
1 相关工作
1.1 基于博弈论的集群协同建模研究
1.2 无人集群鲁棒性评估研究
2 无人机集群协同感知系统模型
2.1 协同感知场景描述
2.2 基于鹰鸽博弈的无人机集群建模
表1 概念映射关系Table 1 Concept mapping relationships |
| 无人机集群协同感知 | 鹰鸽演化博弈 |
|---|---|
| 无人机集群 | 结构化种群 |
| 单个无人机 | 个体节点 |
| 数据分析(策略 ) | 鹰策略 |
| 数据采集(策略 ) | 鸽策略 |
| 不同策略下无人机的收益 | 博弈收益 |
| 无人机之间基于收益的策略转换 | 策略迁移 |
| 采用不同策略的无人机在集群中占比动态变化 | 动态演化 |
| 无人机策略趋于稳定 | 演化稳定 |
表2 收益矩阵Table 2 Payoff matrix |
| 策略名称 | 策略 | 策略 |
|---|---|---|
| 策略 | 0 | |
| 策略 |
2.3 基于愿景驱动规则的协同策略更新
3 协同感知场景鲁棒性指标构建
3.1 场景鲁棒性指标集
表3 鲁棒性指标维度Table 3 Dimensions of robustness indicators |
| 指标类别 | 描述角度 |
|---|---|
| 集群属性 | 单节点能力 |
| 集群能力 | |
| 环境属性 | 地形因素 |
| 干扰因素 | |
| 任务效果 | 个体效果 |
| 集群效果 |
3.2 无人机集群鲁棒性量化定义
4 不同集群拓扑下的集群鲁棒性分析
4.1 无故障场景
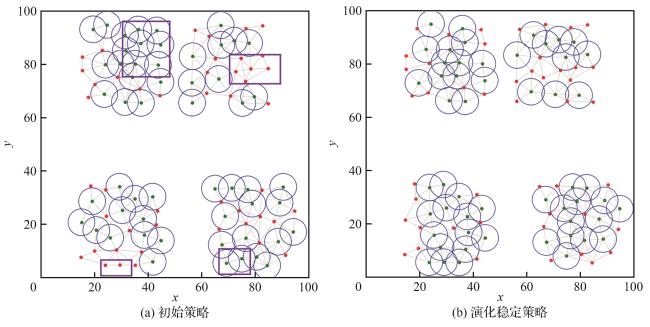
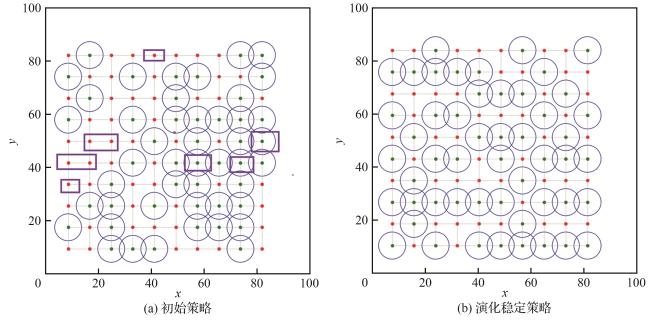
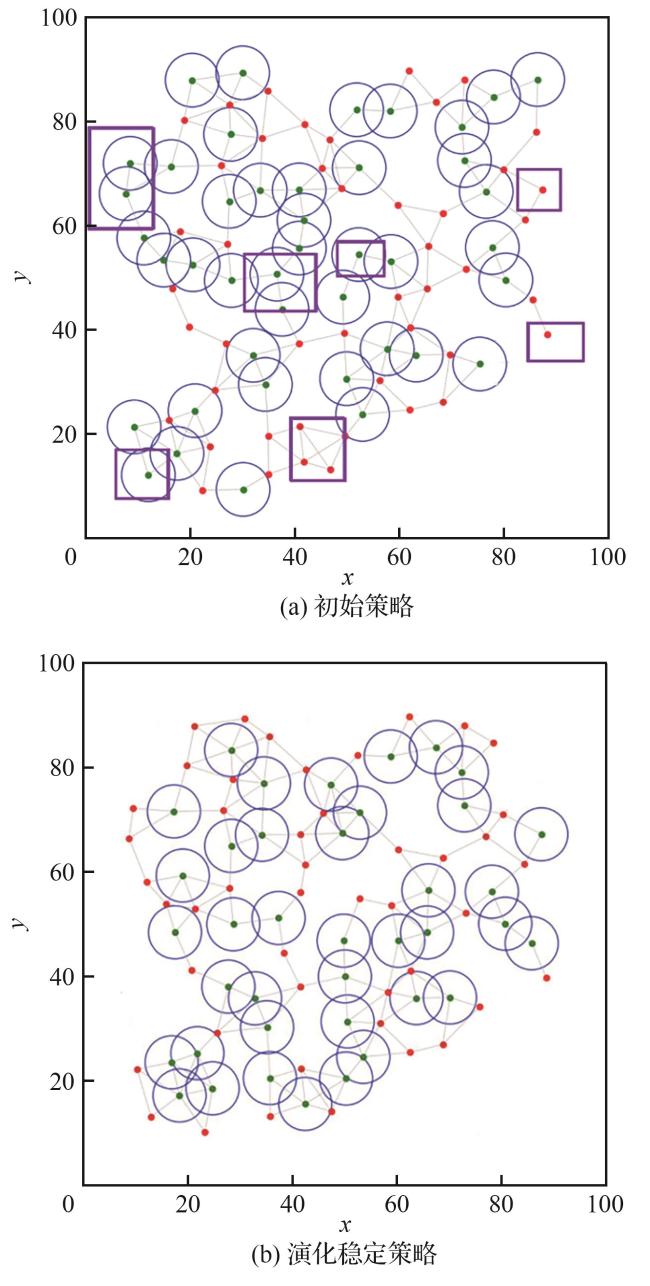
表4 不同拓扑无人机集群鲁棒性 的变化Table 4 Robustness variations of UAV swarm in different topologies |
| 参数 | 场景描述 | 社团网络 | 规则网络 | 随机网络 |
|---|---|---|---|---|
| 初始情况 | 0.642 | 0.587 | 0.626 | |
| 稳定状态 | 0.657 | 0.600 | 0.637 |
