Acta Aeronautica et Astronautica Sinica ›› 2026, Vol. 47 ›› Issue (4): 332217.doi: 10.7527/S1000-6893.2025.32217
• Electronics and Electrical Engineering and Control • Previous Articles
Yu LI1, Xinlong XU2, Kecheng LI3, Chi-yung WEN1, Ni LI4, Xiaoxiong LIU3( )
)
Received:2025-05-12
Revised:2025-07-29
Accepted:2025-09-05
Online:2025-09-19
Published:2025-09-18
Contact:
Xiaoxiong LIU
E-mail:liuxiaoxiong@nwpu.edu.cn
Supported by:CLC Number:
Yu LI, Xinlong XU, Kecheng LI, Chi-yung WEN, Ni LI, Xiaoxiong LIU. Deep-stall recovery control based on safety-constrained reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2026, 47(4): 332217.

Fig.1
Control surface configuration of V-tail aircraft


Fig.2
Control structure of deep-stall recovery
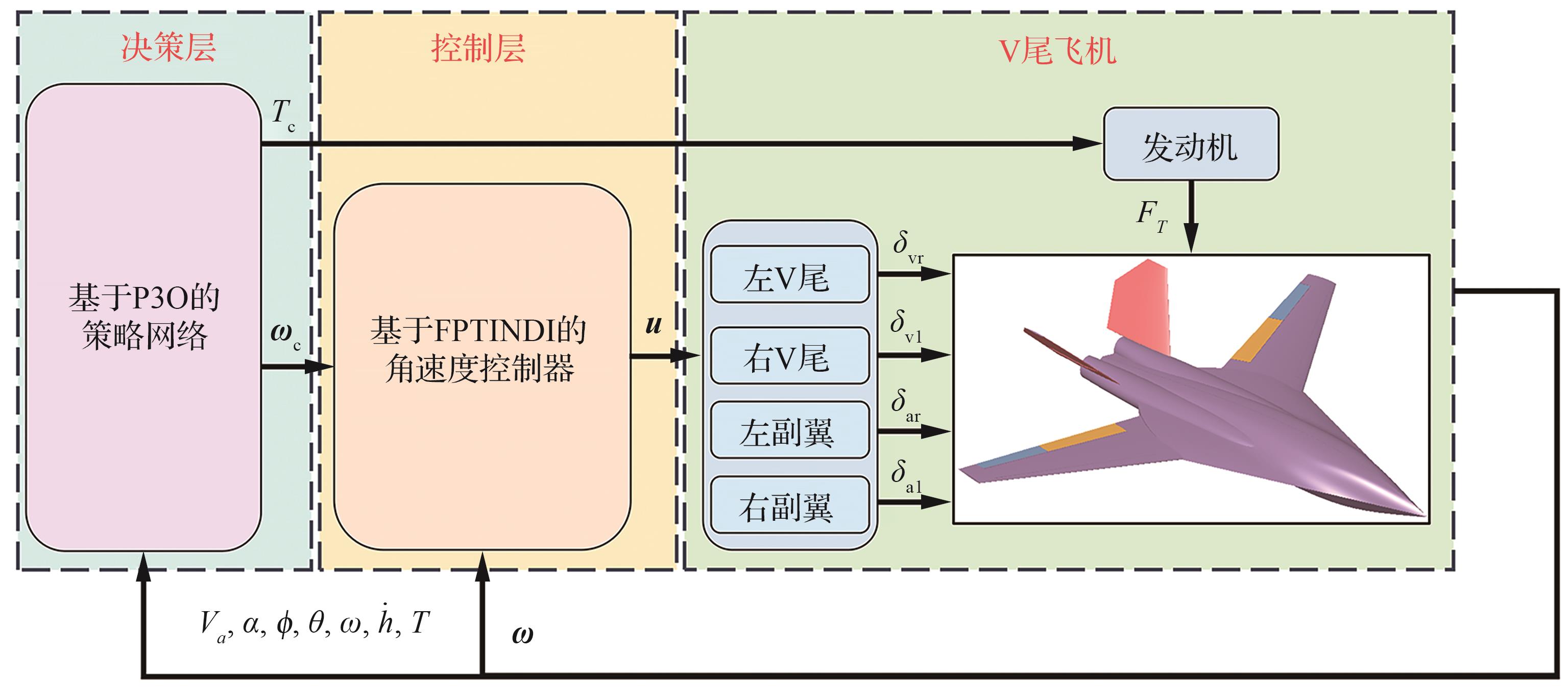

