
无人机避让系统是在空域态势感知的基础上,为无人机提供必要的警报和避让服务,以确保在入侵机出现时本机仍能安全飞行。随着中国低空开放力度不断加大,无人机在隔离空域执行简单任务逐步过渡到混合空域执行复杂任务已成为发展趋势[1-2]。与此同时,中国首个民用无人机系统的安全要求国家标准GB 42590—2023[3]明确指出:“无人机应具备相应的识别和避障功能,能够自动识别和避让障碍物”。
传统的避让功能通过基于规则的策略实现,如当前大型运输航空器普遍安装的空中交通预警和防撞系统(Traffic Alert and Collision Avoidance System,TCAS),使用本机和入侵机到达最接近点时间作为主要决策依据[4]。考虑到非合作交通、决策强度和飞行员假设等问题,形成了基于优化策略的机载防撞系统[5](Airborne Collision Avoidance System X,ACAS X)。ACAS X基于马尔科夫决策过程(Markov Decision Process,MDP),通过监督学习技术构建策略的离线代价表,并加权在线代价,相比于TCAS,ACAS X为驾驶员提供了更加鲁棒的避让策略[6]。然而,在复杂混合空域场景下,离线代价表需要大量的飞行数据更新以适应变化的空域环境,难以实现避让系统的快速应用。同时,基于在线动态规划的策略也无法满足紧急避让场景的实时计算,而基于离散化状态空间和动作空间的设计,难以满足灵活控制需求。
强化学习(Reinforcement Learning,RL)是一种通过与环境交互并从反馈信息中学习最优决策的智能算法[7]。RL结合神经网络进行策略/价值函数近似时,能够更高效地处理高维状态空间,并适应复杂且动态变化的任务环境,因此在多个领域受到广泛关注。Wulfe[8]针对ACAS X存在的问题,基于强化学习,通过深度Q网络拟合避让策略,经蒙特卡洛验证,其相比于优化策略更安全和高效。但动作空间仍是离散化设计,限制了该策略的灵活性,在复杂环境中无法实现精准避让控制。汤新民等[9]将避免警报逻辑和MDP相结合,通过RL拟合避让策略。仅在固定航迹场景下的实验证明,RL模型提供的策略更加高效和安全,但未验证模型在不同场景下的泛化能力,未进一步给出相关的安全性证明。Hu等[10]针对离散控制等问题,基于近端策略优化(Proximal Policy Optimization,PPO)算法,设计连续动作空间的避让任务,并通过实验证明该模型能够提供更加准确、稳健的避让动作。然而,验证过程仅考虑了与训练场景一致的情况,未涉及分布外的场景或全面的安全性验证和分析。尽管上述文献通过实验表明了RL算法在避让任务中表现优异,但针对适航符合性相关的安全验证和定量评估方法仍有所欠缺。
机器学习由于神经网络的不确定性,给机载系统的定量安全性评估与验证带来了挑战,极大限制了其装机应用。马赞等[11]提出了一种基于泛化边界的CNN分类器的不确性量化方法,以支持基于SAE ARP4761[12]的安全性评估过程。为确保ACAS X神经网络的安全性,文献[13-14]基于可达性分析对其进行形式化验证,以明确避让策略在不同飞行环境下的可靠性。然而,上述方法多局限于图像分类等监督学习任务[15-16],只验证了其在微小扰动和特定输入空间内的安全性质。而强化学习(RL)在训练中还受到环境动态性、奖励反馈延迟与策略优化目标变化等多重因素影响,使得不确定性量化方法难以直接迁移。此外,由于时刻前后的状态动作耦合性强,给形式化验证带来了双重维度灾难,难以在确切时刻添加精准干扰完成有效的对抗测试,从而无法给出精确的失效概率评估。
神经网络的不确定性量化在其他领域中也受到广泛关注。例如,在连续控制领域,Mai等[17]提出了逆方差强化学习方法,在评论家网络引入可学习的方差网络,显式解耦环境动态与策略优化的不确定性表征。在轨迹预测任务中,Pustynnikov等[18]设计了基于谱归一化神经网络编码器,通过预测的方差对不确定性进行建模。上述不确定性量化方法依赖于引入额外或复杂结构的神经网络,尽管在建模能力和性能上有所提升,但受限于神经网络固有的“黑箱”特性,其可解释性较差,难以满足安全性场景对透明性和可验证性的要求。文献[19]表明,高斯过程模型用于RL值函数估计时,性能与收敛速度不及深度神经网络,但其具有良好不确定性表征与可解释性。
