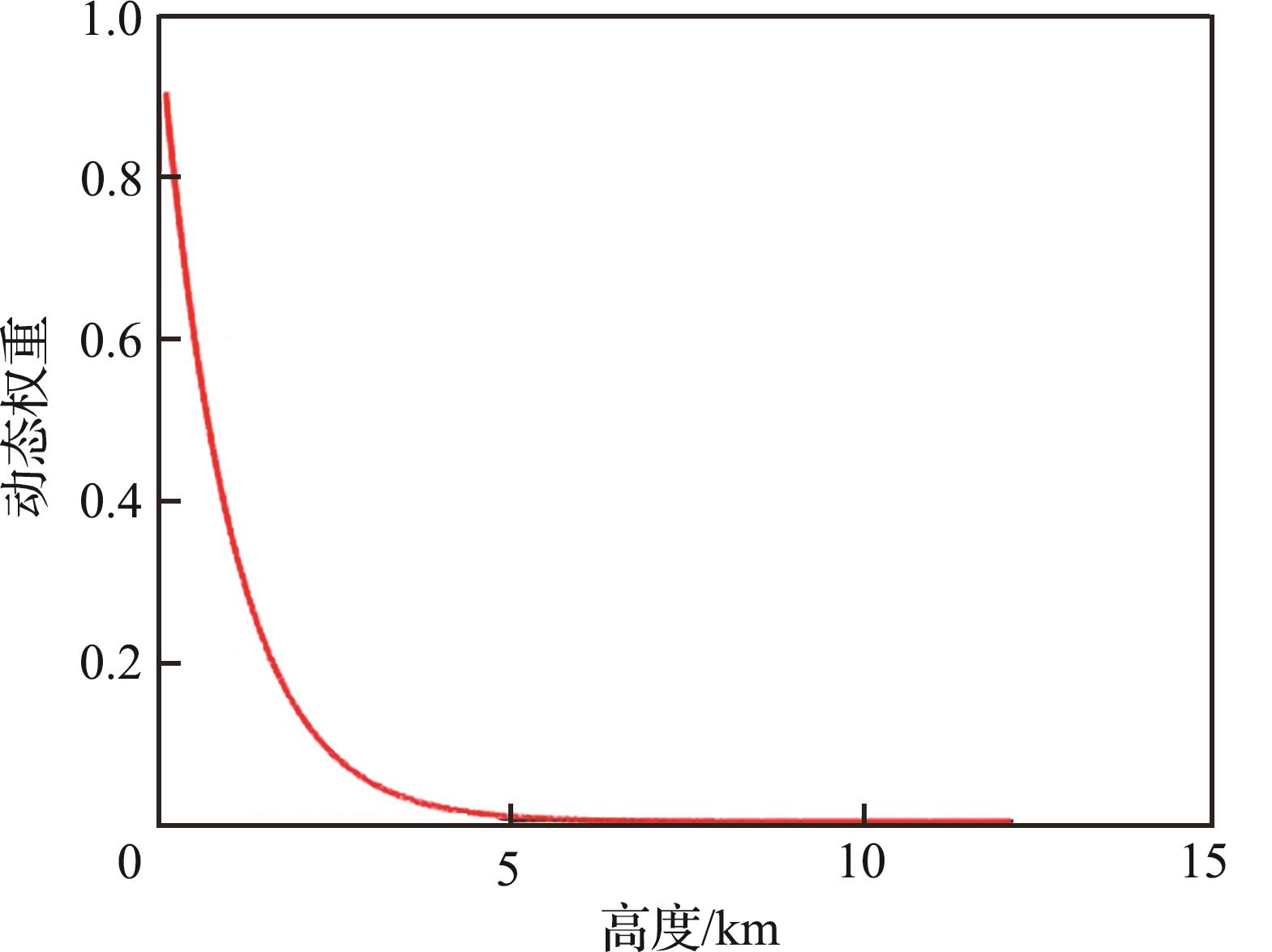
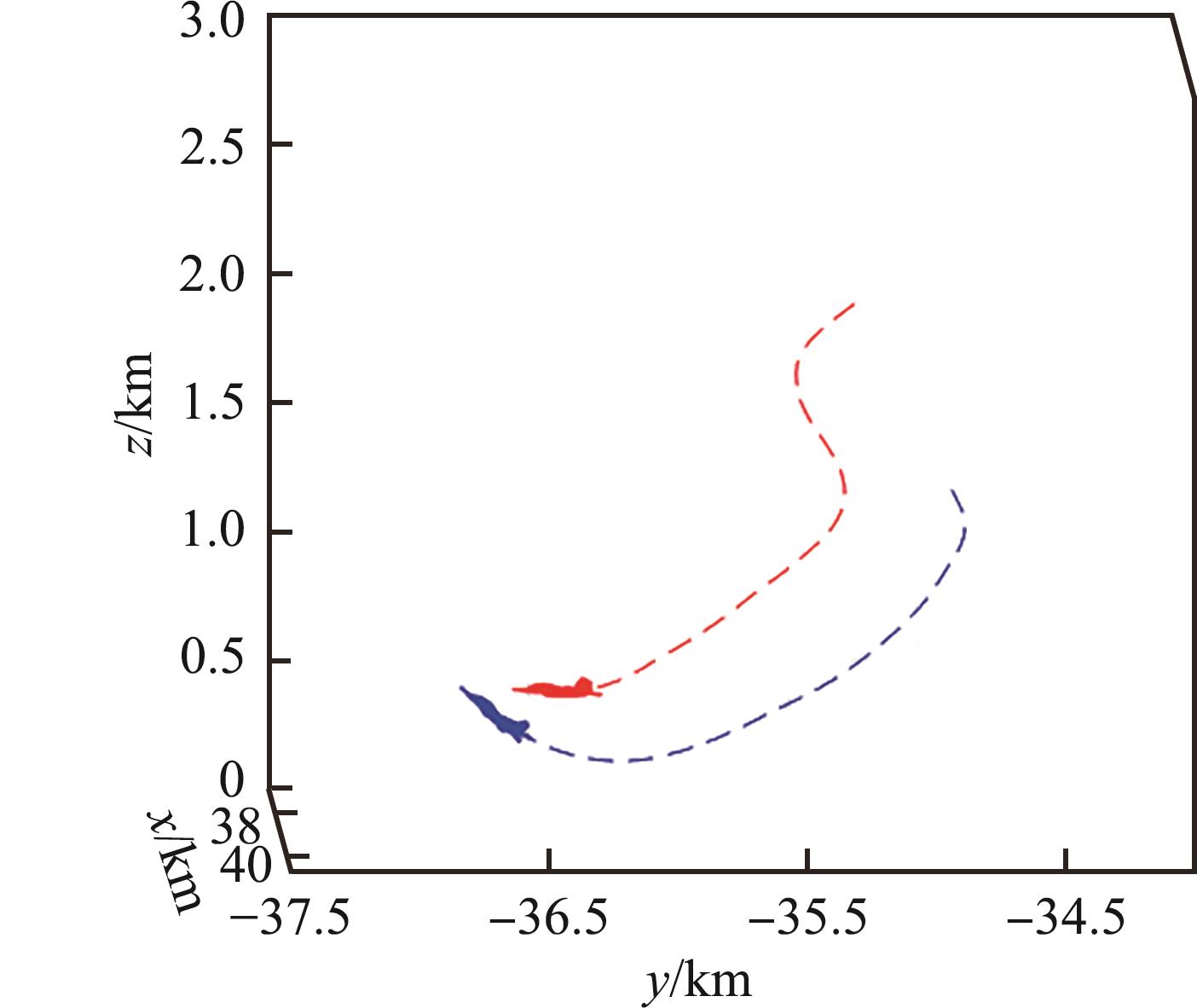
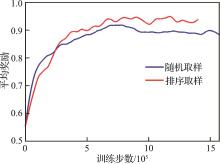
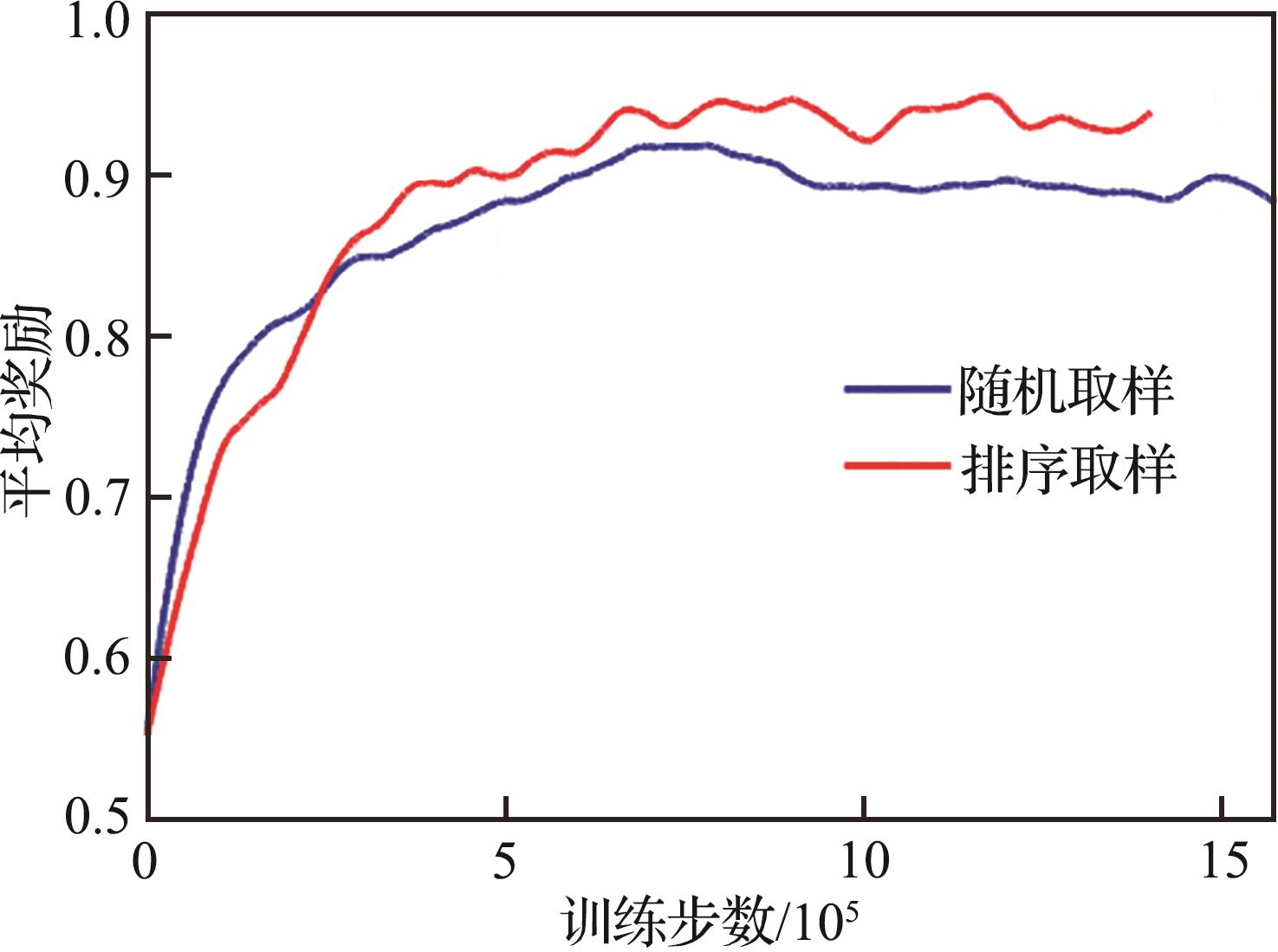