4.2 故障场景
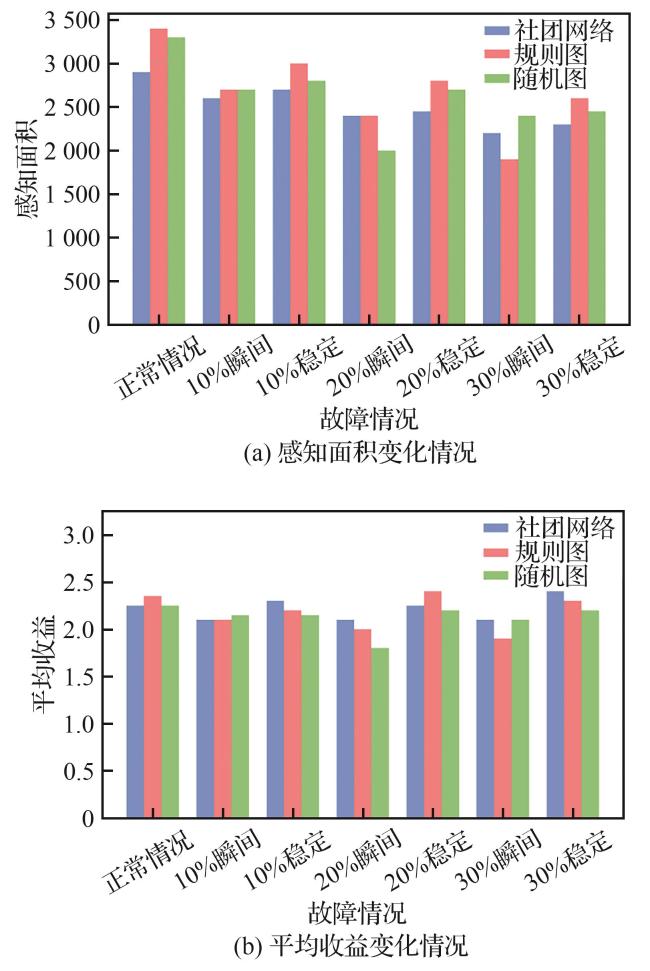
表5 不同拓扑随机故障下无人机集群鲁棒性 变化Table 5 Robustness variations of UAV swarm under random failures in different topologies |
| 场景描述 | 社团网络 | 规则图 | 随机图 |
|---|---|---|---|
| 正常情况 | 0.657 | 0.600 | 0.637 |
| 删除10%节点 | 0.637 | 0.540 | 0.586 |
| 删除20%节点 | 0.582 | 0.500 | 0.557 |
| 删除30%节点 | 0.581 | 0.466 | 0.516 |
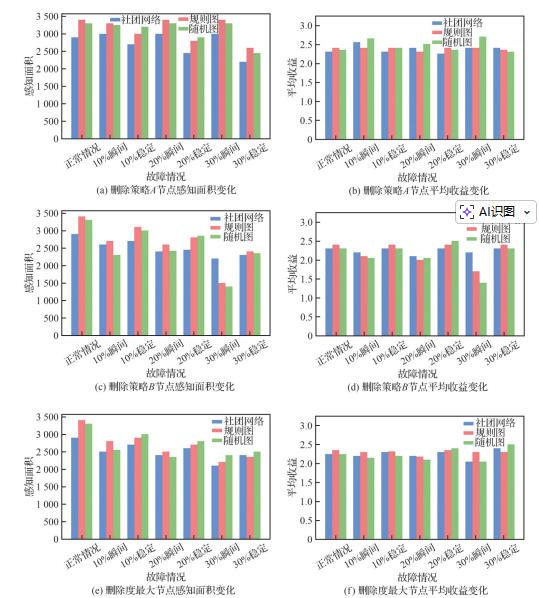
表6 删除策略 节点各拓扑无人机集群鲁棒性 的变化Table 6 Robustness variations of UAV swarm with Strategy A deletion in different topologies |
| 场景描述 | 社团网络 | 规则图 | 随机图 |
|---|---|---|---|
| 正常情况 | 0.657 | 0.600 | 0.637 |
| 删除10%节点 | 0.648 | 0.562 | 0.629 |
| 删除20%节点 | 0.618 | 0.498 | 0.551 |
| 删除30%节点 | 0.559 | 0.410 | 0.511 |
表7 删除策略 节点各拓扑无人机集群鲁棒性 变化Table 7 Robustness variations of UAV swarm with Strategy B deletion in different topologies |
| 场景描述 | 社团网络 | 规则图 | 随机图 |
|---|---|---|---|
| 正常情况 | 0.657 | 0.600 0 | 0.637 |
| 删除10%节点 | 0.619 | 0.537 5 | 0.603 |
| 删除20%节点 | 0.594 | 0.502 0 | 0.522 |
| 删除30%节点 | 0.593 | 0.438 0 | 0.521 |