本文将机载智能避让系统作为一个“黑盒”系统,在典型冲突场景下,基于无人机运动学模型与PPO算法,建立智能避让系统。将“黑盒”系统模型的验证任务[20]引入至强化学习,并与贝叶斯优化理论结合,通过3个获取函数完成对高斯代理模型的迭代式训练。在少量样本的情况下,实现对智能避让系统的安全验证、安全边界确定和功能失效概率分析,支持整机/系统定量安全性评估。最后,基于典型避让系统设计架构为案例,根据ARP4761标准进行初步安全性定量评估,结果表明该方法对适航安全性保证起到有效支撑,为智能避让系统的装机应用提供了必要的适航符合性方法和技术保证。
1 问题描述
1) 问题1:如何估计RL模型的失效概率。在基于MDP建模的冲突解脱任务中,无人机的碰撞并非由RL模型在单次交互中输出的不合理动作直接引起,而是由多个时间步内的动作序列相互作用、累积误差所导致的结果。这些动作之间的相互影响和耦合效应逐步引发了碰撞事件。高维状态-动作对序列的逐个分析给概率安全评估带来了维度灾难。同时,神经网络自身“黑盒”特性所造成的可解释性缺失、透明度差和决策过程不可溯源等问题,也进一步增加了对模型失效概率定量计算的难度。尤其在适航验证过程中,这些问题使得传统的适航验证方法难以有效地应用于RL模型。
基于需求满足性和场景符合性的“黑盒”测试法,其不依赖模型、通用性强和灵活度高等优势可以有效缓解上述问题。将整个冲突解脱过程视为“黑盒”系统,其失效概率计算如图1所示,冲突场景中的关键致因作为输入 ,经过系统 得到“事件”输出的碰撞结果 ,通过访问输入分布 计算系统失效概率 ,即

2) 问题2:如何确定安全边界。在冲突解脱任务中,安全边界指触发避障行为所需满足的最小空间距离或最晚响应时刻,其在确保飞行安全和任务稳定性方面具有关键作用。具体而言,安全边界的合理设计可确保RL策略在面临极端场景时,依然遵循系统的安全约束条件,避免因策略不稳定或响应滞后导致的碰撞等高风险行为。
在此基础上,本文定义的安全边界是指在RL策略部署前,通过对其在安全验证阶段的失效概率进行定量分析,结合预设的安全容忍阈值,推导出的最小安全距离或最短响应时间裕度。其核心目标在于提前识别并排除策略可能引发失效的状态空间区域,从而避免在任务执行中生成错误或不可接受的动作输出。
3) 问题3:如何在少样本情况下完成RL模型安全验证任务。基于问题1和问题2的验证需求,如果通过在输入空间X中离散化随机采样进行概率安全评估,则需要大量的采样点、较高的时间成本和巨大的计算开销,才能满足精度要求。
利用贝叶斯优化构建概率性代理模型,并不断进行更新迭代,提高准确性,从而支持通过选择最具风险的采样点进行验证来代替随机采样过程,可最大限度地降低验证计算成本,提高效率,实现输入空间上的连续预测。同时,代理模型在高维空间仍能有效识别失效区域,表现出较好的分类性能,验证了其在“黑盒”系统安全验证中的可行性与实用性,为冗余可靠性分析提供支持。
2 无人机智能避让模型建立
2.1 任务概述与控制设计
智能避让系统的设计主要涵盖任务描述、感知信息、控制动作和运动学方程。
1) 任务描述。假设在一定范围约束的三维空间内,一架装有智能避让系统的无人机从固定点出发行驶至随机目标点(距出发点大于一定距离且位于同水平高度),躲避从固定点出发随机移动的入侵无人机。
2) 感知信息。本机和入侵无人机的位置速度信息分别由GPS及ADS-B系统提供,当前时刻 的状态 包括本机位置 和速度 、N架入侵无人机的位置 和速度 以及目标点的位置 。
3) 控制动作。假设无人机机身方向速度固定为 ,策略网络 输出三维连续控制动作 。 为输出动作 的持续时间,考虑无人机执行任务时保持稳定以及避免过度操作,满足 ; 分别为偏航角变化率和俯仰角变化率,受到无人机自身动力学模型的约束和影响,满足 、 和 。
