唐旭( ), 谷峰, 马晶晶, 张向荣
), 谷峰, 马晶晶, 张向荣
收稿日期:2025-07-28
修回日期:2025-09-08
接受日期:2025-09-30
出版日期:2025-10-28
发布日期:2025-10-24
通讯作者:
唐旭
E-mail:tangxu128@gmail.com
基金资助:
Xu TANG(), Feng GU, Jingjing MA, Xiangrong ZHANG
Received:2025-07-28
Revised:2025-09-08
Accepted:2025-09-30
Online:2025-10-28
Published:2025-10-24
Contact:
Xu TANG
E-mail:tangxu128@gmail.com
Supported by:摘要:
为解决多模态遥感数据因空间分辨率差异、数据异质性及标记样本有限导致的土地覆盖分类不准确问题,对高光谱图像与激光雷达数据联合分类方法展开研究。提出语义感知跨模态融合网络(SCF-Net),先运用轻量级图像块编码器将数据转换为RGB兼容特征图,输入可学习提示增强的基于对比语言-图像预训练(CLIP)视觉编码器;再借助自适应跨模态融合架构,以分组线性投影和关系判断模块实现低计算成本的动态空间特征交互;最后生成属性-类别文本提示,通过计算特征与文本嵌入余弦相似度,采用TopK属性平均策略完成分类。在Houston 2013、MUUFL和Trento数据集上的实验表明,较8种融合技术,SCF-Net总体精度提升超2.88%,平均精度提高2.69%,Kappa系数增长3.02%,同时保持较高参数效率。消融实验验证了各模块有效性。SCF-Net为复杂遥感分类任务中多模态数据与大规模预训练模型的结合应用提供了新范式。
中图分类号:
唐旭, 谷峰, 马晶晶, 张向荣. 基于视觉-语言预训练模型的高光谱-激光雷达联合分类方法[J]. 航空学报, 2026, 47(10): 632630.
Xu TANG, Feng GU, Jingjing MA, Xiangrong ZHANG. Hyperspectral-LiDAR joint classification method based on vision-language pre-trained models[J]. Acta Aeronautica et Astronautica Sinica, 2026, 47(10): 632630.
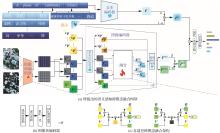
图 1
语义感知跨模态融合网络及核心模块
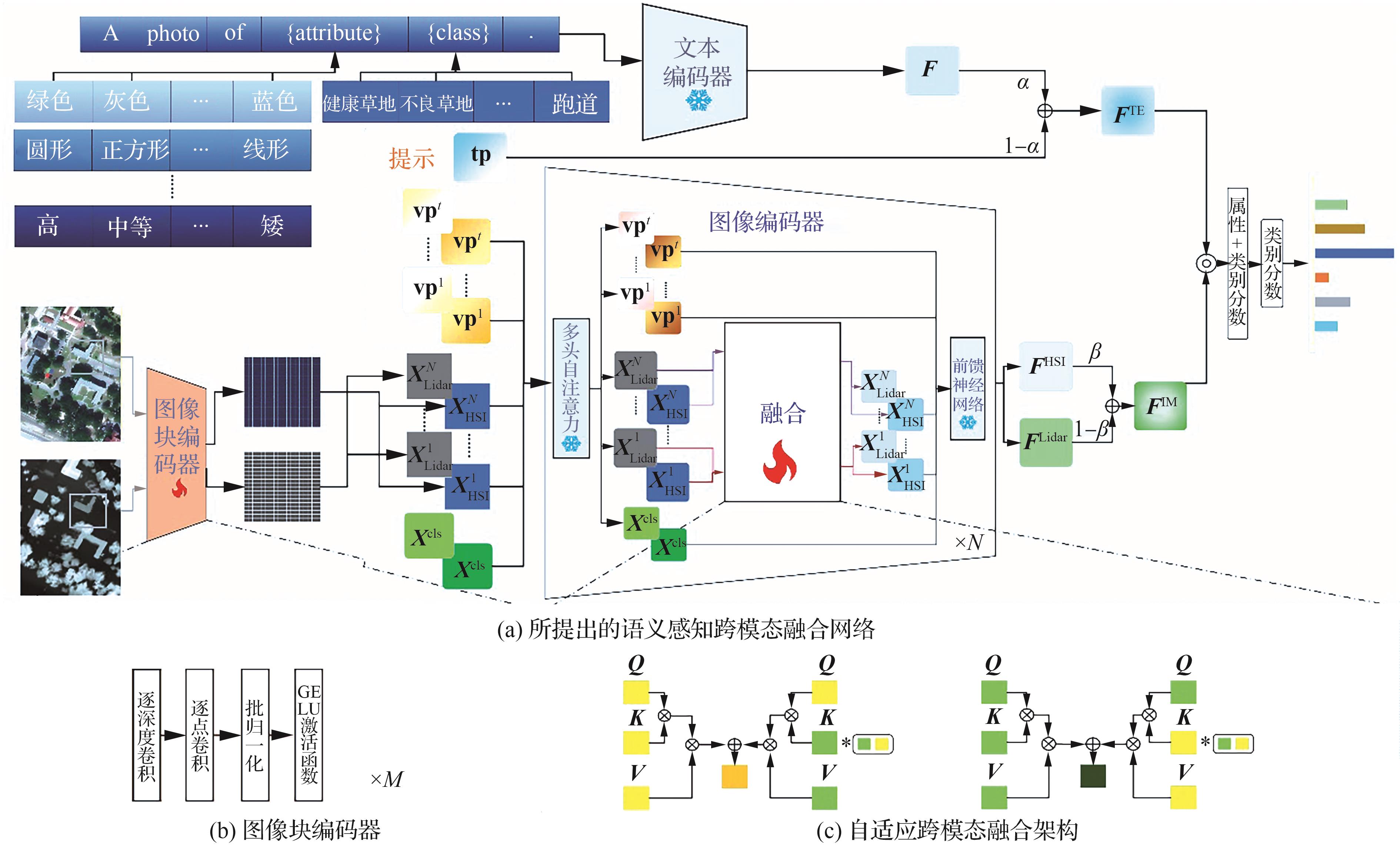

图 2
Houston 2013 数据集可视化结果


图 3
MUUFL数据集可视化结果


图 4
Trento数据集可视化结果

表1
基于Houston 2013数据集的不同方法分类精度
| 序号 | 类别 | 数量 | 分类精度/% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 测试集 | IP-CNN | HRWN | Cross-HL | HyperMLP | TMCLNet | M2FNet | MGNet | SPT | SCF-Net | ||
| 1 | 健康草地 | 20 | 1 231 | 85.77 | 85.61 | 83.10 | 83.01 | 87.38 | 84.12 | 83.00 | 94.25 | 97.24* |
| 2 | 不良草地 | 20 | 1 234 | 87.34 | 85.17 | 97.37 | 84.49 | 97.80 | 95.24 | 85.15 | 95.90 | 99.51* |
| 3 | 人造草地 | 20 | 677 | 100.00* | 99.57 | 99.34 | 100.00* | 100.00* | 98.29 | 97.82 | 99.94 | 100* |
| 4 | 树木 | 20 | 1 224 | 94.26 | 92.20 | 97.30 | 98.48* | 98.82* | 95.68 | 92.61 | 98.33 | 97.55 |
| 5 | 土壤 | 20 | 1 222 | 98.42 | 100.00* | 99.94 | 100* | 98.31 | 99.12 | 100.00* | 99.82 | 100.00* |
| 6 | 水域 | 20 | 305 | 99.91 | 98.15 | 96.97 | 96.50 | 99.63 | 95.80 | 96.50 | 96.39 | 100.00* |
| 7 | 住宅区 | 20 | 1 248 | 94.59 | 95.98 | 80.15 | 83.44 | 91.70 | 92.22 | 92.63 | 96.22 | 99.05* |
| 8 | 商业区 | 20 | 1 224 | 91.81 | 97.59* | 91.01 | 80.63 | 86.78 | 90.90 | 91.83 | 76.88 | 97.06 |
| 9 | 道路 | 20 | 1 232 | 89.35 | 88.66 | 90.82 | 86.12 | 85.94 | 92.35 | 94.43* | 87.91 | 92.53 |
| 10 | 高速公路 | 20 | 1 207 | 72.43 | 86.23 | 58.86 | 79.54 | 92.26 | 76.31 | 95.17 | 86.18 | 95.28* |