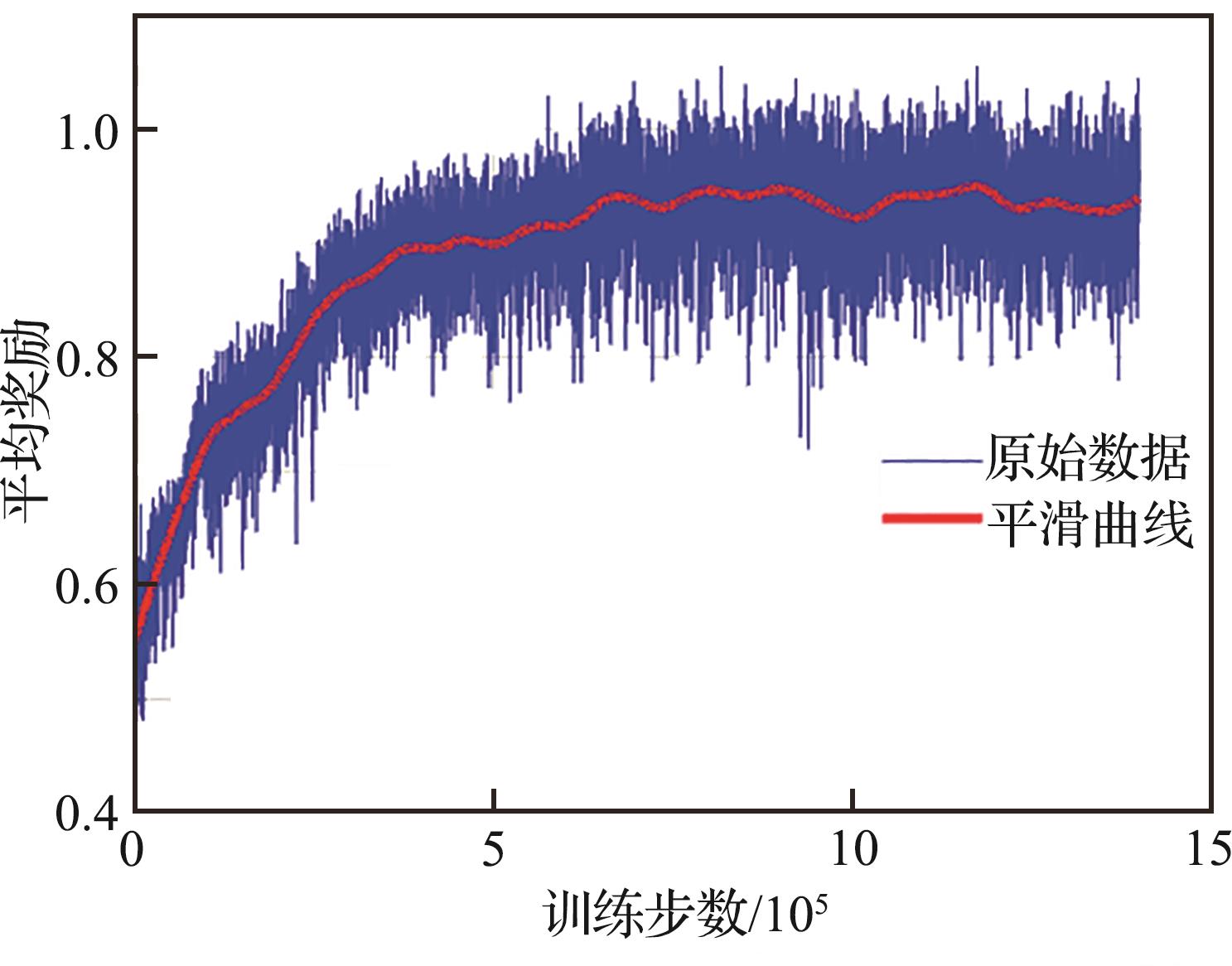
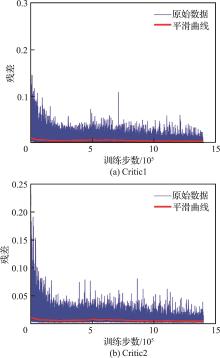
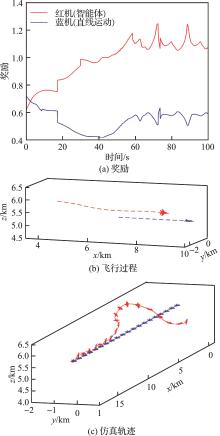
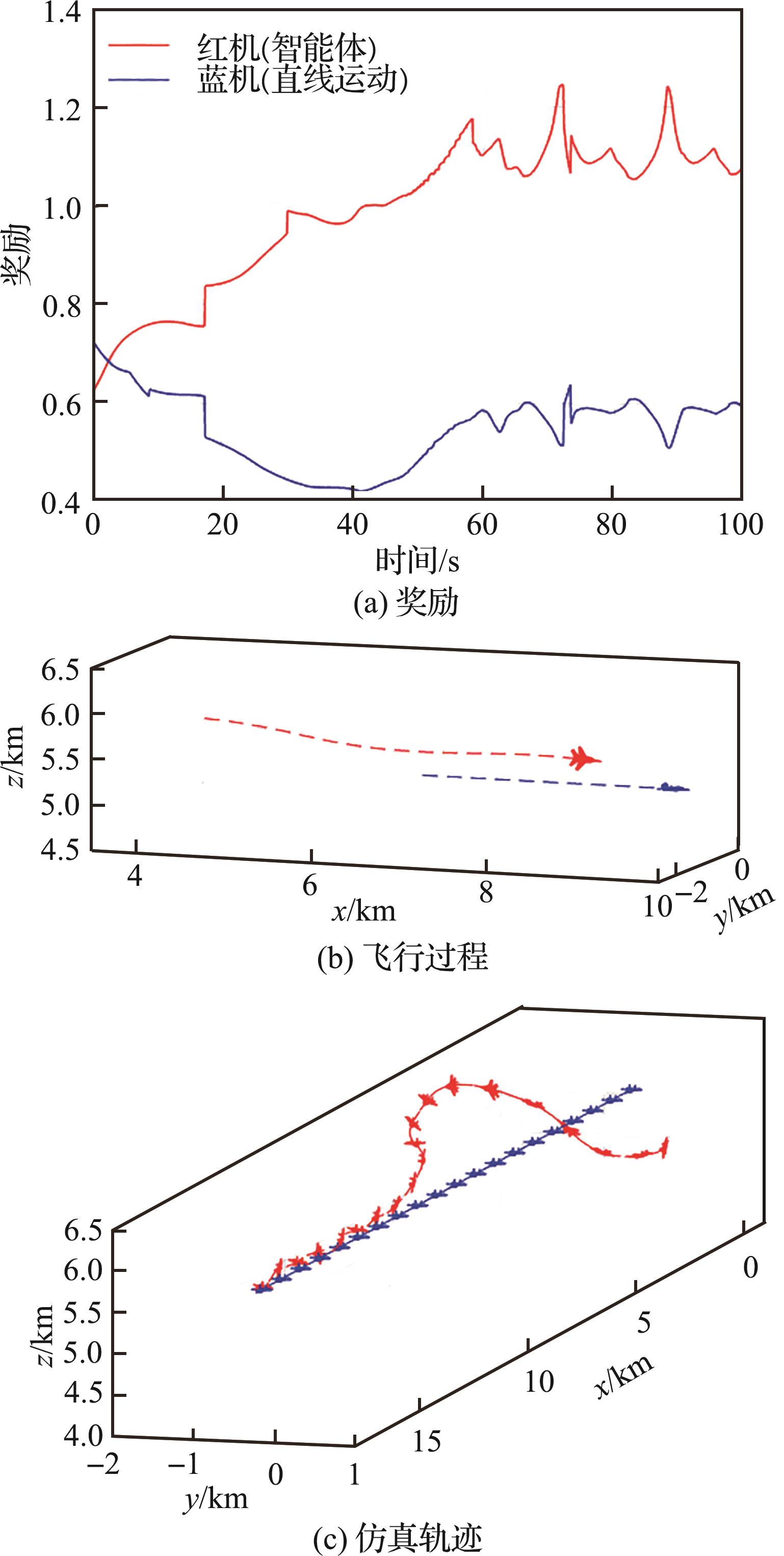
