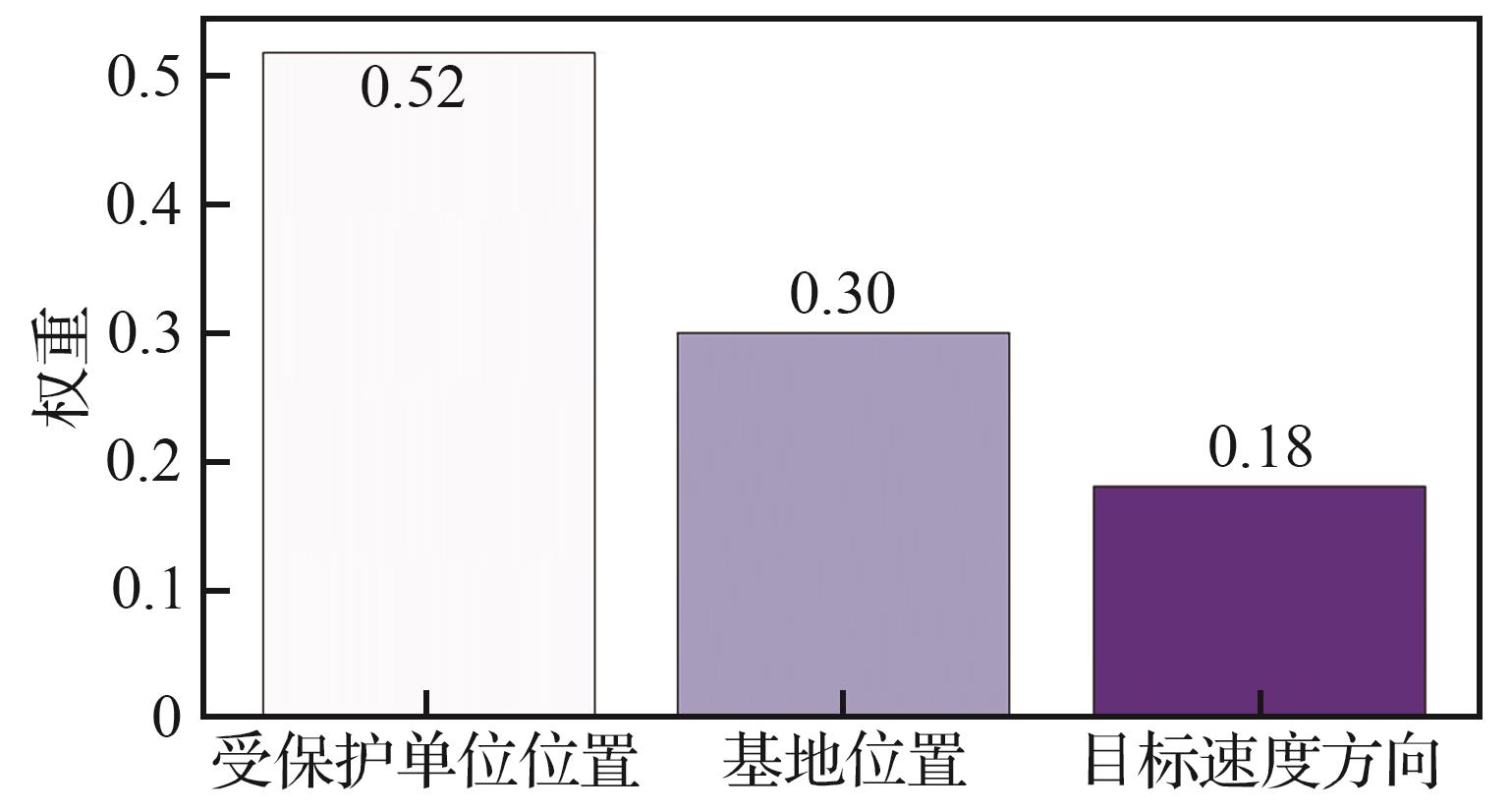
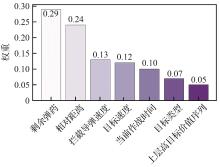
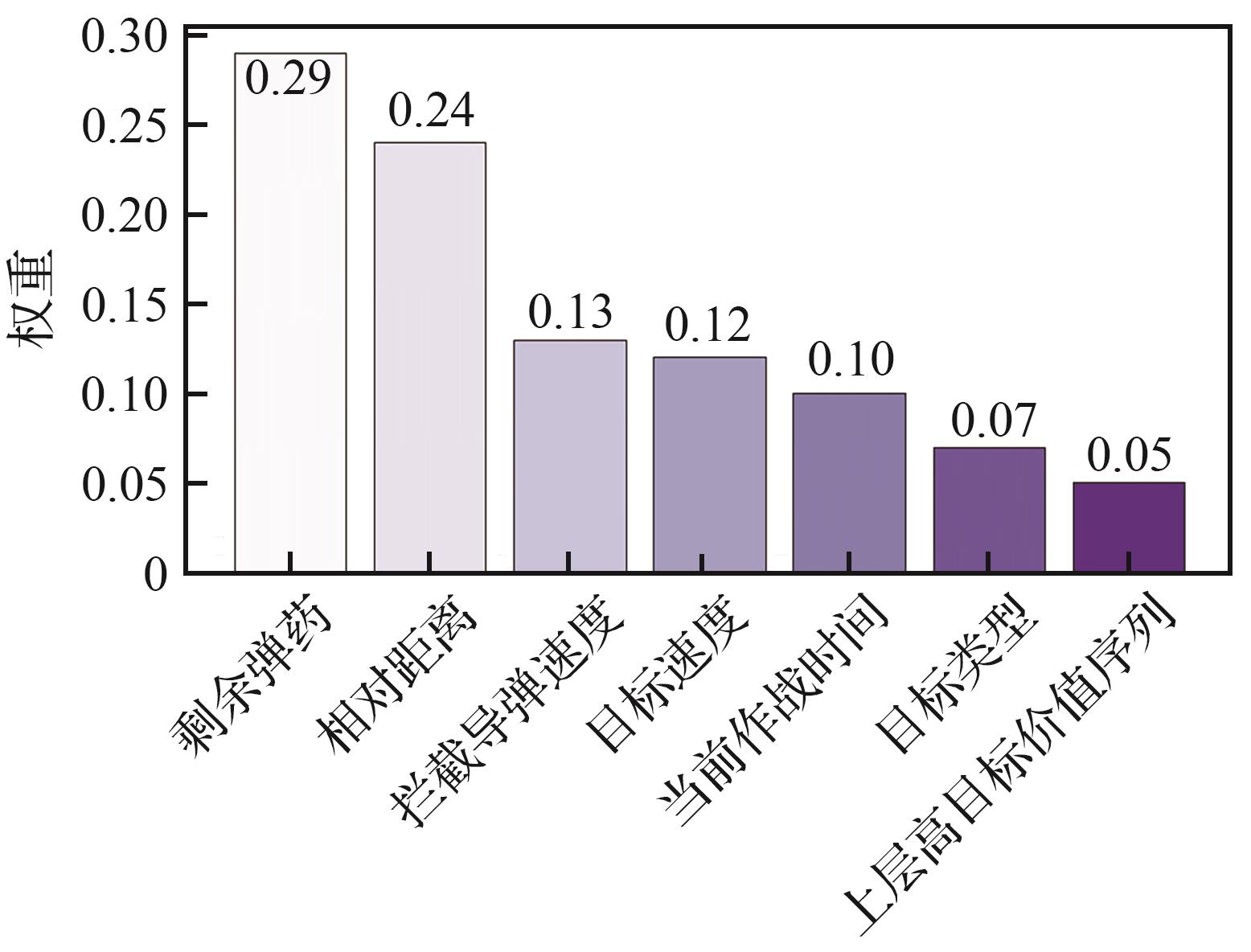
Fig.15
LIME weight of lower-level decision-making in late stage of combat
| [1] | 刘伟, 张琳, 王代强, 等. 激光武器反无人机集群作战运用及关键技术[J]. 航空学报, 2024, 45(12): 329457. |
| LIU W, ZHANG L, WANG D Q, et al. Application and key technologies of laser weapons in anti-UAV swarm operations[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(12): 329457 (in Chinese). | |
| [2] | SUN Z Y, YANG J Y. Multi-missile interception for multi-targets: Dynamic situation assessment, target allocation and cooperative interception in groups[J]. Journal of the Franklin Institute, 2022, 359(12): 5991-6022. |
| [3] | LI J R, WU G H, WANG L. A comprehensive survey of weapon target assignment problem: Model, algorithm, and application[J]. Engineering Applications of Artificial Intelligence, 2024, 137: 109212. |
| [4] | OH S H, BYUEON G W, CHO Y I, et al. Artificial intelligence in combat decision-making: Weapon target assignment via reinforcement learning and graph neural networks[J]. IEEE Transactions on Cybernetics, 2025, pp(99):1-13. |
| [5] | TUNCER O, CIRPAN H A. Adaptive fuzzy based threat evaluation method for air and missile defense systems[J]. Information Sciences, 2023, 643: 119191. |
| [6] | CHEN L, YANG J, ZHOU Y Z, et al. A rule-based agent for unmanned systems with TDGG and VGD for online air target intention recognition[J]. Drones, 2024, 8(12): 765. |
| [7] | COSKUN M, TASDEMIR S. Fuzzy logic-based threat assessment application in air defense systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(3): 2245-2251. |
| [8] | PIRES H B, GUIMARÃES L N F. Dynamic multi-target three-way threat assessment in the context of air defense[J]. IEEE Access, 2024, 12: 141397-141413. |
| [9] | PIRES H B, GUIMARÃES L N F, REBOUÇAS S. A multi-target threat assessment method based on objective three-way decision[J]. IEEE Access, 2025, 13: 681-694. |
| [10] | 刘富樯, 周伦, 刘中阳, 等. 基于三支决策和遗传算法的动态武器目标分配[J]. 兵工学报, 2025, 46(3): 240281. |
| LIU F Q, ZHOU L, LIU Z Y, et al. Dynamic weapon-target assignment based on three-way decision and genetic algorithm[J]. Acta Armamentarii, 2025, 46(3): 240281 (in Chinese). | |
| [11] | 唐明南, 张承龙, 赵强, 等. 任务场景驱动的防空资源部署方案智能生成与优化方法[J]. 现代防御技术, 2023, 51(3): 1-9. |