| 11 | 铁路 | 20 | 1 215 | 96.57 | 97.98 | 98.77 | 94.31 | 98.99* | 94.44 | 97.34 | 91.37 | 89.06 |
| 12 | 停车场1 | 20 | 1 213 | 95.60 | 97.40* | 91.55 | 96.73 | 86.41 | 94.56 | 95.10 | 94.33 | 86.07 |
| 13 | 停车场2 | 20 | 449 | 94.37 | 91.47 | 90.49 | 88.07 | 99.01 | 91.15 | 84.56 | 95.32 | 99.78* |
| 14 | 网球场 | 20 | 408 | 99.86 | 100.00* | 99.96 | 99.19 | 97.76 | 99.35 | 100.00* | 99.80 | 100.00* |
| 15 | 跑道 | 20 | 640 | 99.99 | 100.00* | 98.64 | 99.58 | 99.89 | 98.26 | 99.58 | 100* | 100.00* |
表2
基于Houston 2013数据集的不同方法分类准确率
| 方法 | OA/% | AA/% | Kappa/% |
|---|---|---|---|
| IP-CNN | 92.06±0.88 | 93.35±0.79 | 91.42±0.93 |
| HRWN | 93.61±0.65 | 94.40±0.49 | 93.09±0.61 |
| Cross-HL | 89.66±0.98 | 91.25±1.13 | 88.78±1.05 |
| HyperMLP | 81.00±2.32 | 89.86±0.89 | 89.03±0.86 |
| TMCLNet | 90.98±0.78 | 94.71±0.52 | 93.31±0.71 |
| M2FNet | 93.80±0.58 | 93.18±0.54 | 91.61±0.51 |
| MGNet | 93.20±0.28 | 93.72±0.36 | 92.61±0.33 |
| SPT | 93.23±0.46 | 94.18±0.39 | 92.68±0.43 |
| SCF-Net | 96.11*±0.21 | 96.87*±0.15 | 95.70*±0.13 |

图 5
各种方法获得的Houston 2013数据集标记样本分类图

表3
基于MUUFL数据集的不同方法分类精度
| 序号 | 类别 | 数量 | 分类精度/% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 测试集 | IP-CNN | HRWN | Cross-HL | HyperMLP | TMCLNet | M2FNet | MGNet | SPT | SCF-Net | ||
| 1 | 树木 | 20 | 23 226 | 88.26 | 86.58 | 86.47 | 89.97 | 83.83 | 89.28 | 88.04 | 84.93 | 93.21* |
| 2 | 大部分草地 | 20 | 4 250 | 58.38 | 58.28 | 60.80 | 50.75 | 84.11* | 61.46 | 56.52 | 76.07 | 73.76 |
| 3 | 混合地面 | 20 | 6 862 | 47.32 | 64.85 | 54.02 | 70.37 | 67.02 | 64.16 | 68.14 | 73.93 | 76.43* |
| 4 | 泥土和沙子 | 20 | 1 806 | 87.32 | 85.94 | 93.52* | 92.91 | 88.71 | 87.60 | 87.54 | 89.27 | 90.65 |
| 5 | 道路 | 20 | 6 667 | 82.15 | 84.48 | 67.26 | 69.70 | 87.81 | 80.17 | 88.92 | 89.15* | 85.99 |
| 6 | 水 | 20 | 446 | 100.00* | 100.00* | 99.78 | 100.00* | 99.04 | 100.00* | 100.00* | 98.48 | 100.00* |
| 7 | 建筑物阴影 | 20 | 2 213 | 81.97 | 82.56 | 84.64 | 80.80 | 93.58* | 83.42 | 83.37 | 92.00 | 88.32 |
| 8 | 建筑物 | 20 | 6 220 | 90.72 | 94.18 | 89.16 | 94.79* | 87.92 | 90.23 | 90.48 | 91.21 | 93.14 |
| 9 | 人行道 | 20 | 1 365 | 63.44 | 52.53 | 56.19 | 45.35 | 66.47 | 57.51 | 60.66 | 76.01 | 81.88* |
| 10 | 黄色路缘 | 20 | 163 | 63.80 | 69.94 | 75.46 | 70.55 | 93.31 | 71.17 | 38.04 | 96.32 | 97.57* |
| 11 | 布质面板 | 20 | 249 | 94.38 | 95.98 | 95.98 | 93.98 | 98.92* | 93.57 | 95.98 | 95.18 | 96.01 |