Fig.3
FPTINDI-based angular rate controller


Fig.4
Adaptive constraint threshold adjustment
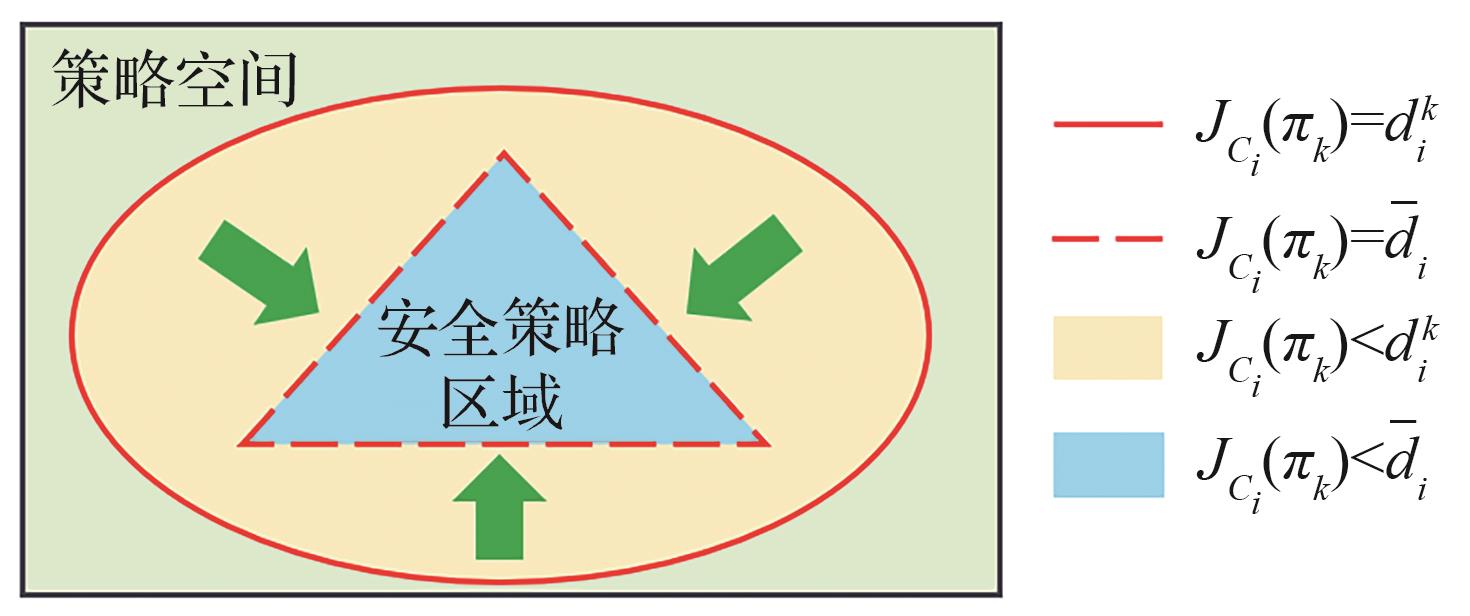
Table 1
Parameters of FPTINDI controller
| 组成 | 参数 |
|---|---|
| NTD | |
| FPTNF | |
| FPTINDI |
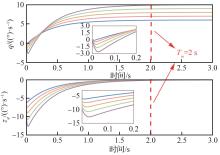
Fig.5
Response of pitch angular rate and its error

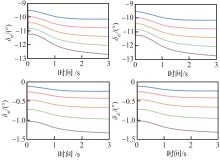
Fig.6
Deflections of control surfaces
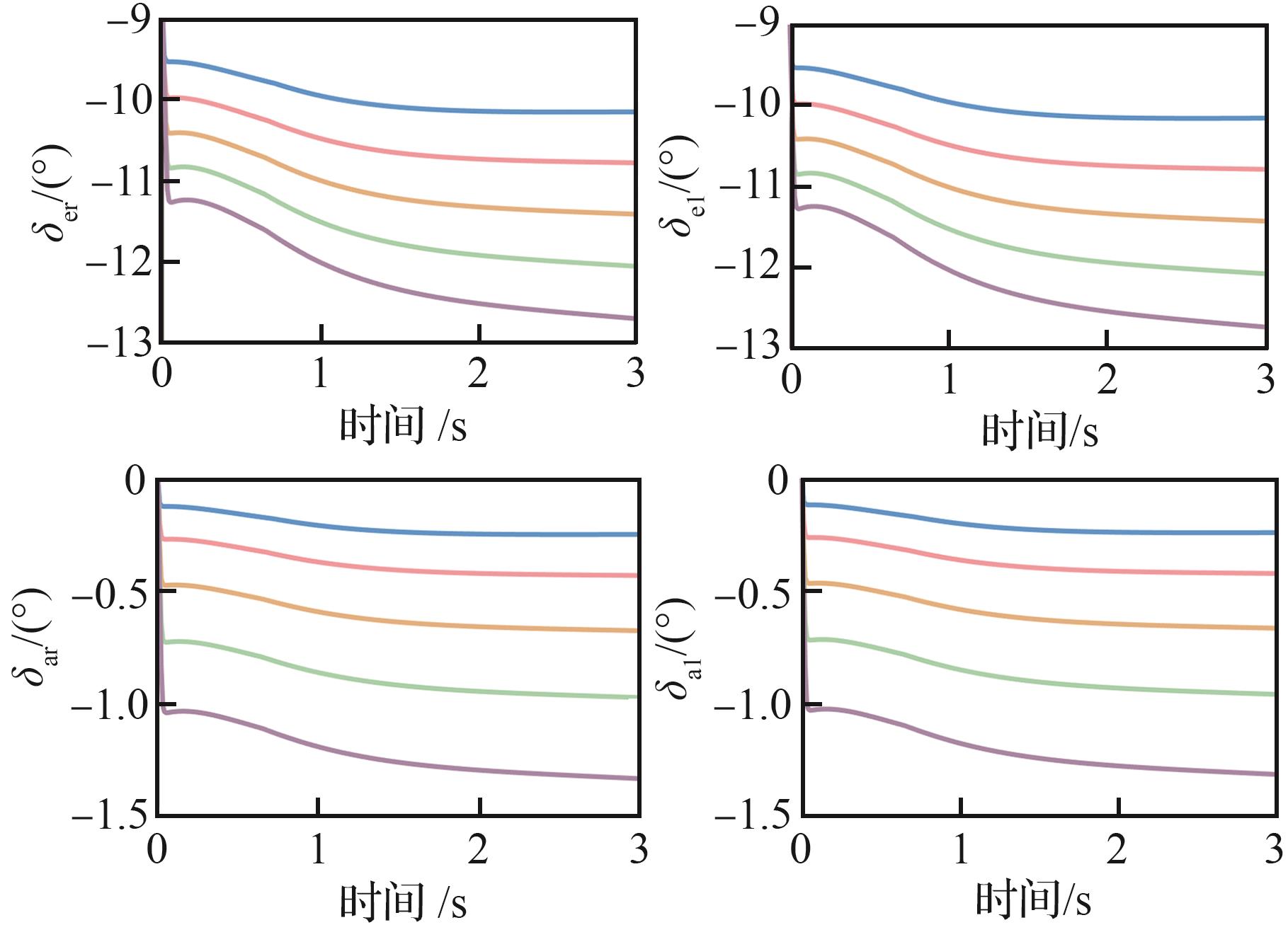