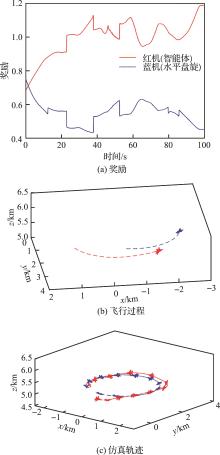
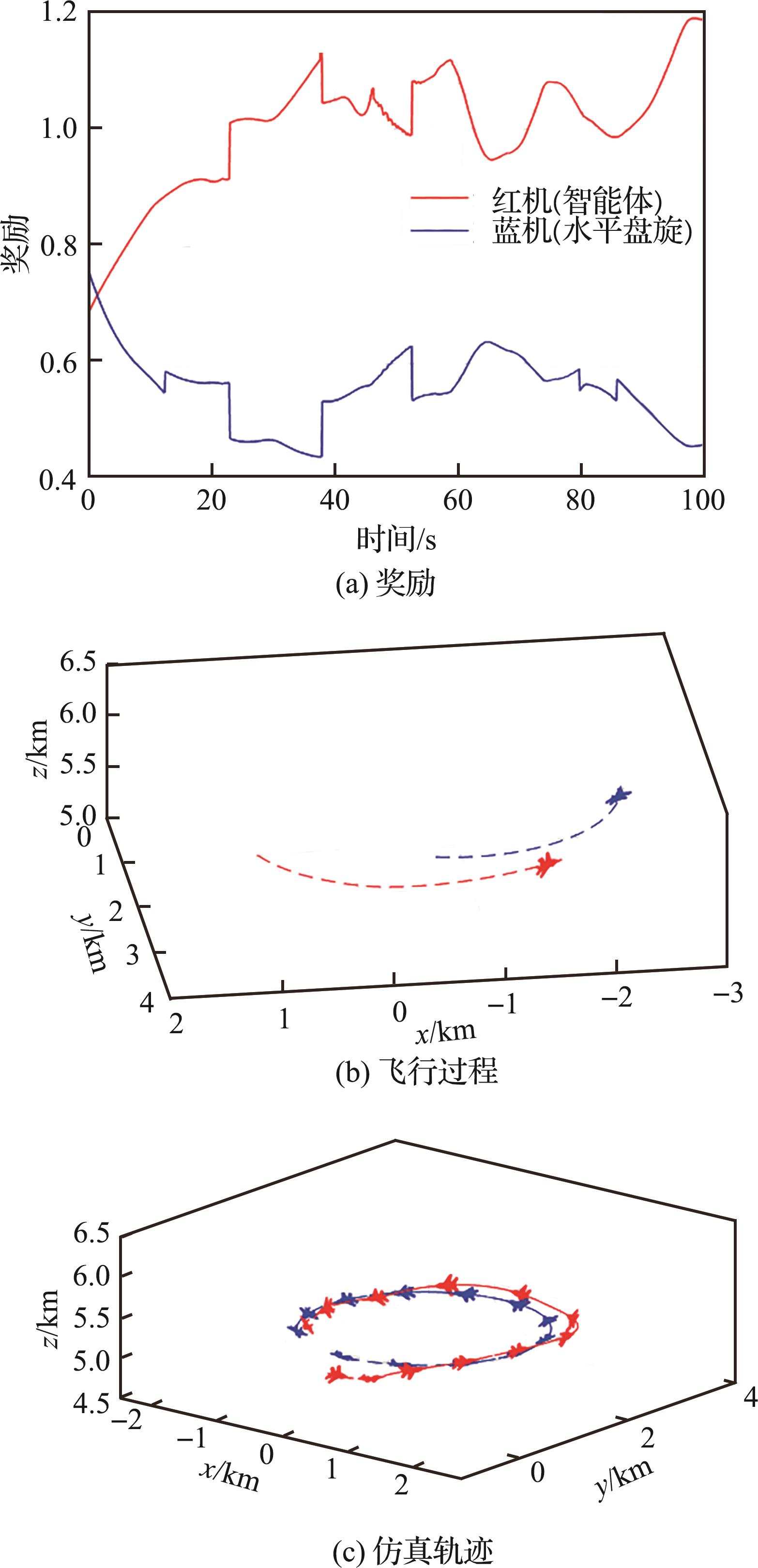
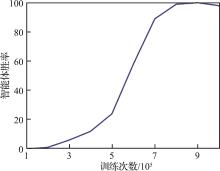
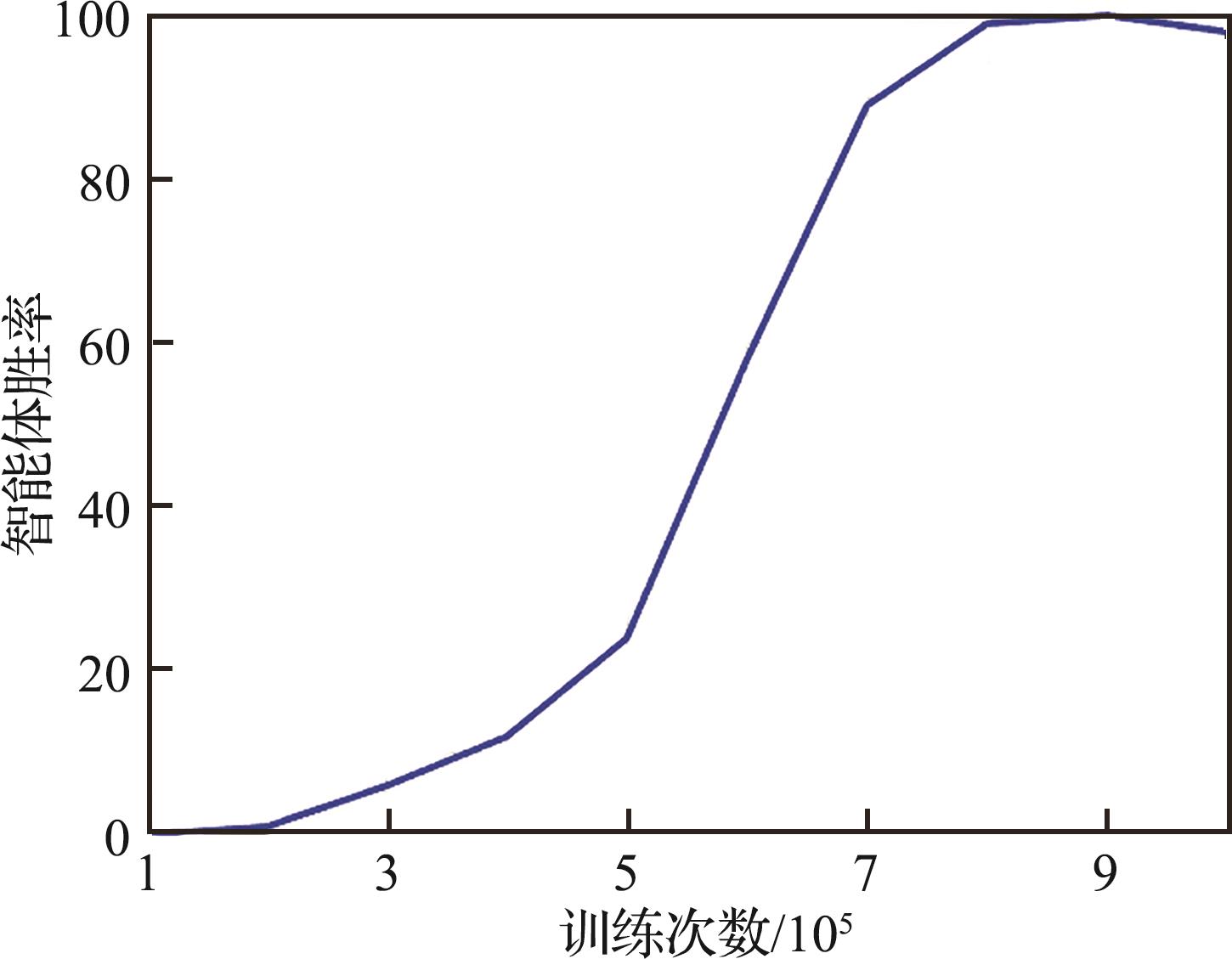