4) 运动学方程。通过偏航角 和俯仰角 的变化将机身方向速度分解,以 固定时间间隔更新本机位置信息,运动方程为
考虑圆柱碰撞模型,设置水平和垂直碰撞阈值分别为 和 ,与入侵无人机相对位置距离同时小于水平和垂直碰撞阈值时即认定发生碰撞。
2.2 基于PPO的智能避让算法
PPO[24]是基于策略梯度的强化学习算法,适用于连续动作控制任务。本文使用的2个参数化神经网络分别为值网络 和策略网络 ,分别用于输出动作 和近似状态价值函数。值网络基于均方误差和梯度下降法进行更新,策略网络通过裁剪函数进行优化更新,即
式中: 为当前策略 和旧策略 的比值差异,用于衡量策略 更新前后对动作选择的影响;为防止策略更新幅度过大导致训练不稳定,PPO引入了裁剪函数 ,将更新前后的 限制在 范围内,以防止模型过拟合; 为广义优势函数,用于评估采取动作后的状态优势值 ,通过引入权衡因子 平衡优势估计的方差和偏差,广义优势函数 表示为
PPO算法训练后确定参数化策略网络 作为智能避让系统的RL组件,用于飞行过程中完成自主导航和避让任务,进行安全性评估。
2.3 评估指标和场景模型
2.3.1 评估指标
智能避让系统在导航至目标点的过程中的主要任务为避免与入侵无人机发生碰撞,定义累计折扣碰撞概率为评估指标,即
式中: 为根据策略 采样出的轨迹; 为折扣因子,用于平衡长期碰撞概率估计; 为在状态 的碰撞概率。
2.3.2 评估场景模型
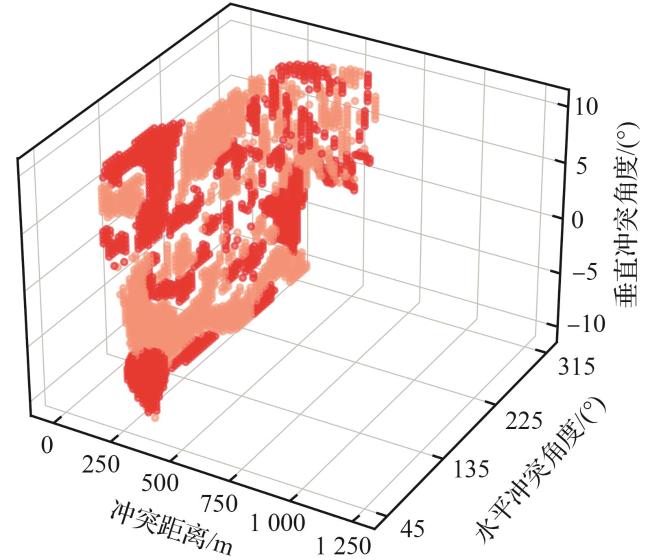
根据无人机间的相对位置不同,冲突场景可分为水平冲突和垂直冲突。水平冲突指无人机在同一高度平面内发生的潜在碰撞,通常表现为无人机之间的水平距离过近,存在发生相撞的风险;垂直冲突指无人机在不同的高度层次上发生的碰撞危险。本文的评估场景为装有智能避让系统的无人机与非合作的入侵机发生高风险水平冲突情况。根据最接近点时间,设定冲突解脱场景由冲突距离 和冲突角度 构建,如图2所示。
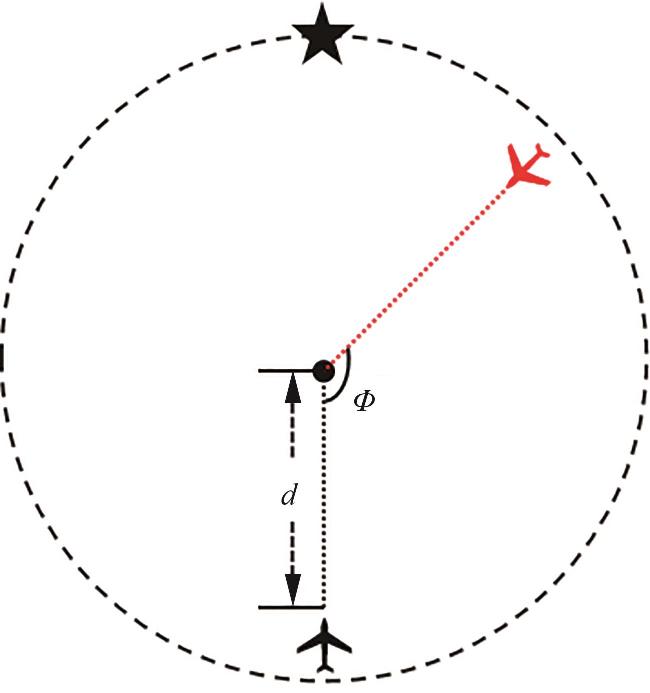
假设装有智能避让系统的无人机在到达目标点途中,遭遇以固定速度 直线运动的无人机。考虑终止时刻 到达目标点、发生碰撞或超出范围约束空间,使用 代替无限步长 , ;仅使用碰撞阈值作为碰撞准则,碰撞概率有 ,对式(5) 进行推导,则有
式中:参数化策略网络 确定策略 ;策略 、评估场景模型和无人机的运动学方程共同确定状态转移函数 。可将上述部分视为对“黑盒”系统内外影响的综合描述。
冲突解脱过程可以视为一条步长为 的采样轨迹,最终碰撞结果 可用二进制值表示,0表示未发生碰撞,1表示碰撞。其中,初始状态 可由 和 唯一确定,记作 ,有 ,则碰撞期望表示为
3 基于贝叶斯优化的智能避让系统定量评估算法
对于“黑盒”系统失效概率评估而言,与传统随机采样相比,基于贝叶斯优化理论迭代生成的模型,不仅能提供更加细致的失效边界预测和更加精确的失效概率估计,还能在保证结果准确性的前提下,大幅降低验证所需的样本量,减少无效的样本采集、大量计算开支和不必要的验证成本。
3.1 贝叶斯优化
贝叶斯优化是一种黑盒优化方法,在不需要关注目标函数 内部信息的情况下对其进行全局优化。
1) 将每次冲突解脱任务视为一个独立事件,考虑到“黑盒”系统内部过程的复杂性和不透明性,采用高斯过程建模这一类独立事件,通过捕获样本间关联信息,预测碰撞结果。假设目标函数 服从高斯过程,即
式中: 为输入集合; 为高斯过程的均值函数; 为高斯过程的协方差核函数。其中 ,用于计算样本点 和 的相关性。考虑系统失效区域分布的不规则和局部不光滑特征,使用的核函数为Matérn核函数[25],用于捕获失效区域的细微变化。其中,长度尺度 和标准差 ,即
2) 通过最大化获取函数 ,采集输入空间X中的下一个评估输入 添加至输入集合,即
由此得到真实值 ,添加至输出集合 。
3.2 获取函数设计