表4
基于MUUFL数据集的不同方法分类准确率
| 方法 | OA/% | AA/% | Kappa/% |
|---|---|---|---|
| IP-CNN | 79.28±2.02 | 77.98±1.93 | 73.36±1.67 |
| HRWN | 81.21±1.83 | 79.57±0.97 | 75.88±1.54 |
| Cross-HL | 77.69±3.31 | 78.48±2.83 | 71.56±2.95 |
| HyperMLP | 81.00±2.32 | 78.11±1.98 | 75.26±0.71 |
| TMCLNet | 83.04±0.85 | 86.43±0.93 | 78.39±0.99 |
| M2FNet | 81.76±2.21 | 79.87±1.94 | 76.40±3.32 |
| MGNet | 82.45±1.94 | 77.97±2.14 | 77.34±1.53 |
| SPT | 84.48±0.91 | 87.50±0.36 | 80.16±0.72 |
| SCF-Net | 88.09*±1.24 | 88.69*±1.51 | 84.24*±1.63 |

图 6
各种方法获得的MUUFL数据集标记样本分类图

表 5
基于Trento数据集的不同方法分类精度
| 序号 | 类别 | 数量 | 分类精度/% | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 测试集 | IP-CNN | HRWN | Cross-HL | HyperMLP | TMCLNet | M2FNet | MGNet | SPT | SCF-Net | ||
| 1 | 苹果树 | 20 | 4 014 | 99.00 | 99.75 | 99.32 | 100.00* | 99.40 | 99.20 | 99.62 | 99.48 | 99.18 |
| 2 | 建筑物 | 20 | 2 883 | 99.40* | 94.32 | 95.32 | 98.66 | 97.82 | 98.15 | 98.81 | 97.73 | 97.95 |
| 3 | 地面 | 20 | 459 | 99.10 | 98.75 | 97.62 | 93.94 | 97.27 | 97.11 | 88.24 | 98.56 | 100.00* |
| 4 | 树林 | 20 | 9 103 | 99.92 | 100.00* | 99.89 | 100.00* | 99.93 | 99.99 | 99.99 | 99.98 | 100.00* |
| 5 | 葡萄园 | 20 | 10 481 | 99.66 | 100.00* | 99.97 | 99.99 | 98.13 | 99.99 | 100.00* | 99.66 | 99.97 |
| 6 | 道路 | 20 | 3 154 | 90.21 | 94.90 | 94.17 | 94.77 | 95.00 | 97.95 | 95.45 | 95.68 | 97.34* |
表 6
基于Trento数据集的不同方法分类准确率
| 方法 | OA/% | AA/% | Kappa/% |
|---|---|---|---|
| IP-CNN | 98.58±0.54 | 97.88±1.19 | 98.17±1.03 |
| HRWN | 81.21±1.83 | 97.95±1.43 | 98.48±1.26 |
| Cross-HL | 98.69±1.03 | 97.47±1.45 | 98.25±1.17 |
| HyperMLP | 99.22±0.29 | 97.89±1.14 | 98.96±1.09 |
| TMCLNet | 98.58±0.26 | 97.93±1.02 | 98.07±0.83 |
| M2FNet | 99.40±0.12 | 98.73±0.43 | 99.26±0.18 |
| MGNet | 99.21±0.42 | 97.02±1.34 | 98.94±0.83 |
| SPT | 99.11±0.53 | 98.51±0.97 | 98.81±0.81 |
| SCF-Net | 99.41*±0.15 | 99.07*±0.08 | 99.21*±0.12 |

图 7
各种方法获得的Trento数据集标记样本分类图
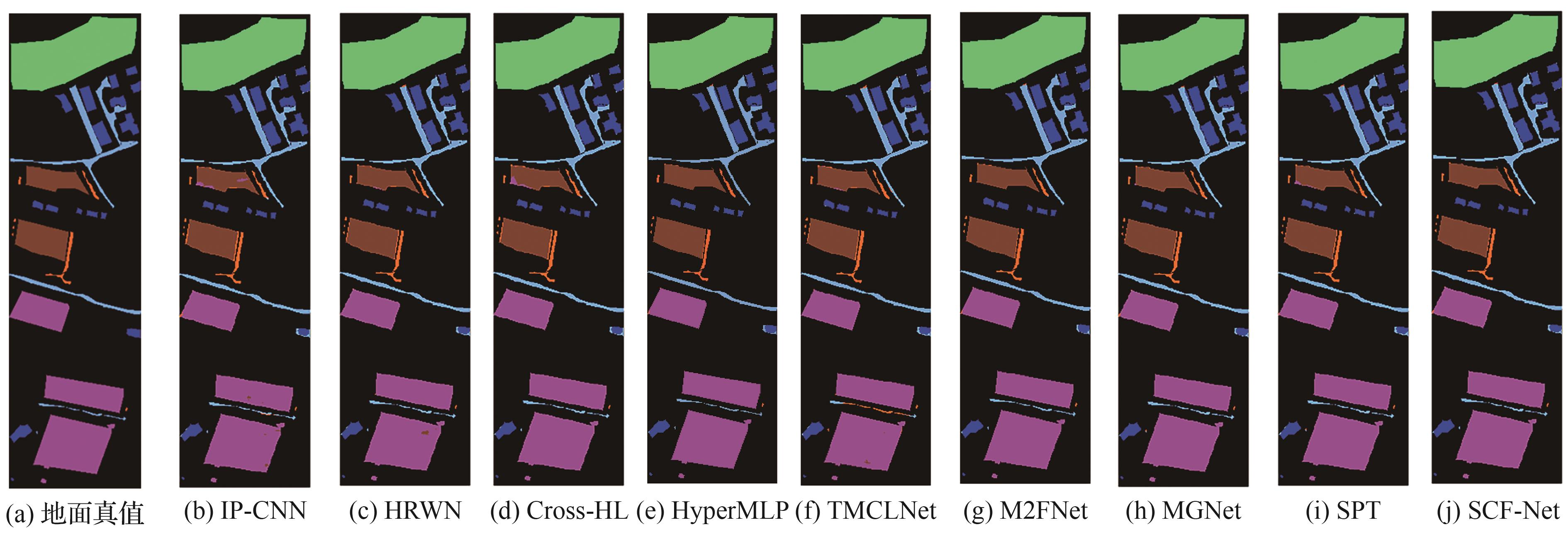
表 7
SCF-Net 各个部分在3个数据集上的消融研究结果
| 组合 | 模块 | Houston 2013 | MUUFL | Trento | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PE | ACMF | DACTR | OA/% | AA/% | Kappa/% | OA/% | AA/% | Kappa/% | OA/% | AA/% | Kappa/% | |
| 1 | √ | 95.90 | 96.64 | 95.49 | 87.85 | 88.46 | 83.97 | 99.17 | 98.53 | 98.92 | ||
| 2 | √ | 95.79 | 96.48 | 95.42 | 87.74 | 88.39 | 83.89 | 98.95 | 98.48 | 98.84 | ||
| 3 | √ | 95.85 | 96.52 | 95.38 | 87.69 | 88.43 | 83.81 | 98.90 | 98.41 | 98.79 | ||