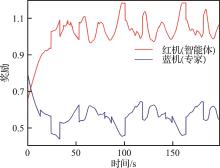
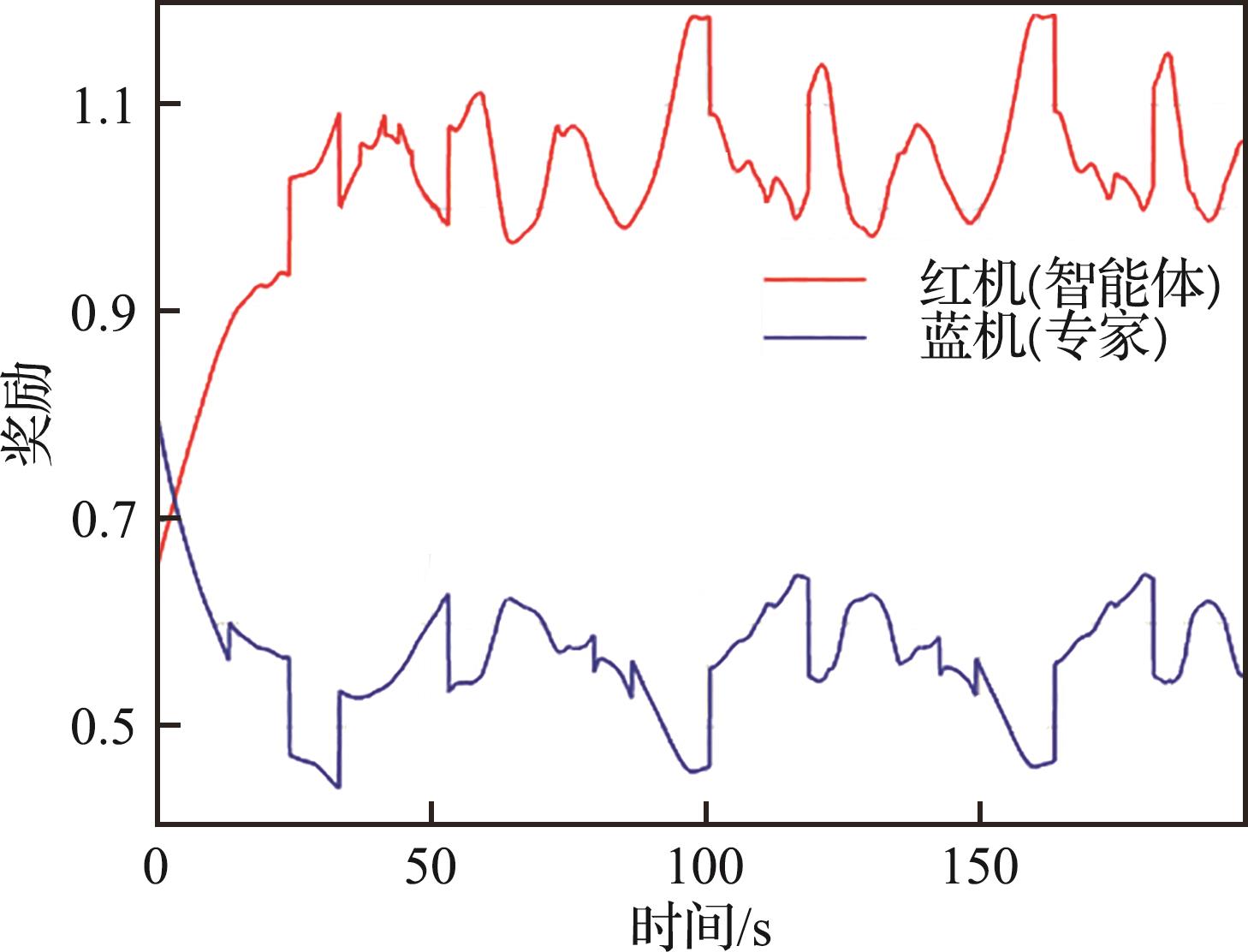
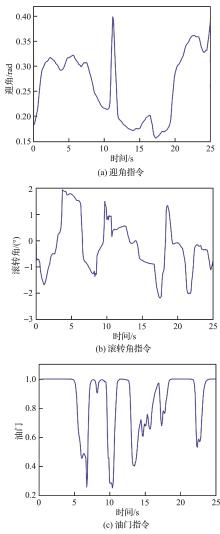