不同于传统优化问题中的最大化或最小化目标函数[26],验证问题关注的是避让系统的碰撞结果,其目标函数输出为 二进制值。然而,高斯过程输出均值为 连续的实值函数。因此,本文重新构建优化问题,通过3个获取函数,以平衡对高斯过程均值 和标准差 的探索和利用,用于“黑盒”系统安全验证。这些获取函数用于引导搜索过程,优化高斯过程的采样策略,以最大限度地提高碰撞结果的预测精度和安全验证的效率。
1) 不确定性探索。在高斯过程建模中,不确定性探索的核心目的是发现模型在输入空间中具有最大预测不确定性的区域。考虑高斯过程的标准差 ,搜寻不确定性最大的输入点 ,即
识别当前模型最不确定的输入点,即对碰撞结果预测最为模糊的区域。这些输入点通常是高斯过程对“黑盒”系统尚未充分了解或预测置信度较低的地方。
2) 边界细化。避让系统的安全验证中,目标函数输出为二进制值,而高斯过程输出为连续的概率预测。为准确识别失效边界区域,当高斯过程的均值 =0.5时,通过上置信采样[22]细化边界,找到失效边界输入点 ,即
式中:通过置信区间系数 ,探索碰撞边界附近失效区域;高斯过程迭代轮次 修正探索优先级,先对高分布输入区域进行边界细化保证失效概率精度。
3) 失效区域采样。文献[27]表明最优重要性采样分布为
基于目标函数的二进制输出,式(13) 直观地表示了最优采样应关注于失效区域( ),并根据输入分布 进行加权,即理想的采样分布应与失效发生的可能性成正比。为避免从输入分布 抽取大量样本进行评估,考虑高斯过程输出均值 来替代真实函数估计失效区域,并从置信上限 找到点 ,即
式中: 为指示函数,当 的值大于0.5时为1,反之为0。
3.3 训练流程
基于贝叶斯优化,高斯过程回归用于智能避让系统碰撞预测,训练流程如算法1所示。通过不确定性探索、边界细化和失效区域采样3个获取函数进行采样 ;通过目标函数 得到真实值 ;更新输入输出集合 ;经过迭代轮次 轮拟合训练。最后,完成训练并返回代理模型 。
| |
|---|
| 1.初始化输入空间;输入输出集合 ;高斯过程 ;分布函数 。 |
| 2. |
| 3. |
| 4. |
| 5. |
| 6. |
| 7. |
| 8. |
| 9. |
| 10. |
4 安全任务
4.1 RL模型安全验证
4.1.1 证伪
证伪过程旨在找出导致避让系统发生碰撞的输入。在基于采样测试的集合 中,定义失效样本集合 的占比作为评估指标,即
通过分析导致系统产生碰撞的样本,有助于识别出可能导致系统失效的边界,为优化策略网络、提高系统稳健性以及减少失效风险提供重要依据。
4.1.2 最可能失效分析
使用高斯过程估计输入空间 中导致系统最大失效概率样本点 和失效概率 ,即
为满足失效概率要求,RL模型的评估和迭代过程应重点关注最大失效概率样本附近区域。同时,应针对这些区域进行训练,并采取防止过拟合措施,以降低模型的失效概率。
4.1.3 失效概率估计
由于系统失效区域通常概率极低,直接在 下采样可能难以获得有效样本。为了有效且无偏地估计系统在分布 下的失效概率 ,故采用重要性采样方法进行估计。考虑采样分布 ,从而提升罕见事件的估计效率,并根据似然比 重新估计出 ,即
在连续输入空间中,通常考虑采用均匀分布作为重要性采样分布。然而,采样分布 与系统输入分布 差异较大时,可能导致估计结果不准确,进而显著增加估计的方差[28]。因此,采用离散化网格均匀采样以保证估计的准确性,通过 配备相同的似然性,有 ;考虑目标函数 ,使用指示函数进行校准均值 ,即
安全验证中的主要任务为失效概率估计。为了考量代理模型的可信度,可通过访问智能避让系统目标函数获取真实失效概率 ,计算真实系统和代理模型的相对失效概率 ,即
4.2 智能避让系统安全评估流程
本文基于功能需求满足性和测试场景符合性,设计了一种“黑盒”RL模型失效概率测试方法。为提高样本利用率,将其与贝叶斯优化理论结合,具有较好的迁移性和可扩展性。将上述方法与ARP4761适航标准框架结合,构建包含RL模型的智能避让系统评估流程,具体如表1所示。