| 4 | √ | √ | 96.06 | 96.73 | 95.58 | 87.97 | 88.59 | 84.13 | 99.34 | 98.89 | 99.11 | |
| 5 | √ | √ | 95.84 | 96.59 | 95.51 | 87.89 | 88.51 | 83.98 | 99.28 | 98.76 | 99.03 | |
| 6 | √ | √ | 95.92 | 96.66 | 95.45 | 87.92 | 88.53 | 84.05 | 99.25 | 98.82 | 99.07 | |
| 7 | √ | √ | √ | 96.11* | 96.87* | 95.70* | 88.09* | 88.69* | 84.24* | 99.41* | 99.07* | 99.21* |

图 8
SPT和 SCF-Net在3个数据集上的特征分布图
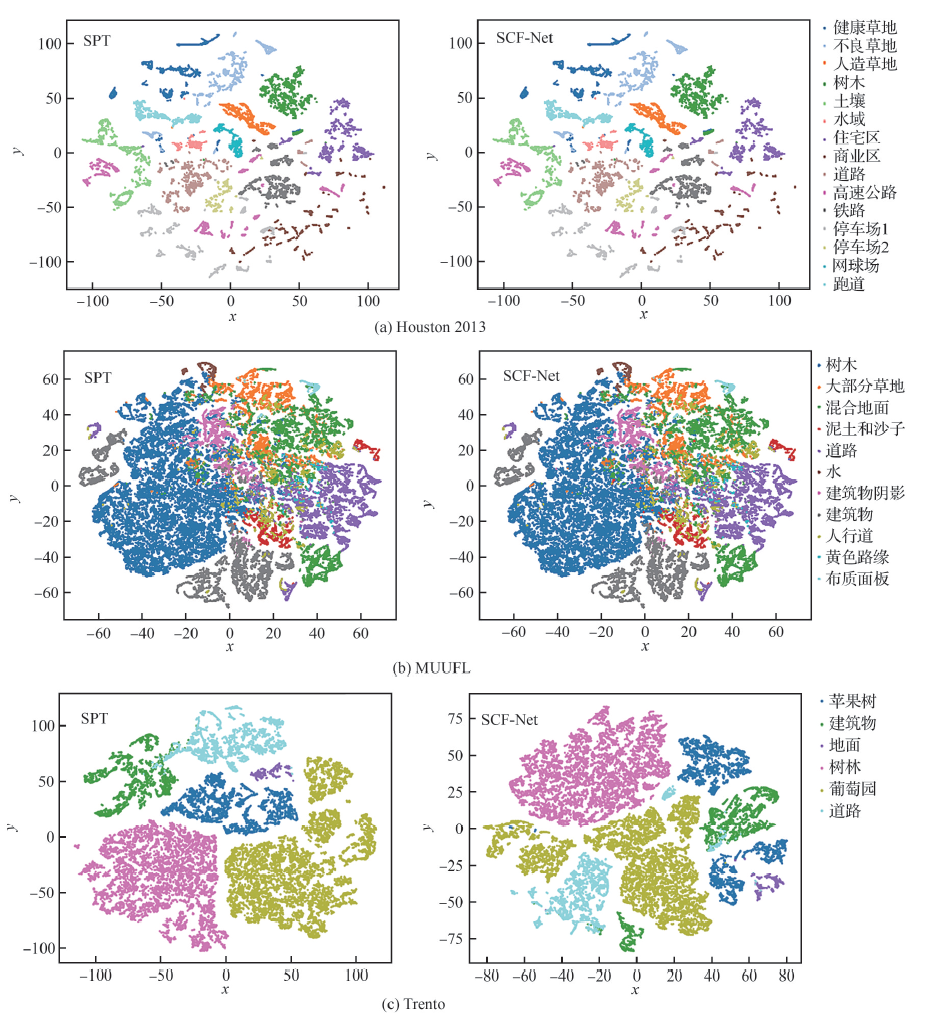
表8
Houston 2013数据集上每个方法的模型大小、训练时间和推理时间
| 方法 | 模型大小/MB | 训练时间/s | 推理时间/s |
|---|---|---|---|
| IP-CNN | 1.53 | 180.75 | 43.01 |
| HRWN | 1.33 | 360.92 | 20.86 |
| Cross-HL | 1.74 | 312.90 | 11.18 |
| HyperMLP | 1.52 | 174.10* | 5.43* |
| TMCLNet | 1.17 | 676.88 | 15.57 |
| M2FNet | 1.28 | 446.56 | 38.82 |
| MGNet | 1.35 | 363.12 | 28.46 |
| SPT | 16.34 | 608.34 | 14.75 |
| SCF-Net | 0.52* | 274.68 | 12.94 |
| [1] | XU K, WANG B J, ZHU Z, et al. A contrastive learning enhanced adaptive multimodal fusion network for hyperspectral and LiDAR data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 4700319. |
| [2] | CHANG H H, BI H X, LI F, et al. Deep symmetric fusion transformer for multimodal remote sensing data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5644115. |
| [3] | 李晓航, 周建江. 基于自适应记忆长度的多尺度模态融合网络[J]. 航空学报, 2023, 44(22): 628977. |
| LI X H, ZHOU J J. Multi-scale modality fusion network based on adaptive memory length[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(22): 628977 (in Chinese). | |
| [4] | ZHU F, SHI C P, SHI K J, et al. Joint classification of hyperspectral and LiDAR data using hierarchical multimodal feature aggregation-based multihead axial attention transformer[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5503817. |
| [5] | ZHANG M M, ZHAO Y Y, CHEN R J, et al. Remote sensing collaborative classification using multimodal adaptive modulation network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5529512. |
| [6] | MENG X C, ZHANG S F, LIU Q, et al. Uncertain category-aware fusion network for hyperspectral and LiDAR joint classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5523015. |
| [7] | LIAO D L, WANG Q S, LAI T, et al. Joint classification of hyperspectral and LiDAR data based on mamba[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5530915. |
