
1 有人/无人机协同智能空战的可解释问题建模
1.1 场景描述
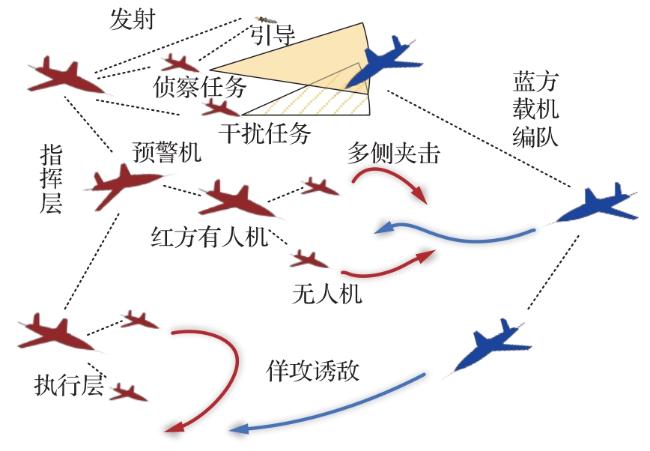
1.2 数学模型
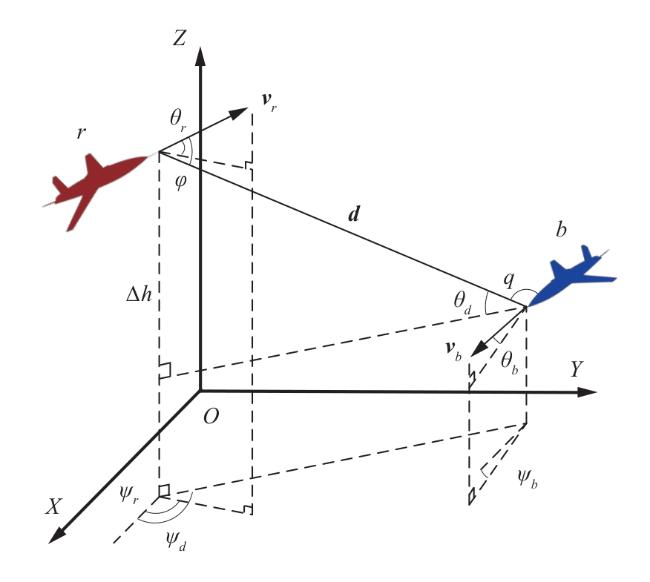
1.3 基于深度强化学习的算法设计
1.3.1 动作空间和状态空间设计
1.3.2 奖励函数设计
2 基于Bayesian-Shapley的可解释强化学习
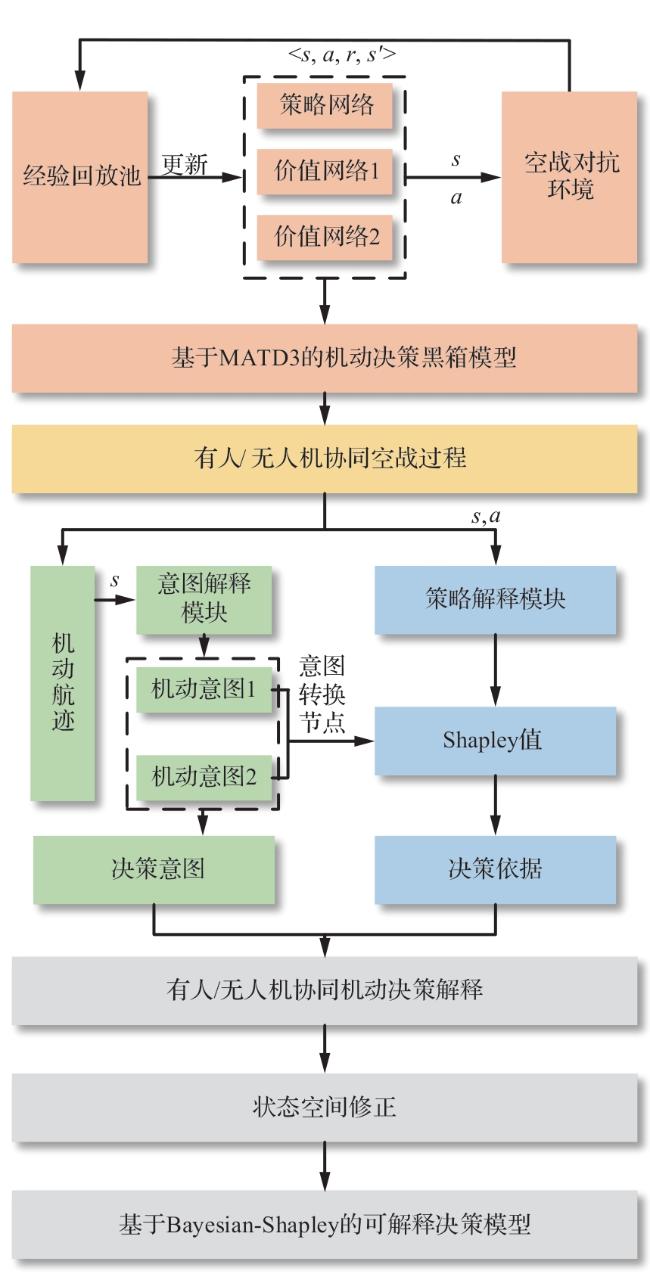
2.1 可解释模型框架
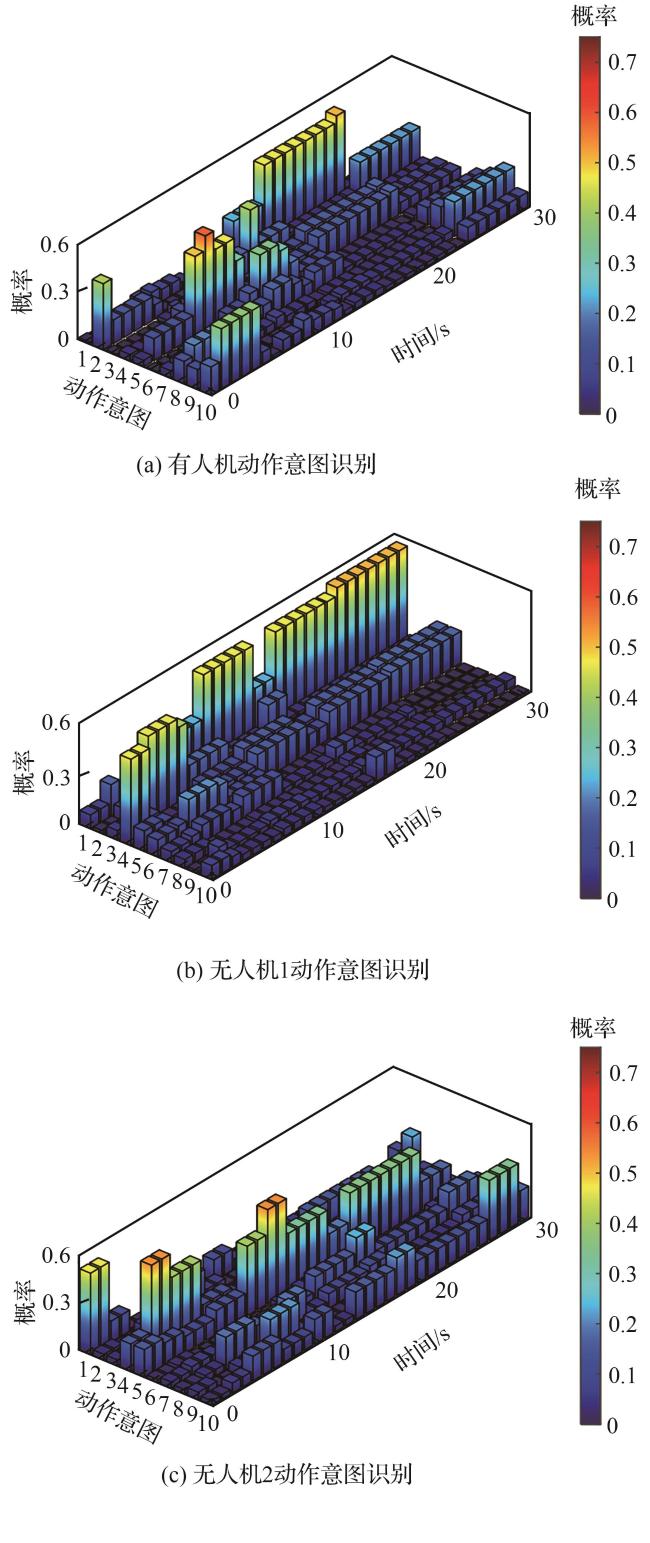
2.2 动态Bayesian网络的机动意图识别
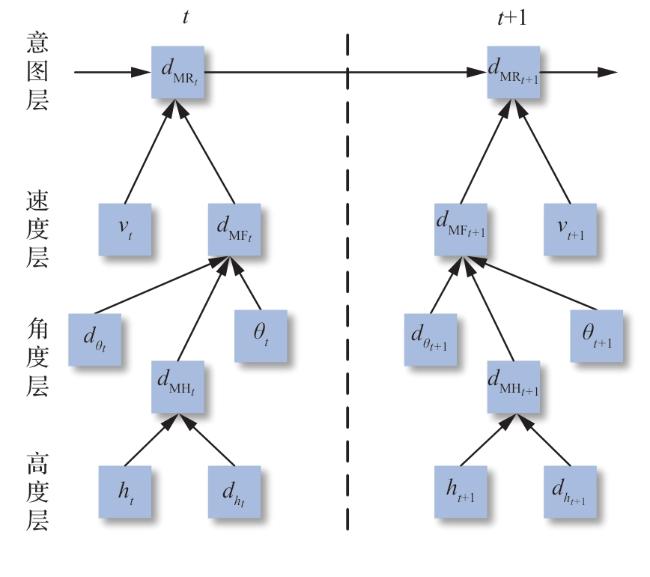
表1 机动动作状态参数变化特征Table 1 Maneuver state parameter variation characteristics |