表1 包含RL模型智能避让系统安全性评估流程Table 1 Safety assessment process of intelligent collision avoidance system with RL models |
| 步骤 | 活动 |
|---|---|
| 步骤1:功能危害评估 | 在运行概念下进行系统功能危害分析(本文重点关注含RL模型错误“机动”功能危害) |
| 步骤2:初步系统安全性评估 | 1.定义安全性目标 2.定义初步系统架构以满足安全性目标 3.衍生包括独立需求的安全性需求,满足目标和支持架构 4.定义和确认假设 5.分配研制保证水平(DAL) 6.基于贝叶斯优化,通过不确定性探索、边界细化和失效区域采样函数,训练高斯代理模型 7.在冲突距离和冲突角度两维输入空间X和分布函数 的场景下对RL模型进行失效概率估计与分析 8.衍生需求满足性的RL模型运行域(即安全边界) 9.执行RL单元失效模式影响分析 |
| 步骤3:系统安全性评估 | 执行最终的安全性评估 |
流程重点关注由RL模型提供错误“机动”所带来的定量计算和失效分析。通过代理模型高效估计RL模型失效概率,识别高风险失效区域和边界,为模型优化和评估迭代提供依据。在以冲突距离和冲突角度构建的输入空间X的场景下,为活动8安全运行域的设计提供数据支撑。此外,可快速评估由运行场景分布差异带来的安全风险,并重新制定安全运行域。
5 实验与分析
5.1 实验设置
设置输入空间X中冲突距离 和冲突角度 的范围分别为 和 。为适应贝叶斯优化的迭代训练过程,需要将这2个参数的范围归一化到统一的区间范围 。具体而言,通过对冲突距离和冲突角度进行线性变换,将其映射到新范围,变换公式为
假设经线性变化后的冲突距离 和冲突角度 符合正态分布的随机变量,设定为 和 。
5.2 训练过程与结果
随迭代轮次t增加,高斯过程代理模型、不确定性探索函数、边界细化函数和失效区域采样函数变化如图5所示。
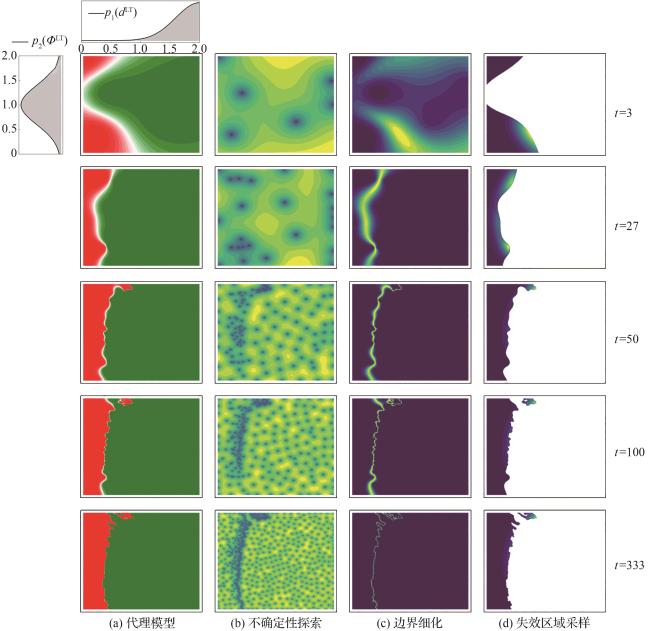
图5(a)展示了高斯过程代理模型预测均值 变化情况。随迭代轮次t的增加,高斯过程代理模型预测结果的“软边界”不断细化、精度刻画不断优化,同时失效或非失效区域更加稳定。
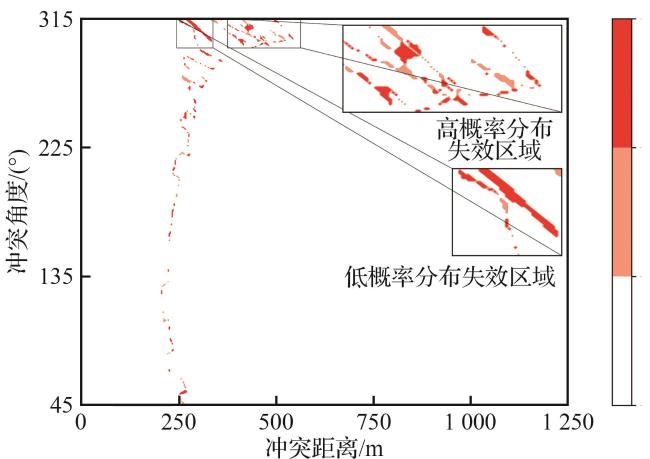
图5(b)展示了不确定性探索函数的变化情况。首先,函数在输入空间内随机探索,以发现大范围的失效或非失效区域。其次,随迭代轮次t的增加,边界和高概率分布失效区域密度也快速增加,函数专注于识别输入空间中失效或非失效的局部区域。最后,失效边界和高概率复杂失效区域不确定性最小。
图5(c)展示了边界细化函数的变化情况。首先,函数根据大致失效区域划分进行上置信边界采样。其次,随着迭代轮次t的增加,函数从高概率分布区域边界采样,以细化其边界精度并保证失效概率的准确性。最后,函数实现在输入空间上的整体边界细化和多失效边界识别。
图5(d)展示了失效区域采样函数的变化情况。给出了使用指示函数对高斯过程预测均值进行校准后得到的“硬边界”和输入 ,并呈现输入样本的失效概率分布情况。随着迭代轮次t的增加,高概率分布失效区域逐步固定,反映了模型在随机移动的无人机场景中训练时,在特定冲突角度下难以完成避障任务。该结果表明模型训练存在不足,或在特定冲突场景下存在过拟合问题。
333轮次训练的代理模型和全部采样点如图6所示,红色方块为失效样本采样,绿色方块为非失效样本采样。在每一轮迭代中,高斯过程通过3个获取函数优化采样集合:不确定性探索函数确保采样密度覆盖整个输入空间、边界细化函数和失效区域采样函数分别对边界区域和失效区域进行上置信度探索,以提高失效概率的估计精度。随后,对采样点进拟合,其中高斯过程的均值函数 用于推测未知点的均值 ,核函数 则用于衡量未知点和采样点间的相关性,以计算标准差 ,从而构建对输入空间的高效代理模型。
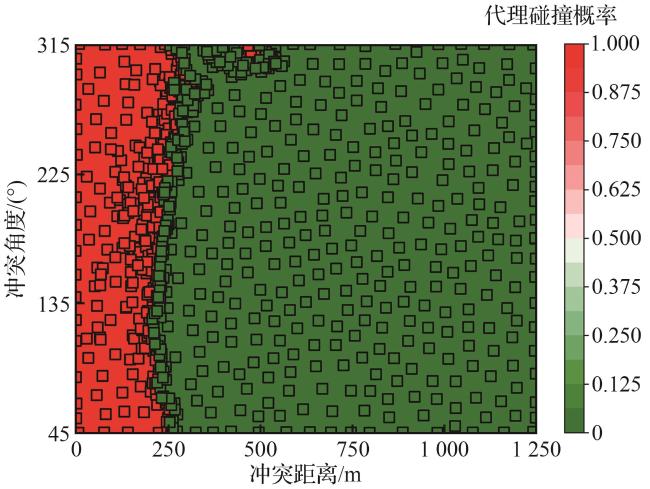
5.3 安全性评估
5.3.1 安全验证任务