| [8] | HU W S, LI W, LI H C, et al. Global clue-guided cross-memory quaternion transformer network for multisource remote sensing data classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(4): 7357-7371. |
| [9] | CAI Y M, ZHANG Z J, LIU X B, et al. Learning unified anchor graph for joint clustering of hyperspectral and LiDAR data[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(4): 6341-6354. |
| [10] | 冯燕, 贾应彪, 曹宇明, 等. 高光谱图像压缩感知投影与复合正则重构[J]. 航空学报, 2012, 33(8): 1466-1473. |
| FENG Y, JIA Y B, CAO Y M, et al. Compressed sensing projection and compound regularizer reconstruction for hyperspectral images[J]. Acta Aeronautica et Astronautica Sinica, 2012, 33(8): 1466-1473 (in Chinese). | |
| [11] | YU W B, HUANG H, SHEN Y, et al. IamCSC: Intuitive assimilation modality driven crossmodal subspace clustering for land-cover identification and hyperspectral-LiDAR fusion[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5505013. |
| [12] | HU Y T, HU Q W, LI J Y. CMINet: A unified cross-modal integration framework for crop classification from satellite image time series[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 4402213. |
| [13] | WANG L F, MEI S H, WANG Y, et al. CAMCFormer: Cross-attention and multicorrelation aided transformer for few-shot object detection in optical remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5613316. |
| [14] | FU X Y, ZHOU X, FU Y W, et al. Progressive semantic enhancement network for hyperspectral and LiDAR classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(6): 11327-11339. |
| [15] | GUO F M, LI Z W, REN G B, et al. Instance-wise domain generalization for cross-scene wetland classification with hyperspectral and LiDAR data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5501212. |
| [16] | DONG W Q, ZHANG T, QU J H, et al. Multibranch feature fusion network with self-and cross-guided attention for hyperspectral and LiDAR classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5530612. |
| [17] | FENG Y N, JIN J R, YIN Y, et al. MCFT: Multimodal contrastive fusion transformer for classification of hyperspectral image and LiDAR data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5537017. |
| [18] | KONG Y, YU S C, CHENG Y H, et al. Joint classification of hyperspectral images and LiDAR data based on candidate pseudo labels pruning and dual mixture of experts[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5505912. |