Fig.7
Comparison of angular rate response


Fig.8
Comparison of control surfaces

Table 2
Parameters of strategy network, reward function, and cost function
| 组成 | 参数 |
|---|---|
| 策略网络 | |
| 奖励函数和成本函数 |
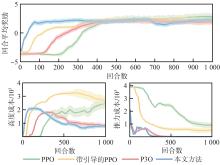
Fig.9
Comparison of reward and cost convergence
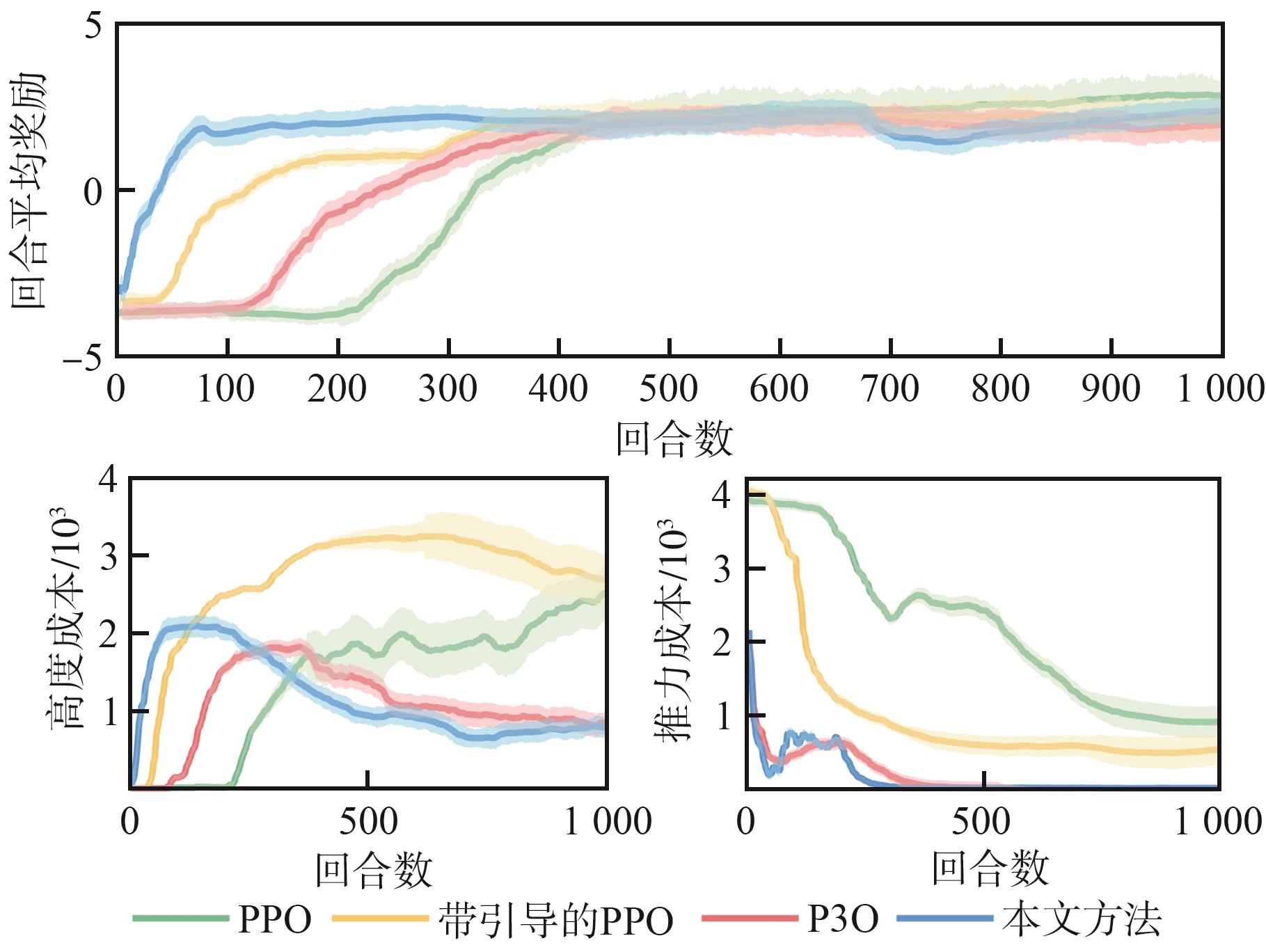