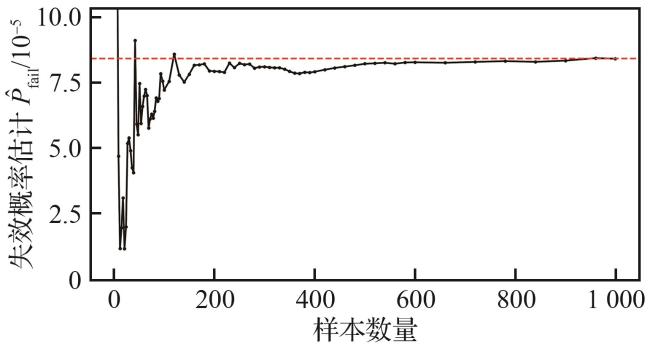
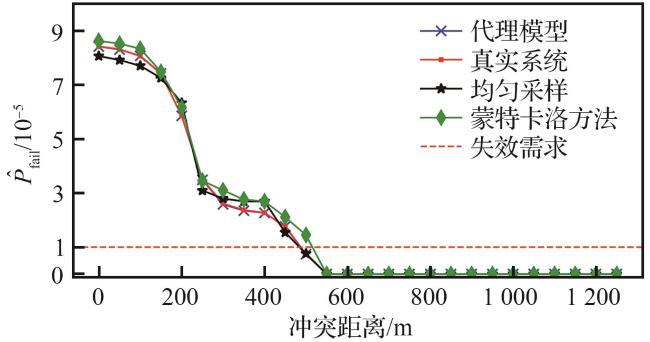
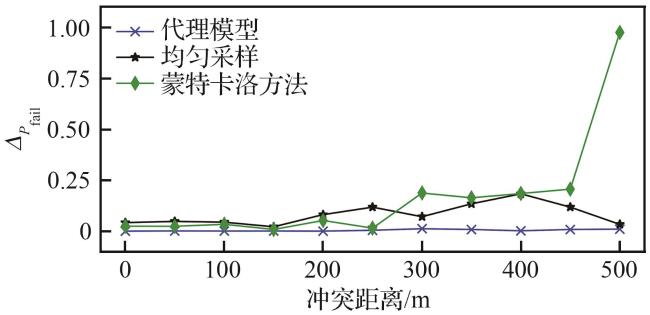
1) 对比试验。为评估算法在安全任务中表现,离散网格化采样出250 000个真实样本点集合为真实系统。在少量输入集合样本数 的情况下,采用了均匀采样(离散网格采样)和蒙特卡洛采样2种方法进行对比,以评估算法在安全任务中的表现。具体而言,均匀采样通过在输入空间中生成均匀的离散1 024=32×32个样本点。鉴于蒙特卡洛方法基于输入分布采样 ,可能难以覆盖到失效区域,因此采用基于均匀分布的重要性采样策略,生成999个样本点,用于进行安全性评估的对照实验。
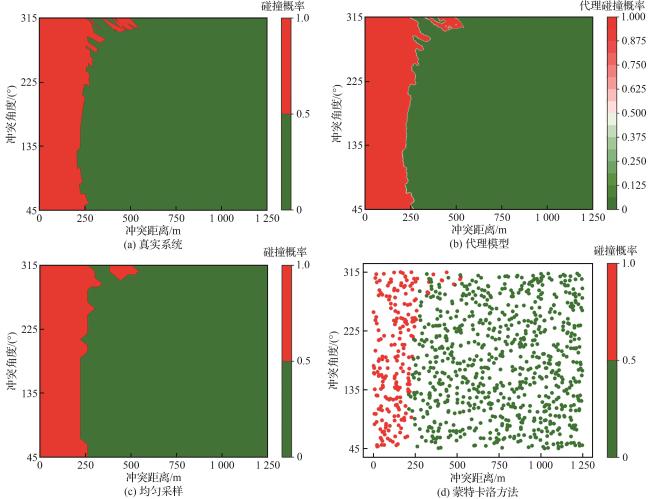
优化算法旨在实现安全验证,即证伪、最可能失效分析及失效概率估计,并通过与真实系统结果对比,评估算法的可信度以及相对失效概率 (见表2)。在训练阶段,代理模型通过边界细化和失效区域采样函数,有效提升证伪率至50.2%,显著增强了对避让系统潜在失效输入的识别能力。安全验证阶段,基于高斯过程的代理模型对采样点进行拟合,实现对输入空间的连续预测。借助大量预测样本点及基于离散网格的重要性采样方法,完成最可能失效分析和失效概率估计。与均匀采样和蒙特卡洛的采样相比,显著提高了分析和估计的精度,且相对失效概率最低,即 。此外,模型对失效区域及边界的刻画更加细致,为后续安全性评估提供了坚实支撑。
表2 4种评估方法用于安全验证任务Table 2 Four evaluation methods for safety verification tasks |
| 评估方法 | |||||
|---|---|---|---|---|---|
| 真实系统 | 20.8% | (0.867 93,1.895 79) | 1.496×10-3 | 8.410 72×10-5 | |
| 代理模型 | 50.2% | (0.861 72,1.895 79) | 1.396×10-3 | 8.407 26×10-5 | 4.12×10-4 |
| 均匀采样 | 21.7% | (0.838 70,1.935 48) | 9.543×10-4 | 8.055 44×10-5 | 4.22×10-2 |
| 蒙特卡洛 | 21.6% | (0.827 56,1.918 87) | 9.687×10-4 | 8.619 19×10-5 | 2.48×10-2 |
2) 时间复杂度分析。实际应用中,高斯过程的限制在于拟合 个样本点所需的时间复杂度 ,这是由于 维的矩阵求逆导致[29]。考虑高斯过程总迭代轮次为 ,每轮采样点数为 (代理模型使用3个获取函数, ),代理模型拟合所需的理论时间复杂度为
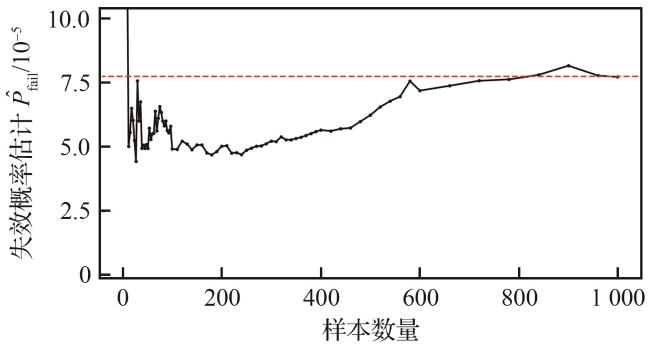
均匀采样和蒙特卡洛方法作为基于大量样本的不确定性估计手段,其计算效率受仿真时间步长 和冲突距离 等因素的影响,导致了不同样本之间的计算时间存在差异。在大量样本的情况下,理论采样时间复杂度可以近似估计为 。图9展示了在不同样本数量下失效概率估计的变化趋势,同等水平精度下的均匀采样和蒙特卡洛方法所需样本量分别为50 000和85 000。
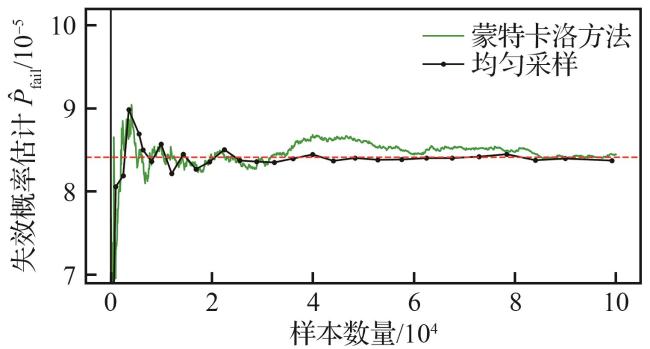
实验硬件平台包括:Intel Xeon W-3245 处理器、256 GB内存以及NVIDIA RTX A2000 显卡。实验软件环境:基于Python 3.7编程语言,核心库 Numpy 1.21.5和Scikit-learn 1.0.2。基于上述实验条件和样本量需求,均匀采样和蒙特卡洛方法所需时间分别为高斯过程代理模型时间的3.12倍和5.31倍。