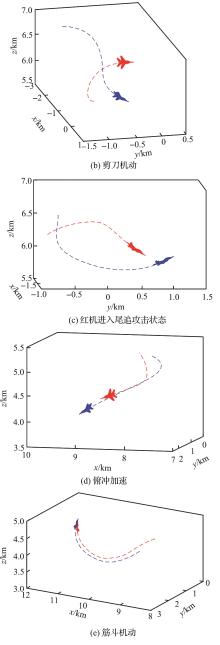
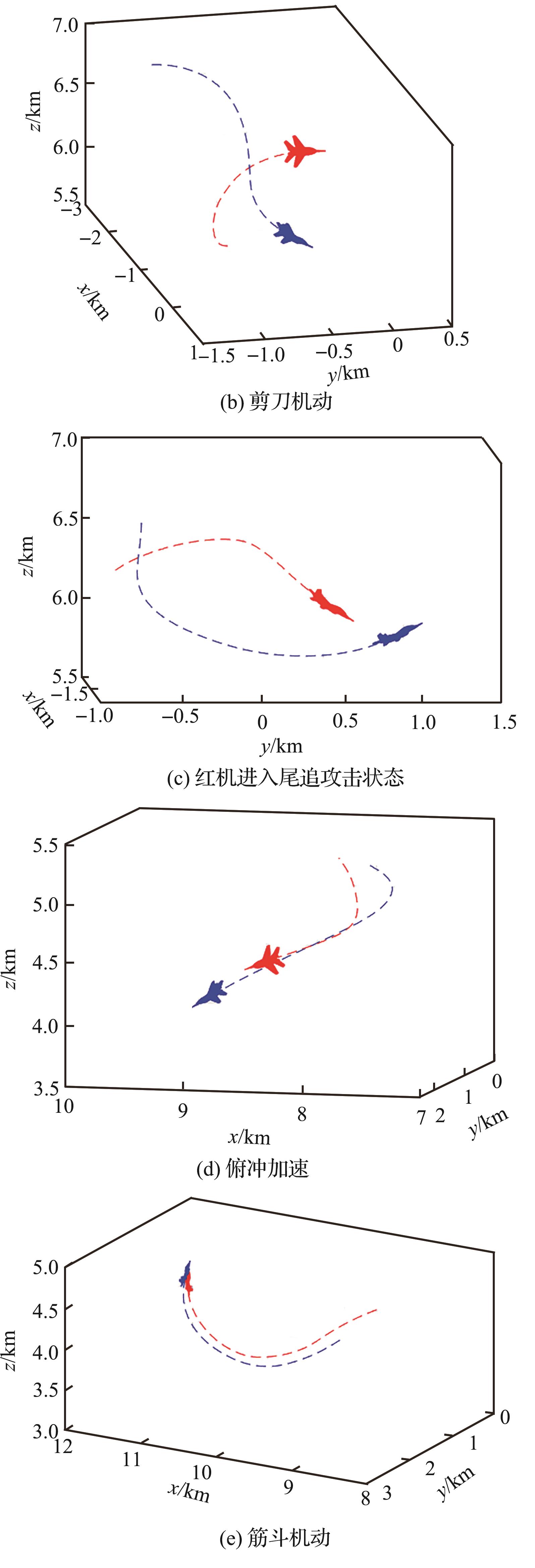
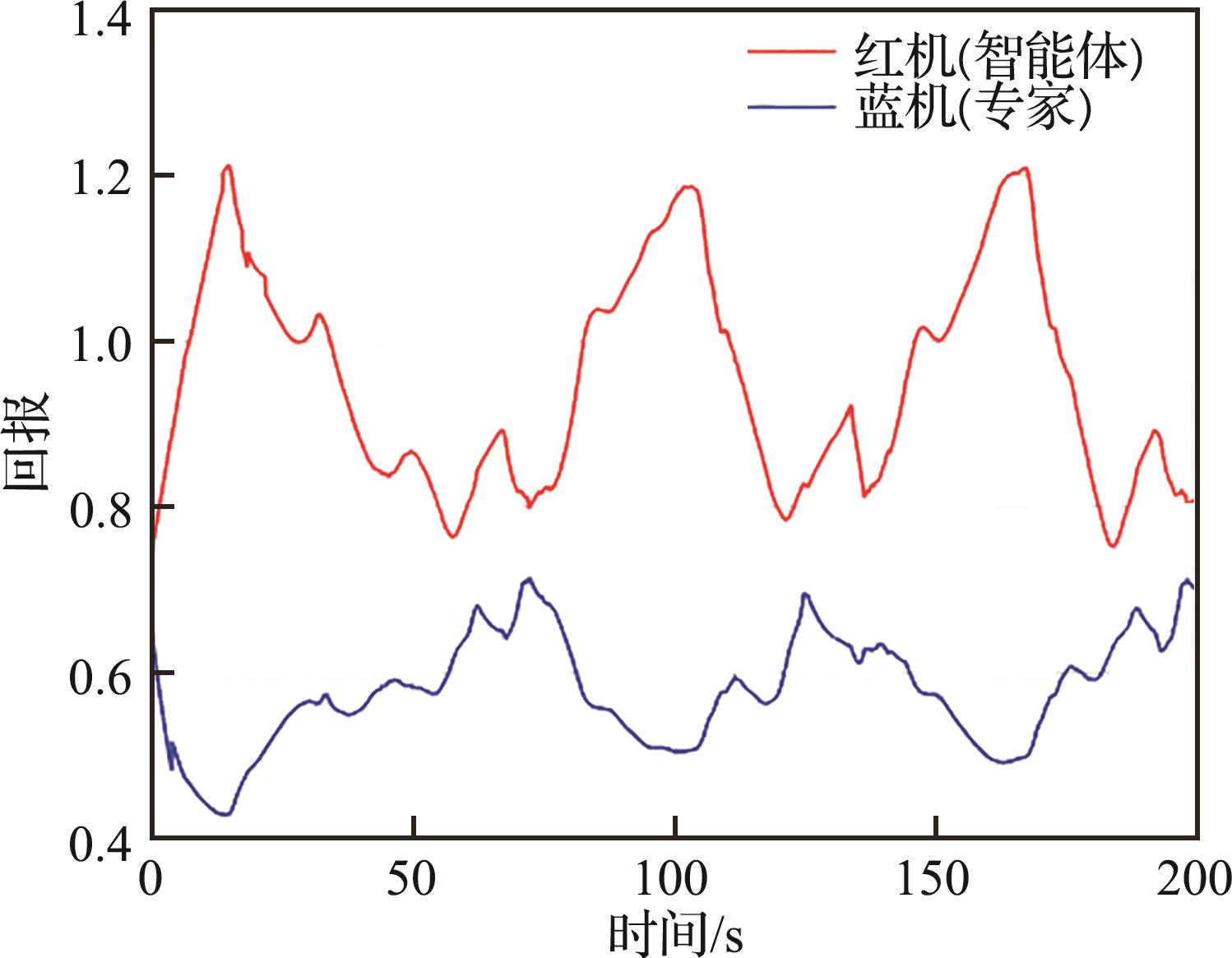
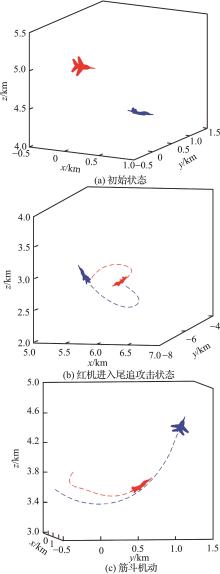