表8 各拓扑删除度最大节点无人机集群鲁棒性 变化Table 8 Robustness variations of UAV swarm with maximum degree node deletion in different topologies |
| 场景描述 | 社团网络 | 规则图 | 随机图 |
|---|---|---|---|
| 正常情况 | 0.657 | 0.600 | 0.637 |
| 删除10%节点 | 0.624 | 0.486 | 0.620 |
| 删除20%节点 | 0.608 | 0.400 | 0.612 |
| 删除30%节点 | 0.559 | 0.386 | 0.510 |
4.3 通信受限场景
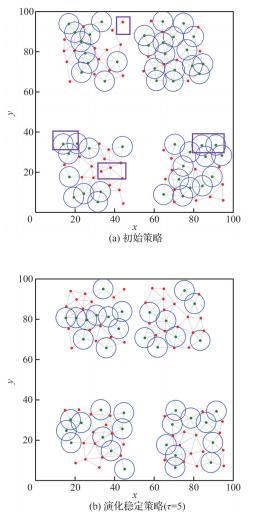
图 7 通信延迟时社团网络演化结果( )Fig.7 Evolution results of community network with communication delay ( ) |
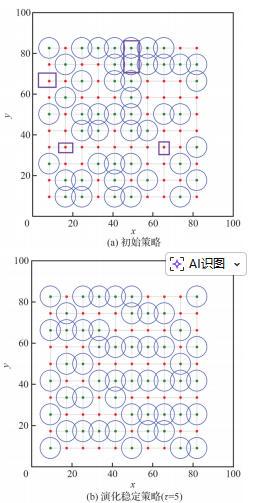
图 8 通信延迟时规则网络演化结果( )Fig.8 Evolution results of regular network with communication delay ( ) |
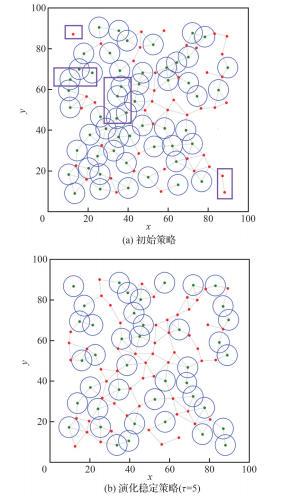
表9 通信延迟下无人机集群鲁棒性 的变化Table 9 Variation of robustness of UAV swarm with communication delay |
| 场景描述 | 社团网络 | 规则网络 | 随机网络 |
|---|---|---|---|
| 正常情况 | 0.647 | 0.600 | 0.627 |
| 0.646 | 0.598 | 0.625 | |
| 0.644 | 0.599 | 0.622 | |
| 0.645 | 0.596 | 0.621 |
5 基于可解释机器学习的鲁棒性智能评估
5.1 基于XGBoost的评估方法
表10 XGBoost优化参数Table 10 Optimized parameters of XGBoost |
| 参数 | 意义 |
|---|---|
| max_depth | 树的最大深度 |