| 机动类型 | 编号 | 机动状态 | 速度 | 速度偏角 | 速度偏角变化率 | 高度 | 高度变化率 |
|---|---|---|---|---|---|---|---|
| 直线类 | 1 | 平飞 | 保持 | 保持 | 保持 | 保持 | 保持 |
| 2 | 爬升 | 减小 | 保持 | 保持 | 增大 | 增大-减小 | |
| 3 | 俯冲 | 增大 | 保持 | 保持 | 减小 | 减小-增大 | |
| 盘旋类 | 4 | 左盘旋 | 保持 | 减小 | 保持 | 保持 | 保持 |
| 5 | 右盘旋 | 保持 | 增大 | 保持 | 保持 | 保持 | |
| 6 | 半滚倒转 | 增大 | 突变 | 突变 | 减小 | 增大-减小 | |
| 翻滚类 | 7 | 桶滚 | 减小 | 突变 | 突变 | 增大-减小 | 增大-减小 |
| 8 | 筋斗 | 增大 | 突变 | 突变 | 增大-减小 | 增大-减小 | |
| 9 | 半筋斗 | 减小 | 突变 | 突变 | 增大 | 增大-减小 | |
| 战斗转弯类 | 10 | 战斗转弯 | 减小-增大 | 突变 | 突变 | 增大-减小 | 增大-减小 |
| |
|---|
| 输入:s:时间段T内各架飞行器状态 1.初始化网络节点的状态机维数 2.加载先验概率表、动作状态转移概率表和条件概率表 3.特征序列提取,得到 、 、 、 和 4.for t in range T 5. 计算各观测特征发生的概率: 、 、 、 和 6. 求解执行动作 下观测到 的条件概率分布 7. While true 8. 计算归一化因子 9. 求解观测 下的动作 的概率 10. 更新决策节点的概率分布,最大概率大于n时退出循环 11.输出推理结果为决策节点中概率最大的决策结果,重置网络 |
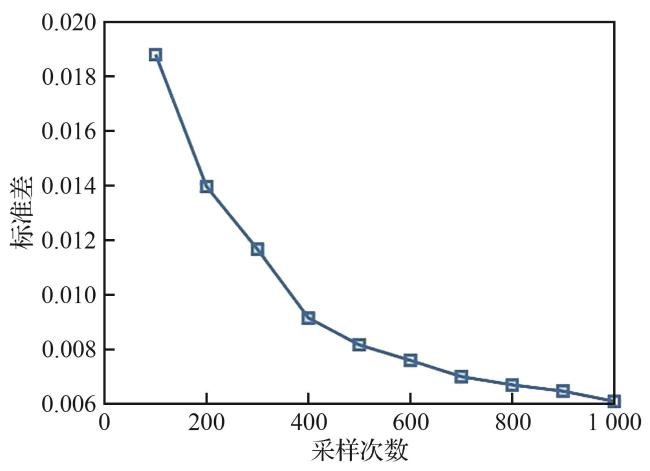
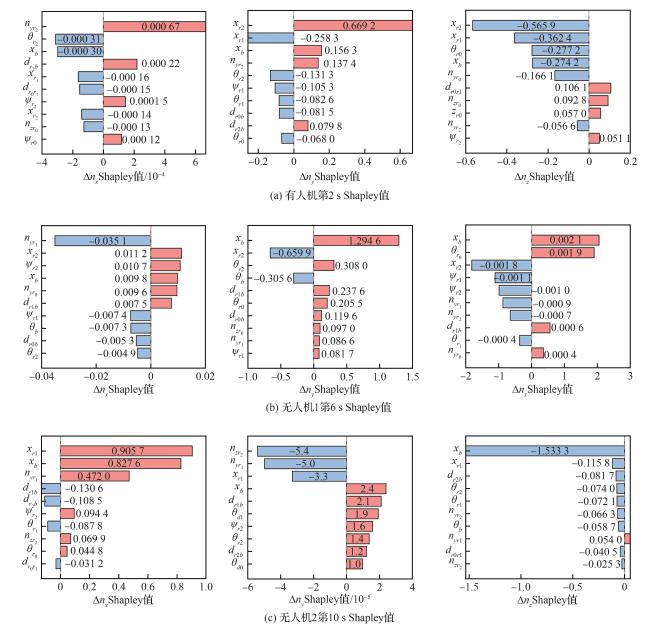