| [19] | YANG C, ZHAO M H, BRUZZONE L, et al. Cross-modality adaptive feature fusion for multitype and multiscale impact craters identification on Mars[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5613013. |
| [20] | WANG X H, SONG L Y, FENG Y N, et al. S3F2Net: Spatial-spectral-structural feature fusion network for hyperspectral image and LiDAR data classification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(5): 4801-4815. |
| [21] | JIN X D, GU Y F, LIU T Z, et al. Supervoxel-based intrinsic scene properties from hyperspectral images and LiDAR[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5510613. |
| [22] | ZHU B E, TANG K H, SUN Q R, et al. Generalized logit adjustment: Calibrating fine-tuned models by removing label bias in foundation models[C]∥37th International Conference on Neural Information Processing Systems. 2023. |
| [23] | MALLADI S, GAO T Y, NICHANI E, et al. Fine-tuning language models with just forward passes[C]∥37th International Conference on Neural Information Processing Systems. 2023. |
| [24] | HU E J, SHEN Y L, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C]∥10th International Conference on Learning Representations. 2022. |
| [25] | JIA M L, TANG L M, CHEN B C, et al. Visual prompt tuning[C]∥European Conference on Computer Vision 2022. 2022: 709-727. |
| [26] | HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-efficient transfer learning for NLP[C]∥International Conference on Machine Learning. 2019. |
| [27] | QU J H, YANG Y B, DONG W Q, et al. LDS2AE: Local diffusion shared-specific autoencoder for multimodal remote sensing image classification with arbitrary missing modalities[C]∥AAAI Conference on Artificial Intelligence. 2024: 14731-14739. |
| [28] | PEDERGNANA M, MARPU P R, DALLA MURA M, et al. Classification of remote sensing optical and LiDAR data using extended attribute profiles[J]. IEEE Journal of Selected Topics in Signal Processing, 2012, 6(7): 856-865. |
| [29] | CHINI M, PIERDICCA N, EMERY W J. Exploiting SAR and VHR optical images to quantify damage caused by the 2003 bam earthquake[J]. IEEE Transactions on Geoscience and Remote Sensing, 2009, 47(1): 145-152. |
| [30] | RASTI B, GHAMISI P. Remote sensing image classification using subspace sensor fusion[J]. Information Fusion, 2020, 64: 121-130. |