Fig.10
Comparison of fixed and adaptive thresholds
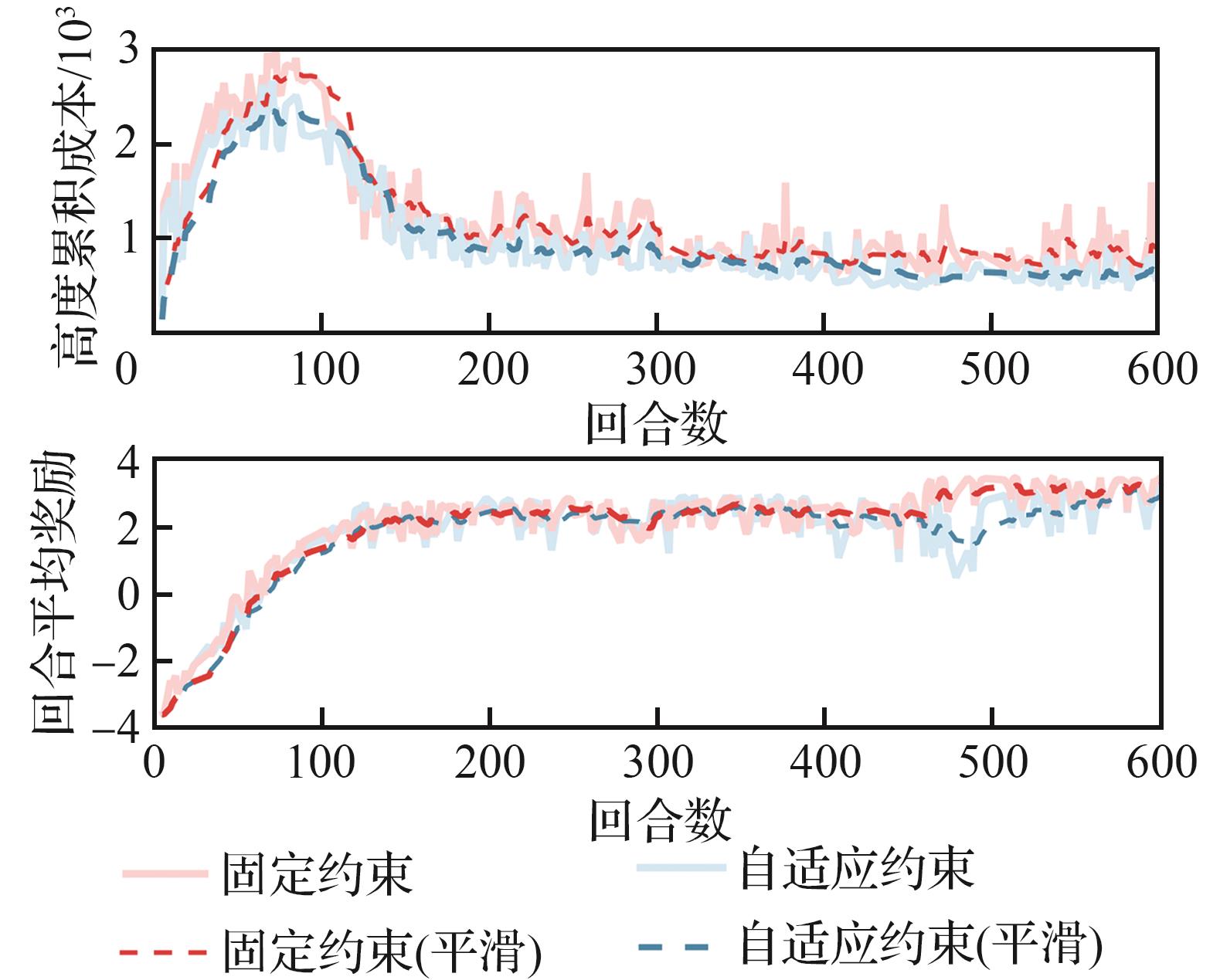