| n_estimators | 决策树的弱学习器数量 |
| subsample | 每棵树随机取样的比例 |
| colsample_bytree | 构建弱学习器时随机采样的特征比例 |
| colsample_bylevel | 每个分层随机采样的特征比例 |
| lambda | XGBoost的正则化参数 |
| alpha | XGBoost的正则化参数 |
| gamma | XGBoost中决策树拆分导致loss减少的阈值 |
| learning_rate | 控制每个弱学习器的权重降低系数 |
| min_child_weight | 子节点中最小样本的权重之和 |
表11 HHO参数设置Table 11 Parameter Settings of HHO |
| 参数 | 数值 |
|---|---|
| 迭代次数 | 50 |
| 种群规模 | 50 |
| 搜索空间上限 | 1 |
| 搜索空间下限 | 0 |
| |
|---|
| 输入:种群规模 和最大迭代次数 |
| 输出:eXGBoost模型 |
| 1: Randomly generated as initial Harris hawk populations |
| 2: while stopping condition is not met do: |
| 3: Calculate the fitness values of hawks |
| 4: Set as the location of rabbit (Location of optimal fitness) |
| 5: for each hawk( ) do: |
| 6: Update the initial energy and jump strength |
| 7: Update the according to |
| 8: if then: |
| 9: Update the location vector according to |
| 10: end if |
| 11: if then: |
| 12: if and then |
| 13: Update the location vector according to |
| 14: else if and then |
| 15: Update the location vector according to |
