
1 机载末端干扰问题
1.1 问题描述
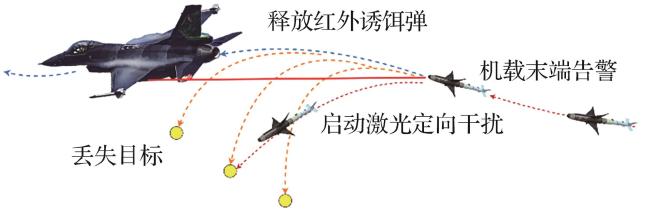
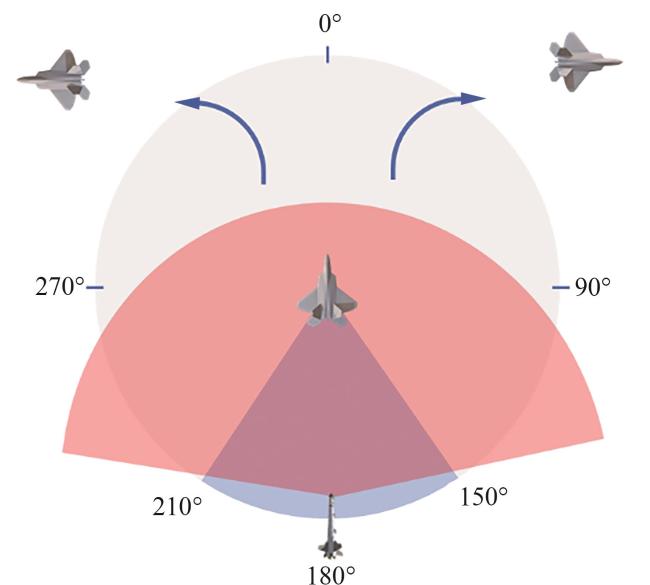
1.2 红外干扰建模
1.2.1 红外诱饵弹干扰模型
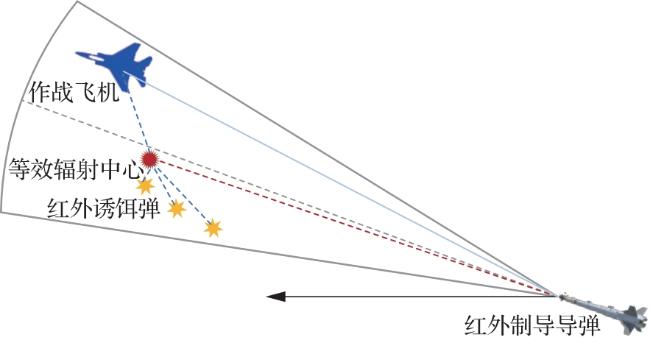
1.2.2 激光定向干扰模型
2 基于DACTM-PPO算法的干扰智能决策
2.1 PPO算法原理
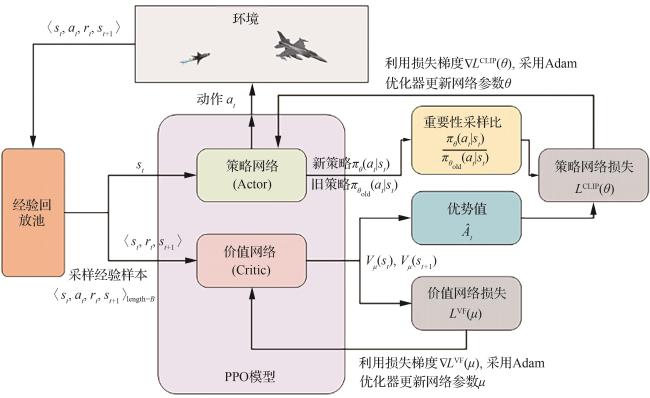
2.2 改进的动态非对称边界裁剪机制
2.2.1 动态裁剪机制
2.2.2 非对称裁剪机制
2.3 融合时序记忆与注意力机制的网络结构设计
2.3.1 长短期记忆网络
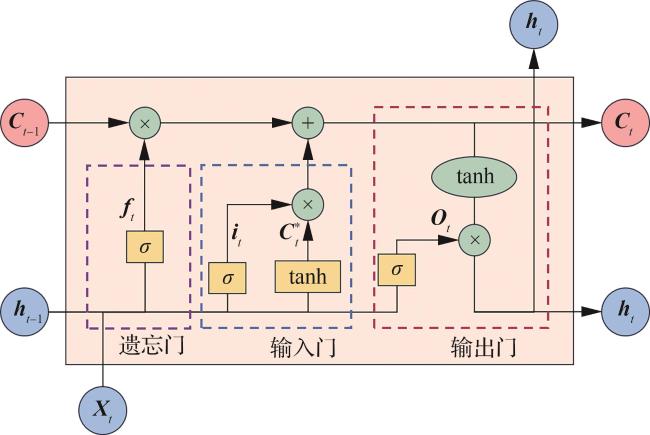
2.3.2 时间约束注意力机制
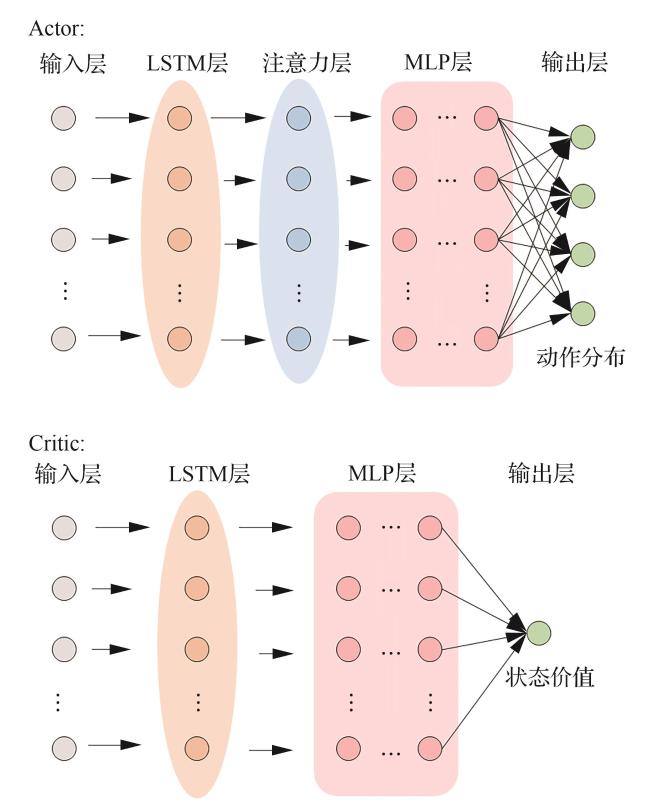
2.4 融合干扰手段特性的奖励函数设计
2.5 状态空间与动作空间设计