3) 获取函数消融实验。在上述设定下进行消融实验,以评估3种获取函数及其组合对模型拟合性能与安全验证效果的影响,验证其重要性。在样本量相同的情况下,单独使用3种单独获取函数时,设置总迭代轮次为999,理论时间复杂度约为代理模型的3倍;在使用两两组合的获取函数时,设置总迭代轮次为500,理论时间复杂度约为代理模型的1.5倍。

安全验证任务结果如表3所示。失效区域采样函数仅关注对失效区域进行上置信度采样,因而能够实现较高的证伪率(89.2%),但由于缺乏对非失效区域和边界的有效覆盖,整体模型的拟合精度较低,泛化能力有限。边界细化与失效区域采样函数的组合在采样上实现了局部精细刻画与目标区域高置信采样的协同互补,提高了失效概率估计的精度,但仍存在过拟合等问题。
表3 3种获取函数的消融实验用于安全验证任务Table 3 Ablation study of three acquisition functions for safety validation task |
| 获取函数组合 | |||||
|---|---|---|---|---|---|
| 不确定性探索 | 21.6% | (0.833 67,1.907 82) | 1.030×10-3 | 8.522 94×10-5 | 1.33×10-2 |
| 边界细化 | 35.5% | (0.861 72,1.899 80) | 1.368×10-3 | 8.628 98×10-5 | 2.59×10-2 |
| 失效区域采样 | 89.2% | (0.436 88,1.330 66) | 3.352×10-4 | 5.827 44×10-5 | 3.07×10-1 |
| 不确定性探索、边界细化 | 34.6% | (0.857 72,1.895 79) | 1.366×10-3 | 8.485 22×10-5 | 8.86×10-3 |
| 不确定性探索、失效区域采样 | 49.3% | (0.821 64,1.887 77) | 1.094×10-3 | 7.749 55×10-5 | 7.86×10-2 |
| 边界细化、失效区域采样 | 52.8% | (0.857 71,1.895 79) | 1.361×10-3 | 8.453 47×10-5 | 5.08×10-3 |
| 代理模型 | 50.2% | (0.861 72,1.895 79) | 1.396×10-3 | 8.407 26×10-5 | 4.12×10-4 |
综上所述,本文采用3种获取函数的组合作为代理模型的采样函数,在提升模型对输入空间的全局覆盖能力的同时,增强了对失效边界及高风险区域的预测精度,从而在各项安全验证指标中表现最优,且模型拟合结果表现稳定。此外,代理模型理论时间复杂度较低,有效控制了计算成本。
4) 扩展实验。在前文对比实验设置的基础上扩展至三维空间,增加垂直方向冲突角度变量 ( 范围为 ),归一化至相同的区间范围 ,以统一输入空间的尺度。所得训练结果如图11所示,其失效概率估计随样本数量的变化而呈现出一定趋势。随着输入空间维度的增加,在样本数量较少时,估计结果表现出一定的滞后性与不稳定性。然而,在有限的迭代轮次内,算法仍展现出收敛性。此外,高维空间中为了更充分地覆盖输入区域、识别更多潜在的失效区域,通常需要更多的样本。
三维空间中,通过均匀离散的网格采样生成60×60×60=216 000个真实样本点,与代理模型在安全验证任务中的结果进行对比。如表4所示,证伪和最可能失效分析与二维空间结果表现相近,表明代理模型在识别失效区域方面依然保持较强一致性和有效性,但失效概率估计与均匀采样结果存在一定的差异。
表4 扩展实验安全验证任务对比Table 4 Comparison of safety verification tasks in extended experiments |
| 评估方法 | ||||
|---|---|---|---|---|
| 均匀采样 | 21.4% | (0.915,1.932,1.254) | 1.665×10-3 | 8.051 64×10-5 |