| 16: else if and then |
| 17: Update the location vector according to |
| 18: else if and then |
| 19: Update the location vector according to |
| 20: end if |
| 21: end if |
| 22: end for |
| 23: end while |
| 24: Calculation of model parameters |
| 25: return eXGBoost model |
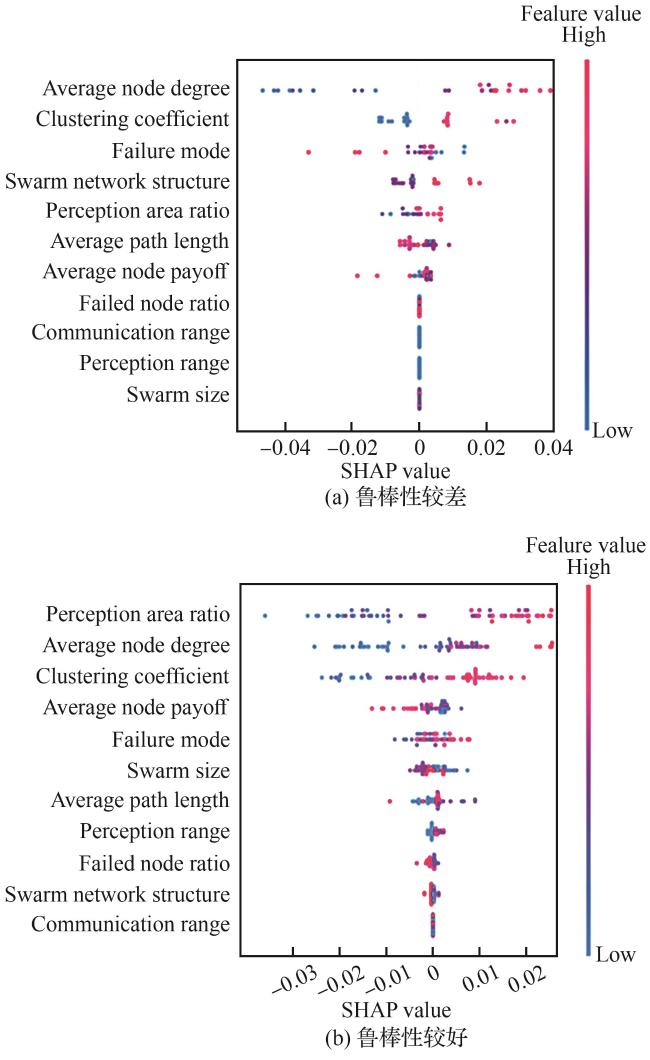
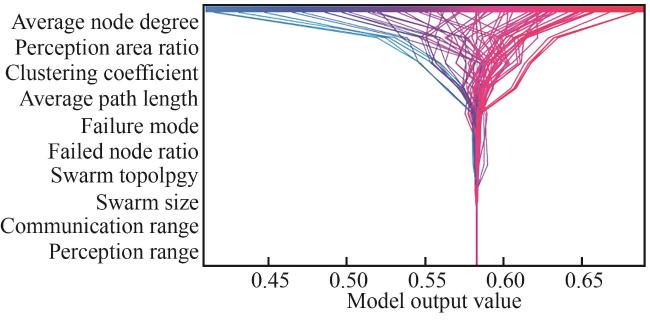
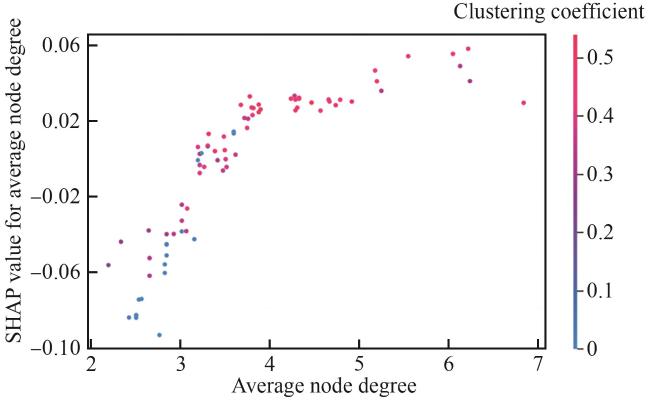
5.2 评估结果
表12 数据样例Table 12 Data samples |
| 指标 | 样例1 | 样例2 | 样例3 | 样例4 |
|---|---|---|---|---|
| 感知范围 | 5 | 5 | 7 | 5 |
| 通信范围 | 10 | 10 | 13 | 10 |
| 集群规模 | 100 | 120 | 90 | 120 |
| 集群拓扑 | 社团网络 | 规则网络 | 随机网络 | 随机网络 |
| 平均路径长度 | 2.61 | 6.93 | 5.31 | 6.39 |
| 平均节点度 | 4.66 | 3.16 | 4.31 | 2.93 |
| 聚类系数 | 0.53 | 0 | 0.47 | 0.35 |
| 故障模式 | 未故障 | 随机故障 | 策略A 节点故障 | 度最大 节点故障 |
| 故障节点比例 | 0 | 0.1 | 0.2 | 0.3 |
| 节点平均收益 | 2.308 | 2.44 | 2.377 5 | 2.23 |
| 感知面积比值 | 1 | 0.905 | 0.809 | 0.742 |
| 鲁棒性指标 | 0.657 | 0.495 | 0.58 | 0.524 |
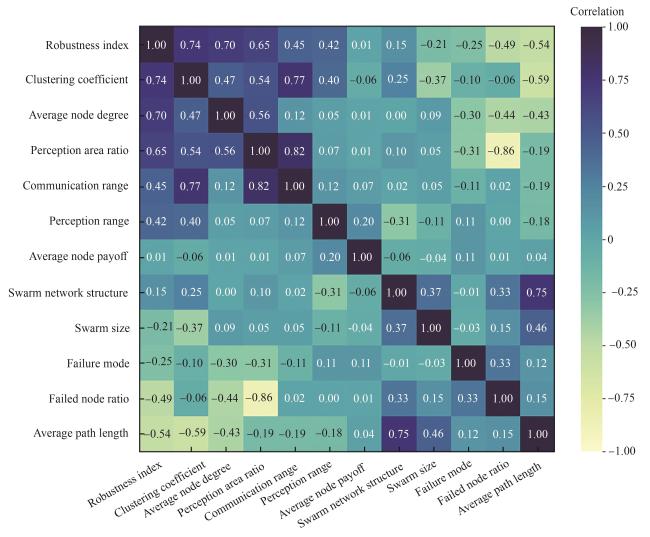
表13 算法准确率对比Table 13 Algorithm accuracy comparison |