2.5.1 状态空间
表1 机载末端状态空间Table 1 Airborne terminal state space |
| 状态名称 | 状态标识 | 维度 | 取值范围 |
|---|---|---|---|
| 机弹相对方位/rad | 2 | ||
| 最大测角误差/rad | 2 | ||
| 机弹距离编号 | 1 | ||
| 飞机速度/( ) | 1 | ||
| 飞机高度/m | 1 | ||
| 飞机俯仰角和偏航角/rad | 2 | ||
| 飞机机动动作 | 1 | ||
| 红外诱饵弹剩余数量/枚 | 1 |
2.5.2 动作空间
表2 机载末端动作空间Table 2 Airborne terminal action space |
| 动作名称 | 动作标识 | 维度 | 取值范围 |
|---|---|---|---|
| 是否释放一组红外诱饵弹 | 1 | ||
| 每组红外诱饵弹枚数 | 1 | ||
| 组内红外诱饵弹弹间隔 | 1 | ||
| 激光定向干扰状态 | 1 |
2.6 DACTM-PPO算法流程
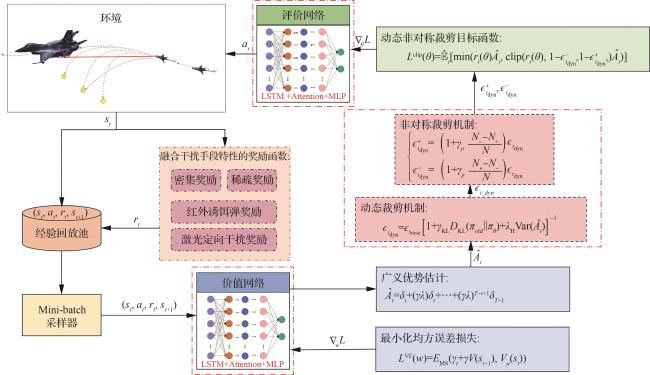
| |
|---|
| 输入:初始化策略参数 、价值函数参数 、折扣因子 、GAE折扣系数 、学习率 、clip基础裁剪参数 、调节系数 和预设最大训练轮数 |
| 输出:更新后的策略参数 、价值函数参数 |
| 1: for do |
| 2: 使用策略 与环境进行交互,收集轨迹集合 |
| 3: 经LSTM得到隐状态序列 |
| 4: 构造时间因果掩码M |
| 5: 计算时间约束注意力,以H生成 、 、 ,得上下文 |
| 6: 拼接 |
| 7: 使用当前的价值网络估算状态价值 |
| 8: 广义优势估计,计算优势函数 : |
| 9: 计算时序差分误差: |
| 10: 计算优势函数: |
| 11: 最小化均方误差损失:
|
| 12: 采Adam优化器对价值网络参数w进行更新:
|
| 13: 计算重要性采样比: 14: 更新自适应裁剪参数 :
|
| 15: 更新非对称裁剪参数:
|
| 16: clip损失函数:
|
| 17: 采Adam优化器对策略网络参数 进行更新:
|
| 18: 若奖励函数满足收敛条件或达到预设最大训练轮数,则终止训练。 |
| end for |
3 仿真验证
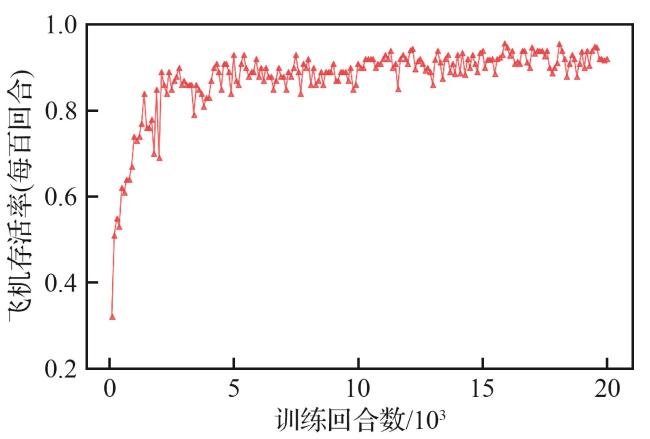
3.1 训练与评估
表3 飞机参数及红外干扰参数Table 3 Aircraft parameters and infrared jamming parameters |
| 性能参数 | 数值或设置 |
|---|---|
| 最大过载 /g | 2.5 |
| 红外诱饵弹初始质量 /kg | 0.5 |
| 红外诱饵弹质量变化率 /(kg·s-1) | 0.01 |
| 红外诱饵弹速度 /(m·s-1) | 50 |
| 红外诱饵弹最大辐射强度 /(W·(sr)-1) | 9 000 |
| 红外诱饵弹燃烧时间 /s | 5 |
| 红外诱饵弹投放方向 | 沿机体坐标 系后下方45° |
| 激光定向干扰输出功率 /W | 4 000 |
| 激光束散角 /rad | 1×10-3 |
| 激光波长 /μm | 10.6 |