Fig.11
Comparison of altitude


Fig.12
Comparison of angle of attack


Fig.13
Phase portrait of angle of attack

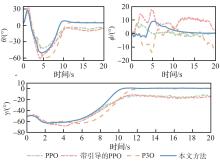
Fig.14
Comparison of aircraft states
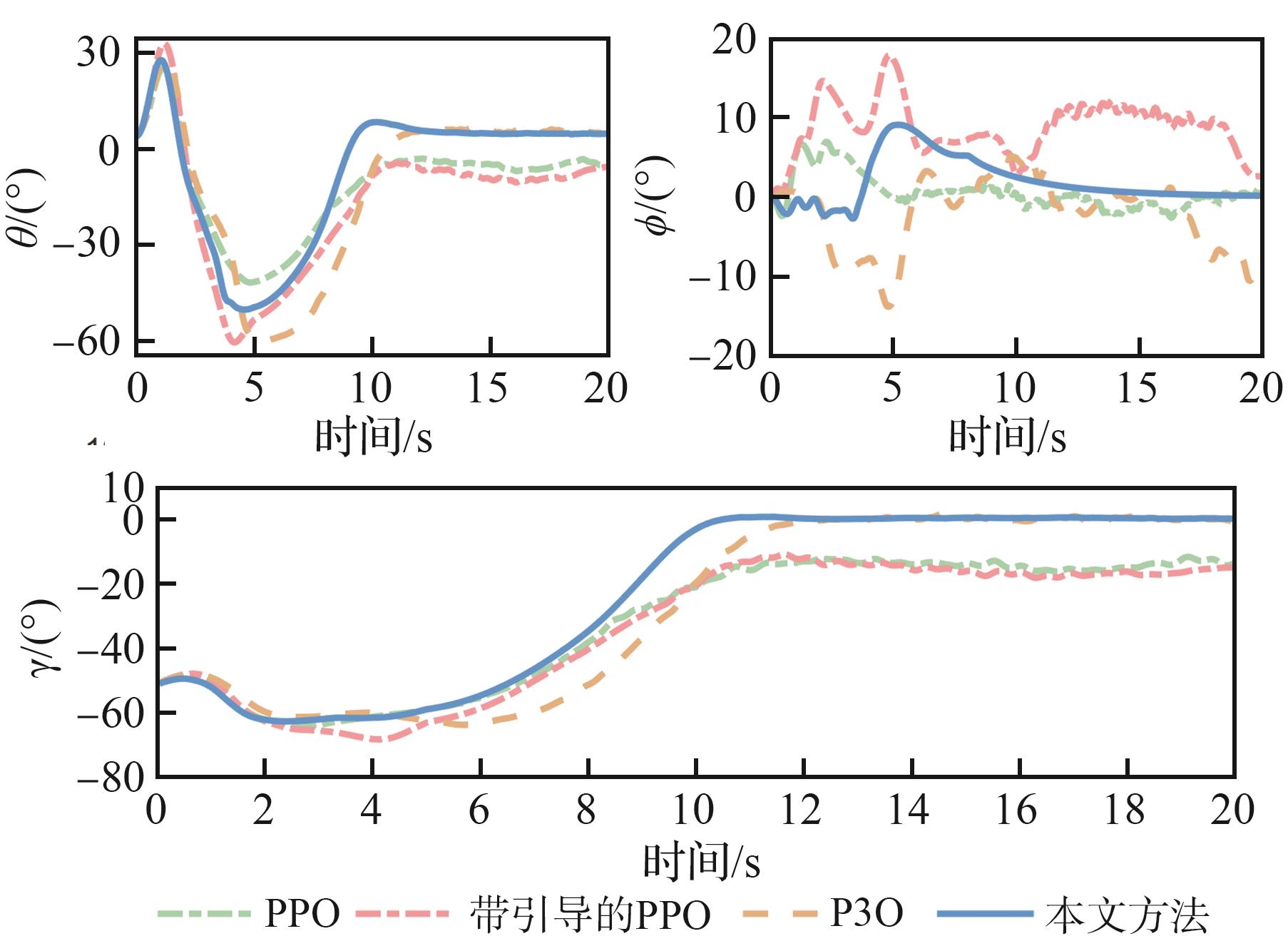
Fig.15
Comparison of control inputs
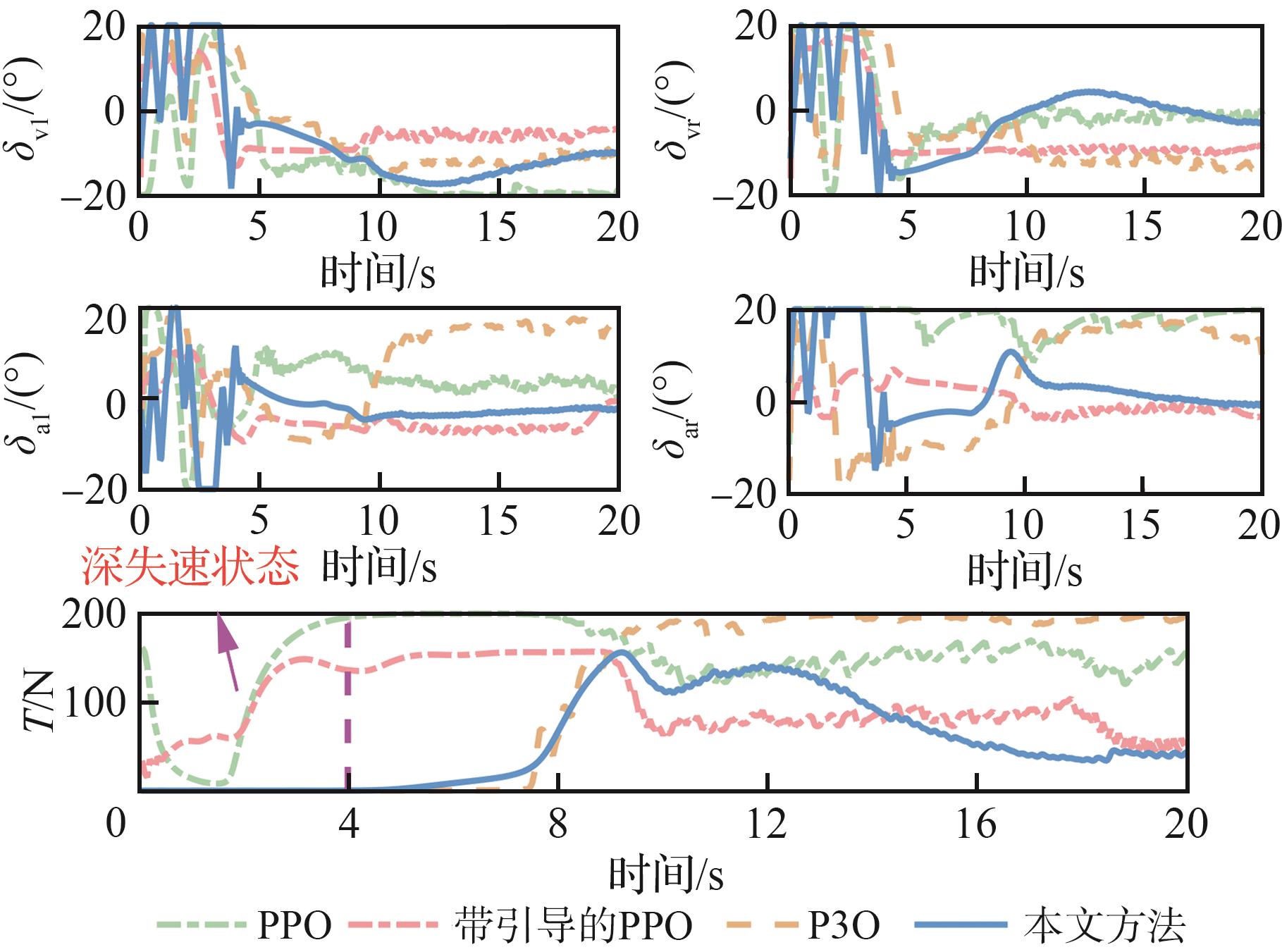