| 代理模型 | 47.2% | (0.929,1.939,1.293) | 1.331×10-3 | 7.714 31×10-5 |
全面评估代理模型在高维空间中的表现,并验证其对失效区域及边界的识别能力。代理模型和均匀采样的差异性比对如图12所示,红色为未预测出的失效点,橙红色为错误预测的非失效点。比对显示差异性主要存在于失效边界“面”附近,代理模型仍能较为精确地刻画边界并识别出失效区域,具备一定的泛化能力。随着输入空间维度的增加,失效边界复杂度也随之增加,失效概率估计难度加大,少量样本下不可避免地导致代理模型失效概率估计差异。
为进一步验证代理模型的有效性与可行性,对常用的分类性能指标进行统计,结果如下:准确率0.937、精确率0.921、召回率0.916、F1分数为0.918。少量样本下的代理模型仍能够较为准确地识别失效区域,具备一定的可行性与实用性,可作为一种高效的冗余可靠性分析方法。
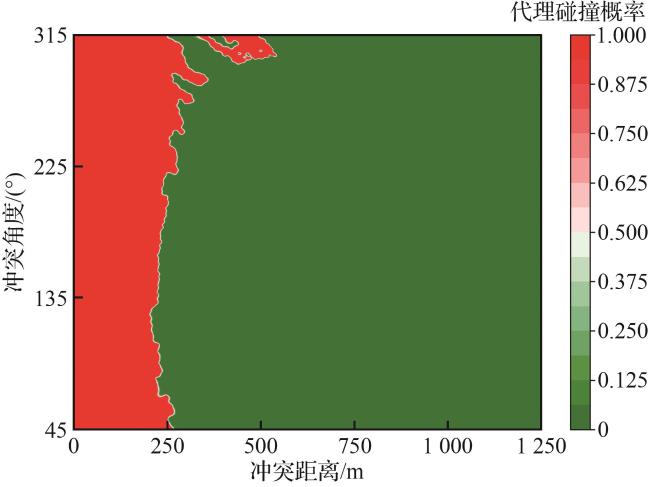
5.3.2 安全边界确定
基于上述高斯过程代理模型对失效概率估计的量化和分析,制定相关安全边界,用于排除RL模型中的高风险状态区域,避免产生错误或不可接受的避让动作。如图7(b)所示,受冲突角度 的影响,失效区域的边界呈现出一定复杂性,但整体上仍主要由冲突距离 决定。因此,可进一步制定基于距离的水平安全边界 ,其对应的失效概率计算式为
5.3.3 系统安全性评估
假设智能避让系统通过机载信息感知设备获得本机和入侵机的状态信息,经RL模型产生避让动作建议,向飞行员提供咨询,在其授权情况下,执行避让功能。
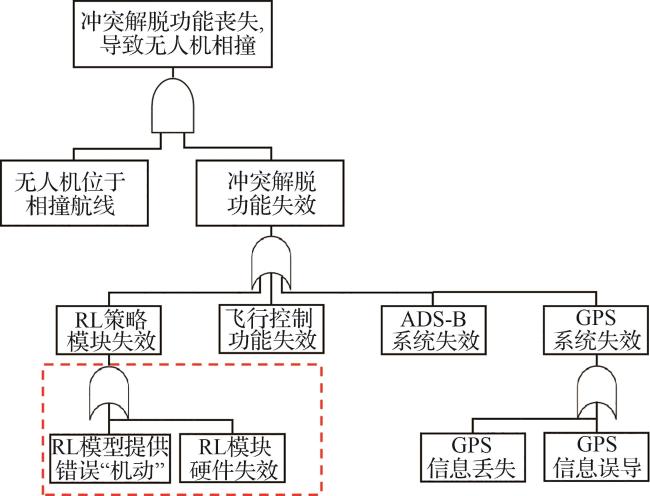
表5 故障树底层事件失效概率Table 5 Failure data of basic events in FTA |
| 编号 | 故障树底事件 | 失效概率/每次飞行 |
|---|---|---|
| 1 | ADS-B系统功能失效 | 1.0×10-5 |
| 2 | GPS系统数据丢失 | 2.0×10-4 |
| 3 | GPS系统信息误导 | 3.0×10-5 |
| 4 | RL模块提供错误“机动” | 1.0×10-5 |
| 5 | RL模块硬件失效 | 3.5×10-6 |
| 6 | 飞行控制功能失效 | 1.0×10-6 |
| 7 | 无人机位于相撞航线 |
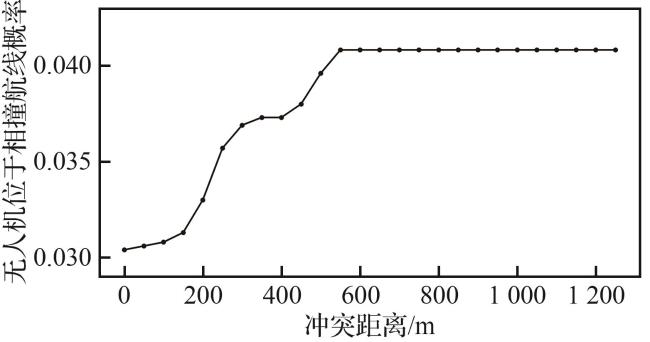
此外,“无人机位于相撞航线”这一事件发生的概率与空域交通流量、无人机型号和航迹交汇等因素密切相关,然而相关数据仍存在一定缺失。为了满足空中相撞风险小于 概率要求,本文给出无人机在管制空域内每飞行时,无人机处于相撞航线概率随设定安全边界(冲突距离)变化的最低要求,如图16所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
6 结论
RL模型已经在诸多领域广泛应用于路径规划和自主避撞。然而,当其应用于机载系统时,必需满足相关的适航安全性要求。本文在SAE ARP4761适航标准框架下,基于无人机运动学模型和算法设计,采用贝叶斯优化理论,通过不确定性探索、边界细化和失效区域采样3个获取函数完成对高斯代理模型的迭代式训练,实现少量样本下智能避让系统的安全验证、安全边界确定和功能失效概率分析。
以基于典型智能感知避让系统设计架构为案例,表明了该方法对适航安全性评估的有效支撑作用,可为智能避让系统的装机应用提供必要的适航符合性方法和技术保证。同时实验也验证了在少量样本的情况下,相比于均匀采样和蒙特卡洛方法,基于贝叶斯优化的方法能够为强化学习模块提供细致的失效边界预测、精确的失效概率估计和更高的置信水平。
实际应用中,无人机受风速变化、感知设备探测精度及状态转移不确定性等内外因素影响。可能出现的复杂失效区域和多失效边界是验证难点。可将上述致因“编码”至输入空间进行二次验证或结合其它方法进行辅助验证,有待进一步研究或讨论。