表4 导弹性能参数Table 4 Missile performance parameters |
| 导弹性能参数 | 数值 |
|---|---|
| 最大过载 /g | 50 |
| 导弹杀伤半径 /m | 12 |
| 导引头最大作用距离 /m | 12 000 |
| 导引头视场角度 /(°) | 180 |
| 导弹最大角速度 /(rad·s-1) | 15.7 |
| 导引头光学系统焦距 /mm | 57 |
| 红外探测器像元尺寸 /μm | 12 |
表5 DACTM-PPO算法训练参数Table 5 DACTM-PPO algorithm training parameters |
| 算法参数 | 数值 |
|---|---|
| 最大训练次数 | |
| PPO剪切系数 | 0.2 |
| 折扣因子 | 0.95 |
| GAE折扣系数 | 0.98 |
| 熵正则项系数 | |
| 每轮训练迭代次数 | 4 |
| LSTM隐层维度 | 128 |
| LSTM层数 | 1 |
| 注意力键/查询维度 | 128 |
| 注意力Dropout概率 | 0.2 |
| Actor/Critic网络结构 | [256, 128, 64, 32] |
| Actor/Critic学习率 | |
| 训练批次样本数 | 128 |
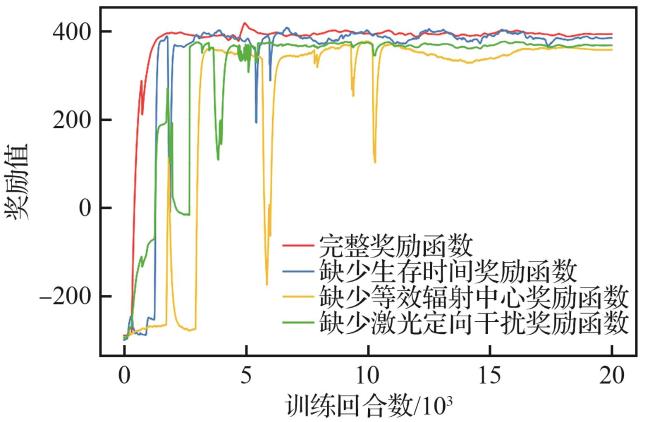
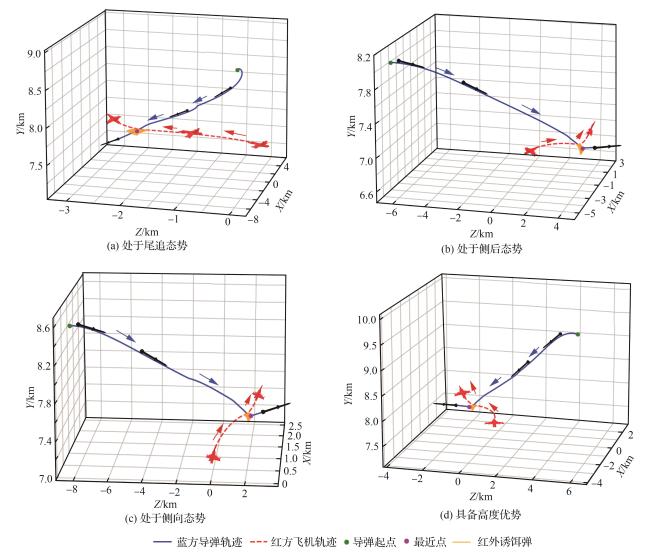
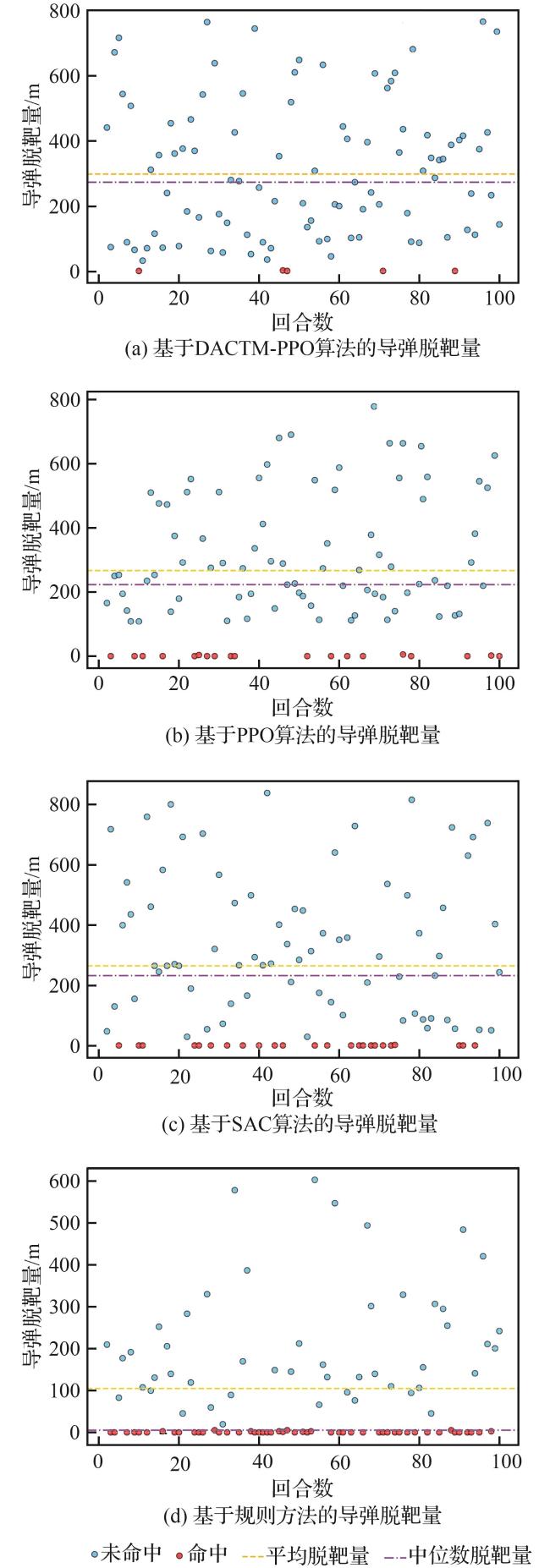
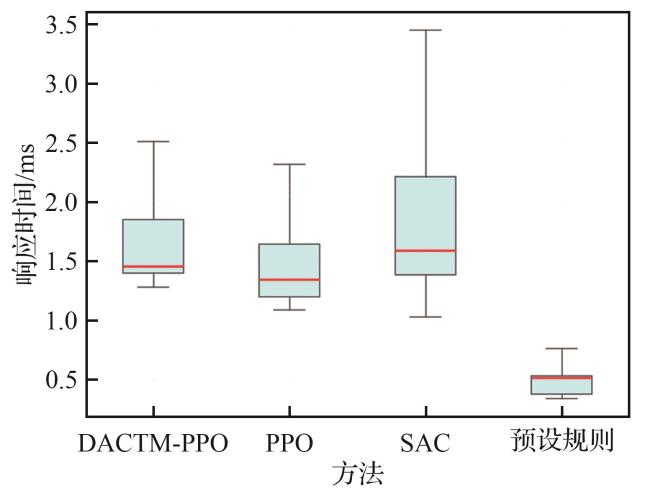
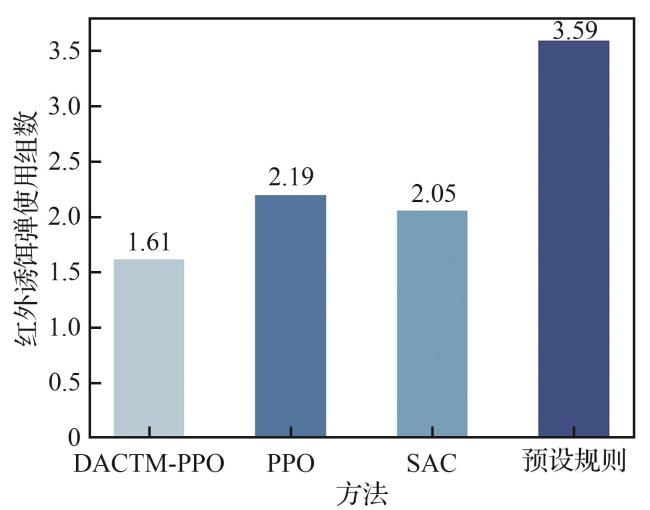
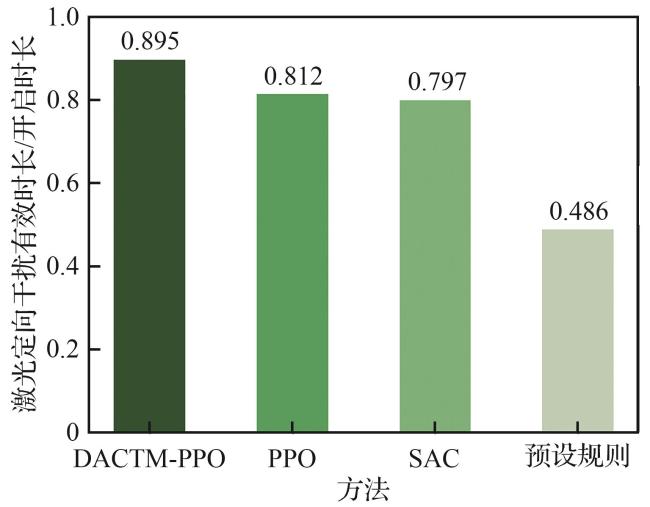
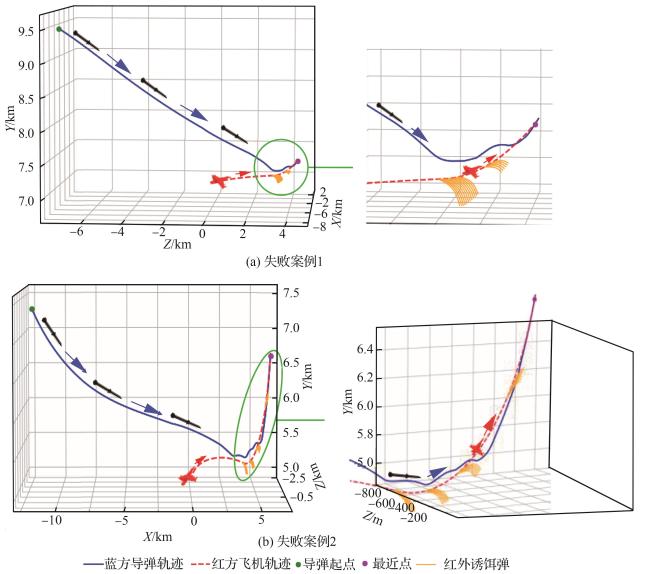
3.2 算法对比
表6 SAC算法训练参数Table 6 SAC algorithm training parameters |
| 参数 | 数值 |
|---|---|