| [31] | RASTI B, ULFARSSON M O, SVEINSSON J R. Hyperspectral feature extraction using total variation component analysis[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(12): 6976-6985. |
| [32] | ROY S K, SUKUL A, JAMALI A, et al. Cross hyperspectral and LiDAR attention transformer: An extended self-attention for land use and land cover classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5512815. |
| [33] | DING K X, LU T, FU W, et al. Global-local transformer network for HSI and LiDAR data joint classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5541213. |
| [34] | ROY S K, DERIA A, HONG D F, et al. Hyperspectral and LiDAR data classification using joint CNNs and morphological feature learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5530416. |
| [35] | HANG R L, LI Z, GHAMISI P, et al. Classification of hyperspectral and LiDAR data using coupled CNNs[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(7): 4939-4950. |
| [36] | JIA S, ZHOU X, JIANG S G, et al. Collaborative contrastive learning for hyperspectral and LiDAR classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5507714. |
| [37] | XIA S X, ZHANG X H, MENG H Y, et al. Ternary modality contrastive learning for hyperspectral and LiDAR data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5522017. |
| [38] | AGIZA A, NESEEM M, REDA S. MTLoRA: A low-rank adaptation approach for efficient multi-task learning[C]∥2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 16196-16205. |
| [39] | WU J L, HU X, WANG Y Q, et al. Omni-SMoLA: Boosting generalist multimodal models with soft mixture of low-rank experts[C]∥2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 14205-14215. |
| [40] | IMTIAZ HOSSAIN M R, SIAM M, SIGAL L, et al. Visual prompting for generalized few-shot segmentation: A multi-scale approach[C]∥2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 23470-23480. |
| [41] | KIM B, YU J, HWANG S J. ECLIPSE: Efficient continual learning in panoptic segmentation with visual prompt tuning[C]∥2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 3346-3356. |
| [42] | KONG Y, CHENG Y H, CHEN Y, et al. Joint classification of hyperspectral image and LiDAR data based on spectral prompt tuning[J]. IEEE Transactions on Geoscience and Remote Sensing. Piscataway: IEEE Press, 2024, 62: 5521312. |
| [43] | ZHU P F, SUN Y, CAO B, et al. Task-customized mixture of adapters for general image fusion[C]∥2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 7099-7108. |