Fig.16
Comparison of altitude under different strategies


Fig.17
Comparison of angle of attack under different strategies
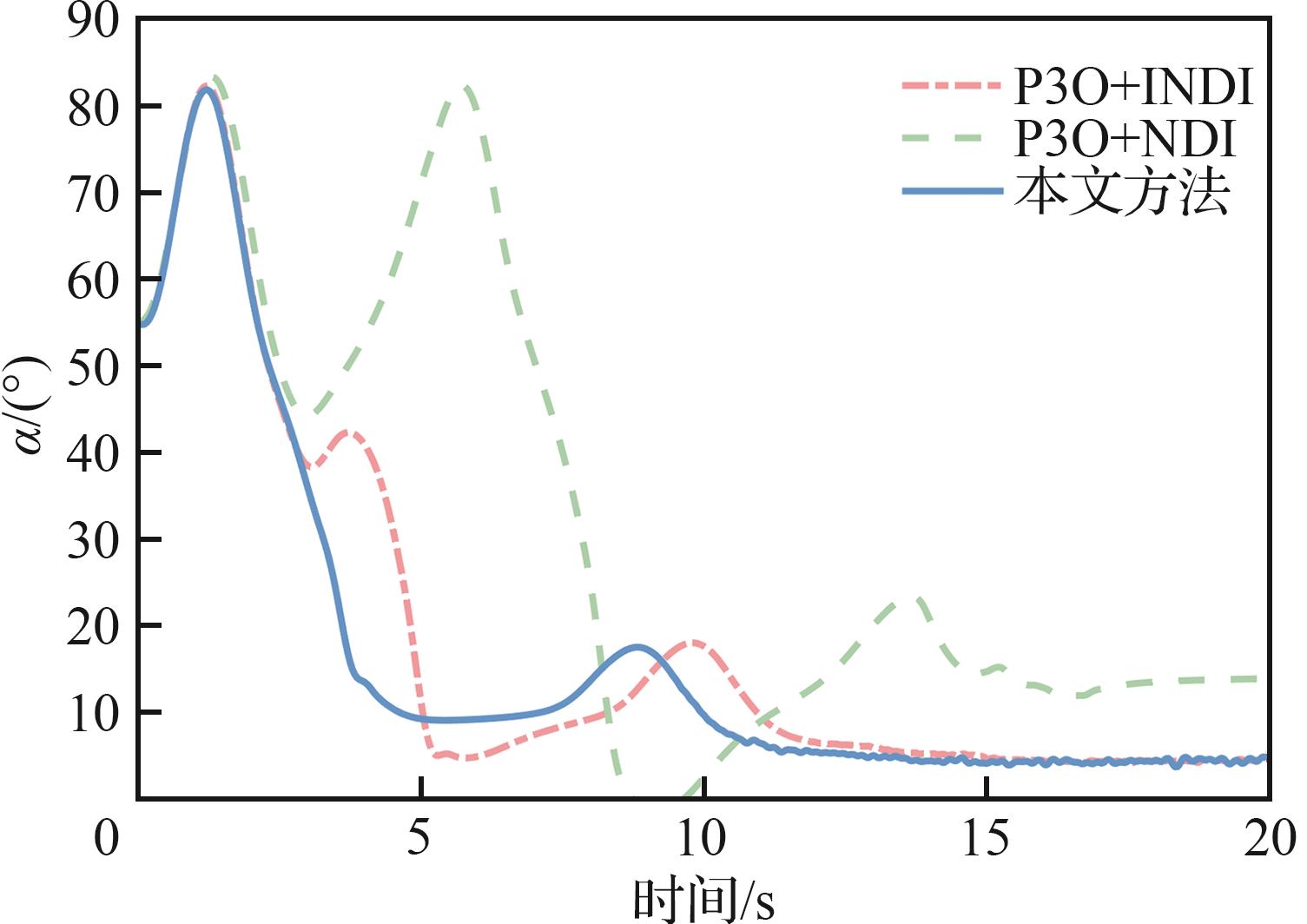
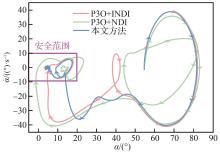
Fig.18
Phase portrait comparison of angle of attack under different strategies
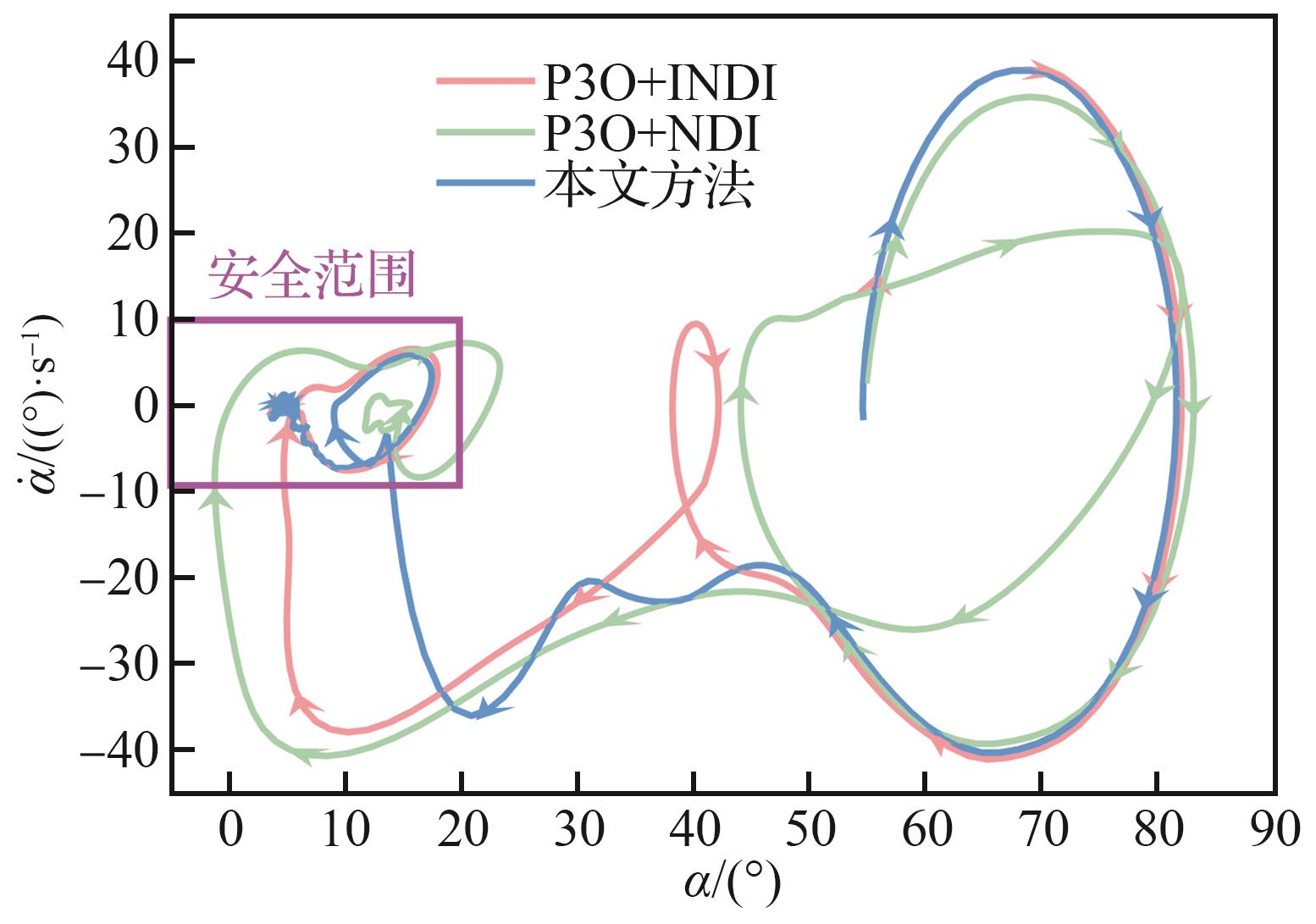
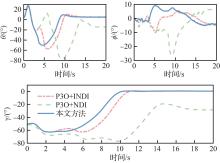
Fig.19
Comparison of aircraft states under different strategies