| 最大训练次数 | |
| 折扣因子 | 0.95 |
| Actor/Critic学习率 | |
| 批样本次数 | 128 |
| 软更新系数 | |
| 初始温度 | 0.01 |
| 温度学习率 |
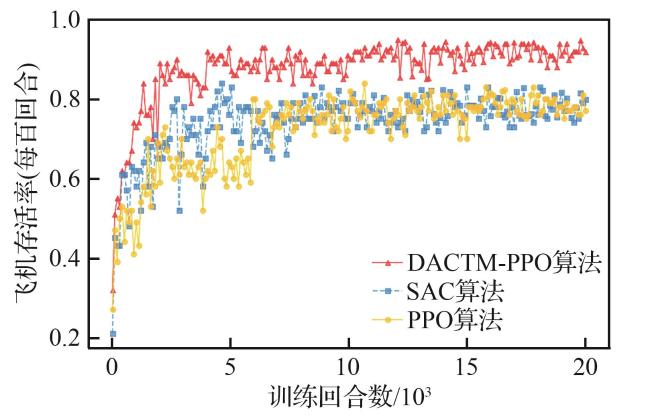
3.2.1 收敛性能对比
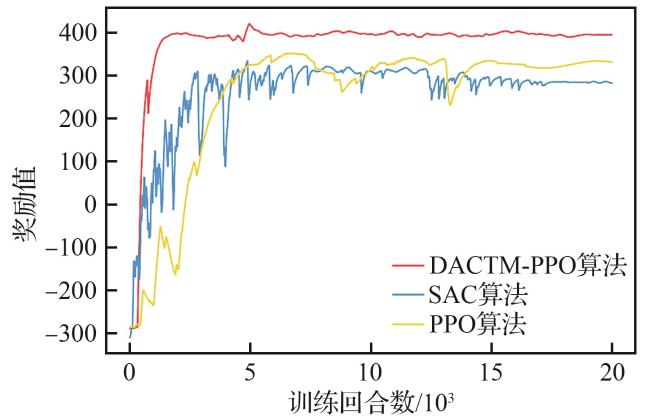
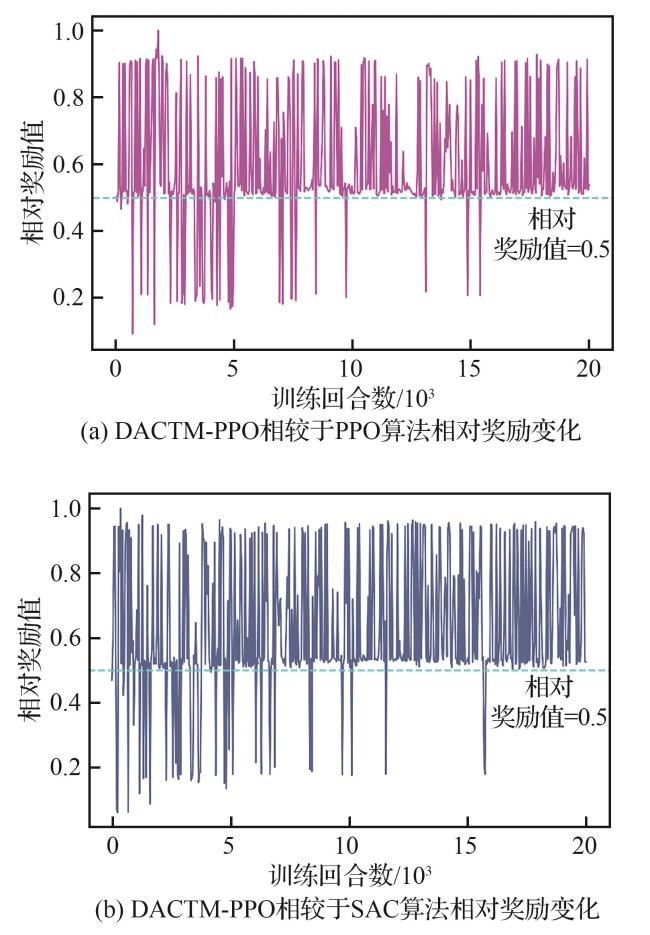
表7 收敛效果对比Table 7 Convergence effect comparison |
| 算法 | 飞机存活率/% | 平均训练时长/s |
|---|---|---|
| DACTM-PPO | 94.6 | 5 589.39 |
| PPO | 81.2 | 5 083.36 |
| SAC | 79.6 | 24 108.40 |
| 预设规则 | 49.2 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}