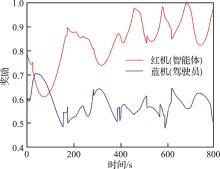
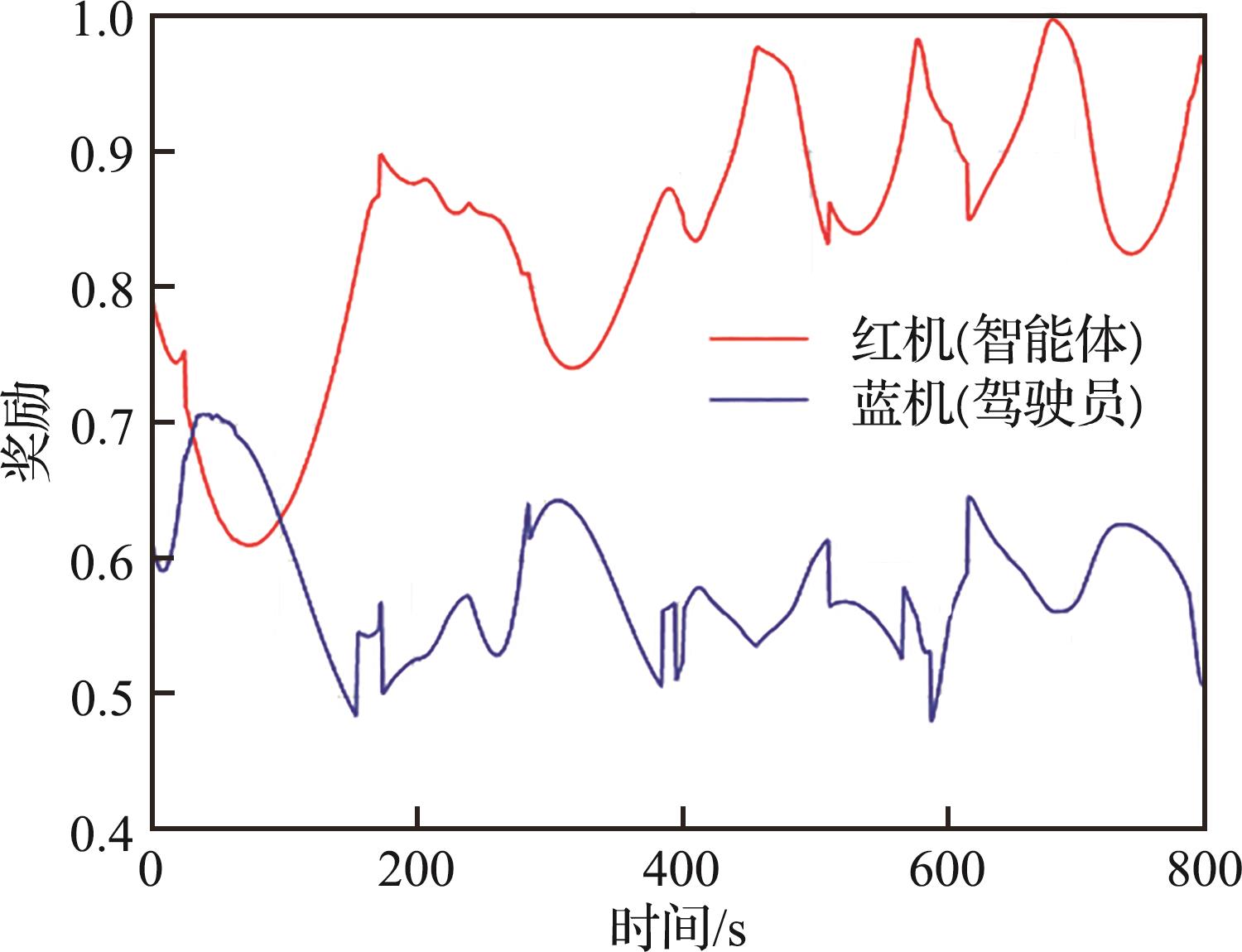
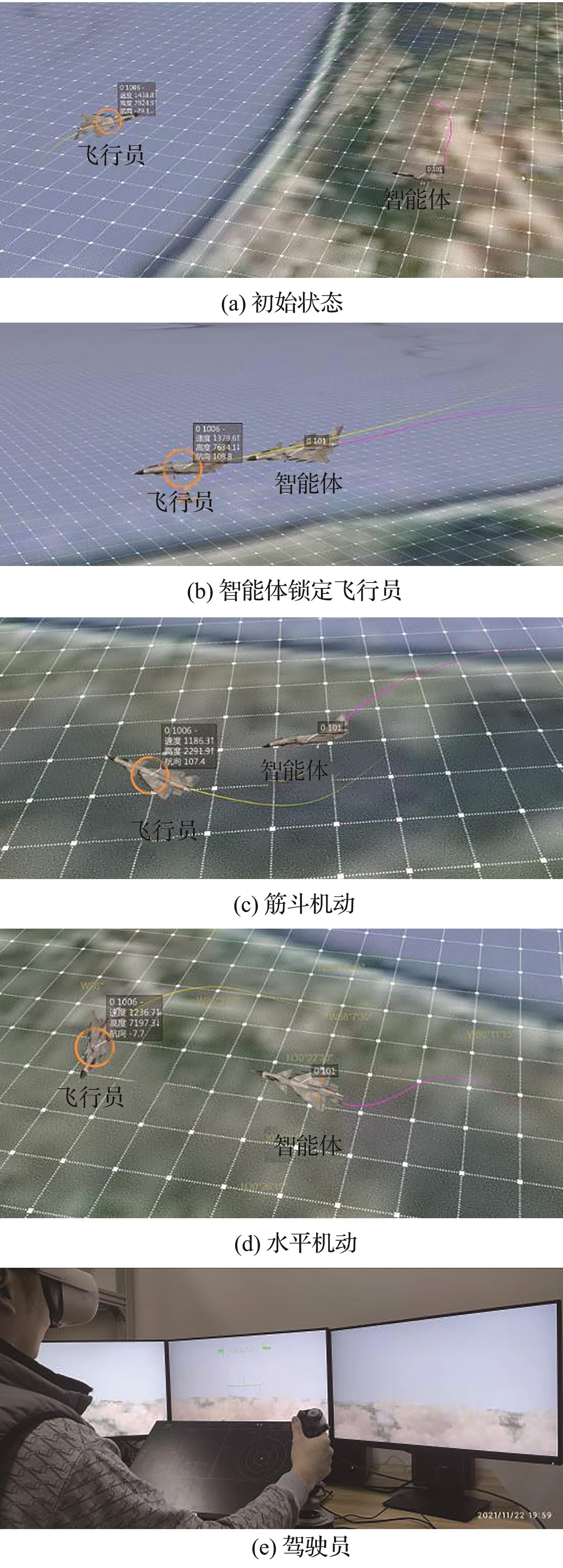
| 1 |
SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
|
| 2 |
Defense Advanced Research Projects Agency. AlphaGogfight trials go virtual for final event [EB/OL]. (2020-08-07) [2021-03-10]. :.