Fig.20
Comparison of actuators and thrust under different strategies


Fig.21
Monte Carlo simulation results

Table 3
Statistics of control surface deflections
| 舵面 | 改出过程平均出舵量/( | 标准差/( |
|---|---|---|
| 14.85 | 2.78 | |
| 15.35 | 3.53 | |
| 13.86 | 2.56 | |
| 11.95 | 1.89 |
| [1] | TAYLOR R T, RAY E J. Deep-stall aerodynamic characteristics of T-tail aircraft[R]. Washington, D.C.: NASA, 1965. |
| [2] | NGUYEN D H, LOWENBERG M H, NEILD S A. Analysing dynamic deep stall recovery using a nonlinear frequency approach[J]. Nonlinear Dynamics, 2022, 108(2): 1179-1196. |
| [3] | 陈永亮, 沈宏良, 刘昶. 飞机深失速改出特性分析与控制[J]. 南京航空航天大学学报, 2007, 39(4): 435-439. |
| CHEN Y L, SHEN H L, LIU C. Analysis and control of aircraft deep stall recovery characteristics[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2007, 39(4): 435-439 (in Chinese). | |
| [4] | 艾文磊. 歼击机深失速特性分析及改出控制研究[D]. 南京: 南京航空航天大学, 2015. |
| AI W L. Characteristics analysis and recovery control for deep-stall of fighters[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2015 (in Chinese). | |
| [5] | TRUBSHAW E B. Low speed handling with special reference to the super stall[J]. Journal of the Royal Aeronautical Society, 1966, 70(667): 695-704. |
| [6] | ILOPUTAIFE O I. Design of deep stall protection for the C-17A[J]. Journal of Guidance, Control, and Dynamics, 1997, 20(4): 760-767. |
| [7] | DEFAZIO P A, LARSEN R. Final committee report on the design, development, and certification of the boeing 737 max [EB/OL]. (2020-09-16)[2025-05-12]. . |
| [8] | JIANG H T, XIONG H, ZENG W F, et al. Safely learn to fly aircraft from human: An offline-online reinforcement learning strategy and its application to aircraft stall recovery[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(6): 8194-8207. |
| [9] | SINGH TOMAR D, GAUCI J, DINGLI A, et al. Automated aircraft stall recovery using reinforcement learning and supervised learning techniques[C]∥2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC). Piscataway: IEEE Press, 2021. |
| [10] | KOOPMAN C, ZAMMIT-MANGION D. Using reinforcement learning for AI systems in the mitigation of automation failures and stall recovery in complex aircraft[C]∥ AIAA SciTech 2024 Forum. Reston: AIAA, 2024. |
| [11] | GRILLO A, TORRE G, BUNGE R. Optimal stall recovery via deep reinforcement learning for a general aviation aircraft[C]∥ AIAA SciTech 2024 Forum. Reston: AIAA, 2024. |
| [12] | 李煜, 陈通文, 王志刚, 等. 基于预定义时间的直接升力着舰增量控制[J]. 航空学报, 2025, 46(13): 531163. |
| LI Y, CHEN T W, WANG Z G, et al. Incremental control of direct lift landing based on predefined-time theory[J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(13): 531163 (in Chinese). | |
| [13] | 罗飞, 张军红, 王博, 等. 基于直接升力与动态逆的舰尾流抑制方法[J]. 航空学报, 2021, 42(12): 124770. |
| LUO F, ZHANG J H, WANG B, et al. Air wake suppression method based on direct lift and nonlinear dynamic inversion control[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(12): 124770 (in Chinese). | |
| [14] | KOLB S, HÉTRU L, FAURE T M, et al. Nonlinear analysis and control of an aircraft in the neighbourhood of deep stall[J]. AIP Conference Proceedings, 2017, 1798: 020080. |
| [15] | LI Y, WEN C Y, LIU X X, et al. Prescribed-time fault-tolerant flight control for aircraft subject to structural damage[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 1848-1859. |
| [16] | 吴慈航, 闫建国, 钱先云, 等. 受油机指定时间姿态稳定控制[J]. 航空学报, 2022, 43(2): 324996. |
| WU C H, YAN J G, QIAN X Y, et al. Predefined-time attitude stabilization control of receiver aircraft[J]. Acta Aeronautica et Astronautica Sinica, 2022, 43(2): 324996 (in Chinese). | |
| [17] | YE D, ZOU A M, SUN Z W. Predefined-time predefined-bounded attitude tracking control for rigid spacecraft[J]. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(1): 464-472. |
| [18] | LI Y, WANG T Q, LIU X X, et al. Predefined-time active fault-tolerant control of transport aircraft subject to control surface failures[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(3): 5731-5744. |
| [19] | TIAN D P, SHEN H H, DAI M. Improving the rapidity of nonlinear tracking differentiator via feedforward[J]. IEEE Transactions on Industrial Electronics, 2014, 61(7): 3736-3743. |