| TANG M N, ZHANG C L, ZHAO Q, et al. Scenario-driven and intelligent optimization of disposition scheme for air defense[J]. Modern Defense Technology, 2023, 51(3): 1-9 (in Chinese). | |
| [12] | 毕文豪, 周久力, 段晓波, 等. 基于多要素改进NSGA-Ⅱ的小直径制导炸弹空面打击最优火力分配方法[J]. 航空学报, 2023, 44(17): 328116. |
| BI W H, ZHOU J L, DUAN X B, et al. Optimal fire distribution method of small diameter guided bomb in air-to-surface strike based on multi-factor modified NSGA-Ⅱ[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(17): 328116 (in Chinese). | |
| [13] | SONG J M, CHENG T, WANG Y M, et al. LPI-based resource allocation strategy for multiple targets tracking in CMIMO radar system with array division[J]. Signal Processing, 2024, 225: 109625. |
| [14] | BERTSIMAS D, PASKOV A. Solving large-scale weapon target assignment problems in seconds using branch-price-and-cut[J]. Naval Research Logistics (NRL), 2025, 72(5): 735-749. |
| [15] | 隆雨佟, 陈爱国, 史红权, 等. 基于改进差分进化算法的跨平台武器目标分配方法[J]. 系统工程与电子技术, 2024, 46(3): 953-962. |
| LONG Y T, CHEN A G, SHI H Q, et al. Cross-platform weapon target allocation method based on improved differential evolution algorithm[J]. Systems Engineering and Electronics, 2024, 46(3): 953-962 (in Chinese). | |
| [16] | YI X J, YU H Y, XU T. Solving multi-objective weapon-target assignment considering reliability by improved MOEA/D-AM2M[J]. Neurocomputing, 2024, 563: 126906. |
| [17] | Lu Y, Chen D Z, Gao T. An exact algorithm for the dynamic two-stage weapon-target assignment problem: abstract=4485993[R]. SSRN, 2023. |
| [18] | 孙昕, 邢立宁, 王锐, 等. 基于多目标进化算法的防空导弹武器目标分配[J]. 系统仿真学报, 2024, 36(6): 1298-1308. |
| SUN X, XING L N, WANG R, et al. Air defense missile weapon target assignment based on multi-objective evolutionary algorithm[J]. Journal of System Simulation, 2024, 36(6): 1298-1308 (in Chinese). | |
| [19] | ZHAO J, LV Y F. Output-feedback robust control of systems with uncertain dynamics via data-driven policy learning[J]. International Journal of Robust and Nonlinear Control, 2022, 32(18): 9791-9807. |
| [20] | 高树一, 林德福, 郑多,等. 考虑拦截器探测能力限制的飞行器智能机动突防制导策略[J]. 航空学报, 2025, 46(10): 331304. |
| GAO S Y, LIN D F, ZHENG D, et al. Intelligent maneuvering penetration guidance strategies for aerial vehicles considering interceptor detection capability limitations[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(10): 331304 (in Chinese). | |