|
| 3 |
孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 525799.
|
|
SUN Z X, YANG S Q, PIAO H Y, et al. A survey of air combat artificial intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 525799 (in Chinese).
|
| 4 |
PARK H, LEE B Y, TAHK M J, et al. Differential game based air combat maneuver generation using scoring function matrix[J]. International Journal of Aeronautical and Space Sciences, 2016, 17(2): 204-213.
|
| 5 |
WEINTRAUB I E, PACHTER M, GARCIA E. An introduction to pursuit-evasion differential games[C]∥ 2020 American Control Conference (ACC). Piscataway: IEEE Press, 2020: 1049-1066.
|
| 6 |
MCGREW J S. Real-time maneuvering decisions for autonomous air combat[D]. Cambridge: Massachusetts Institute of Technology, 2008: 91-104.
|
| 7 |
KANESHIGE J, KRISHNAKUMAR K. Artificial immune system approach for air combat maneuvering[C]∥Proceeding of the SPIE, 2007.
|
| 8 |
薛羽, 庄毅, 张友益, 等. 基于启发式自适应离散差分进化算法的多UCAV协同干扰空战决策[J]. 航空学报, 2013, 34(2): 343-351.
|
|
XUE Y, ZHUANG Y, ZHANG Y Y, et al. Multiple UCAV cooperative jamming air combat decision making based on heuristic self-adaptive discrete differential evolution algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2013, 34(2): 343-351 (in Chinese).
|
| 9 |
BURGIN G H. Improvements to the adaptive maneuvering logic program: NASA CR 3985[R]. Washington, D.C.: NASA, 1986.
|
| 10 |
左家亮, 杨任农, 张滢, 等. 基于启发式强化学习的空战机动智能决策[J]. 航空学报, 2017, 38(10): 321168.
|
|
ZUO J L, YANG R N, ZHANG Y, et al. Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(10): 321168 (in Chinese).
|
| 11 |
张耀中, 许佳林, 姚康佳, 等. 基于DDPG算法的无人机集群追击任务[J]. 航空学报, 2020, 41(10): 324000.
|
|
ZHANG Y Z, XU J L, YAO K J, et al. Pursuit missions for UAV swarms based on DDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(10): 324000 (in Chinese).
|
| 12 |
杜海文, 崔明朗, 韩统, 等 .基于多目标优化与强化学习的空战机动决策[J].北京航空航天大学学报,2018, 44 (11) : 2247-2256.
|
|
DU H W, CUI M L, HAN T, et al. Maneuvering decision in air combat based on multi-objective optimization and reinforcement learning [J]. Journal of Beijing University of Aeronautics and Astronautics, 2018, 44(11): 2247-2256 (in Chinese).
|
| 13 |
施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623.
|
|
SHI W, FENG Y H, CHENG G Q, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning[J]. Acta Automatica Sinica, 2021, 47(7): 1610-1623 (in Chinese).
|
| 14 |
张强, 杨任农, 俞利新, 等. 基于Q-network强化学习的超视距空战机动决策[J]. 空军工程大学学报(自然科学版), 2018, 19(6): 8-14.
|
|
ZHANG Q, YANG R N, YU L X, et al. BVR air combat maneuvering decision by using Q-network reinforcement learning[J]. Journal of Air Force Engineering University (Natural Science Edition), 2018, 19(6): 8-14 (in Chinese).
|
| 15 |
李银通, 韩统, 孙楚, 等. 基于逆强化学习的空战态势评估函数优化方法[J]. 火力与指挥控制, 2019, 44(8): 101-106.
|
|
LI Y T, HAN T, SUN C, et al. An optimization method of air combat situation assessment function based on inverse reinforcement learning[J]. Fire Control & Command Control, 2019, 44(8): 101-106 (in Chinese).
|
| 16 |
SUTTON R S, BARTO A G. Reinforcement learning: an introduction[M]. 2nd ed. London: MIT Press, 2018.
|
| 17 |
HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
|
| 18 |
WATKINS C J C H, DAYAN P. Q-learning[J]. Machine Learning, 1992, 8(3): 279-292.
|
| 19 |
RUMMERY G A, NIRANJAN M. On-line Q-learning using connectionist systems[M]. Cambridge:University of Cambridge, 1994.
|
| 20 |
SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization[C]∥ Proceedings of the 31st International Conference on Machine Learning, 2015: 1889-1897.
|
| 21 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. 2017: arXiv: 1707.06347. .
|
| 22 |
KONDA V R, TSITSIKLIS J N. OnActor-critic algorithms[J]. SIAM Journal on Control and Optimization, 2003, 42(4): 1143-1166.
|
| 23 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]∥4th International Conference on Learning Representations, ICLR 2016-Conference Track Proceedings, 2016.
|
| 24 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
|
| 25 |
FUJIMOTO S, VAN HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]∥Proceedings of the 35th International Conference on Machine Learning, 2018: 1587-1596.
|
| 26 |
魏航. 基于强化学习的无人机空中格斗算法研究[D]. 哈尔滨: 哈尔滨工业大学, 2015: 42-43.
|
|
WEI H. Research of UCAV air combat based on reinforcemnt learning[D]. Harbin: Harbin Institute of Technology, 2015: 42-43 (in Chinese).
|
| 27 |
钟友武, 柳嘉润, 杨凌宇, 等. 自主近距空战中机动动作库及其综合控制系统[J]. 航空学报, 2008, 29(S1): 114-121.
|
|
ZHONG Y W, LIU J R, YANG L Y, et al. Maneuver library and integrated control system for autonomous close-in air combat[J]. Acta Aeronautica et Astronautica Sinica, 2008, 29(1): 114-121 (in Chinese).
|
 ), 章胜1, 刘刚2, 舒博文1,3, 唐骥罡1
), 章胜1, 刘刚2, 舒博文1,3, 唐骥罡1