| [44] | YIN D S, YANG Y R, WANG Z C, et al. 1% VS 100%: Parameter-efficient low rank adapter for dense predictions[C]∥2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 20116-20126. |
| [45] | GE C R, DU Q, SUN W W, et al. Deep residual network-based fusion framework for hyperspectral and LiDAR data[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 2458-2472. |
| [46] | DEBES C, MERENTITIS A, HEREMANS R, et al. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(6): 2405-2418. |
| [47] | LU T, DING K X, FU W, et al. Coupled adversarial learning for fusion classification of hyperspectral and LiDAR data[J]. Information Fusion, 2023, 93: 118-131. |
| [48] | Congalton R G. A review of assessing the accuracy of classifications of remotely sensed data[J]. Remote Sensing of Environment, 1991, 37(1): 35-46. |
| [49] | ZHANG M M, LI W, TAO R, et al. Information fusion for classification of hyperspectral and LiDAR data using IP-CNN[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5506812. |
| [50] | ZHAO X D, TAO R, LI W, et al. Joint classification of hyperspectral and LiDAR data using hierarchical random walk and deep CNN architecture[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(10): 7355-7370. |
| [51] | LI J J, LIU Y Z, SONG R, et al. HyperMLP: Superpixel prior and feature aggregated perceptron networks for hyperspectral and LiDAR hybrid classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5505614. |
| [52] | SUN L, WANG X Y, ZHENG Y H, et al. Multiscale 3-D-2-D mixed CNN and lightweight attention-free transformer for hyperspectral and LiDAR classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 2100116. |
| [53] | Gao H, Feng H, Zhang Y, et al. Interactive enhanced network based on multihead self-attention and graph convolution for classification of hyperspectral and lidar data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024. |
| [54] | Arora S, Hu W, Kothari P K, An analysis of the t-SNE algorithm for data visualization[C]∥31st Annual Conference on Learning Theory. 2018. |
| [1] | 孙奥, 徐芳, 江树国, 杨文, 夏桂松. 遥感基础模型多模态协同增强的语义分割方法[J]. 航空学报, 2026, 47(10): 532910-532910. |
| [2] | 刘志洋, 刘权威, 张玉香, 董燕妮. 融合机载高光谱图像与星载合成孔径雷达影像的空天遥感多模态海面溢油探测[J]. 航空学报, 2026, 47(10): 632581-632581. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 航空学报编辑部
版权所有 © 2011航空学报杂志社
主管单位:中国科学技术协会 主办单位:中国航空学会 北京航空航天大学