| [21] | ZHAO M R, WANG G, FU Q, et al. Intelligent decision‐making system of air defense resource allocation via hierarchical reinforcement learning[J]. International Journal of Intelligent Systems, 2024, 2024(1): 7777050. |
| [22] | LI T, WANG G, FU Q, et al. An intelligent algorithm for solving weapon-target assignment problem: DDPG-DNPE algorithm[J]. Computers, Materials & Continua, 2023, 76(3): 3499-3522. |
| [23] | NA H, AHN J, MOON I C. Weapon-target assignment by reinforcement learning with pointer network[J]. Journal of Aerospace Information Systems, 2023, 20(1): 53-59. |
| [24] | 闫世祥, 刘海军. 基于深度强化学习的传感器-武器-目标分配方法[J]. 现代防御技术, 2025, 53(4): 10-17. |
| YAN S X, LIU H J. Sensor-weapon-target assignment method based on deep reinforcement learning[J]. Modern Defense Technology, 2025, 53(4): 10-17 (in Chinese). | |
| [25] | QIN P, ZHAO T. Knowledge guided fuzzy deep reinforcement learning[J]. Expert Systems with Applications, 2025, 264: 125823. |
| [26] | VOUROS G A. Explainable deep reinforcement learning: state of the art and challenges[J]. ACM Computing Surveys, 2022, 55(5): 1-39. |
| [27] | 张晨浩, 周焰, 蔡益朝, 等. 空中目标作战意图识别研究综述[J]. 现代防御技术, 2024, 52(4): 1-15. |
| ZHANG C H, ZHOU Y, CAI Y C, et al. A review of air target operational intention recognition research[J]. Modern Defense Technology, 2024, 52(4): 1-15 (in Chinese). | |
| [28] | KIM J E, LEE C H, YI M Y. A study on the weapon–target assignment problem considering heading error[J]. International Journal of Aeronautical and Space Sciences, 2024, 25(3): 1105-1120. |
| [29] | ZHAO K, SONG J, YU J W, et al. Integrated assignment and guidance with multi-objective function in a three-dimensional scenario[J]. Engineering Optimization, 2025: 1-16. |
| [30] | WONG A, BÄCK T, KONONOVA A V, et al. Deep multiagent reinforcement learning: Challenges and directions[J]. Artificial Intelligence Review, 2023, 56(6): 5023-5056. |
| [31] | MINH D, WANG H X, LI Y F, et al. Explainable artificial intelligence: A comprehensive review[J]. Artificial Intelligence Review, 2022, 55: 3503-3568. |
| [32] | GAJCIN J, DUSPARIC I. Redefining counterfactual explanations for reinforcement learning: Overview, challenges and opportunities[J]. ACM Computing Surveys, 2024, 56(9): 1-33. |