| 算法 | 准确率 | |||
|---|---|---|---|---|
| 误差容忍度0.04 | 误差容忍度0.06 | 误差容忍度0.08 | 误差容忍度0.10 | |
| eXGBoost | 0.93 | 0.96 | 0.97 | 0.98 |
| XGBoost | 0.84 | 0.91 | 0.95 | 0.97 |
| LightGBM | 0.85 | 0.93 | 0.97 | 0.98 |
| CatBoost | 0.85 | 0.9 | 0.93 | 0.94 |
| SVM | 0.55 | 0.73 | 0.77 | 0.81 |
| MLP | 0.83 | 0.91 | 0.95 | 0.96 |
| Kernel ridge regression | 0.70 | 0.87 | 0.93 | 0.97 |
| DRVFL | 0.6 | 0.72 | 0.78 | 0.85 |
表14 算法性能比较Table 14 Algorithm performance comparison |
| 算法 | MAE | MSE | RMSE | |
|---|---|---|---|---|
| eXGBoost | 0.043 | 0.005 | 0.071 | 0.994 |
| XGBoost | 0.067 | 0.014 | 0.120 | 0.978 |
| LightGBM | 0.061 | 0.011 | 0.104 | 0.990 |
| CatBoost | 0.082 | 0.086 | 0.294 | 0.950 |
| SVM | 0.230 | 0.161 | 0.401 | 0.804 |
| MLP | 0.119 | 0.042 | 0.205 | 0.960 |
| Kernel ridge regression | 0.093 | 0.020 | 0.136 | 0.980 |
| DRVFL | 0.182 | 0.112 | 0.335 | 0.863 |
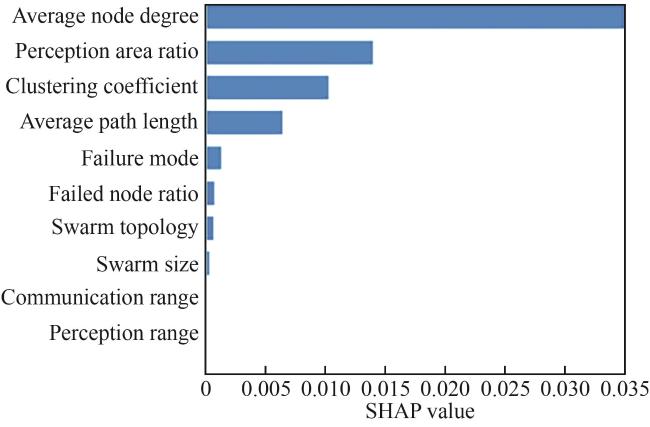
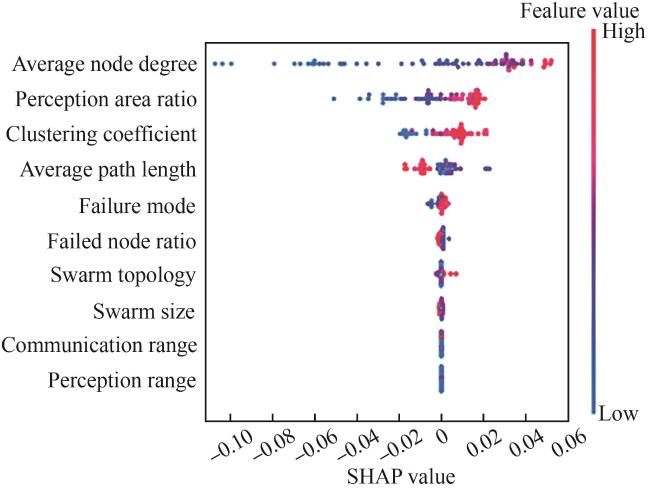

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}