| [20] | KHALIL H K. Nonlinear system[M]. 3rd ed. Englewood Cliffs: Prentice-Hall, 2002:5-10. |
| [21] | YU X, WU Z J. Stochastic barbalat’s lemma and its applications[J]. IEEE Transactions on Automatic Control, 2012, 57(6): 1537-1543. |
| [22] | ZHANG L R, SHEN L, YANG L, et al. Penalized proximal policy optimization for safe reinforcement learning [EB/OL]. arXiv preprint: 2205.11814, 2022. |
| [23] | JOHN S, PHILIPP M, SERGEY L, et al. High-dimensional continuous control using generalized advantage estimation [EB/OL]. arXiv preprint: 1506.02438, 2016. |
| [24] | KINGMA D P, JIMMY B. Adam: A method for stochastic optimization [EB/OL]. arXiv preprint: 1412.6980, 2017. |
| [25] | SCHULAMN J, MORITZ P, LEVINE S, et, al. High-dimensional continuous control using generalized advantage estimation[C]∥ International Conference on Learning Representations. New York: ACM, 2016. |
| [1] | . Research on Hybrid Active-Passive Fault-Tolerant Control for Carrier Land-ing Subject to Control Surface Effectiveness Loss [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [2] | . Design and Wind Tunnel Testing of an Advanced Controller for Flying Boom Aerial Refuel Docking [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [3] | . An integrated intelligent decision-making algorithm for penetration and strike considering the field of view angle constraint [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [4] | . An intelligent modeling method for aircraft formation behaviors integrating LLM technology [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [5] | . Hierarchical fault-tolerant formation control for unmanned helicopters based on the fully actuated system approach [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [6] | . Distributed Safety Cooperative Control for Multiple UAVs under Multi-Source Risks [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [7] | Erchao RONG, Yuying ZHANG, Junning LIANG, Ximin LYU. Neural-network aerodynamics-based NMPC trajectory tracking control for a tail-sitter VTOL UAV [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(24): 331995-331995. |
| [8] | Guocheng YAN, Honglun WANG, Yanxiang WANG, Yuebin LUN, Junfan ZHU. Prescribed performance anti-swing control for wing rotation process of UAV towed aerial recovery [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(24): 331840-331840. |
| [9] | Jiong HE, Binwu REN, Siliang DU, Yousong XU, Bo WANG. Adaptive attitude control for tilt-quadrotor UAV based on ADRC-RBF [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(S1): 732189-732189. |
| [10] | Pan ZHOU, Ni LI, Jiangtao HUANG, Qinglin YANG, Yunxiao LIAN. Autonomous decision-making in close-range game under imperfect information for unmanned aerial vehicles [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(S1): 732215-732215. |
| [11] | Zhihao HE, Peng KOU, Bohua LIANG, Deliang LIANG. Powered yaw predictive control of distributed electric propulsion aircraft considering slipstream effects [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(S1): 732305-732305. |
| [12] | Zhao-Xing LI YANG LIN. Finite-Time Deep Stall Recovery Control for Fighter Aircraft Using Forced Oscillation [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [13] | . 基于多目标强化学习的太阳能无人机航迹规划 [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [14] | . Health assessment for electro-hydraulic servomechanism integrating multi-source information [J]. Acta Aeronautica et Astronautica Sinica, 0, (): 1-0. |
| [15] | Yicheng SONG, Ruiyun QI, Bin JIANG. Distributed topology reconstruction of UAV formation network under communication fault [J]. Acta Aeronautica et Astronautica Sinica, 2025, 46(22): 331914-331914. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Address: No.238, Baiyan Buiding, Beisihuan Zhonglu Road, Haidian District, Beijing, China
Postal code : 100083
E-mail:hkxb@buaa.edu.cn
Total visits: 6658907 Today visits: 1341All copyright © editorial office of Chinese Journal of Aeronautics
All copyright © editorial office of Chinese Journal of Aeronautics
Total visits: 6658907 Today visits: 1341