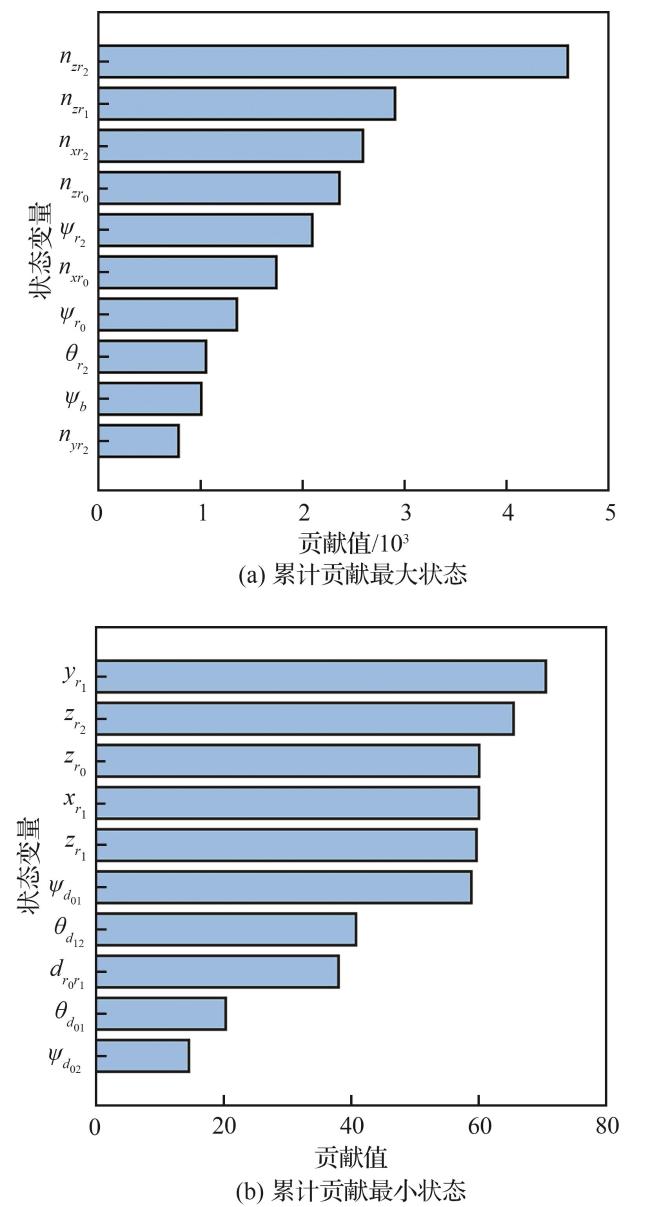
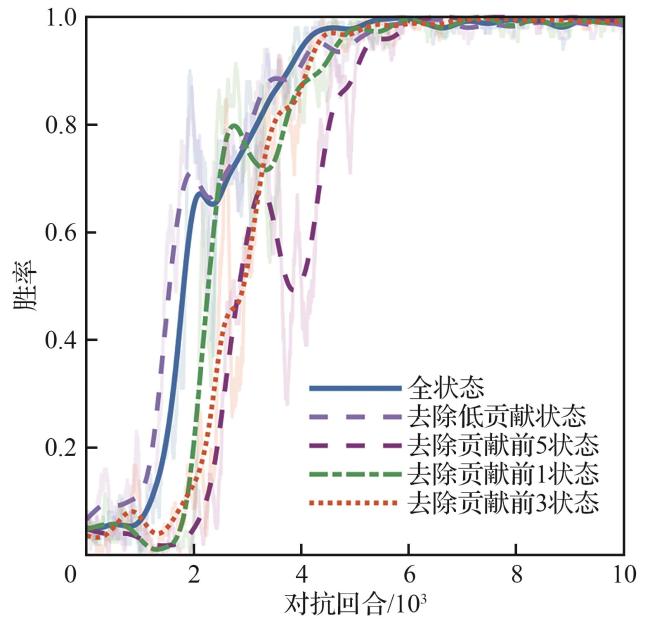
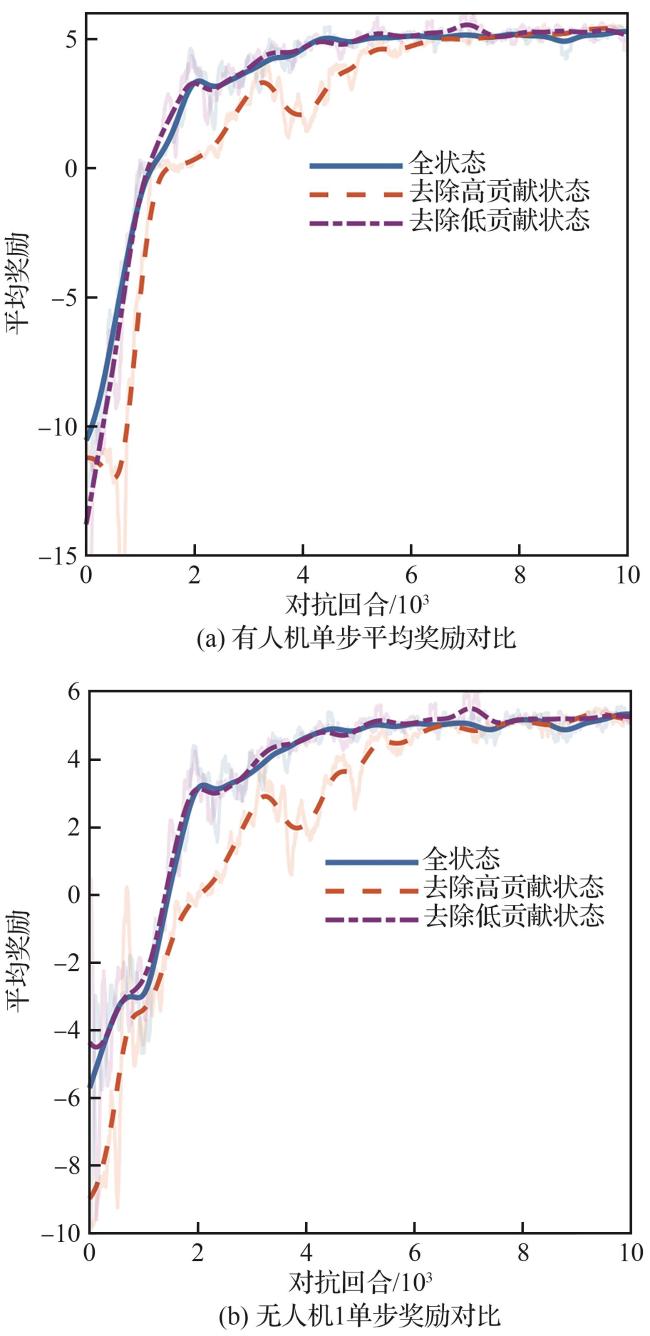
2.3 基于Shapley算法的关键决策节点解释
| |
|---|
| 输入 observation:观测状态 uav_model:决策模型 baseline:基线输入 1. for i in range num_samples 2. 随机排列状态索引:feature_order 3. 计算基线输出 4. for j in feature_order 5. 改变状态j为观测状态 6. 计算状态j的边际贡献 7. 累加状态j的边际贡献 8. 更新基线输出 9.取累计贡献的平均值:shapley_value |
3 仿真验证
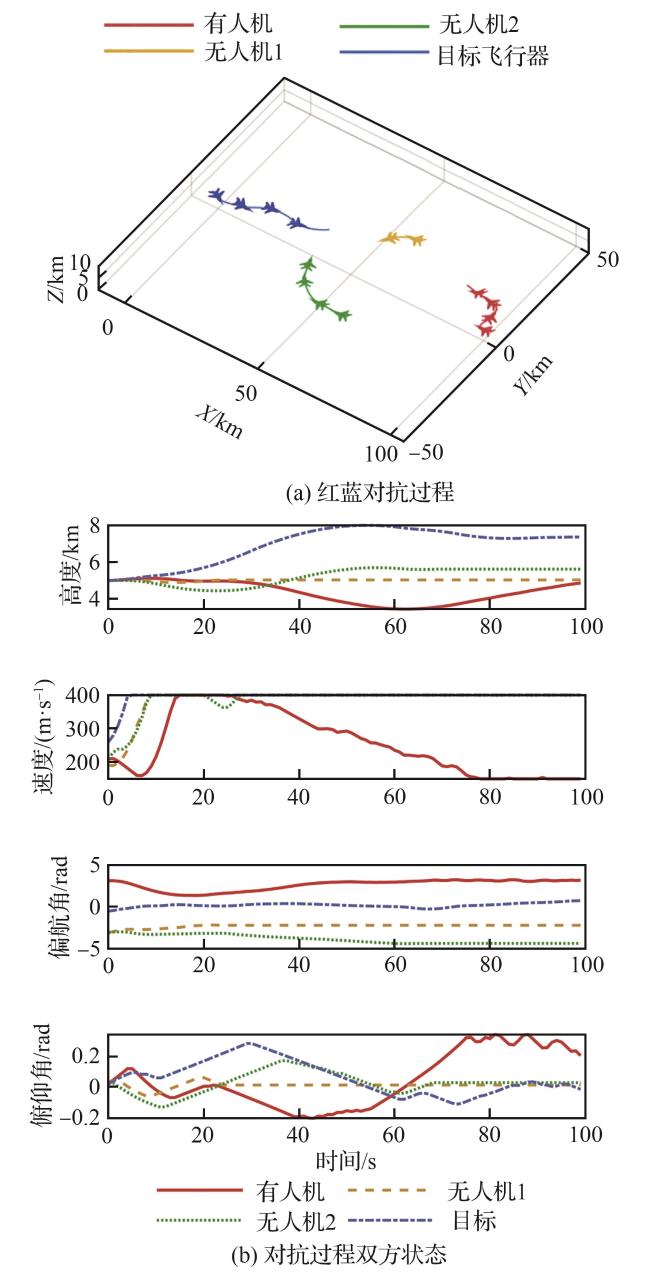
3.1 基于MATD3的有无人协同训练仿真
表2 红方有人机参数Table 2 Manned aerial vehicle parameters of red side |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
表3 红方无人机参数Table 3 Unmanned aerial vehicle parameters of red side |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
表4 蓝方有人机参数Table 4 Unmanned aerial vehicle parameters of blue side |
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
表5 超参数设置Table 5 Hyperparameter setting |
| 参数 | 数值 |
|---|---|
| Actor学习率 | |
| Critic学习率 | |
| 软更新因子 | |
| 学习衰减率 | |
| 经验回放池容量 | |
| 抽取样本数 | |
| 学习间隔步长 | |
| 训练最大局数 |
表6 训练场景参数设置Table 6 Environmental parameter setting |
| 参数 | 数值 |
|---|---|
| 无人机数量 | 2 |
| 100 | |
| 蓝方初始位置 | (0,0,5) |
| 蓝方初始航向/(°) | |
| 有人机初始位置 | (100,0,5) |
| 有人机初始航向/(°) | [150,210] |
| 无人机1初始位置 | (60,30,5) |
| 无人机1初始航向/(°) | [150,210] |
| 无人机2初始位置 | |
| 无人机2初始航向/(°) | [150,210] |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}