| [33] | RIBEIRO M, SINGH S, GUESTRIN C. “Why should I trust you?” Explaining the predictions of any classifier[C]∥2016 Conference of the north American chapter of the association for computational linguistics: Demonstrations. San Diego: NAACL, 2016: 97-101. |
| [34] | SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128: 336-359. |
| [1] | Peizhao WANG, Ming HE, Haihua CHEN, Hongpeng WANG. Real-time task scheduling algorithm for FANET considering communication topology control [J]. Acta Aeronautica et Astronautica Sinica, 2026, 47(6): 332636-332636. |
| [2] | Yizhe LUO, Hui ZHANG, Xinde YU, Zhao JIN, Shuo FENG, Yucheng SHI, Mingling XU. Hierarchical dynamic scheduling for multi-wave carrier-based aircraft ammunition support missions [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(18): 331945-331945. |
| [3] | Chen WANG, Caisheng WEI, Zeyang YIN, Kai JIN, Xingchen LI. Collaborative planning of multi-UAV trajectories and communication strategies considering channel resource constraints [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(18): 331837-331837. |
| [4] | Yongjie ZHANG, Jingpiao ZHOU, Lei SHI, Dong LI, Binqian ZHANG. Optimization design method of central fuselage spherical deficient surface frames in blended⁃wing⁃body civil aircraft based on PRSEUS structure [J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(12): 229331-229331. |
| [5] | JIA Guanghui, DUAN Xiao. Enhanced collaborative optimization modeling method of BLE about honeycomb sandwich panel [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2015, 36(7): 2260-2268. |
| [6] | LIU Chengwu, JIN Xiaoxiong, LIU Yunping, LIU Jihong. Reliability-based Multidisciplinary Design Optimization Integrating BLISCO and iPMA [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2014, 35(11): 3054-3063. |
| [7] | JIA Zhigang, WANG Rongqiao, HU Dianyin. Application of Fluid-solid Coupling on Multidisciplinary Optimization Design for Turbine Blades [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2013, 34(12): 2777-2784. |
| [8] | LI Jiaozan, GAO Zhenghong. Multivariable Aerodynamic Design Based on Multilevel Collaborative Optimization [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2013, 34(1): 58-65. |
| [9] | WU Beibei, HUANG Hai, WU Wenrui. Multidisciplinary Design Optimization of Main Parameters of Spacecraft with Sub-vehicles [J]. ACTA AERONAUTICAET ASTRONAUTICA SINICA, 2011, 32(4): 628-635. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341